dream
v1.13.0
DeepPavlov Dream é uma plataforma para a criação de assistentes de IA generativos com múltiplas habilidades.
Para saber mais sobre a plataforma e como construir assistentes de IA com ela, visite Dream. Se você quiser saber mais sobre o DeepPavlov Agent que alimenta o Dream, visite a documentação do DeepPavlov Agent.
Já incluímos seis distribuições: quatro delas são baseadas no leve socialbot Deepy, uma é um chatbot Dream em tamanho real (baseado na versão Alexa Prize Challenge) em inglês e um chatbot Dream em russo.
Versão básica do assistente lunar. Deepy Base contém anotador de pré-processamento ortográfico, habilidade de manutenção de Harvesters baseada em modelo e habilidade de programa de domínio aberto baseada em AIML baseada no Dialog Flow Framework.
Versão avançada do assistente lunar. Deepy Advanced contém pré-processamento ortográfico, segmentação de frases, anotadores de vinculação de entidades e coletor de intenções, habilidade GoBot de manutenção de Harvesters para respostas orientadas a objetivos e habilidade de programa de domínio aberto baseada em AIML baseada no Dialog Flow Framework.
Versão FAQ do assistente lunar. Deepy FAQ contém anotador de pré-processamento ortográfico, habilidade de perguntas frequentes baseada em modelo e habilidade de programa de domínio aberto baseada em AIML baseada no Dialog Flow Framework.
Versão orientada para objetivos do assistente lunar. Deepy GoBot Base contém anotador de pré-processamento ortográfico, habilidade GoBot de manutenção de Harvesters para respostas orientadas a objetivos e habilidade de programa de domínio aberto baseada em AIML baseada no Dialog Flow Framework.
Versão completa do DeepPavlov Dream Socialbot. Esta é quase a mesma versão do socialbot DREAM do final do Alexa Prize Challenge 4. Alguns serviços API são substituídos por modelos treináveis. Alguns serviços (por exemplo, News Annotator, Game Skill, Weather Skill) exigem chaves privadas para APIs subjacentes, a maioria delas pode ser obtida gratuitamente. Se você quiser usar esses serviços em implantações locais, adicione suas chaves às variáveis ambientais (por exemplo, ./.env , ./.env_ru ). Esta versão do Dream Socialbot consome muitos recursos devido à sua arquitetura modular e objetivos originais (participação no Alexa Prize Challenge). Fornecemos uma demonstração do Dream Socialbot em nosso site.
Versão mini do DeepPavlov Dream Socialbot. Este é um socialbot baseado em geração que usa o modelo DialoGPT em inglês para gerar a maioria das respostas. Ele também contém componentes de captura e resposta de intenções para cobrir solicitações especiais do usuário. Link para a distribuição.
Versão russa do DeepPavlov Dream Socialbot. Este é um socialbot generativo que usa o DialoGPT russo da DeepPavlov para gerar a maioria das respostas. Ele também contém componentes de captura e resposta de intenções para cobrir solicitações especiais do usuário. Link para a distribuição.
Versão mini do DeepPavlov Dream Socialbot com o uso de modelos generativos baseados em prompts. Este é um socialbot generativo que usa grandes modelos de linguagem para gerar a maioria das respostas. Você pode fazer upload de seus próprios prompts (arquivos json) para common/prompts, adicionar nomes de prompts a PROMPTS_TO_CONSIDER (separados por vírgula) e as informações fornecidas serão usadas na geração de respostas com tecnologia LLM como um prompt. Link para a distribuição.
docker a partir de 20;docker-compose v1.29.2; git clone https://github.com/deeppavlov/dream.git
Se você receber um erro "Permissão negada" ao executar o docker-compose, certifique-se de configurar seu usuário do docker corretamente.
docker-compose -f docker-compose.yml -f assistant_dists/deepy_base/docker-compose.override.yml up --build
docker-compose -f docker-compose.yml -f assistant_dists/deepy_adv/docker-compose.override.yml up --build
docker-compose -f docker-compose.yml -f assistant_dists/deepy_faq/docker-compose.override.yml up --build
docker-compose -f docker-compose.yml -f assistant_dists/deepy_gobot_base/docker-compose.override.yml up --build
A maneira mais fácil de experimentar o Dream é implantá-lo via proxy. Todas as solicitações serão redirecionadas para a API DeepPavlov, para que você não precise usar nenhum recurso local. Consulte o uso de proxy para obter detalhes.
docker-compose -f docker-compose.yml -f assistant_dists/dream/docker-compose.override.yml -f assistant_dists/dream/dev.yml -f assistant_dists/dream/proxy.yml up --build
Observe que os componentes do DeepPavlov Dream requerem muitos recursos. Consulte a seção de componentes para ver os requisitos estimados.
docker-compose -f docker-compose.yml -f assistant_dists/dream/docker-compose.override.yml -f assistant_dists/dream/dev.yml up --build
Também incluímos uma configuração com alocações de GPU para ambientes multi-GPU:
AGENT_PORT=4242 docker-compose -f docker-compose.yml -f assistant_dists/dream/docker-compose.override.yml -f assistant_dists/dream/dev.yml -f assistant_dists/dream/test.yml up
Quando você precisar reiniciar um contêiner docker específico sem reconstruí-lo (certifique-se de que o mapeamento em assistant_dists/dream/dev.yml esteja correto):
AGENT_PORT=4242 docker-compose -f docker-compose.yml -f assistant_dists/dream/docker-compose.override.yml -f assistant_dists/dream/dev.yml restart container-name
docker-compose -f docker-compose.yml -f assistant_dists/dream_persona_prompted/docker-compose.override.yml -f assistant_dists/dream_persona_prompted/dev.yml -f assistant_dists/dream_persona_prompted/proxy.yml up --build
Também incluímos uma configuração com alocações de GPU para ambientes multi-GPU.
O DeepPavlov Agent oferece várias opções de interação: uma interface de linha de comando, uma API HTTP e um bot do Telegram
Em uma guia de terminal separada, execute:
docker-compose exec agent python -m deeppavlov_agent.run agent.channel=cmd agent.pipeline_config=assistant_dists/dream/pipeline_conf.json
Digite seu nome de usuário e converse com o Dream!
Depois de iniciar o bot, a API do agente do DeepPavlov será executada em http://localhost:4242 . Você pode aprender sobre a API nos documentos do agente DeepPavlov.
Uma interface básica de chat estará disponível em http://localhost:4242/chat .
Atualmente, o bot Telegram é implantado em vez da API HTTP. Edite a definição command agent dentro da configuração docker-compose.override.yml :
agent:
command: sh -c 'bin/wait && python -m deeppavlov_agent.run agent.channel=telegram agent.telegram_token=<TELEGRAM_BOT_TOKEN> agent.pipeline_config=assistant_dists/dream/pipeline_conf.json'
NOTA: trate seu token do Telegram como um segredo e não o envie para repositórios públicos!
O Dream usa vários arquivos de configuração do docker-compose:
./docker-compose.yml é a configuração principal que inclui contêineres para DeepPavlov Agent e banco de dados mongo;
./assistant_dists/*/docker-compose.override.yml lista todos os componentes da distribuição;
./assistant_dists/dream/dev.yml inclui ligações de volume para facilitar a depuração do Dream;
./assistant_dists/dream/proxy.yml é uma lista de contêineres com proxy.
Se os seus recursos de implantação forem limitados, você poderá substituir os contêineres pelas cópias em proxy hospedadas pelo DeepPavlov. Para fazer isso, substitua essas definições de contêiner dentro de proxy.yml , por exemplo:
convers-evaluator-annotator:
command: ["nginx", "-g", "daemon off;"]
build:
context: dp/proxy/
dockerfile: Dockerfile
environment:
- PROXY_PASS=proxy.deeppavlov.ai:8004
- SERVICE_PORT=8004
e inclua esta configuração em seu comando de implantação:
docker-compose -f docker-compose.yml -f assistant_dists/dream/docker-compose.override.yml -f assistant_dists/dream/dev.yml -f assistant_dists/dream/proxy.yml up --build
Por padrão, proxy.yml contém todas as definições de proxy disponíveis.
A Dream Architecture é apresentada na imagem a seguir: 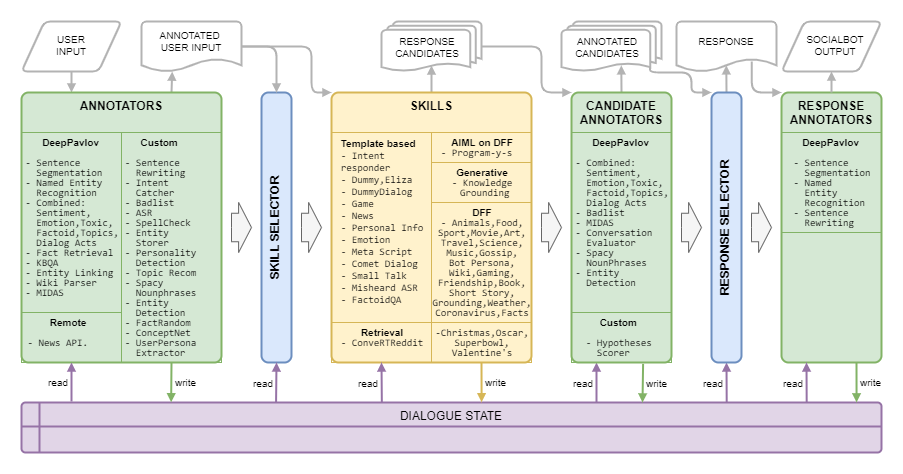
| Nome | Requisitos | Descrição |
|---|---|---|
| Seletor Baseado em Regras | Algoritmo que seleciona uma lista de habilidades para gerar respostas candidatas ao contexto atual com base em tópicos, entidades, emoções, toxicidade, atos de diálogo e histórico de diálogo | |
| Seletor de Resposta | 50 MB de RAM | Algoritmo que seleciona uma resposta final entre uma determinada lista de respostas candidatas |
| Nome | Requisitos | Descrição |
|---|---|---|
| RAS | 40 MB de RAM | calcula a confiança geral do ASR para uma determinada expressão e a classifica como muito baixa , baixa , média ou alta (para marcação da Amazon) |
| Palavras na lista incorreta | 150 MB de RAM | detecta palavras e frases da lista ruim |
| Classificação Combinada | 1,5 GB de RAM, 3,5 GB de GPU | Modelo baseado em BERT incluindo classificação de tópicos, classificação de atos de diálogo, sentimento, toxicidade, emoção, classificação factóide |
| Classificação Combinada leve | 1,6 GB de RAM | O mesmo modelo da Classificação Combinada, mas leva 42% menos tempo graças à estrutura mais leve |
| COMeT Atômico | 2 GB de RAM, 1,1 GB de GPU | Modelos de previsão de senso comum COMeT Atomic |
| COMeT ConceptNet | 2 GB de RAM, 1,1 GB de GPU | Modelos de previsão de senso comum COMeT ConceptNet |
| Anotador do avaliador Convers | 1 GB de RAM, 4,5 GB de GPU | é treinado com base nos dados do Prêmio Alexa de competições anteriores e prevê se a resposta do candidato é interessante, compreensível, relevante, envolvente ou errônea |
| Classificação Emocional | 2,5 GB de RAM | anotador de classificação de emoções |
| Detecção de entidade | 1,5 GB de RAM, 3,2 GB de GPU | extrai entidades e seus tipos de declarações |
| Vinculação de entidades | 2,5 GB de RAM, 1,3 GB de GPU | encontra IDs de entidades do Wikidata para as entidades detectadas com Detecção de Entidades |
| Armazenador de entidades | 220 MB de RAM | um componente baseado em regras, que armazena entidades das declarações do usuário e do socialbot se a expressão de opinião for detectada com padrões ou classificador MIDAS e as salva junto com a atitude detectada para o estado de diálogo |
| Fato Aleatório | 50 MB de RAM | retorna fatos aleatórios para uma determinada entidade (para entidades da expressão do usuário) |
| Recuperação de fatos | 7,4 GB de RAM, 1,2 GB de GPU | extrai fatos da Wikipedia e wikiHow |
| Apanhador de Intenções | 1,7 GB de RAM, 2,4 GB de GPU | classifica as declarações do usuário em uma série de intenções predefinidas que são treinadas em um conjunto de frases e expressões regulares |
| KBQA | 2 GB de RAM, 1,4 GB de GPU | responde às perguntas factóides do usuário com base no Wikidata KB |
| Classificação MIDAS | 1,1 GB de RAM, 4,5 GB de GPU | Modelo baseado em BERT treinado em um subconjunto de classes semânticas do conjunto de dados MIDAS |
| Preditor MIDAS | 30 MB de RAM | Modelo baseado em BERT treinado em um subconjunto de classes semânticas do conjunto de dados MIDAS |
| NER | 2,2 GB de RAM, 5 GB de GPU | extrai nomes de pessoas, nomes de locais e organizações de texto sem maiúsculas e minúsculas |
| Anotador da API de notícias | 80 MB de RAM | extrai as últimas notícias sobre entidades ou temas usando a API GNews. As implantações do DeepPavlov Dream utilizam nossa própria chave de API. |
| Apanhador de Personalidade | 30 MB de RAM | a habilidade é alterar a descrição da personalidade do sistema através da interface de bate-papo, funciona como um comando do sistema, a resposta é uma mensagem semelhante ao sistema |
| Seletor de prompt | 50 MB de RAM | Anotador utilizando o Sentence Ranker para classificar os prompts e selecionar N_SENTENCES_TO_RETURN prompts mais relevantes (com base nas perguntas fornecidas nos prompts) |
| Extração de propriedade | 6,3 GB de RAM | extrai atributos do usuário de declarações |
| Palavras-chave de rake | 40 MB de RAM | extrai palavras-chave de enunciados com a ajuda do algoritmo RAKE |
| Extrator de Persona Relativa | 50 MB de RAM | Anotador utilizando o Sentence Ranker para classificar frases pessoais e selecionar N_SENTENCES_TO_RETURN as frases mais relevantes |
| Sentrewrite | 200 MB de RAM | reescreve as declarações do usuário substituindo pronomes por nomes específicos que fornecem informações mais úteis para componentes posteriores |
| Sentseg | 1 GB de RAM | nos permite lidar com declarações longas e complexas do usuário, dividindo-as em frases e recuperando a pontuação |
| Frases nominais espaçosas | 180 MB de RAM | extrai substantivos usando Spacy e filtra os genéricos |
| Classificador de função de fala | 1,1 GB de RAM, 4,5 GB de GPU | um algoritmo hierárquico baseado em vários modelos lineares e uma abordagem baseada em regras para a previsão de funções de fala descritas por Eggins e Slade |
| Preditor de Função de Fala | 1,1 GB de RAM, 4,5 GB de GPU | produz probabilidades de funções de fala que podem seguir uma função de fala prevista pelo Classificador de Função de Fala |
| Pré-processamento ortográfico | 50 MB de RAM | componente baseado em padrões para reescrever diferentes expressões coloquiais para um estilo de conversa mais formal |
| Recomendação de tópico | 40 MB de RAM | oferece um tópico para conversa adicional usando as informações sobre os tópicos discutidos e as preferências do usuário. A versão atual é baseada em personalidades do Reddit (veja Dream Report para Alexa Prize 4). |
| Classificação tóxica | 3,5 GB de RAM, 3 GB de GPU | Modelo de classificação tóxica de Transformers especificado como PRETRAINED_MODEL_NAME_OR_PATH |
| Extrator de Persona do Usuário | 40 MB de RAM | determina a qual categoria de idade o usuário pertence com base em algumas palavras-chave |
| Analisador de wikis | 100 MB de RAM | extrai trigêmeos do Wikidata para as entidades detectadas com Entity Linking |
| Fatos Wiki | 1,7 GB de RAM | modelo que extrai fatos relacionados das páginas da Wikipedia e WikiHow |
| Nome | Requisitos | Descrição |
|---|---|---|
| DialoGPT | 1,2 GB de RAM, 2,1 GB de GPU | serviço generativo baseado no modelo generativo de Transformers, o modelo é definido no argumento de composição do docker PRETRAINED_MODEL_NAME_OR_PATH (por exemplo, microsoft/DialoGPT-small com 0,2-0,5 segundos na GPU) |
| DialoGPT baseado em Persona | 1,2 GB de RAM, 2,1 GB de GPU | serviço generativo baseado no modelo generativo de Transformers, o modelo foi pré-treinado no conjunto de dados PersonaChat para gerar uma resposta condicionada a várias frases da persona do socialbot |
| Legendagem de imagens | 4 GB de RAM, 5,4 GB de GPU | cria representação de texto de uma imagem recebida |
| Preenchimento | 1 GB de RAM, 1,2 GB de GPU | (desativado, mas o código está disponível) serviço generativo baseado no modelo Infilling, para o enunciado fornecido retorna o enunciado onde _ do texto original é substituído por tokens gerados |
| Fundamento do Conhecimento | 2 GB de RAM, 2,1 GB de GPU | serviço generativo baseado na arquitetura BlenderBot que fornece uma resposta ao contexto levando em consideração um parágrafo de texto adicional |
| LM mascarado | 1,1 GB de RAM, 1 GB de GPU | (desativado, mas o código está disponível) |
| Seq2seq baseado em Persona | 1,5 GB de RAM, 1,5 GB de GPU | serviço generativo baseado no modelo Transformers seq2seq, o modelo foi pré-treinado no conjunto de dados PersonaChat para gerar uma resposta condicionada a várias frases da persona do socialbot |
| Classificador de frases | 1,2 GB de RAM, 2,1 GB de GPU | modelo de classificação fornecido como PRETRAINED_MODEL_NAME_OR_PATH que para um par de sentenças retorna uma pontuação flutuante de correspondência |
| HistóriaGPT | 2,6 GB de RAM, 2,15 GB de GPU | serviço generativo baseado em GPT-2 ajustado, para um determinado conjunto de palavras-chave retorna um conto usando as palavras-chave |
| GPT-3.5 | 100 MB de RAM | serviço generativo baseado no serviço OpenAI API, o modelo é definido no argumento docker compose PRETRAINED_MODEL_NAME_OR_PATH (em particular, neste serviço, text-davinci-003 é usado. |
| Bate-papoGPT | 100 MB de RAM | serviço generativo baseado no serviço API OpenAI, o modelo é definido no argumento docker compose PRETRAINED_MODEL_NAME_OR_PATH (em particular, neste serviço, gpt-3.5-turbo é usado. |
| Prompt HistóriaGPT | 3 GB de RAM, 4 GB de GPU | serviço generativo baseado em GPT-2 ajustado, para um determinado tópico representado por um substantivo retorna um conto sobre um determinado tópico |
| GPT-J 6B | 1,5 GB de RAM, 24,2 GB de GPU | serviço generativo baseado no modelo generativo de Transformers, o modelo é definido no argumento docker compose PRETRAINED_MODEL_NAME_OR_PATH (em particular, neste serviço, o modelo GPT-J é usado. |
| FLORZ 7B | 2,5 GB de RAM, 29 GB de GPU | serviço generativo baseado no modelo generativo de Transformers, o modelo é definido no argumento docker compose PRETRAINED_MODEL_NAME_OR_PATH (em particular, neste serviço, o modelo BLOOMZ-7b1 é usado. |
| GPT-JT 6B | 2,5 GB de RAM, 25,1 GB de GPU | serviço generativo baseado no modelo generativo de Transformers, o modelo é definido no argumento docker compose PRETRAINED_MODEL_NAME_OR_PATH (em particular, neste serviço, o modelo GPT-JT é usado. |
| Nome | Requisitos | Descrição |
|---|---|---|
| Manipulador Alexa | 30 MB de RAM | manipulador para vários comandos específicos do Alexa |
| Habilidade de Natal | 30 MB de RAM | oferece suporte a perguntas frequentes, fatos e scripts para o Natal |
| Habilidade de Diálogo Cometa | 300 MB de RAM | usa o modelo COMeT ConceptNet para expressar uma opinião, fazer uma pergunta ou comentar sobre as ações do usuário mencionadas no diálogo |
| Converter Reddit | 1,2 GB de RAM | usa um codificador ConveRT para construir representações eficientes para frases |
| Habilidade fictícia | uma parte do contêiner do agente | uma habilidade alternativa com múltiplas respostas candidatas não tóxicas |
| Caixa de diálogo de habilidade fictícia | 600 MB de RAM | retorna o próximo turno do conjunto de dados de bate-papo tópico se a resposta do usuário à habilidade fictícia for semelhante à resposta correspondente nos dados de origem |
| Elizabeth | 30 MB de RAM | Bot de bate-papo (https://github.com/wadetb/eliza) |
| Habilidade Emocional | 40 MB de RAM | retorna respostas de modelo para emoções detectadas pela Classificação de Emoções do anotador de Classificação Combinada |
| Controle de qualidade factóide | 170 MB de RAM | responde a perguntas factóides |
| Habilidade cooperativa de jogo | 100 MB de RAM | fornece ao usuário uma conversa sobre jogos de computador: os gráficos dos melhores jogos do ano passado, do mês passado e da semana passada |
| Habilidade de manutenção de colheitadeiras | 30 MB de RAM | Habilidade de manutenção de colheitadeiras |
| Habilidade Gobot de manutenção de colheitadeiras | 30 MB de RAM | Manutenção de colheitadeiras Habilidade orientada a objetivos |
| Habilidade de fundamentação do conhecimento | 100 MB de RAM | gera uma resposta com base no histórico do diálogo e no conhecimento fornecido relacionado ao tópico atual da conversa |
| Habilidade de MetaScript | 150 MB de RAM | fornece um diálogo multifacetado em torno das atividades humanas. A habilidade usa o modelo COMeT Atomic para gerar descrições e perguntas de bom senso sobre vários aspectos |
| Ouvi mal ASR | 40 MB de RAM | usa as anotações do processador ASR para fornecer feedback ao usuário quando a confiança do ASR é muito baixa |
| Habilidade da API de notícias | 60 MB de RAM | apresenta as últimas notícias mais bem avaliadas sobre entidades ou tópicos usando a API GNews |
| Habilidade do Oscar | 30 MB de RAM | oferece suporte a perguntas frequentes, fatos e roteiros do Oscar |
| Habilidade de informações pessoais | 40 MB de RAM | consulta e armazena o nome, local de nascimento e localização do usuário |
| Habilidade do Programa DFF Y | 800 MB de RAM | [Nova versão DFF] Chatbot Programa Y (https://github.com/keiffster/program-y) adaptado para Dream socialbot |
| Programa DFF Y Habilidade Perigosa | 100 MB de RAM | [Nova versão DFF] Chatbot Programa Y (https://github.com/keiffster/program-y) adaptado para Dream socialbot, contendo respostas a situações perigosas em um diálogo |
| Programa DFF Y Ampla Habilidade | 110 MB de RAM | [Nova versão DFF] Chatbot Programa Y (https://github.com/keiffster/program-y) adaptado para Dream socialbot, que inclui apenas modelos muito gerais (com menor confiança) |
| Habilidade de conversa fiada | 35 MB de RAM | faz perguntas usando roteiros escritos à mão para 25 tópicos, incluindo, entre outros, amor, esportes, trabalho, animais de estimação, etc. |
| Habilidade do SuperBowl | 30 MB de RAM | oferece suporte a perguntas frequentes, fatos e scripts para SuperBowl |
| Controle de qualidade de texto | 1,8 GB de RAM, 2,8 GB de GPU | O serviço encontra a resposta de uma pergunta factóide no texto. |
| Habilidade do Dia dos Namorados | 30 MB de RAM | oferece suporte a perguntas frequentes, fatos e scripts para o Dia dos Namorados |
| Habilidade de discagem do Wikidata | 100 MB de RAM | gera um enunciado usando trigêmeos do Wikidata. Não ativado, precisa de melhorias |
| Habilidade de Animais DFF | 200 MB de RAM | é criado usando DFF e possui três ramos de conversa sobre animais: animais de estimação do usuário, animais de estimação do socialbot e animais selvagens |
| Habilidade Artística DFF | 100 MB de RAM | Habilidade baseada em DFF para discutir arte |
| Habilidade do livro DFF | 400 MB de RAM | [Nova versão DFF] detecta títulos de livros e autores mencionados na expressão do usuário com a ajuda do analisador Wiki e link de entidade e recomenda livros aproveitando informações do banco de dados GoodReads |
| Habilidade de personalidade do bot DFF | 150 MB de RAM | tem como objetivo discutir os favoritos dos usuários e 20 coisas mais populares com histórias curtas expressando a opinião do socialbot em relação a eles |
| Habilidade de Coronavírus DFF | 110 MB de RAM | [Nova versão DFF] recupera dados sobre o número de casos e mortes por coronavírus em diferentes locais, provenientes do Centro de Ciência e Engenharia de Sistemas da Universidade John Hopkins |
| Habilidade Alimentar DFF | 150 MB de RAM | construído com DFF para incentivar conversas relacionadas à alimentação |
| Habilidade de Amizade DFF | 100 MB de RAM | [Nova versão DFF] Habilidade baseada em DFF para cumprimentar o usuário no início da caixa de diálogo e encaminhar o usuário para alguma habilidade com script |
| Habilidade Funfact DFF | 100 MB de RAM | [Nova versão DFF] Conta curiosidades ao usuário |
| Habilidade de jogo DFF | 80 MB de RAM | fornece uma discussão sobre videogames. Gaming Skill é para uma conversa mais geral sobre videogames |
| Habilidade de fofoca DFF | 95 MB de RAM | Habilidade baseada em DFF para discutir outras pessoas com notícias sobre elas |
| Habilidade de imagem DFF | 100 MB de RAM | [Nova versão DFF] Habilidade com script que se baseia nas respostas de legendas de imagens enviadas (de anotações) com respostas específicas em caso de alimentos, animais ou pessoas detectadas e respostas padrão caso contrário |
| Habilidade de modelo DFF | 50 MB de RAM | [Nova versão DFF] Habilidade baseada em DFF que fornece um exemplo de uso de DFF |
| Habilidade solicitada pelo modelo DFF | 50 MB de RAM | [Nova versão DFF] Habilidade baseada em DFF que fornece respostas geradas pelo modelo de linguagem com base em prompts especificados e no contexto do diálogo. O modelo a ser utilizado é especificado em GENERATIVE_SERVICE_URL. Por exemplo, você pode usar o serviço Transformer LM GPTJ. |
| Habilidade de aterramento DFF | 90 MB de RAM | [Nova versão DFF] Habilidade baseada em DFF para responder qual é o tópico da conversa, para gerar reconhecimento, para gerar respostas universais em alguns atos de diálogo do MIDAS |
| Respondente de intenção DFF | 100 MB de RAM | [Nova versão DFF] fornece respostas baseadas em modelos para algumas das intenções detectadas pelo anotador Intent Catcher |
| Habilidade de filme DFF | 1,1 GB de RAM | é implementado usando DFF e cuida das conversas relacionadas a filmes |
| Habilidade Musical DFF | 70 MB de RAM | Habilidade baseada em DFF para discutir música |
| Habilidade Científica DFF | 90 MB de RAM | Habilidade baseada em DFF para discutir ciência |
| Habilidade de conto curto DFF | 90 MB de RAM | [Nova versão DFF] conta histórias curtas do usuário em 3 categorias: (1) histórias para dormir, como fábulas e histórias morais, (2) histórias de terror e (3) histórias engraçadas |
| Habilidade Esportiva DFF | 70 MB de RAM | Habilidade baseada em DFF para discutir esportes |
| Habilidade de viagem DFF | 70 MB de RAM | Habilidade baseada em DFF para discutir viagens |
| Habilidade Meteorológica DFF | 1,4 GB de RAM | [Nova versão DFF] usa o serviço OpenWeatherMap para obter a previsão da localização do usuário |
| Habilidade Wiki DFF | 150 MB de RAM | utilizado para confecção de cenários com extração de entidades, preenchimento de slots, inserção de fatos e agradecimentos |
| Nome | Requisitos | Descrição |
|---|---|---|
| Habilidade de perguntas frequentes sobre IA | 150 MB de RAM | [Nova versão DFF] Tudo o que você queria saber sobre IA moderna, mas tinha medo de perguntar! Este FAQ Assistant conversa com você enquanto explica os tópicos mais simples do mundo tecnológico atual. |
| Habilidade de estilista de moda | 150 MB de RAM | [Nova versão DFF] Fique protegido em todas as estações com o Assistente de Roupas da Costa Industries! Experimente o máximo conforto e proteção, independentemente do clima. Fique aquecido no inverno... |
| Habilidade de Personagem de Sonho | 150 MB de RAM | [Nova versão DFF] Habilidade baseada em prompt que utiliza determinado serviço generativo para gerar respostas com base no prompt fornecido |
| Habilidade de marketing | 150 MB de RAM | [Nova versão DFF] Conecte-se com seu público como nunca antes com o Marketing AI Assistant! Alcance novos patamares de sucesso explorando o poder da empatia. Diga adeus.. |
| Habilidade de conto de fadas | 150 MB de RAM | [Nova versão DFF] Este assistente contará a você ou a seus filhos um conto de fadas curto, mas envolvente. Escolha os personagens e o tema e deixe o resto para a imaginação da IA. |
| Habilidade Nutricional | 150 MB de RAM | [Nova versão DFF] Descubra o segredo para uma alimentação saudável com nosso assistente de IA! Encontre opções de alimentos nutritivos para você e seus entes queridos com facilidade. Diga adeus ao estresse da hora das refeições e olá às delícias... |
| Habilidade de coaching de vida | 150 MB de RAM | [Nova versão DFF] Desbloqueie todo o seu potencial com o assistente de IA patenteado da Rhodes & Co! Alcance o desempenho máximo no trabalho e em casa. Entre em sua melhor forma sem esforço e inspire outras pessoas. |
Kuratov Y. e outros. Relatório técnico DREAM para o Alexa Prize 2019 //Alexa Prize Proceedings. – 2020.
Baymurzina D. et al. Relatório Técnico DREAM para o Prêmio Alexa 4 //Proceedings do Prêmio Alexa. – 2021.
DeepPavlov Dream está licenciado sob Apache 2.0.
O programa-y (ver dream/skills/dff_program_y_skill , dream/skills/dff_program_y_wide_skill , dream/skills/dff_program_y_dangerous_skill ) é licenciado sob Apache 2.0. Eliza (ver dream/skills/eliza ) é licenciada sob licença MIT.
Para fazer a certificação xlsx - arquivo com respostas de bot, você pode usar o script xlsx_responder.py executando
docker-compose -f docker-compose.yml -f dev.yml exec -T -u $( id -u ) agent python3
utils/xlsx_responder.py --url http://0.0.0.0:4242
--input ' tests/dream/test_questions.xlsx '
--output ' tests/dream/output/test_questions_output.xlsx '
--cache tests/dream/output/test_questions_output_ $( date --iso-8601=seconds ) .json Certifique-se de que todos os serviços estejam implantados. --input - arquivo xlsx com perguntas de certificação, --output - arquivo xlsx com respostas do bot, --cache - json , que contém uma marcação detalhada e é usado para um cache.


