qlib
v0.9.5 ?

Recursos lançados recentemente
 : Agentes de evolução autônoma baseados em LLM para P&D baseado em dados industriais
: Agentes de evolução autônoma baseados em LLM para P&D baseado em dados industriaisTemos o prazer de anunciar o lançamento do RD-Agent ?, uma ferramenta poderosa que suporta mineração automatizada de fatores e otimização de modelos em P&D de investimentos quantitativos.
O RD-Agent já está disponível no GitHub e damos as boas-vindas à sua estrela?!
Para saber mais, visite nossa página ♾️Demo. Aqui você encontrará vídeos de demonstração em inglês e chinês para ajudá-lo a entender melhor o cenário e o uso do RD-Agent.
Preparamos vários vídeos de demonstração para você:
| Cenário | Vídeo de demonstração (inglês) | Vídeo de demonstração (中文) |
|---|---|---|
| Mineração de fator quantitativo | Link | Link |
| Quant Factor Mining a partir de relatórios | Link | Link |
| Otimização do modelo quântico | Link | Link |
| Recurso | Status |
|---|---|
| BPQP para aprendizagem ponta a ponta | ?Em breve!(Em revisão) |
| Auto Quant Factory dirigida por LLM | Lançado em ♾️RD-Agent em 8 de agosto de 2024 |
| Modelos KRNN e Sanduíche | ? Lançado em 26 de maio de 2023 |
| Lançamento do Qlib v0.9.0 | Lançado em 9 de dezembro de 2022 |
| Estrutura de aprendizagem RL | ? ? Lançado em 10 de novembro de 2022. #1332, #1322, #1316,#1299,#1263, #1244, #1169, #1125, #1076 |
| Modelos HIST e IGMTF | ? Lançado em 10 de abril de 2022 |
| Tutorial de notebook Qlib | Lançado em 7 de abril de 2022 |
| Dados do índice Ibovespa | ? Lançado em 6 de abril de 2022 |
| Banco de dados pontual | ? Lançado em 10 de março de 2022 |
| Exemplo de dados de back-end e livro de pedidos do provedor do Ártico | ? Lançado em 17 de janeiro de 2022 |
| Estrutura baseada em meta-aprendizagem e DDG-DA | ? ? Lançado em 10 de janeiro de 2022 |
| Otimização de portfólio baseada em planejamento | ? Lançado em 28 de dezembro de 2021 |
| Lançamento do Qlib v0.8.0 | Lançado em 8 de dezembro de 2021 |
| ADICIONAR modelo | ? Lançado em 22 de novembro de 2021 |
| Modelo ADARNN | ? Lançado em 14 de novembro de 2021 |
| Modelo TCN | ? Lançado em 4 de novembro de 2021 |
| Estrutura de decisão aninhada | ? Lançado em 1º de outubro de 2021. Exemplo e documento |
| Adaptador de roteamento temporal (TRA) | ? Lançado em 30 de julho de 2021 |
| Transformador e Localformer | ? Lançado em 22 de julho de 2021 |
| Lançamento do Qlib v0.7.0 | Lançado em 12 de julho de 2021 |
| Modelo TCTS | ? Lançado em 1º de julho de 2021 |
| Exibição on-line e rolagem automática de modelos | ? Lançado em 17 de maio de 2021 |
| Modelo DoubleEnsemble | ? Lançado em 2 de março de 2021 |
| Exemplo de processamento de dados de alta frequência | ? Lançado em 5 de fevereiro de 2021 |
| Exemplo de negociação de alta frequência | ? Parte do código lançada em 28 de janeiro de 2021 |
| Dados de alta frequência (1min) | ? Lançado em 27 de janeiro de 2021 |
| Modelo Tabnet | ? Lançado em 22 de janeiro de 2021 |
Os recursos lançados antes de 2021 não estão listados aqui.

Qlib é uma plataforma de investimento quantitativo de código aberto orientada para IA que visa concretizar o potencial, capacitar a investigação e criar valor utilizando tecnologias de IA no investimento quantitativo, desde a exploração de ideias até à implementação de produções. Qlib oferece suporte a diversos paradigmas de modelagem de aprendizado de máquina, incluindo aprendizado supervisionado, modelagem de dinâmica de mercado e aprendizado por reforço.
Um número crescente de trabalhos/artigos de pesquisa SOTA Quant em diversos paradigmas estão sendo lançados no Qlib para resolver colaborativamente os principais desafios no investimento quantitativo. Por exemplo, 1) usar aprendizagem supervisionada para explorar os padrões não lineares complexos do mercado a partir de dados financeiros ricos e heterogêneos, 2) modelar a natureza dinâmica do mercado financeiro usando tecnologia de desvio de conceito adaptativo e 3) usar aprendizagem por reforço para modelar investimento contínuo decisões e auxiliar os investidores na otimização de suas estratégias de negociação.
Ele contém o pipeline completo de ML para processamento de dados, treinamento de modelo e backtesting; e cobre toda a cadeia de investimento quantitativo: busca de alfa, modelagem de risco, otimização de portfólio e execução de ordens. Para obter mais detalhes, consulte nosso artigo "Qlib: Uma plataforma de investimento quantitativo orientada para IA".
| Frameworks, tutorial, dados e DevOps | Principais desafios e soluções em pesquisa quantitativa |
|---|---|
|
|
Novos recursos em desenvolvimento (ordenados por tempo estimado de lançamento). Seus feedbacks sobre os recursos são muito importantes.

A estrutura de alto nível do Qlib pode ser encontrada acima (os usuários podem encontrar a estrutura detalhada do design do Qlib ao entrar em detalhes). Os componentes são projetados como módulos soltos e cada componente pode ser usado de forma independente.
Qlib fornece uma infraestrutura sólida para apoiar a pesquisa Quant. Os dados são sempre uma parte importante. Uma forte estrutura de aprendizagem é projetada para apoiar diversos paradigmas de aprendizagem (por exemplo, aprendizagem por reforço, aprendizagem supervisionada) e padrões em diferentes níveis (por exemplo, modelagem dinâmica de mercado). Ao modelar o mercado, as estratégias de negociação gerarão decisões comerciais que serão executadas. Múltiplas estratégias de negociação e executores em diferentes níveis ou granularidades podem ser aninhados para serem otimizados e executados em conjunto. Por fim, será fornecida uma análise abrangente e o modelo poderá ser atendido online com baixo custo.
Este guia de início rápido tenta demonstrar
Aqui está uma demonstração rápida que mostra como instalar Qlib e executar o LightGBM com qrun . Porém , certifique-se de já ter preparado os dados seguindo as instruções.
Esta tabela demonstra a versão Python suportada do Qlib :
| instalar com pip | instalar da fonte | trama | |
|---|---|---|---|
| Pitão 3.7 | ✔️ | ✔️ | ✔️ |
| Pitão 3.8 | ✔️ | ✔️ | ✔️ |
| Pitão 3.9 | ✔️ |
Observação :
conda pode resultar na falta de arquivos de cabeçalho, causando falha na instalação de determinados pacotes.Qlib a partir do código-fonte. Se os usuários usam Python 3.6 em suas máquinas, é recomendado atualizar o Python para a versão 3.7 ou usar o Python de conda para instalar Qlib a partir do código-fonte.Qlib suporta a execução de fluxos de trabalho, como modelos de treinamento, backtest e plotagem da maioria das figuras relacionadas (aquelas incluídas no notebook). No entanto, a plotagem do desempenho do modelo não é suportada por enquanto e corrigiremos isso quando os pacotes dependentes forem atualizados no futuro.Qlib Requer pacote tables , hdf5 em tabelas não suporta python3.9. Os usuários podem instalar facilmente Qlib por pip de acordo com o comando a seguir.
pip install pyqlibNota : o pip instalará o qlib estável mais recente. No entanto, o ramo principal do qlib está em desenvolvimento ativo. Se você deseja testar os scripts ou funções mais recentes no branch principal. Instale o qlib com os métodos abaixo.
Além disso, os usuários podem instalar a versão de desenvolvimento mais recente Qlib pelo código-fonte de acordo com as seguintes etapas:
Antes de instalar Qlib a partir do código-fonte, os usuários precisam instalar algumas dependências:
pip install numpy
pip install --upgrade cython Clone o repositório e instale Qlib da seguinte maneira.
git clone https://github.com/microsoft/qlib.git && cd qlib
pip install . # `pip install -e .[dev]` is recommended for development. check details in docs/developer/code_standard_and_dev_guide.rst Nota : Você também pode instalar o Qlib com python setup.py install . Mas não é a abordagem recomendada. Isso irá pular pip e causar problemas obscuros. Por exemplo, apenas o comando pip install . pode substituir a versão estável instalada por pip install pyqlib , enquanto o comando python setup.py install não pode .
Dicas : Se você não conseguir instalar Qlib ou executar os exemplos em seu ambiente, comparar suas etapas e o fluxo de trabalho do CI pode ajudá-lo a encontrar o problema.
Dicas para Mac : Se você estiver usando Mac com M1, poderá encontrar problemas na construção da roda para LightGBM, devido à falta de dependências do OpenMP. Para resolver o problema, instale o openmp primeiro com brew install libomp e depois execute pip install . para construí-lo com sucesso.
❗ Devido à política de segurança de dados mais restrita. O conjunto de dados oficial está desativado temporariamente. Você pode experimentar esta fonte de dados fornecida pela comunidade. Aqui está um exemplo para baixar os dados atualizados em 20240809.
wget https://github.com/chenditc/investment_data/releases/download/2024-08-09/qlib_bin.tar.gz
mkdir -p ~ /.qlib/qlib_data/cn_data
tar -zxvf qlib_bin.tar.gz -C ~ /.qlib/qlib_data/cn_data --strip-components=1
rm -f qlib_bin.tar.gzO conjunto de dados oficial abaixo será retomado em breve.
Carregue e prepare os dados executando o seguinte código:
# get 1d data
python -m qlib.run.get_data qlib_data --target_dir ~ /.qlib/qlib_data/cn_data --region cn
# get 1min data
python -m qlib.run.get_data qlib_data --target_dir ~ /.qlib/qlib_data/cn_data_1min --region cn --interval 1min
# get 1d data
python scripts/get_data.py qlib_data --target_dir ~ /.qlib/qlib_data/cn_data --region cn
# get 1min data
python scripts/get_data.py qlib_data --target_dir ~ /.qlib/qlib_data/cn_data_1min --region cn --interval 1min
Este conjunto de dados é criado por dados públicos coletados por scripts crawler, que foram lançados no mesmo repositório. Os usuários poderiam criar o mesmo conjunto de dados com ele. Descrição do conjunto de dados
Preste ATENÇÃO , pois os dados são coletados do Yahoo Finance e podem não ser perfeitos. Recomendamos que os usuários preparem seus próprios dados se tiverem um conjunto de dados de alta qualidade. Para mais informações, os usuários podem consultar o documento relacionado .
Esta etapa é opcional se os usuários quiserem apenas testar seus modelos e estratégias em dados históricos.
Recomenda-se que os usuários atualizem os dados manualmente uma vez (--trading_date 2021-05-25) e, em seguida, configurem-nos para atualização automática.
NOTA : Os usuários não podem atualizar dados de forma incremental com base nos dados off-line fornecidos pelo Qlib (alguns campos são removidos para reduzir o tamanho dos dados). Os usuários devem usar o coletor do Google para baixar os dados do Yahoo do zero e, em seguida, atualizá-los gradativamente.
Para obter mais informações, consulte: coletor do Google
Atualização automática de dados para o diretório "qlib" a cada dia de negociação (Linux)
use crontab : crontab -e
configurar tarefas cronometradas:
* * * * 1-5 python <script path> update_data_to_bin --qlib_data_1d_dir <user data dir>
Atualização manual de dados
python scripts/data_collector/yahoo/collector.py update_data_to_bin --qlib_data_1d_dir <user data dir> --trading_date <start date> --end_date <end date>
docker pull pyqlib/qlib_image_stable:stabledocker run -it --name < container name > -v < Mounted local directory > :/app qlib_image_stable>>> python scripts/get_data.py qlib_data --name qlib_data_simple --target_dir ~ /.qlib/qlib_data/cn_data --interval 1d --region cn
>>> python qlib/workflow/cli.py examples/benchmarks/LightGBM/workflow_config_lightgbm_Alpha158.yaml>>> exitdocker start -i -a < container name >docker stop < container name >docker rm < container name > Qlib fornece uma ferramenta chamada qrun para executar todo o fluxo de trabalho automaticamente (incluindo construção de conjunto de dados, modelos de treinamento, backtest e avaliação). Você pode iniciar um fluxo de trabalho de pesquisa de quantificação automática e obter uma análise de relatórios gráficos de acordo com as seguintes etapas:
Fluxo de trabalho de pesquisa Quant: execute qrun com configuração de fluxo de trabalho lightgbm (workflow_config_lightgbm_Alpha158.yaml da seguinte forma.
cd examples # Avoid running program under the directory contains `qlib`
qrun benchmarks/LightGBM/workflow_config_lightgbm_Alpha158.yaml Se os usuários quiserem usar qrun no modo de depuração, use o seguinte comando:
python -m pdb qlib/workflow/cli.py examples/benchmarks/LightGBM/workflow_config_lightgbm_Alpha158.yaml O resultado do qrun é o seguinte. Consulte Negociação intradiária para obter mais detalhes sobre o resultado.
' The following are analysis results of the excess return without cost. '
risk
mean 0.000708
std 0.005626
annualized_return 0.178316
information_ratio 1.996555
max_drawdown -0.081806
' The following are analysis results of the excess return with cost. '
risk
mean 0.000512
std 0.005626
annualized_return 0.128982
information_ratio 1.444287
max_drawdown -0.091078 Aqui estão documentos detalhados para qrun e fluxo de trabalho.
Análise de relatórios gráficos: execute examples/workflow_by_code.ipynb com jupyter notebook para obter relatórios gráficos
Análise do sinal de previsão (previsão do modelo)
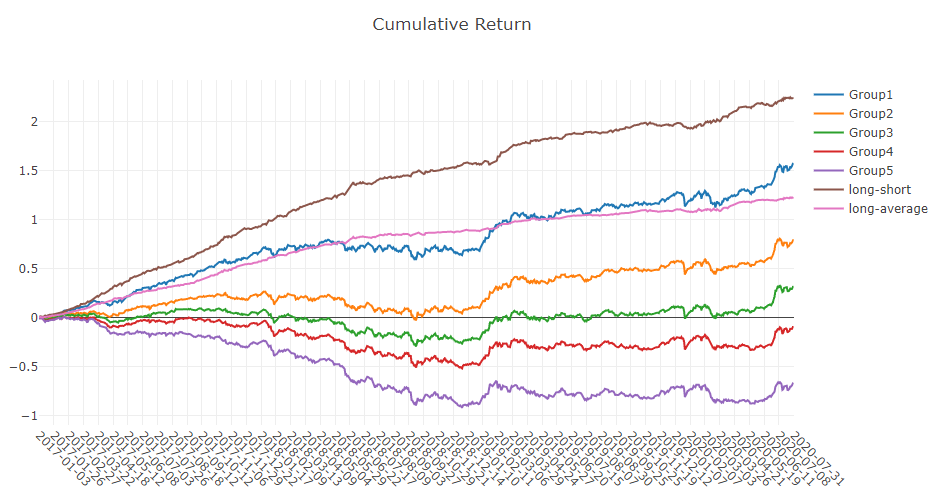
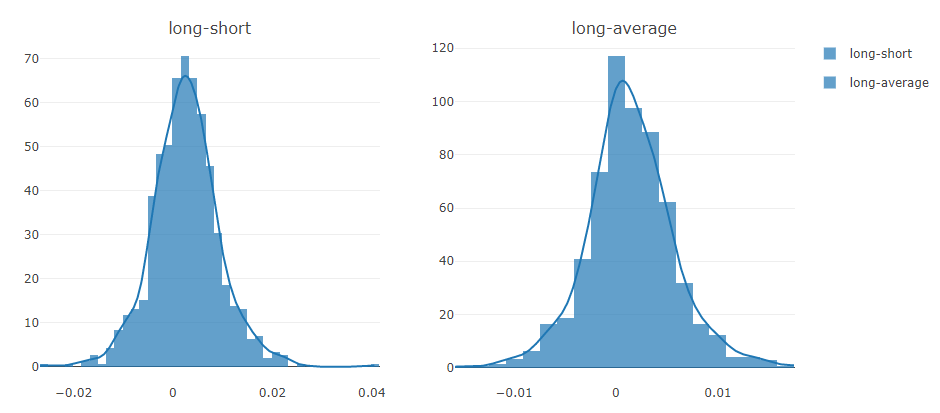
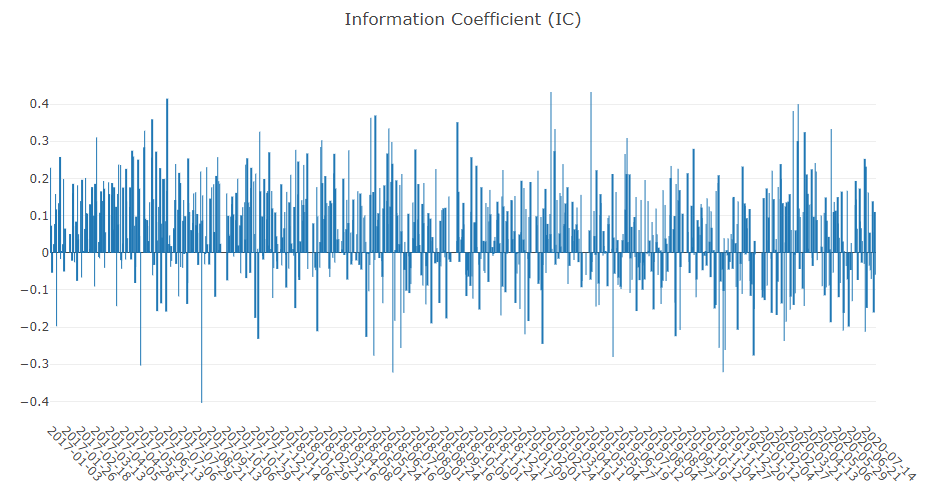
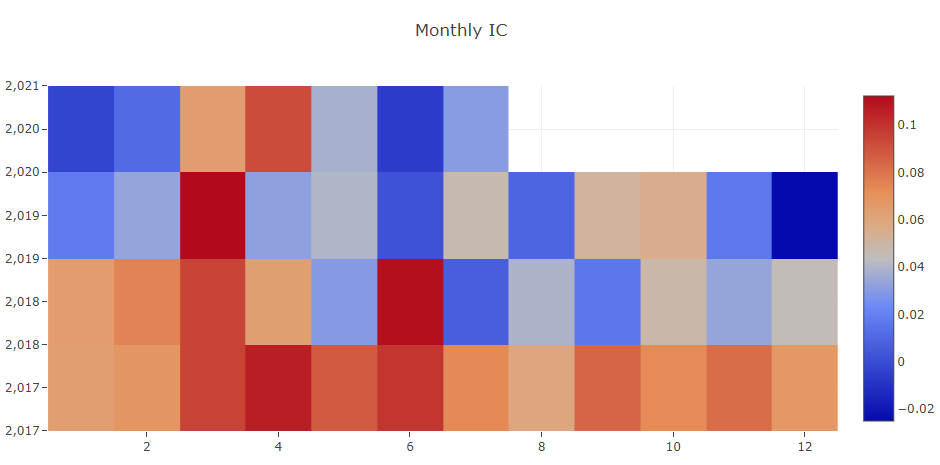
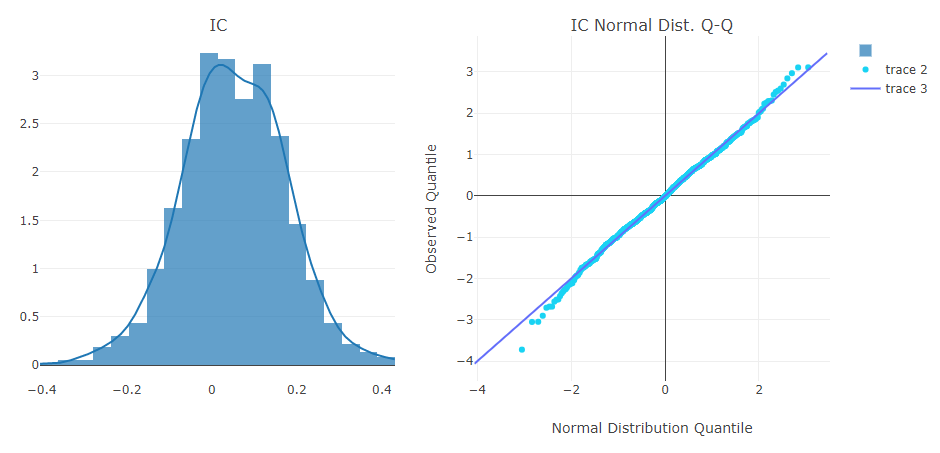
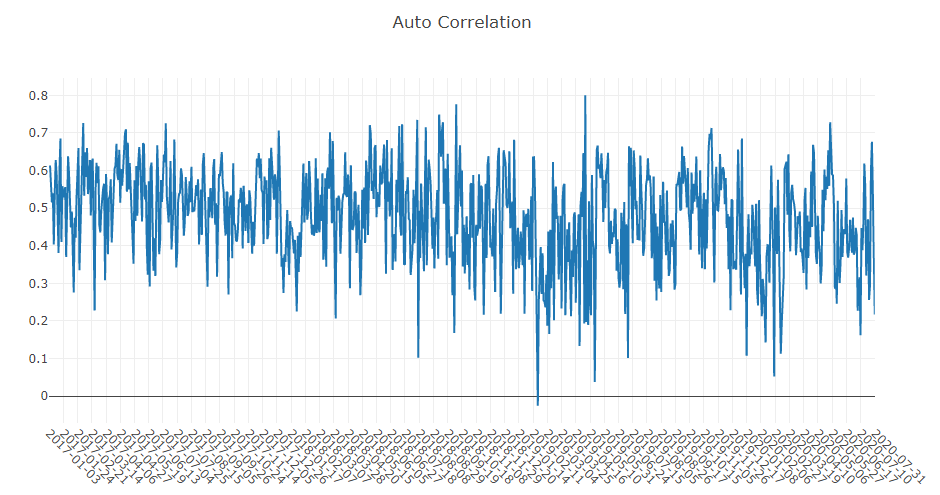
Análise de portfólio
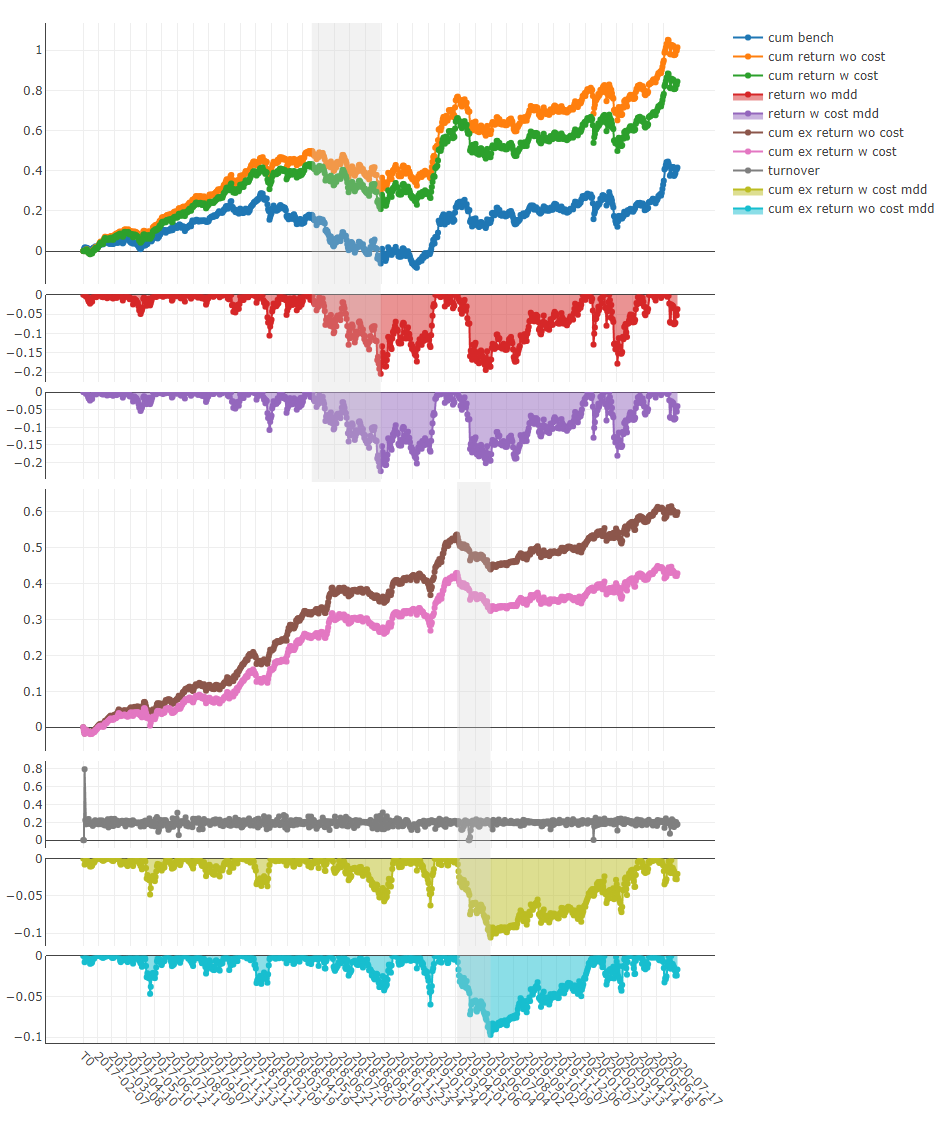
Explicação dos resultados acima
O fluxo de trabalho automático pode não ser adequado ao fluxo de trabalho de pesquisa de todos os pesquisadores Quant. Para apoiar um fluxo de trabalho flexível de pesquisa Quant, o Qlib também fornece uma interface modularizada para permitir que os pesquisadores construam seu próprio fluxo de trabalho por código. Aqui está uma demonstração do fluxo de trabalho de pesquisa Quant personalizado por código.
O investimento quantitativo é um cenário único, com muitos desafios importantes a serem resolvidos. Atualmente, a Qlib fornece algumas soluções para vários deles.
A previsão precisa da tendência dos preços das ações é uma parte muito importante para construir carteiras lucrativas. Porém, a enorme quantidade de dados com diversos formatos no mercado financeiro torna um desafio a construção de modelos de previsão.
Um número crescente de trabalhos/artigos de pesquisa SOTA Quant, que se concentram na construção de modelos de previsão para extrair sinais/padrões valiosos em dados financeiros complexos, são lançados no Qlib
Aqui está uma lista de modelos construídos em Qlib .
Seu PR de novos modelos Quant é muito bem-vindo.
O desempenho de cada modelo nos conjuntos de dados Alpha158 e Alpha360 pode ser encontrado aqui.
Todos os modelos listados acima podem ser executados com Qlib . Os usuários podem encontrar os arquivos de configuração que fornecemos e alguns detalhes sobre o modelo na pasta benchmarks. Mais informações podem ser recuperadas nos arquivos de modelo listados acima.
Qlib oferece três maneiras diferentes de executar um único modelo, os usuários podem escolher aquela que melhor se adapta aos seus casos:
Os usuários podem usar a ferramenta qrun mencionada acima para executar o fluxo de trabalho de um modelo com base em um arquivo de configuração.
Os usuários podem criar um script python workflow_by_code baseado naquele listado na pasta de examples .
Os usuários podem usar o script run_all_model.py listado na pasta de examples para executar um modelo. Aqui está um exemplo do comando shell específico a ser usado: python run_all_model.py run --models=lightgbm , onde os argumentos --models podem levar qualquer número de modelos listados acima (os modelos disponíveis podem ser encontrados em benchmarks). Para mais casos de uso, consulte a documentação do arquivo.
tensorflow==1.15.0 ) Qlib também fornece um script run_all_model.py que pode executar vários modelos para várias iterações. ( Nota : o script suporta apenas Linux por enquanto. Outros sistemas operacionais serão suportados no futuro. Além disso, ele também não suporta a execução paralela do mesmo modelo várias vezes, e isso também será corrigido no desenvolvimento futuro.)
O script criará um ambiente virtual exclusivo para cada modelo e excluirá os ambientes após o treinamento. Assim, apenas resultados de experimentos como IC e resultados backtest serão gerados e armazenados.
Aqui está um exemplo de execução de todos os modelos para 10 iterações:
python run_all_model . py run 10Ele também fornece a API para executar modelos específicos de uma só vez. Para mais casos de uso, consulte a documentação do arquivo.
Devido à natureza não estacionária do ambiente do mercado financeiro, a distribuição dos dados pode mudar em diferentes períodos, o que faz com que o desempenho dos modelos baseados em decaimentos de dados de treinamento nos dados de teste futuros. Portanto, adaptar os modelos/estratégias de previsão à dinâmica do mercado é muito importante para o desempenho do modelo/estratégias.
Aqui está uma lista de soluções criadas no Qlib .
O Qlib agora oferece suporte ao aprendizado por reforço, um recurso projetado para modelar decisões de investimento contínuas. Esta funcionalidade ajuda os investidores a otimizar as suas estratégias de negociação, aprendendo com as interações com o ambiente para maximizar alguma noção de recompensa cumulativa.
Aqui está uma lista de soluções construídas em Qlib categorizadas por cenários.
Aqui está a introdução deste cenário. Todos os métodos abaixo são comparados aqui.
O conjunto de dados desempenha um papel muito importante no Quant. Aqui está uma lista dos conjuntos de dados criados no Qlib :
| Conjunto de dados | Mercado dos EUA | Mercado chinês |
|---|---|---|
| Alfa360 | √ | √ |
| Alfa158 | √ | √ |
Aqui está um tutorial para construir um conjunto de dados com Qlib . Seu PR para construir um novo conjunto de dados Quant é muito bem-vindo.
Qlib é altamente personalizável e muitos de seus componentes podem ser aprendidos. Os componentes que podem ser aprendidos são instâncias do Forecast Model e Trading Agent . Eles são aprendidos com base na camada Learning Framework e depois aplicados a vários cenários na camada Workflow . A estrutura de aprendizagem também aproveita a camada Workflow (por exemplo, compartilhando Information Extractor , criando ambientes baseados em Execution Env ).
Com base nos paradigmas de aprendizagem, eles podem ser categorizados em aprendizagem por reforço e aprendizagem supervisionada.
Execution Env na camada Workflow para criar ambientes. É importante notar que NestedExecutor também é compatível. Isso permite que os usuários otimizem diferentes níveis de estratégias/modelos/agentes em conjunto (por exemplo, otimizando uma estratégia de execução de ordens para uma estratégia específica de gerenciamento de portfólio).Se você quiser dar uma olhada rápida nos componentes do qlib usados com mais frequência, você pode experimentar os notebooks aqui.
Os documentos detalhados estão organizados em docs. Sphinx e o tema readthedocs são necessários para construir a documentação em formatos html.
cd docs/
conda install sphinx sphinx_rtd_theme -y
# Otherwise, you can install them with pip
# pip install sphinx sphinx_rtd_theme
make htmlVocê também pode visualizar o documento mais recente diretamente online.
Qlib está em desenvolvimento ativo e contínuo. Nosso plano está no roteiro, que é gerenciado como um projeto no GitHub.
O servidor de dados do Qlib pode ser implantado no modo Offline ou no modo Online . O modo padrão é o modo offline.
No modo Offline , os dados serão implantados localmente.
No modo Online , os dados serão implantados como um serviço de dados compartilhado. Os dados e seu cache serão compartilhados por todos os clientes. Espera-se que o desempenho da recuperação de dados seja melhorado devido a uma taxa mais alta de acessos ao cache. Também consumirá menos espaço em disco. Os documentos do modo online podem ser encontrados no Qlib-Server. O modo online pode ser implantado automaticamente com scripts baseados na CLI do Azure. O código fonte do servidor de dados online pode ser encontrado no repositório Qlib-Server.
O desempenho do processamento de dados é importante para métodos baseados em dados, como tecnologias de IA. Como uma plataforma orientada para IA, Qlib fornece uma solução para armazenamento e processamento de dados. Para demonstrar o desempenho do servidor de dados Qlib, comparamos-o com diversas outras soluções de armazenamento de dados.
Avaliamos o desempenho de diversas soluções de armazenamento concluindo a mesma tarefa, que cria um conjunto de dados (14 características/fatores) a partir dos dados diários básicos do OHLCV de um mercado de ações (800 ações por dia de 2007 a 2020). A tarefa envolve consultas e processamento de dados.
| HDF5 | MySQL | MongoDB | InfluxoDB | Qlib -E -D | Qlib +E-D | Qlib +E +D | |
|---|---|---|---|---|---|---|---|
| Total (1CPU) (segundos) | 184,4±3,7 | 365,3±7,5 | 253,6±6,7 | 368,2±3,6 | 147,0±8,8 | 47,6±1,0 | 7,4±0,3 |
| Total (64CPU) (segundos) | 8,8±0,6 | 4,2±0,2 |
+(-)E indica com (out) ExpressionCache+(-)D indica com (out) DatasetCacheA maioria dos bancos de dados de uso geral leva muito tempo para carregar os dados. Depois de examinar a implementação subjacente, descobrimos que os dados passam por muitas camadas de interfaces e transformações desnecessárias de formato em soluções de banco de dados de uso geral. Essas sobrecargas retardam bastante o processo de carregamento de dados. Os dados Qlib são armazenados em um formato compacto, que é eficiente para ser combinado em matrizes para computação científica.
Qlib , crie solicitações pull.Junte-se a grupos de discussão de mensagens instantâneas:
| Gitter |
|---|
 |
Agradecemos todas as contribuições e agradecemos a todos os contribuidores!
Antes de lançarmos o Qlib como um projeto de código aberto no Github em setembro de 2020, o Qlib era um projeto interno do nosso grupo. Infelizmente, o histórico interno de commits não é mantido. Muitos membros do nosso grupo também contribuíram muito para o Qlib, que inclui Ruihua Wang, Yinda Zhang, Haisu Yu, Shuyu Wang, Bochen Pang e Dong Zhou. Especialmente graças a Dong Zhou devido à sua versão inicial do Qlib.
Este projeto aceita contribuições e sugestões.
Aqui estão alguns padrões de código e orientações de desenvolvimento para enviar uma solicitação pull.
Fazer contribuições não é uma coisa difícil. Resolver um problema (talvez apenas responder a uma questão levantada na lista de problemas ou no gitter), corrigir/emitir um bug, melhorar os documentos e até mesmo corrigir um erro de digitação são contribuições importantes para o Qlib.
Por exemplo, se quiser contribuir com o documento/código do Qlib, você pode seguir as etapas da figura abaixo.

Se você não sabe como começar a contribuir, consulte os exemplos a seguir.
| Tipo | Exemplos |
|---|---|
| Resolvendo problemas | Responda a uma pergunta; emitindo ou corrigindo um bug |
| Documentos | Melhorar a qualidade dos documentos; Corrigir um erro de digitação |
| Recurso | Implemente um recurso solicitado como este; Refatorar interfaces |
| Conjunto de dados | Adicionar um conjunto de dados |
| Modelos | Implementar um novo modelo, algumas instruções para contribuir com modelos |
Boas primeiras edições são rotuladas para indicar que é fácil iniciar suas contribuições.
Você pode encontrar alguma implementação perfeita no Qlib por rg 'TODO|FIXME' qlib
Se você gostaria de se tornar um dos mantenedores do Qlib para contribuir mais (por exemplo, ajudar a mesclar relações públicas, triagem de questões), entre em contato conosco por e-mail ([email protected]). Estamos felizes em ajudar a atualizar sua permissão.
A maioria das contribuições exige que você concorde com um Contrato de Licença de Colaborador (CLA), declarando que você tem o direito de nos conceder, e realmente nos concede, o direito de usar sua contribuição. Para obter detalhes, visite https://cla.opensource.microsoft.com.
Quando você envia uma solicitação pull, um bot CLA determinará automaticamente se você precisa fornecer um CLA e decorará o PR adequadamente (por exemplo, verificação de status, comentário). Basta seguir as instruções fornecidas pelo bot. Você só precisará fazer isso uma vez em todos os repositórios usando nosso CLA.
Este projeto adotou o Código de Conduta de Código Aberto da Microsoft. Para obter mais informações, consulte as Perguntas frequentes sobre o Código de Conduta ou entre em contato com [email protected] com perguntas ou comentários adicionais.


