Seq2seq Chatbot for Keras
1.0.0
Este repositório contém um novo modelo generativo de chatbot baseado na modelagem seq2seq. Mais detalhes sobre este modelo podem ser encontrados na Seção 3 do artigo End-to-end Adversarial Learning for Generative Conversational Agents. No caso de publicação utilizando ideias ou trechos de código deste repositório, por favor, cite este artigo.
O modelo treinado disponível aqui utilizou um pequeno conjunto de dados composto por ~8K pares de contexto (as duas últimas declarações do diálogo até o ponto atual) e respectiva resposta. Os dados foram coletados a partir de diálogos de cursos de inglês online. Este modelo treinado pode ser ajustado usando um conjunto de dados de domínio fechado para aplicações do mundo real.
O modelo canônico seq2seq tornou-se popular na tradução automática neural, tarefa que possui diferentes distribuições de probabilidade a priori para as palavras pertencentes às sequências de entrada e saída, uma vez que os enunciados de entrada e saída são escritos em idiomas diferentes. A arquitetura apresentada aqui assume as mesmas distribuições anteriores para palavras de entrada e saída. Portanto, ele compartilha uma camada de incorporação (incorporação de palavras pré-treinadas por luva) entre os processos de codificação e decodificação por meio da adoção de um novo modelo. Para melhorar a sensibilidade ao contexto, o vetor de pensamento (ou seja, a saída do codificador) codifica as duas últimas declarações da conversa até o ponto atual. Para evitar o esquecimento do contexto durante a geração da resposta, o vetor de pensamento é concatenado a um vetor denso que codifica a resposta incompleta gerada até o ponto atual. O vetor resultante é fornecido para camadas densas que prevêem o token atual da resposta. Consulte a Seção 3.1 do nosso artigo para uma melhor visão das vantagens do nosso modelo.
O algoritmo itera incluindo o token previsto na resposta incompleta e devolvendo-o à camada de entrada do lado direito do modelo mostrado abaixo.
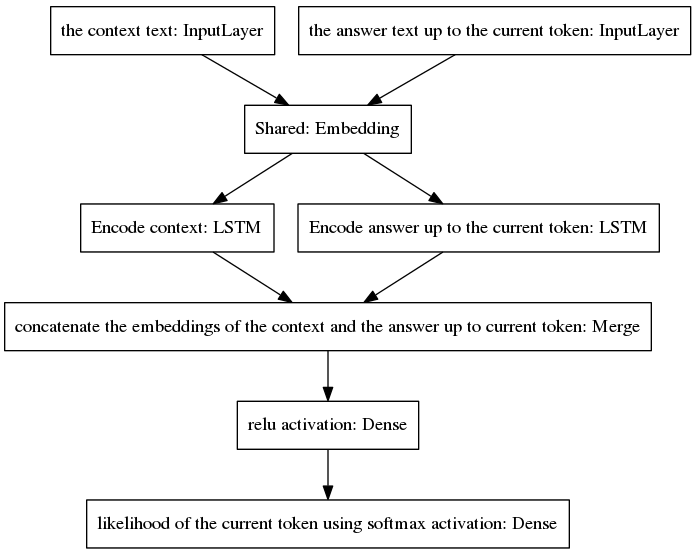
Como pode ser visto na figura acima, os dois LSTMs estão dispostos em paralelo, enquanto o seq2seq canônico possui as camadas recorrentes de codificador e decodificador dispostas em série. Camadas recorrentes são desdobradas durante a retropropagação ao longo do tempo, resultando em um grande número de funções aninhadas e, portanto, em um maior risco de desaparecimento do gradiente, que é agravado pela cascata de camadas recorrentes do modelo canônico seq2seq, mesmo no caso de arquiteturas fechadas como os LSTMs. Acredito que esta seja uma das razões pelas quais meu modelo se comporta melhor durante o treinamento do que o seq2seq canônico.
O pseudocódigo a seguir explica o algoritmo.

A formação deste novo modelo converge em poucas épocas. Usando nosso conjunto de dados de exemplos de treinamento de 8K, foram necessários apenas 100 épocas para atingir a perda categórica de entropia cruzada de 0,0318, ao custo de 139 s/época rodando em uma GPU GTX980. O desempenho deste modelo treinado (fornecido neste repositório) parece tão convincente quanto o desempenho de um modelo vanilla seq2seq treinado nos ~ 300 mil exemplos de treinamento do Cornell Movie Dialogs Corpus, mas requer muito menos esforço computacional para treinar.
Para conversar com o modelo pré-treinado:
Baixe o arquivo python "conversation.py", o arquivo de vocabulário "vocabulary_movie" e os pesos líquidos "my_model_weights20", que podem ser encontrados aqui;
Execute conversa.py.
Para conversar com o novo modelo treinado por nosso novo algoritmo de treinamento baseado em GAN:
Baixe o arquivo python "conversation_discriminator.py", o arquivo de vocabulário "vocabulary_movie" e os pesos líquidos "my_model_weights20.h5", "my_model_weights.h5" e "my_model_weights_discriminator.h5", que podem ser encontrados aqui;
Execute conversa_discriminator.py.
Este modelo apresenta melhor desempenho utilizando os mesmos dados de treinamento. O discriminador do modelo baseado em GAN é usado para selecionar a melhor resposta entre dois modelos, um treinado por força do professor e outro treinado pelo nosso novo método de treinamento semelhante ao GAN, cujos detalhes podem ser encontrados neste artigo.
Para treinar um novo modelo ou ajustar seus próprios dados:
Se você quiser treinar do zero, exclua o arquivo my_model_weights20.h5. Para ajustar seus dados, guarde este arquivo;
Baixe a pasta Glove 'glove.6B' e inclua esta pasta no diretório do chatbot (você pode encontrar esta pasta aqui). Este algoritmo aplica a aprendizagem por transferência usando uma incorporação de palavras pré-treinadas, que é ajustada durante o treinamento;
Execute split_qa.py para dividir o conteúdo dos seus dados de treinamento em dois arquivos: 'context' e 'answers' e get_train_data.py para armazenar as frases preenchidas nos arquivos 'Padded_context' e 'Padded_answers';
Execute train_bot.py para treinar o chatbot (recomenda-se o uso de GPU, para isso digite: THEANO_FLAGS=mode=FAST_RUN,device=gpu,floatX=float32,exception_verbosity=high python train_bot.py);
Nomeie seus dados de treinamento como "data.txt". Este arquivo deve conter uma expressão de diálogo por linha. Se o seu conjunto de dados for grande, defina a variável num_subsets (na linha 29 de train_bot.py) para um número maior.
pesos_file = 'meu_modelo pesos20.h5' pesos_file_GAN = 'meu_model_pesos.h5' pesos_file_discrim = 'meu_model_pesos_discriminator.h5'
Uma boa visão geral das implementações atuais de modelos conversacionais neurais para diferentes estruturas (junto com alguns resultados) pode ser encontrada aqui.
Nosso modelo pode ser aplicado a outras tarefas de PNL, como resumo de texto, veja por exemplo Alternativa 2: Modelo Recursivo A. Encorajamos a aplicação de nosso modelo em outras tarefas, neste caso, pedimos gentilmente que cite nosso trabalho como puder. ser visto neste documento, registrado em julho de 2017.
Esses códigos podem ser executados no Ubuntu 14.04.3 LTS, Python 2.7.6, Theano 0.9.0 e Keras 2.0.4. A utilização de outra configuração pode exigir algumas pequenas adaptações.


