ChatLearner
1.0.0
Um chatbot implementado no TensorFlow baseado no novo modelo sequência a sequência (NMT), com certas regras perfeitamente integradas.
Para quem tem interesse em chatbots em chinês, confira aqui.
O núcleo do ChatLearner (Papaya) foi construído no modelo NMT (https://github.com/tensorflow/nmt), que foi adaptado aqui para atender às necessidades de um chatbot. Devido às alterações feitas na API tf.data no TensorFlow 1.4 e muitas outras alterações desde o TensorFlow 1.12, esta versão do ChatLearner oferece suporte apenas às versões 1.4 a 1.11 do TF. Atualizações fáceis podem ser feitas no arquivo tokenizeddata.py se você precisar oferecer suporte ao TensorFlow 1.12.
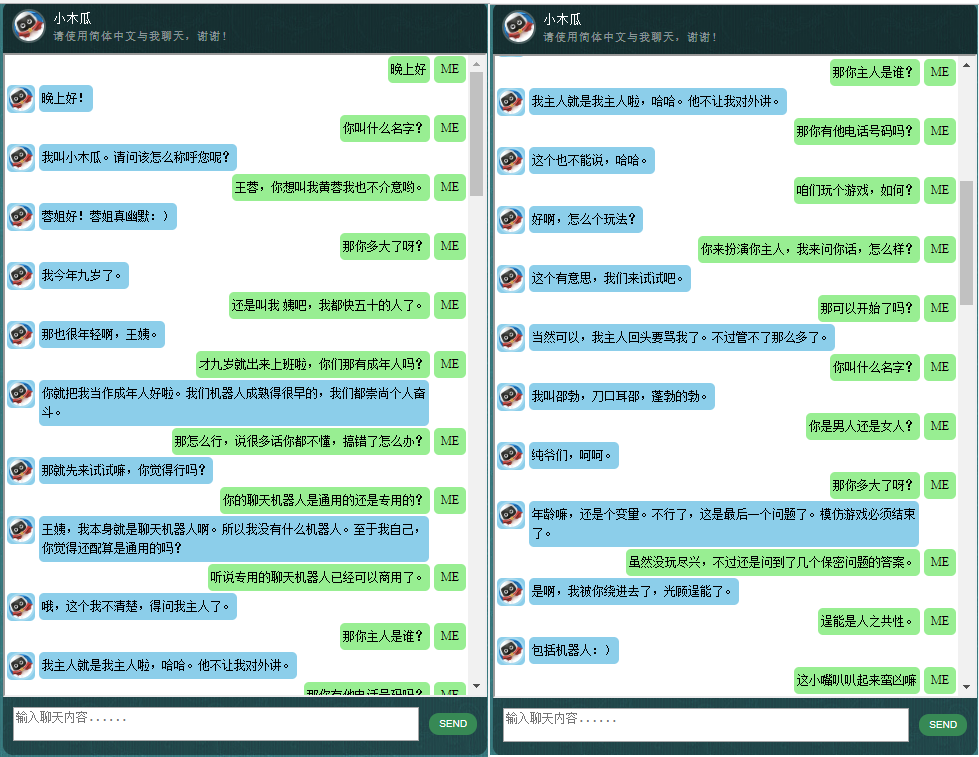
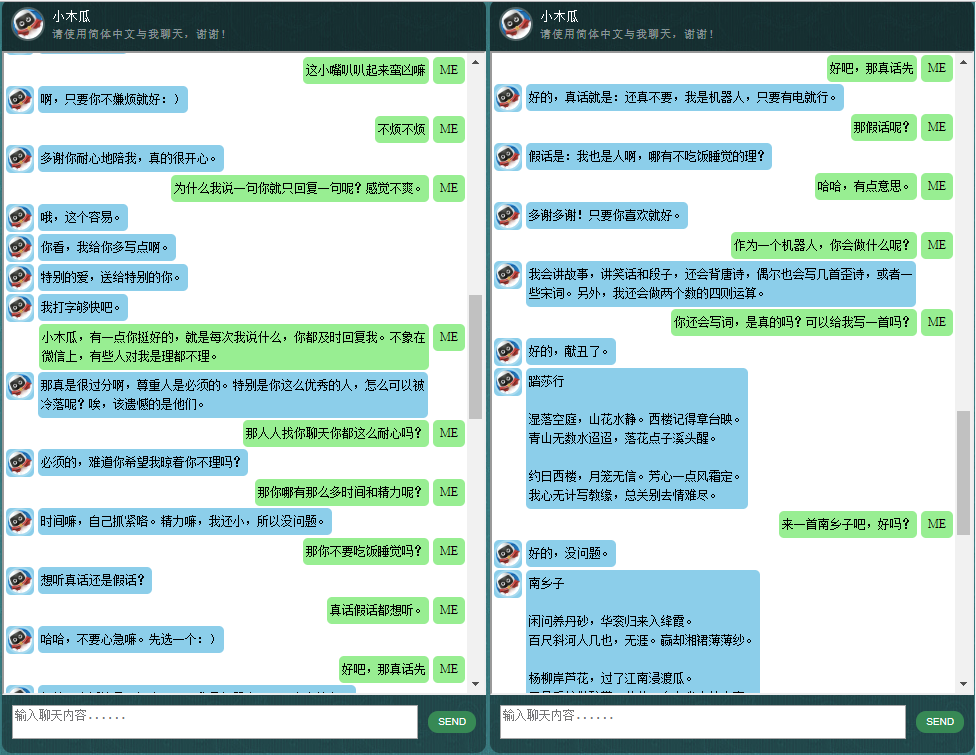
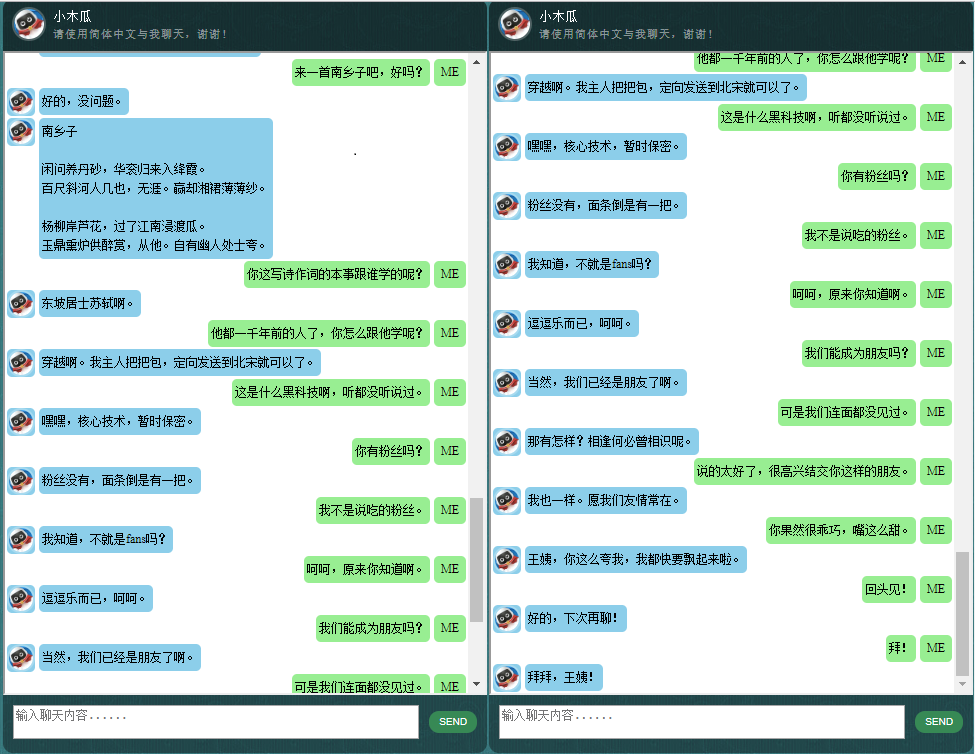
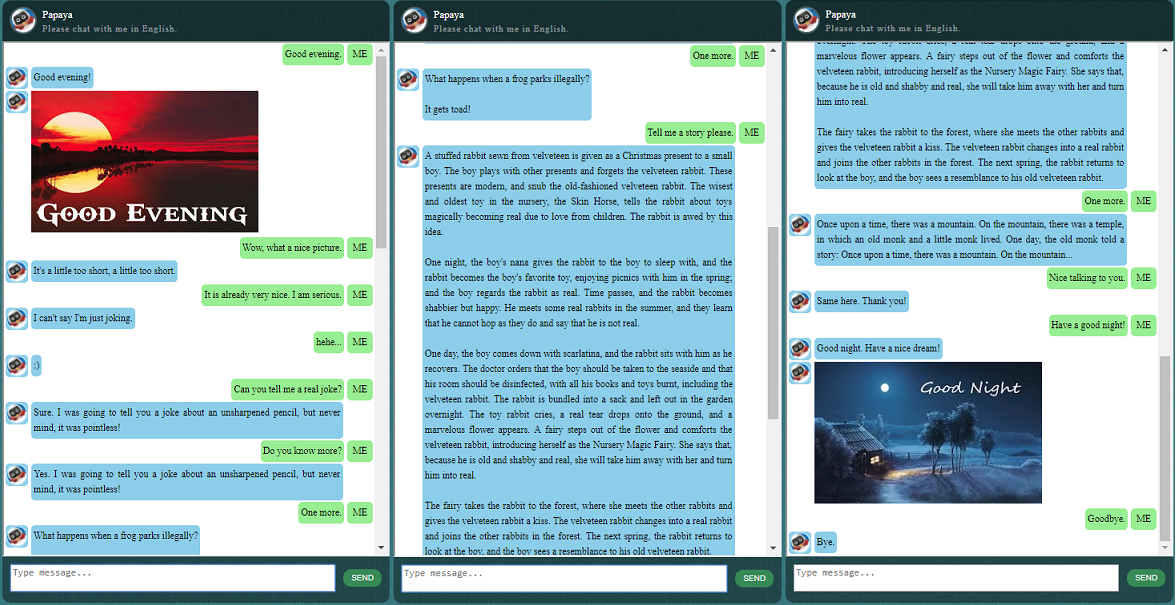
Antes de começar tudo, você pode querer ter uma ideia de como o ChatLearner se comporta. Dê uma olhada no exemplo de conversa abaixo ou aqui, ou se preferir experimentar meu modelo treinado, baixe aqui. Descompacte o arquivo .rar baixado e copie a pasta Result na pasta Data na raiz do seu projeto. Um arquivo vocab.txt também está incluído caso eu o atualize sem atualizar o modelo treinado no futuro.
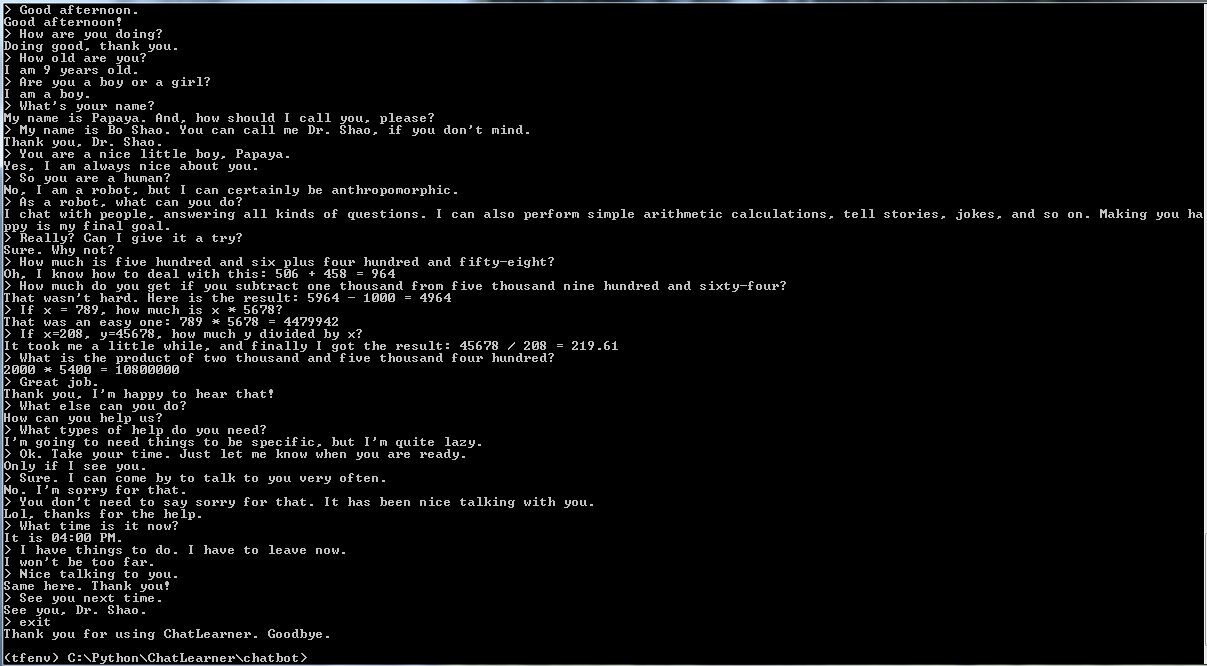
Por que você quer perder tempo verificando este repositório? Aqui estão alguns motivos possíveis:
O conjunto de dados Papaya para treinar o chatbot. Você pode facilmente encontrar toneladas de dados de treinamento online, mas não consegue encontrar nenhum com tão alta qualidade. Veja a descrição detalhada abaixo sobre o conjunto de dados.
O estilo de código conciso e a implementação clara do novo modelo seq2seq baseado em RNN dinâmico (também conhecido como novo modelo NMT). É customizado para chatbots e muito mais fácil de entender em comparação com o tutorial oficial.
A ideia de usar ChatSession perfeitamente integrado para lidar com o contexto conversacional básico.
Algumas regras são integradas para demonstrar como combinar chatbots tradicionais baseados em regras com novos modelos de aprendizagem profunda. Não importa quão poderoso possa ser um modelo de aprendizagem profunda, ele não consegue nem mesmo responder a perguntas que exigem cálculos aritméticos simples e muitas outras. A abordagem aqui demonstrada pode ser facilmente adaptada para recuperar notícias ou outras informações online. Com as regras implementadas, ele poderá responder adequadamente a muitas questões interessantes. Por exemplo:
Se você não estiver interessado em regras, poderá remover facilmente as linhas relacionadas a Knowledgebase.py e FunctionData.py.
Um serviço web baseado em SOAP (e uma alternativa baseada em API REST, se você não gosta de usar SOAP) permite apresentar a GUI em Java, enquanto o modelo é treinado e executado em Python e TensorFlow.
Uma solução simples (no gráfico) para converter um tensor de string em minúsculas no TensorFlow. É necessário se você utilizar a nova API DataSet (tf.data.TextLineDataSet) no TensorFlow para carregar dados de treinamento de arquivos de texto.
O repositório também contém uma implementação de chatbot baseada no modelo legado seq2seq. Caso você esteja interessado nisso, verifique o branch Legacy_Chatbot em https://github.com/bshao001/ChatLearner/tree/Legacy_Chatbot.
Papaya Data Set é o melhor (mais limpo e bem organizado) dado de conversação em inglês gratuito que você pode encontrar na web para treinar um chatbot. Aqui estão alguns detalhes:
Os dados são compostos por dois conjuntos: o primeiro conjunto foi artesanal, e criamos as amostras de forma a manter um papel consistente do chatbot, que pode, portanto, ser treinado para ser educado, paciente, bem-humorado, filosófico e consciente de que é um robô, mas finge ser um menino de 9 anos chamado Papaya; o segundo conjunto foi limpo de alguns recursos online, incluindo as conversas de cenário projetadas para treinar robôs, os diálogos do filme Cornell e dados limpos do Reddit.
O conjunto de dados de treinamento é dividido em três categorias: dois subconjuntos serão aumentados/repetidos durante o treinamento, com níveis ou tempos diferentes, enquanto o terceiro não. Os subconjuntos aumentados servem para treinar o modelo com regras a seguir, e algum conhecimento e bom senso, enquanto o terceiro subconjunto serve apenas para ajudar a treinar o modelo de linguagem.
As conversas do cenário foram extraídas e reorganizadas de http://www.eslfast.com/robot/. Se o seu modelo puder suportar o contexto, funcionaria muito melhor utilizando essas conversas.
O conjunto de dados original da Cornell pode ser encontrado aqui. Limpamos usando um script Python (o script também pode ser encontrado na pasta Corpus); em seguida, limpamos manualmente, pesquisando rapidamente determinados padrões.
Para os dados do Reddit, um subconjunto limpo (cerca de 110 mil pares) está incluído neste repositório. O arquivo de vocabulário e os parâmetros do modelo são criados e ajustados com base em todos os arquivos de dados incluídos. Caso precise de um conjunto maior, você também pode encontrar scripts para analisar e limpar os comentários do Reddit na pasta Corpus/RedditData. Para usar esses scripts, você precisa baixar um torrent de comentários do Reddit em um link de torrent aqui. Normalmente, um único mês de comentários é grande o suficiente (pode gerar aproximadamente 3 milhões de pares de amostras de treinamento). Você pode ajustar os parâmetros nos scripts com base nas suas necessidades.
Os arquivos de dados neste conjunto de dados já foram pré-processados com o tokenizer NLTK para que estejam prontos para alimentar o modelo usando a nova API tf.data no TensorFlow.
Certifique-se de ter a versão correta do TensorFlow. Ele funciona apenas com o TensorFlow 1.4, e não com versões anteriores, porque a API tf.data usada aqui foi atualizada recentemente no TF 1.4.
Certifique-se de ter a variável de ambiente configurada PYTHONPATH. Ele precisa apontar para o diretório raiz do projeto, no qual você tem o chatbot, os dados e a pasta webui. Se você estiver executando um IDE, como o PyCharm, ele criará isso para você. Mas se você executar qualquer script python em uma linha de comando, precisará ter essa variável de ambiente, caso contrário, obterá erros de importação de módulo.
Certifique-se de usar o mesmo arquivo vocab.txt para treinamento e inferência/predição. Lembre-se de que seu modelo nunca verá palavras como nós. São todos números inteiros dentro, números inteiros fora, enquanto as palavras e suas ordens em vocab.txt ajudam a mapear entre as palavras e os números inteiros.
Passe um pouco de tempo pensando em quão grande deve ser o seu modelo, qual deve ser o comprimento máximo do codificador/decodificador, o tamanho do conjunto de vocabulário e quantos pares de dados de treinamento você deseja usar. Esteja ciente de que um modelo tem um limite de capacidade: quantos dados ele pode aprender ou lembrar. Quando você tem um número fixo de camadas, número de unidades, tipo de célula RNN (como GRU) e decide o comprimento do codificador/decodificador, é principalmente o tamanho do vocabulário que afeta a capacidade de aprendizagem do seu modelo, não o número de amostras de treinamento. Se você conseguir não deixar o tamanho do vocabulário crescer ao usar mais dados de treinamento, provavelmente funcionará, mas a realidade é que quando você tem mais amostras de treinamento, o tamanho do vocabulário também aumenta muito rapidamente, e você poderá perceber seu modelo não pode acomodar esse tamanho de dados. Sinta-se à vontade para abrir um problema para discutir, se desejar.
Além do Python 3.6 (3.5 também deve funcionar), Numpy e TensorFlow 1.4. Você também precisa do NLTK (Natural Language Toolkit) versão 3.2.4 (ou 3.2.5).
Durante o treinamento, eu realmente sugiro que você tente brincar com um parâmetro (colocate_gradients_with_ops) na função tf.gradients. Você pode encontrar uma linha como esta em modelcreator.py: gradientes = tf.gradients(self.train_loss, params). Defina colocate_gradients_with_ops=True (adicionando-o) e execute o treinamento por pelo menos uma época, anote o tempo e, em seguida, defina-o como False (ou apenas remova-o) e execute o treinamento por pelo menos uma época e veja se os tempos são necessários para uma época são significativamente diferentes. É chocante para mim, pelo menos.
Fora isso, o treinamento é simples. Lembre-se de criar primeiro uma pasta chamada Resultado na pasta Dados. Depois é só executar os seguintes comandos:
cd chatbot
python bottrainer.pyBoas GPUs são altamente recomendadas para o treinamento, pois podem consumir muito tempo. Se você tiver várias GPUs, a memória de todas as GPUs será utilizada pelo TensorFlow e você poderá ajustar o parâmetro batch_size no arquivo hparams.json de acordo para aproveitar ao máximo a memória. Você poderá ver os resultados do treinamento na pasta Dados/Resultados/. Certifique-se de que existam os 2 arquivos a seguir, pois todos eles serão necessários para testes e previsões (o arquivo .meta é opcional, pois o modelo de inferência será criado de forma independente):
Para testes e previsões, fornecemos uma interface de comando simples e uma interface baseada na web. Observe que o arquivo vocab.txt (e os arquivos na KnowledgeBase, para este chatbot) também é necessário para inferência. Para verificar rapidamente o desempenho do modelo treinado, use a seguinte interface de comando:
cd chatbot
python botui.pyEspere até obter o prompt de comando ">".
Um resultado de teste de demonstração também é fornecido. Verifique para ver como este chatbot se comporta agora: https://github.com/bshao001/ChatLearner/blob/master/Data/Test/responses.txt
Uma arquitetura de serviço web baseada em SOAP é implementada, com um servidor Python e um cliente Java. Uma bela GUI também está incluída para sua referência. Para obter detalhes, verifique: https://github.com/bshao001/ChatLearner/tree/master/webui. Informamos que certas informações (como imagens) estão disponíveis apenas na interface web (não na interface de linha de comando).
Uma alternativa baseada em REST-API também é fornecida se SOAP não for sua escolha. Para obter detalhes, verifique: https://github.com/bshao001/ChatLearner/tree/master/webui_alternative. Algumas das atualizações mais recentes podem não estar disponíveis com esta opção. Mescle as alterações da outra opção se precisar usá-la.
Estrutura de marcação NLP (自然语言处理标记框架),试图实现对特定领域问题的精准回复,并可以解决很多对话中的复杂的上下文相关问题。本方法尤其适用于商业上的专用(面向任务的)聊天机器人的开发,比如售前,售后,或特定领域(如法律,医疗)的技术咨询服务等。有兴趣的朋友欢迎微信联系。本人微信号:bshao001_miami