MELD
1.0.0
Se você estiver interessado em testes de QI LLMs, confira nosso novo trabalho: AlgoPuzzleVQA
Lançamos os recursos visuais extraídos usando Resnet - https://github.com/declare-lab/MM-Align
Para linhas de base atualizadas, visite este link: conv-emotion
Para baixar os dados, use wget: wget http://web.eecs.umich.edu/~mihalcea/downloads/MELD.Raw.tar.gz
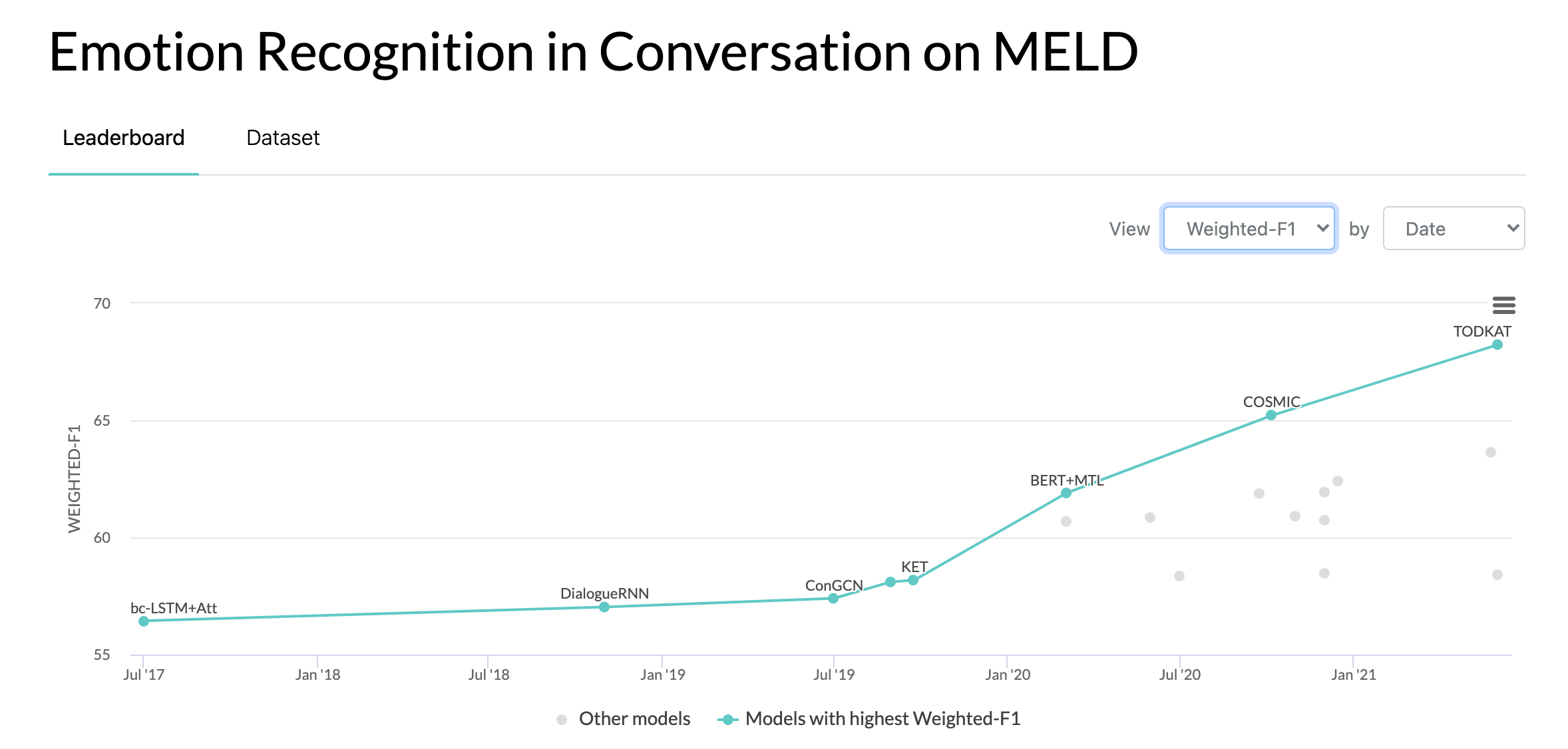
10/10/2020: Novo artigo e SOTA em Reconhecimento de emoções em conversas no conjunto de dados MELD. Consulte o diretório COSMIC para obter o código. Leia o artigo - COSMIC: conhecimento COmmonSense para identificação de eMotion em conversas.
22/05/2019: MELD: A Multimodal Multi-Party Dataset for Emotion Recognition in Conversation foi aceito como artigo completo no ACL 2019. O artigo atualizado pode ser encontrado aqui - https://arxiv.org/pdf/1810.02508. pdf
22/05/2019: Dyadic MELD foi lançado. Pode ser usado para testar modelos conversacionais diádicos.
15/11/2018: O problema no train.tar.gz foi corrigido.
Zhang, Yazhou, Qiuchi Li, Dawei Song, Peng Zhang e Panpan Wang. "Redes interativas de inspiração quântica para análise de sentimentos conversacionais." IJCAI 2019.
Zhang, Dong, Liangqing Wu, Changlong Sun, Shoushan Li, Qiaoming Zhu e Guodong Zhou. "Modelando a dependência sensível ao contexto e ao alto-falante para detecção de emoções em conversas com vários alto-falantes." IJCAI 2019.
Ghosal, Deepanway, Navonil Majumder, Soujanya Poria, Niyati Chhaya e Alexander Gelbukh. "DialogueGCN: Uma rede neural convolucional gráfica para reconhecimento de emoções em conversas." EMNLP 2019.
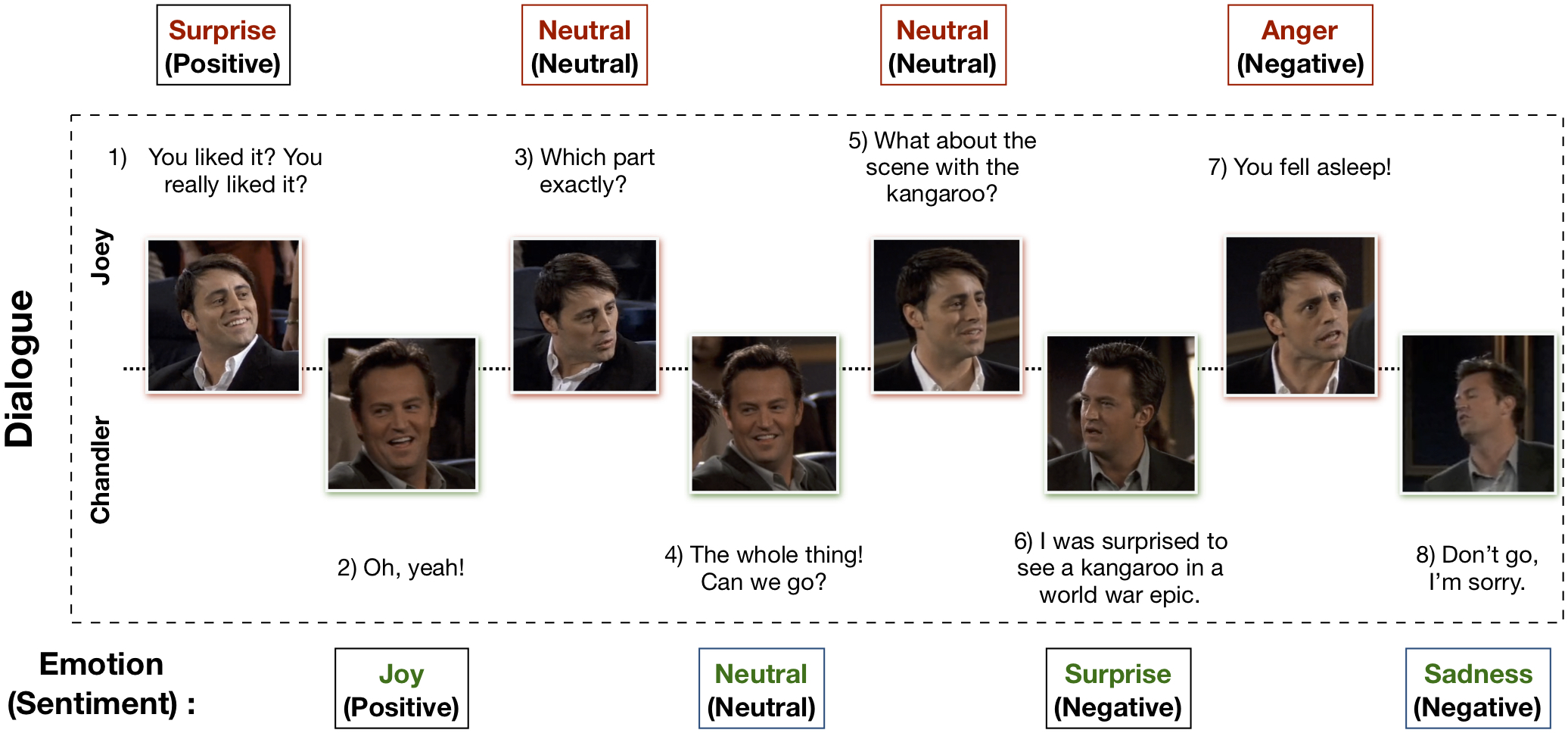
O conjunto de dados Multimodal EmotionLines (MELD) foi criado aprimorando e estendendo o conjunto de dados EmotionLines. MELD contém as mesmas instâncias de diálogo disponíveis no EmotionLines, mas também abrange a modalidade áudio e visual junto com o texto. MELD tem mais de 1.400 diálogos e 13.000 enunciados da série de TV Friends. Vários palestrantes participaram dos diálogos. Cada expressão num diálogo foi rotulada por qualquer uma destas sete emoções – Raiva, Nojo, Tristeza, Alegria, Neutro, Surpresa e Medo. MELD também possui anotação de sentimento (positivo, negativo e neutro) para cada expressão.
| Estatísticas | Trem | Desenvolvedor | Teste |
|---|---|---|---|
| # da modalidade | {a,v,t} | {a,v,t} | {a,v,t} |
| # de palavras únicas | 10.643 | 2.384 | 4.361 |
| Média comprimento da expressão | 8.03 | 7,99 | 8.28 |
| Máx. comprimento da expressão | 69 | 37 | 45 |
| Média # de emoções por diálogo | 15h30 | 3,35 | 3.24 |
| # de diálogos | 1039 | 114 | 280 |
| Nº de declarações | 9989 | 1109 | 2610 |
| # de alto-falantes | 260 | 47 | 100 |
| # de mudança de emoção | 4003 | 427 | 1003 |
| Média duração de um enunciado | 3,59s | 3,59s | 3,58s |
Visite https://affective-meld.github.io para mais detalhes.
| Trem | Desenvolvedor | Teste | |
|---|---|---|---|
| Raiva | 1109 | 153 | 345 |
| Nojo | 271 | 22 | 68 |
| Temer | 268 | 40 | 50 |
| Alegria | 1743 | 163 | 402 |
| Neutro | 4710 | 470 | 1256 |
| Tristeza | 683 | 111 | 208 |
| Surpresa | 1205 | 150 | 281 |
A análise de dados multimodais explora informações de múltiplos canais de dados paralelos para a tomada de decisões. Com o rápido crescimento da IA, o reconhecimento de emoções multimodais ganhou um grande interesse de investigação, principalmente devido às suas potenciais aplicações em muitas tarefas desafiantes, tais como geração de diálogo, interacção multimodal, etc. analisando as emoções do usuário. Embora existam numerosos trabalhos realizados sobre o reconhecimento multimodal de emoções, apenas alguns realmente se concentram na compreensão das emoções nas conversas. No entanto, o seu trabalho é limitado apenas à compreensão de conversas diádicas e, portanto, não é escalável para o reconhecimento de emoções em conversas multipartidárias com mais de dois participantes. EmotionLines pode ser utilizado como recurso de reconhecimento de emoções apenas para texto, pois não inclui dados de outras modalidades como visual e áudio. Ao mesmo tempo, deve-se notar que não existe um conjunto de dados de conversação multimodal multipartidário disponível para pesquisa de reconhecimento de emoções. Neste trabalho, estendemos, melhoramos e desenvolvemos o conjunto de dados EmotionLines para o cenário multimodal. O reconhecimento de emoções em turnos sequenciais apresenta vários desafios e a compreensão do contexto é um deles. A mudança emocional e o fluxo emocional na sequência de turnos de um diálogo tornam a modelagem precisa do contexto uma tarefa difícil. Neste conjunto de dados, como temos acesso às fontes de dados multimodais para cada diálogo, hipotetizamos que irá melhorar a modelagem do contexto, beneficiando assim o desempenho geral do reconhecimento de emoções. Este conjunto de dados também pode ser usado para desenvolver um sistema de diálogo afetivo multimodal. IEMOCAP, SEMAINE são conjuntos de dados conversacionais multimodais que contêm rótulos emocionais para cada expressão. No entanto, esses conjuntos de dados são de natureza diádica, o que justifica a importância do nosso conjunto de dados Multimodal-EmotionLines. Os outros conjuntos de dados multimodais de reconhecimento de emoções e sentimentos disponíveis publicamente são MOSEI, MOSI, MOUD. No entanto, nenhum desses conjuntos de dados é conversacional.
A primeira etapa trata de encontrar o carimbo de data/hora de cada enunciado em cada um dos diálogos presentes no conjunto de dados EmotionLines. Para fazer isso, rastreamos os arquivos de legenda de todos os episódios que contêm o carimbo de data e hora de início e fim dos enunciados. Esse processo nos permitiu obter o ID da temporada, o ID do episódio e o carimbo de data/hora de cada enunciado no episódio. Colocamos duas restrições ao obter os carimbos de data e hora: (a) os carimbos de data e hora dos enunciados em um diálogo devem estar em ordem crescente, (b) todos os enunciados em um diálogo devem pertencer ao mesmo episódio e cena. A restrição a essas duas condições revelou que em EmotionLines, alguns diálogos consistem em múltiplos diálogos naturais. Filtramos esses casos do conjunto de dados. Por causa desta etapa de correção de erros, em nosso caso, temos um número diferente de diálogos em comparação com as EmotionLines. Após obter o carimbo de data/hora de cada enunciado, extraímos os clipes audiovisuais correspondentes do episódio fonte. Separadamente, também retiramos o conteúdo de áudio desses videoclipes. Finalmente, o conjunto de dados contém modalidade visual, sonora e textual para cada diálogo.
O artigo que explica este conjunto de dados pode ser encontrado - https://arxiv.org/pdf/1810.02508.pdf
Visite - http://web.eecs.umich.edu/~mihalcea/downloads/MELD.Raw.tar.gz para baixar os dados brutos. Os dados são armazenados no formato .mp4 e podem ser encontrados em arquivos XXX.tar.gz. As anotações podem ser encontradas em https://github.com/declare-lab/MELD/tree/master/data/MELD.
| Nome da coluna | Descrição |
|---|---|
| Sr. Não. | Números de série dos enunciados principalmente para referenciar os enunciados no caso de versões diferentes ou cópias múltiplas com subconjuntos diferentes |
| Enunciado | Enunciados individuais de EmotionLines como uma string. |
| Palestrante | Nome do locutor associado ao enunciado. |
| Emoção | A emoção (neutra, alegria, tristeza, raiva, surpresa, medo, nojo) expressa pelo locutor no enunciado. |
| Sentimento | O sentimento (positivo, neutro, negativo) expresso pelo locutor no enunciado. |
| Diálogo_ID | O índice do diálogo começando em 0. |
| Enunciado_ID | O índice da expressão específica no diálogo começando em 0. |
| Temporada | A temporada não. do programa de TV Friends ao qual pertence uma determinada expressão. |
| Episódio | O episódio não. do programa de TV Friends em uma determinada temporada à qual o enunciado pertence. |
| Hora de início | A hora de início do enunciado no episódio determinado no formato 'hh:mm:ss,ms'. |
| Hora final | O horário de término do enunciado no episódio determinado no formato 'hh:mm:ss,ms'. |
Existem 13 arquivos pickle compostos por dados e recursos usados para treinar os modelos de linha de base. A seguir está uma breve descrição de cada um dos arquivos pickle.
import pickle
data , W , vocab , word_idx_map , max_sentence_length , label_index = pickle . load ( open ( filepath , 'rb' )) import pickle
train_text_avg_emb , val_text_avg_emb , test_text_avg_emb = pickle . load ( open ( filepath , 'rb' )) import pickle
train_audio_emb , val_audio_emb , test_audio_emb = pickle . load ( open ( filepath , 'rb' )) import pickle
train_text_CNN_emb , val_text_CNN_emb , test_text_CNN_emb = pickle . load ( open ( filepath , 'rb' )) import pickle
train_text_emb , val_text_emb , test_text_emb = pickle . load ( open ( filepath , 'rb' )) import pickle
train_audio_emb , val_audio_emb , test_audio_emb = pickle . load ( open ( filepath , 'rb' )) import pickle
train_bimodal_emb , val_bimodal_emb , test_bimodal_emb = pickle . load ( open ( filepath , 'rb' ))Existem 2 scripts python fornecidos em './utils/':
Para experimentação, todos os rótulos são representados como codificações one-hot, cujos índices são os seguintes:
Para a linha de base da classificação das emoções, foram utilizados os seguintes pesos de classe. A indexação é a mesma mencionada acima. Pesos de classe: [4,0, 15,0, 15,0, 3,0, 1,0, 6,0, 3,0].
Siga estas etapas para executar a linha de base -
./data/pickles/baseline/baseline.py da seguinte forma:python baseline.py -classify [Sentiment|Emotion] -modality [text|audio|bimodal] [-train|-test]python baseline.py -classify Sentiment -modality text -trainpython baseline.py -h para obter texto de ajuda para os parâmetros../data/models/ . Por favor, cite os seguintes artigos se você achar este conjunto de dados útil em sua pesquisa
S. Poria, D. Hazarika, N. Majumder, G. Naik, E. Cambria, R. Mihalcea. MELD: um conjunto de dados multimodal multipartidário para reconhecimento de emoções em conversas. ACL 2019.
Chen, SY, Hsu, CC, Kuo, CC e Ku, LW EmotionLines: um corpus emocional de conversas multipartidárias. Pré-impressão do arXiv arXiv:1802.08379 (2018).
O conjunto de dados multimodal EmoryNLP Emotion Detection foi criado aprimorando e estendendo o conjunto de dados EmoryNLP Emotion Detection. Ele contém as mesmas instâncias de diálogo disponíveis no conjunto de dados EmoryNLP Emotion Detection, mas também abrange a modalidade áudio e visual junto com o texto. Existem mais de 800 diálogos e 9.000 declarações da série de TV Friends no conjunto de dados multimodal EmoryNLP. Vários palestrantes participaram dos diálogos. Cada expressão num diálogo foi rotulada por qualquer uma destas sete emoções – Neutro, Alegre, Pacífico, Poderoso, Assustado, Louco e Triste. As anotações são emprestadas do conjunto de dados original.
| Estatísticas | Trem | Desenvolvedor | Teste |
|---|---|---|---|
| # da modalidade | {a,v,t} | {a,v,t} | {a,v,t} |
| # de palavras únicas | 9.744 | 2.123 | 2.345 |
| Média comprimento da expressão | 7,86 | 6,97 | 7,79 |
| Máx. comprimento da expressão | 78 | 60 | 61 |
| Média # de emoções por cena | 4.10 | 4h00 | 4h40 |
| # de diálogos | 659 | 89 | 79 |
| Nº de declarações | 7551 | 954 | 984 |
| # de alto-falantes | 250 | 46 | 48 |
| # de mudança de emoção | 4596 | 575 | 653 |
| Média duração de um enunciado | 5,55s | 5,46s | 5,27s |
| Trem | Desenvolvedor | Teste | |
|---|---|---|---|
| Alegre | 1677 | 205 | 217 |
| Louco | 785 | 97 | 86 |
| Neutro | 2485 | 322 | 288 |
| Pacífico | 638 | 82 | 111 |
| Poderoso | 551 | 70 | 96 |
| Triste | 474 | 51 | 70 |
| Assustado | 941 | 127 | 116 |
Os videoclipes deste conjunto de dados podem ser baixados neste link. Os arquivos de anotação podem ser encontrados em https://github.com/SenticNet/MELD/tree/master/data/emorynlp. Existem 3 arquivos .csv. Cada entrada na primeira coluna desses arquivos csv contém uma expressão cujo videoclipe correspondente pode ser encontrado aqui. Cada enunciado e seu videoclipe são indexados pelo número da temporada, número do episódio, id da cena e id do enunciado. Por exemplo, sea1_ep2_sc6_utt3.mp4 implica que o clipe corresponde ao enunciado com a temporada no. 1, episódio não. 2, scene_id 6 e enunciado_id 3. Uma cena é simplesmente um diálogo. Esta indexação é consistente com o conjunto de dados original. Os arquivos .csv e os arquivos de vídeo são divididos em conjunto de treinamento, validação e teste de acordo com o conjunto de dados original. As anotações foram emprestadas diretamente do conjunto de dados EmoryNLP original (Zahiri et al. (2018)).
| Nome da coluna | Descrição |
|---|---|
| Enunciado | Enunciados individuais do EmoryNLP como uma string. |
| Palestrante | Nome do locutor associado ao enunciado. |
| Emoção | A emoção (neutra, alegre, pacífica, poderosa, assustada, louca e triste) expressa pelo locutor no enunciado. |
| Cena_ID | O índice do diálogo começando em 0. |
| Enunciado_ID | O índice da expressão específica no diálogo começando em 0. |
| Temporada | A temporada não. do programa de TV Friends ao qual pertence uma determinada expressão. |
| Episódio | O episódio não. do programa de TV Friends em uma determinada temporada à qual o enunciado pertence. |
| Hora de início | A hora de início do enunciado no episódio determinado no formato 'hh:mm:ss,ms'. |
| Fim da Hora | O horário de término do enunciado no episódio determinado no formato 'hh:mm:ss,ms'. |
Nota : Existem alguns enunciados para os quais não conseguimos encontrar o horário de início e término devido a algumas inconsistências nas legendas. Tais declarações foram omitidas do conjunto de dados. No entanto, encorajamos os usuários a encontrar as declarações correspondentes no conjunto de dados original e gerar videoclipes para as mesmas.
Por favor, cite os seguintes artigos se você achar este conjunto de dados útil em sua pesquisa
S. Zahiri e JD Choi. Detecção de emoção em transcrições de programas de TV com redes neurais convolucionais baseadas em sequência. No Workshop AAAI sobre Análise de Conteúdo Afetivo, AFFCON'18, 2018.
S. Poria, D. Hazarika, N. Majumder, G. Naik, E. Cambria, R. Mihalcea. MELD: um conjunto de dados multimodal multipartidário para reconhecimento de emoções em conversas. ACL 2019.


