LLaMA_MPS
1.0.0
Execute a inferência LLaMA (e Stanford-Alpaca) em GPUs Apple Silicon.
Como você pode ver, ao contrário de outros LLMs, o LLaMA não é tendencioso de forma alguma?
1. Clone este repositório
git clone https://github.com/jankais3r/LLaMA_MPS
2. Instale dependências Python
cd LLaMA_MPS
pip3 install virtualenv
python3 -m venv env
source env/bin/activate
pip3 install -r requirements.txt
pip3 install -e . 3. Baixe os pesos do modelo e coloque-os em uma pasta chamada models (por exemplo, LLaMA_MPS/models/7B )
4. (Opcional) Reestilhace os pesos do modelo (13B/30B/65B)
Como estamos executando a inferência em uma única GPU, precisamos mesclar os pesos dos modelos maiores em um único arquivo.
mv models/13B models/13B_orig
mkdir models/13B
python3 reshard.py 1 models/13B_orig models/13B5. Execute a inferência
python3 chat.py --ckpt_dir models/13B --tokenizer_path models/tokenizer.model --max_batch_size 8 --max_seq_len 256
As etapas acima permitirão que você execute inferência no modelo LLaMA bruto em modo de 'preenchimento automático'.
Se você quiser experimentar o modo 'instrução-resposta' semelhante ao ChatGPT usando os pesos ajustados do Stanford Alpaca, continue a configuração com as seguintes etapas:
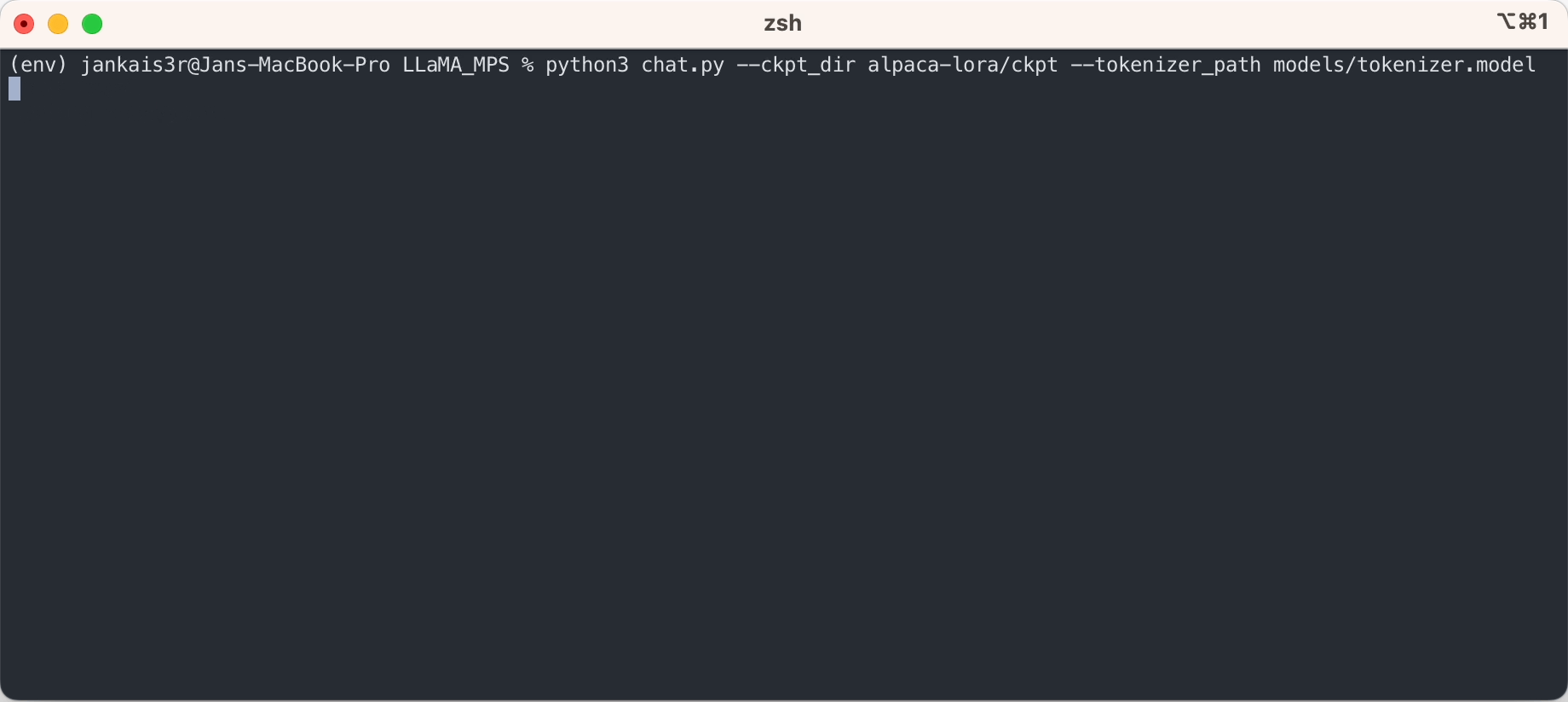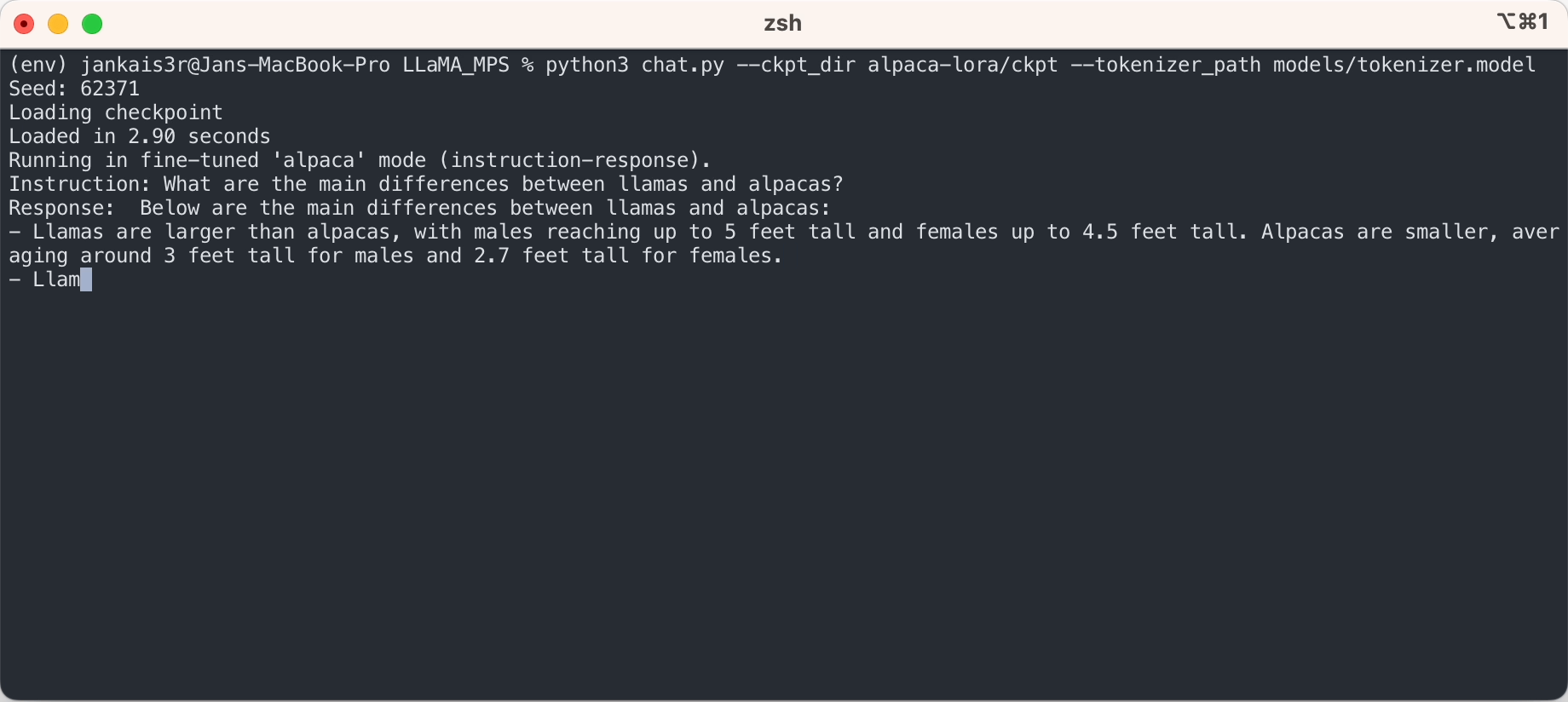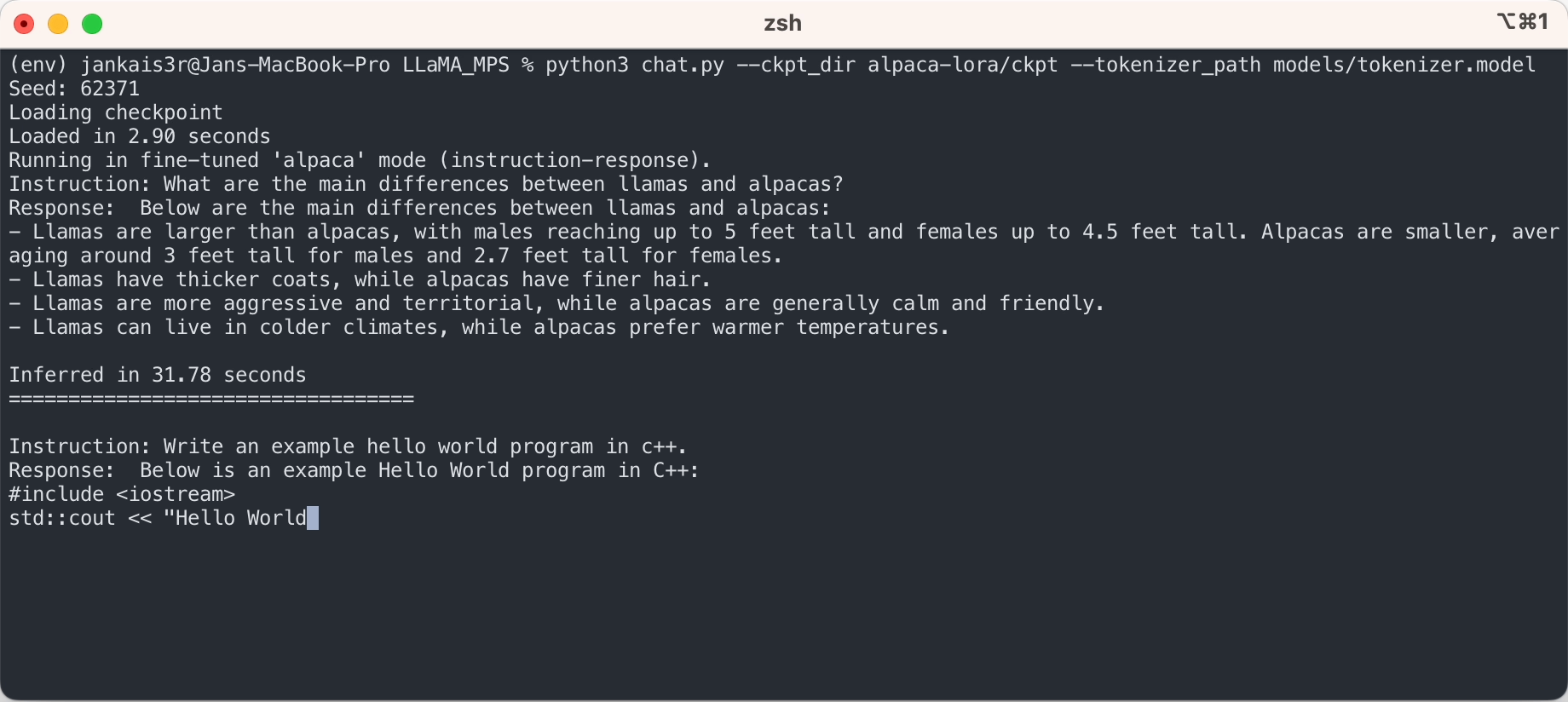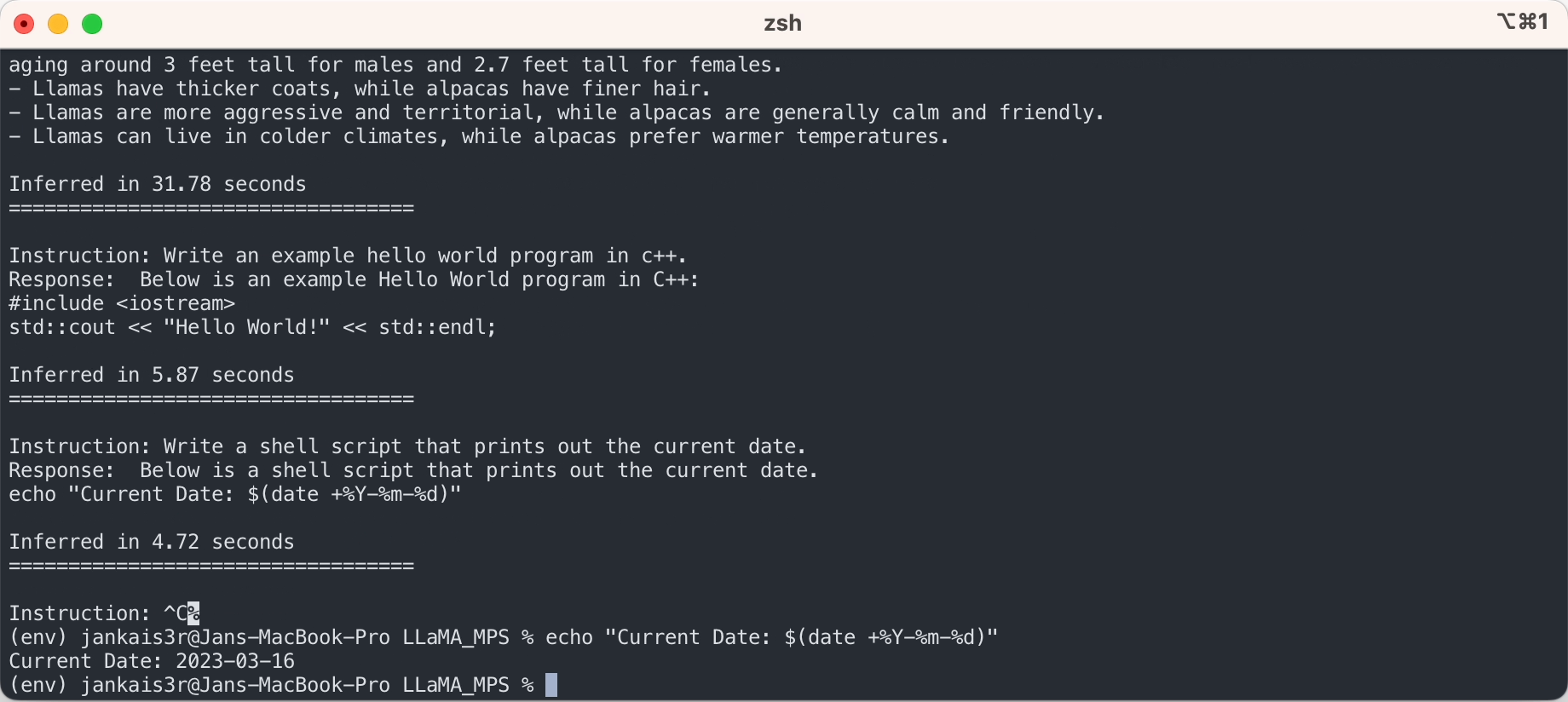
3. Baixe os pesos ajustados (disponíveis para 7B/13B)
python3 export_state_dict_checkpoint.py 7B
python3 clean_hf_cache.py4. Execute a inferência
python3 chat.py --ckpt_dir models/7B-alpaca --tokenizer_path models/tokenizer.model --max_batch_size 8 --max_seq_len 256
| Modelo | Iniciando a memória durante a inferência | Pico de memória durante a conversão do ponto de verificação | Pico de memória durante a reestilhaçamento |
|---|---|---|---|
| 7B | 16 GB | 14GB | N / D |
| 13B | 32 GB | 37GB | 45GB |
| 30B | 66 GB | 76 GB | 125GB |
| 65B | ?? GB | ?? GB | ?? GB |
Especificações mínimas por modelo (lento devido à troca):
Especificações recomendadas por modelo:
- max_batch_size
Se você tiver memória livre (por exemplo, ao executar o modelo 13B em um Mac de 64 GB), poderá aumentar o tamanho do lote usando o argumento --max_batch_size=32 . O valor padrão é 1 .
-max_seq_len
Para aumentar/diminuir o comprimento máximo do texto gerado, use o argumento --max_seq_len=256 . O valor padrão é 512 .
- use_repetition_penalty
O script de exemplo penaliza o modelo por gerar conteúdo repetitivo. Isso deve levar a resultados de maior qualidade, mas retarda um pouco a inferência. Execute o script com o argumento --use_repetition_penalty=False para desabilitar o algoritmo de penalidade.
A melhor alternativa ao LLaMA_MPS para usuários do Apple Silicon é llama.cpp, que é uma reimplementação C/C++ que executa a inferência puramente na parte CPU do SoC. Como o código C compilado é muito mais rápido que o Python, ele pode realmente superar essa implementação MPS em velocidade, porém ao custo de uma eficiência energética e térmica muito pior.
Veja a comparação abaixo ao decidir qual implementação se adapta melhor ao seu caso de uso.
| Implementação | Tempo total de execução – 256 tokens | Tokens/s | Uso máximo de memória | Temperatura máxima do SoC | Consumo máximo de energia do SoC | Tokens por 1 Wh |
|---|---|---|---|---|---|---|
| LAMA_MPS (13B fp16) | 75 segundos | 3.41 | 30GB | 79ºC | 10 W | 1.228,80 |
| lhama.cpp (13B fp16) | anos 70 | 3,66 | 25GB | 106ºC | 35 W | 376,16 |


