MoEL
1.0.0


Esta é a implementação PyTorch do artigo:
MoEL: Mistura de Ouvintes Empáticos . Zhaojiang Lin , Andrea Madotto, Jamin Shin, Peng Xu, Pascale Fung EMNLP 2019 [PDF]
Este código foi escrito usando PyTorch >= 0.4.1. Se você usar algum código-fonte ou conjunto de dados incluído neste kit de ferramentas em seu trabalho, cite o artigo a seguir. O bibtex está listado abaixo:
@artigo{lin2019moel,
title={MoEL: mistura de ouvintes empáticos},
autor={Lin, Zhaojiang e Madotto, Andrea e Shin, Jamin e Xu, Peng e Fung, Pascale},
diário = {pré-impressão arXiv arXiv:1908.07687},
ano={2019}
}
Pesquisas anteriores sobre sistemas de diálogo empático concentraram-se principalmente na geração de respostas a certas emoções. No entanto, ser empático não requer apenas a capacidade de gerar respostas emocionais, mas, mais importante ainda, requer a compreensão das emoções do utilizador e a resposta adequada. Neste artigo, propomos uma nova abordagem ponta a ponta para modelar empatia em sistemas de diálogo: Mistura de Ouvintes Empáticos (MoEL). Nosso modelo primeiro captura as emoções do usuário e gera uma distribuição de emoções. Com base nisso, o MoEL combinará suavemente os estados de saída do(s) Ouvinte(s) apropriado(s), cada um deles otimizado para reagir a certas emoções, e gerar uma resposta empática. Avaliações humanas no conjunto de dados de diálogos empáticos confirmam que o MoEL supera a linha de base do treinamento multitarefa em termos de empatia, relevância e fluência. Além disso, o estudo de caso sobre respostas geradas de diferentes Ouvintes mostra alta interpretabilidade do nosso modelo.
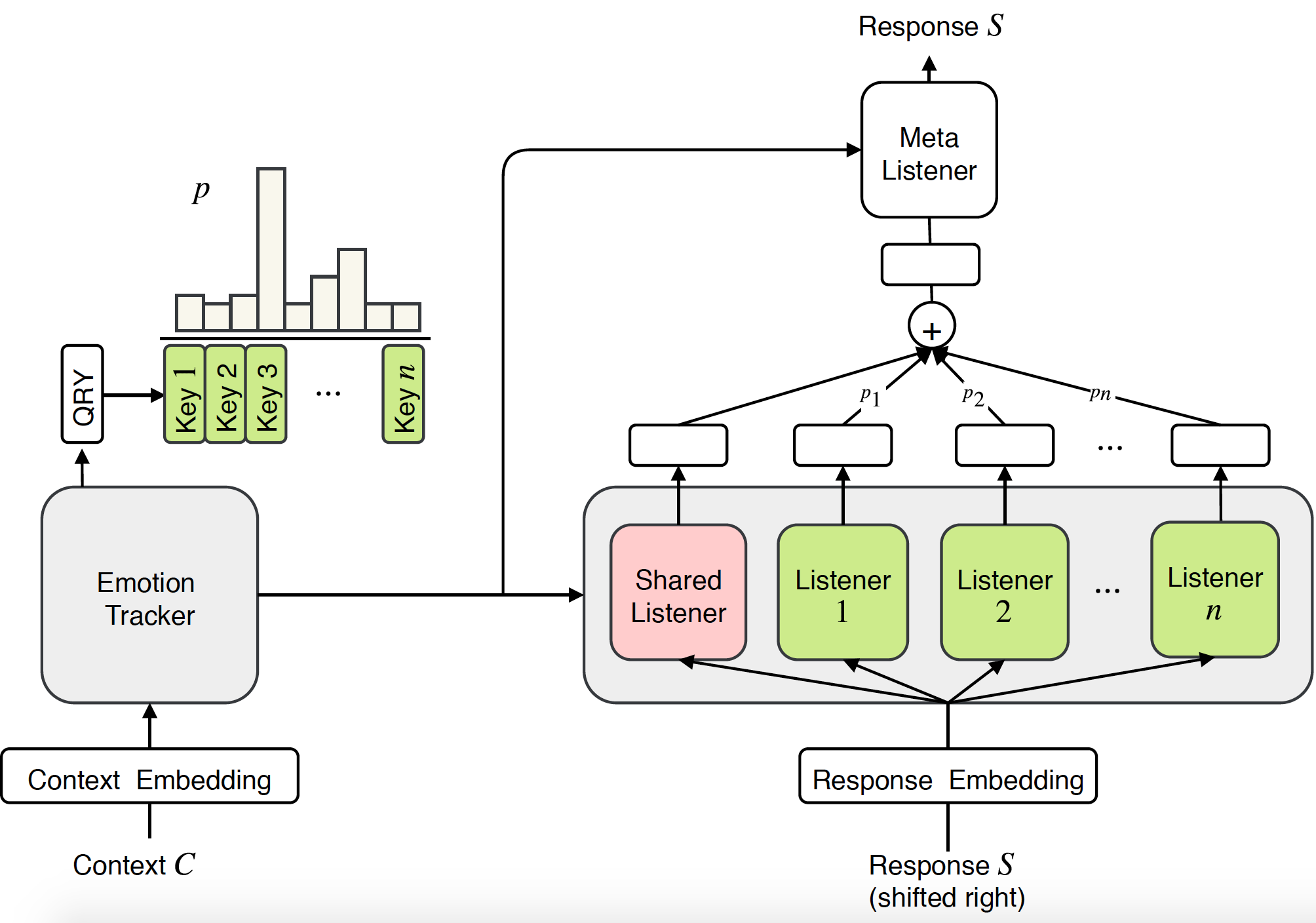
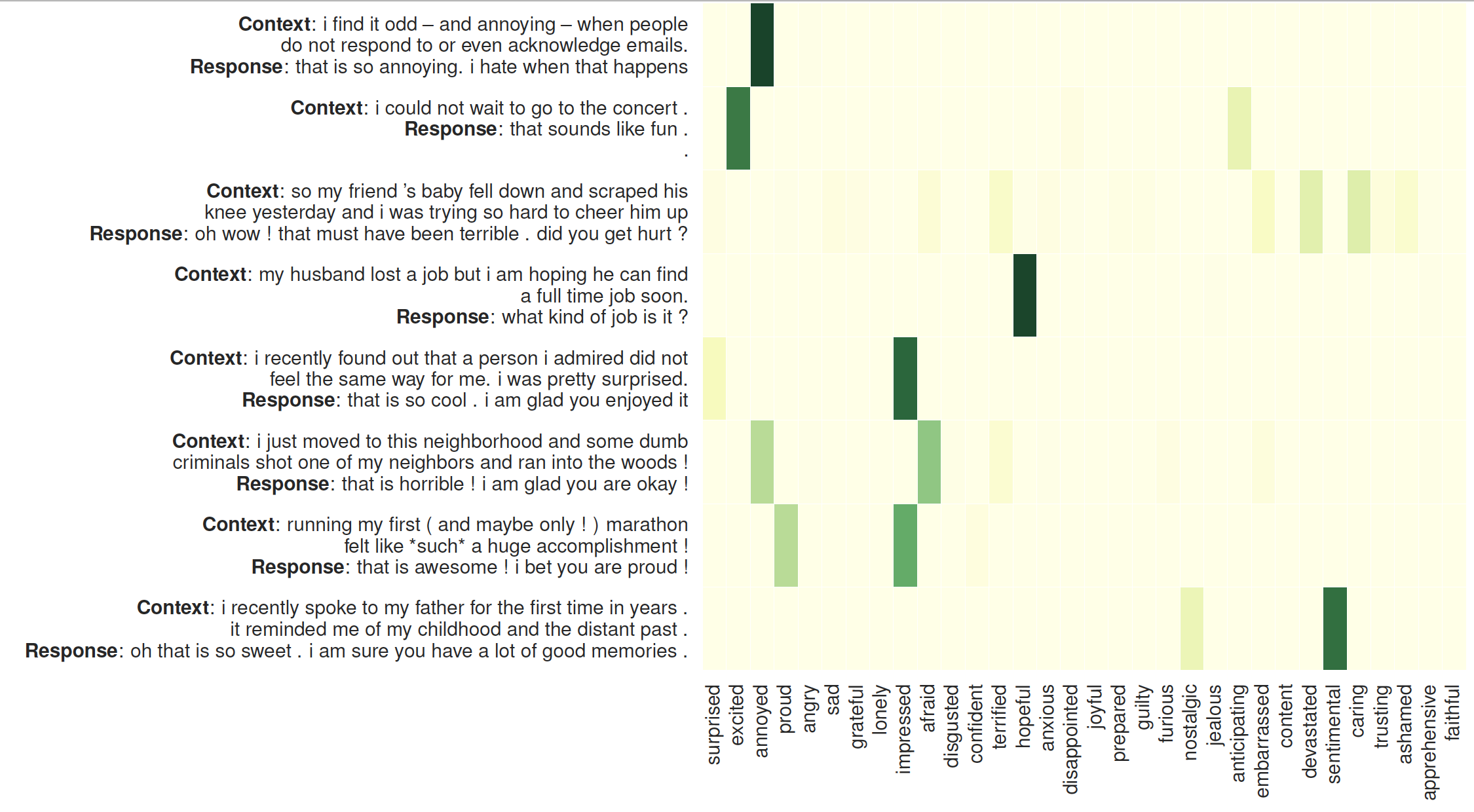
A visualização da atenção dos ouvintes: O lado esquerdo é o contexto seguido das respostas geradas pelo MoEL. O mapa de calor ilustra os pesos de atenção de 32 ouvintes
Verifique os pacotes necessários ou simplesmente execute o comando
❱❱❱ pip install -r requirements.txtIncorporação de luvas pré-treinadas : glove.6B.300d.txt dentro da pasta /vectors/.
Resultado Rápido
Para pular o treinamento, verifique Generation_result.txt .
Conjunto de dados
O conjunto de dados (diálogo empático) é pré-processado e armazenado no formato npy: sys_dialog_texts.train.npy, sys_target_texts.train.npy, sys_emotion_texts.train.npy que consiste em uma lista paralela de contexto (fonte), resposta (alvo) e rótulo de emoção (etiqueta adicional).
Treinamento e teste
MoEL
❱❱❱ python3 main.py --model experts --label_smoothing --noam --emb_dim 300 --hidden_dim 300 --hop 1 --heads 2 --topk 5 --cuda --pretrain_emb --softmax --basic_learner --schedule 10000 --save_path save/moel/
Linha de base do transformador
❱❱❱ python3 main.py --model trs --label_smoothing --noam --emb_dim 300 --hidden_dim 300 --hop 2 --heads 2 --cuda --pretrain_emb --save_path save/trs/
Linha de base do Transformer multitarefa
❱❱❱ python3 main.py --model trs --label_smoothing --noam --emb_dim 300 --hidden_dim 300 --hop 2 --heads 2 --cuda --pretrain_emb --multitask --save_path save/multi-trs/


