gutenberg dialog
1.0.0
Código para baixar e construir sua própria versão do conjunto de dados do Gutenberg Dialog. Facilmente extensível com novos idiomas. Experimente chatbots treinados em vários idiomas aqui: https://ricsinaruto.github.io/chatbot.html.
| Baixar link | Número de enunciados | Comprimento médio do enunciado | Número de diálogos | Duração média do diálogo |
|---|---|---|---|---|
| Inglês | 14 773 741 | 22.17 | 2 526 877 | 5,85 |
| Alemão | 226 015 | 24h44 | 43 440 | 5h20 |
| Holandês | 129 471 | 24.26 | 23 541 | 5,50 |
| Espanhol | 58 174 | 18,62 | 6 912 | 8.42 |
| italiano | 41 388 | 19h47 | 6 664 | 6.21 |
| húngaro | 18 816 | 14,68 | 2 826 | 6,66 |
| Português | 16 228 | 21h40 | 2 233 | 7.27 |
? Gere seu próprio conjunto de dados ajustando parâmetros que afetam a compensação entre tamanho e qualidade do conjunto de dados
A interface modular facilita a extensão do conjunto de dados para outras linguagens
? Você pode excluir facilmente livros manualmente ao criar o conjunto de dados
Execute setup.py que instala os pacotes necessários.
python setup.py
O arquivo principal deve ser chamado da raiz do repositório. O comando abaixo executa o pipeline de construção do conjunto de dados para as linguagens separadas por vírgula fornecidas como argumento. Atualmente são suportados inglês, alemão, holandês, espanhol, português, italiano e húngaro.
python code/main.py -l=en,de,nl,es,pt,it,hu -a
Todos os argumentos configuráveis podem ser vistos abaixo: 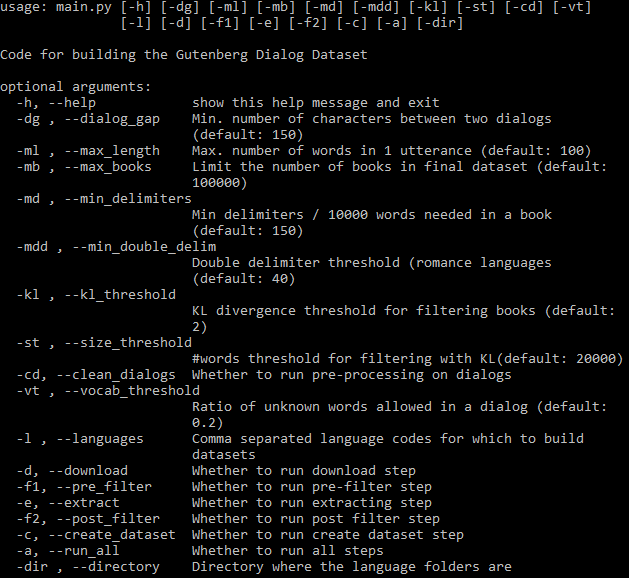
O sinalizador -a controla se todo o pipeline deve ser executado automaticamente. Se -a for omitido, um subconjunto de etapas deverá ser especificado usando sinalizadores (consulte a ajuda acima). Depois que uma etapa é concluída, sua saída pode ser usada nas etapas subsequentes e só será executada novamente se os parâmetros ou o código relacionado a essa etapa forem alterados. Todas as etapas são executadas separadamente para cada idioma.
Baixe livros para determinados idiomas.
Nota: se o download de todos os livros falhar com o erro "Não foi possível baixar o livro", uma causa provável é que o espelho padrão usado pelo pacote gutenberg tornou-se inacessível. Caso isso ocorra, é possível usar qualquer um dos espelhos alternativos listados em https://www.gutenberg.org/MIRRORS.ALL através da variável de ambiente GUTENBERG_MIRROR . Por exemplo:
export GUTENBERG_MIRROR="https://gutenberg.pglaf.org"
python code/main.py ...
A pré-filtragem remove alguns livros antigos e ruídos.
Os diálogos são extraídos de livros. Ao estender o conjunto de dados para novos idiomas (ver seção abaixo), esta é a etapa que pode ser modificada, portanto, as etapas anteriores podem ser ignoradas quando concluídas.
Uma segunda etapa de filtragem removendo alguns diálogos baseados em vocabulário.
Reunir o conjunto de dados final e dividir em dados de treinamento/desenvolvimento/teste. A etapa final cria o arquivo author_and_title.txt no diretório de saída contendo todos os livros (mais títulos e autores) usados para extrair o conjunto de dados final. Os usuários podem copiar manualmente as linhas deste arquivo para banidos_books.txt correspondentes a livros que não deveriam ser permitidos no conjunto de dados. Nas execuções subsequentes de qualquer etapa, os livros deste arquivo não serão levados em consideração.
O código pode ser facilmente estendido para processar outras linguagens. Um arquivo chamado <código de idioma>.py deve ser criado na pasta de idiomas. Aqui uma classe deve ser definida com o nome do código do idioma maiúsculo (por exemplo, En para inglês), com LANG ou qualquer uma das outras subclasses como pai. Com self.cfg os parâmetros de configuração podem ser acessados. Dentro desta classe as 3 funções abaixo devem ser definidas. Por favor, veja it.py para ver um exemplo.
Estatísticas de idiomas
Esta função deve retornar um dicionário onde as chaves são delimitadores potenciais. Para cada delimitador deve ser definida uma função (valores no dicionário), que recebe como entrada uma linha e retorna um número. Este número pode ser, por exemplo, a contagem de delimitadores, um sinalizador se existe um delimitador na linha, etc. Normalmente é aconselhável uma contagem ponderada, dependendo da importância dos diferentes delimitadores. Os valores serão utilizados para determinar o delimitador que deverá ser utilizado no respectivo livro (passado para a função abaixo), e para filtrar livros que contenham baixa quantidade de delimitadores. en.py contém exemplos de vários delimitadores.
Esta função deve extrair os diálogos de um livro e anexá-los a self.dialogs , que é uma lista de diálogos, e cada diálogo é uma lista de declarações consecutivas. Paragraph_list contém o livro como uma lista de parágrafos consecutivos. delimitador é o delimitador mais comum neste arquivo que deve ser usado para extrair diálogos.
Esta função é usada para diálogos de pós-processamento (por exemplo, remover certos caracteres). Toma como entrada um enunciado. Observe que a tokenização de palavras nltk é executada automaticamente.
Este projeto está licenciado sob a licença MIT - consulte o arquivo LICENSE para obter detalhes.
Inclua um link para este repositório se você usar algum conjunto de dados ou código em seu trabalho e considere citar o seguinte artigo:
@inproceedings{Csaky:2021,
title = "The Gutenberg Dialogue Dataset",
author = "Cs{'a}ky, Rich{'a}rd and Recski, G{'a}bor",
booktitle = "Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics",
month = apr,
year = "2021",
publisher = "Association for Computational Linguistics",
url = "https://arxiv.org/abs/2004.12752",
}


