local LLM with RAG
1.0.0

Este projeto é uma sandbox experimental para testar ideias relacionadas à execução de Large Language Models (LLMs) locais com Ollama para realizar Retrieval-Augmented Generation (RAG) para responder perguntas com base em amostras de PDFs. Neste projeto, também estamos usando o Ollama para criar embeddings com o texto nomic-embed para usar com o Chroma. Observe que os embeddings são recarregados sempre que o aplicativo é executado, o que não é eficiente e é feito aqui apenas para fins de teste.
Há também uma interface web criada usando Streamlit para fornecer uma maneira diferente de interagir com Ollama.
python3 -m venv .venv .source .venv/bin/activate no Unix ou MacOS, ou ..venvScriptsactivate no Windows.pip install -r requirements.txt . Nota: Na primeira vez que você executar o projeto, ele fará o download dos modelos necessários do Ollama para o LLM e embeddings. Este é um processo de configuração único e pode levar algum tempo dependendo da sua conexão com a Internet.
python app.py -m <model_name> -p <path_to_documents> para especificar um modelo e o caminho para os documentos. Se nenhum modelo for especificado, o padrão é mistral. Se nenhum caminho for especificado, o padrão será Research localizada no repositório para fins de exemplo.-e <embedding_model_name> . Se não for especificado, o padrão é nomic-embed-text. Isso carregará os PDFs e arquivos Markdown, gerará embeddings, consultará a coleção e responderá à pergunta definida em app.py .
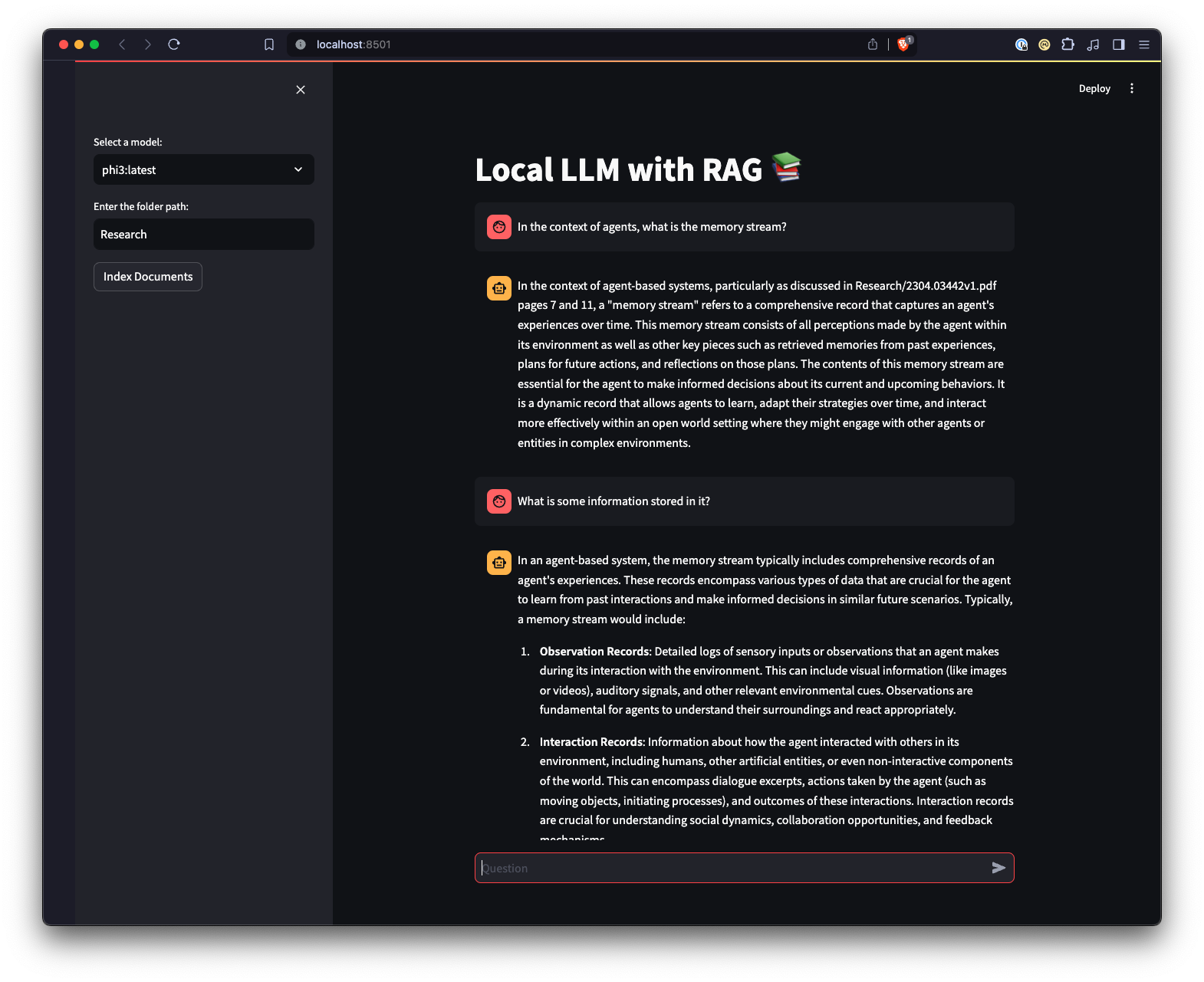
ui.pystreamlit run ui.py em seu terminal.Isso iniciará um servidor web local e abrirá uma nova guia em seu navegador padrão, onde você poderá interagir com o aplicativo. A UI Streamlit permite selecionar modelos, selecionar uma pasta, fornecendo uma maneira mais fácil e intuitiva de interagir com o sistema RAG chatbot em comparação com a interface de linha de comando. A aplicação cuidará do carregamento de documentos, gerando embeddings, consultando o acervo e exibindo os resultados de forma interativa.


