duplicut
v2.2 release
Hoje em dia, a criação de listas de palavras de senha geralmente implica concatenar múltiplas fontes de dados.
Idealmente, as senhas mais prováveis devem estar no início da lista de palavras, para que as senhas mais comuns sejam quebradas instantaneamente.
Com as ferramentas de desduplicação existentes, você é forçado a escolher se prefere preservar a ordem OU lidar com listas de palavras enormes .
Infelizmente, a criação da lista de palavras requer ambos :

Então escrevi duplicut em C altamente otimizado para atender a essa necessidade muito específica?
git clone https://github.com/nil0x42/duplicut
cd duplicut/ && make
./duplicut wordlist.txt -o clean-wordlist.txt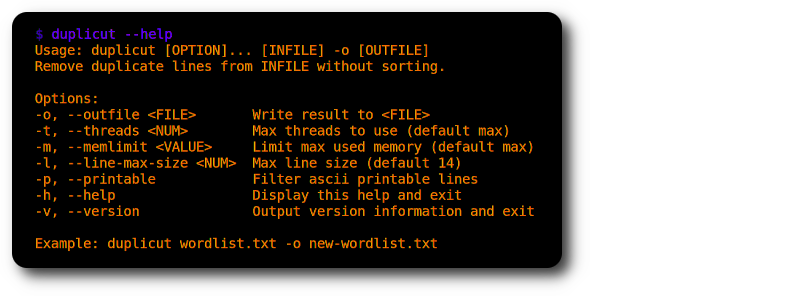
Características :
-l )-p )Implementação :
Limitações :
Um uint64 é suficiente para indexar linhas no hashmap, empacotando as informações size nos bits extras do ponteiro:
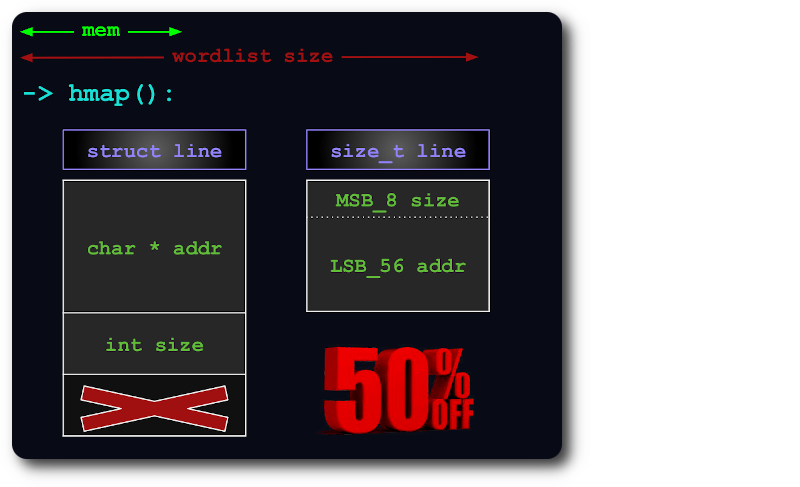
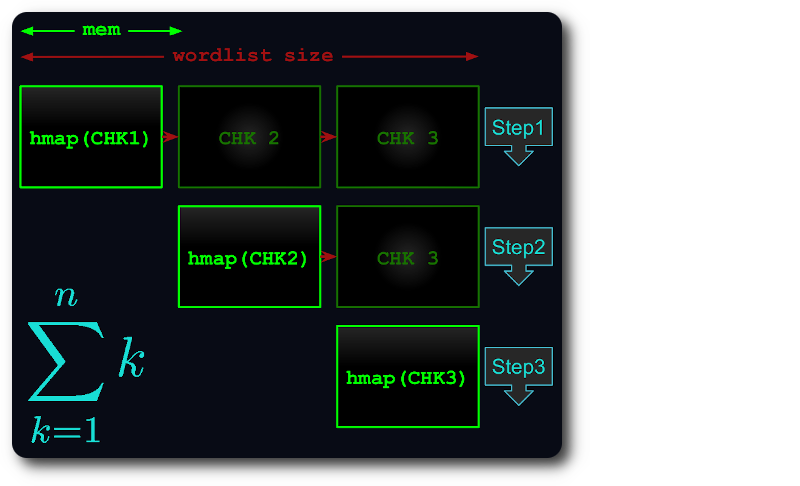
Se o arquivo inteiro não couber na memória, ele será dividido em pedaços virtuais, de forma que cada pedaço use o máximo de RAM possível.
Cada pedaço é então carregado no hashmap, desduplicado e testado em pedaços subsequentes.
Dessa forma, o tempo de execução diminui para no máximo o número do triângulo :
Se você encontrar um bug ou algo não funcionar conforme o esperado, compile o duplicut no modo de depuração e poste um problema com a saída anexada:
# debug level can be from 1 to 4
make debug level=1
./duplicut [OPTIONS] 2>&1 | tee /tmp/duplicut-debug.log


