Dialog
1.0.0
Dialog é um projeto de chatbot japonês.
A arquitetura utilizada neste projeto é o modelo EncoderDecoder que possui BERT Encoder e Transformer Decoder.
Artigo escrito em japonês.
Você pode executar o script de treinamento e avaliação no Google Colab sem criar ambiente.
Por favor clique no link a seguir.
Observe que no caderno de treinamento, o comando de download está descrito no final da nota, mas ainda não foi testado. Portanto, se você executa o caderno de treinamento e não consegue baixar um arquivo de peso treinado, faça o download manualmente.
blog escrito em japonês
@ ycat3 criou um exemplo de conversão de texto em fala usando este projeto para geração de frases e Parallel Wavenet para síntese de fala. O código-fonte não é compartilhado, mas você pode reproduzi-lo se aproveitar o Parallel Wavenet. Esse blog tem algumas amostras de áudio, então tente ouvi-las.
Eu gostaria de criar um aplicativo que nos permitisse conversar com IA por voz usando síntese de fala e reconhecimento de fala se eu tiver muito tempo livre, mas agora não posso fazer isso devido à preparação para os exames...
2 épocas
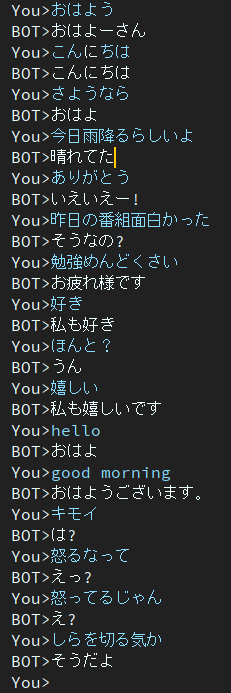
Este modelo ainda contém o problema da resposta monótona.
Para resolver esse problema estou pesquisando agora.
Então descobri que o jornal abordava esse problema.
Outra função objetivo de promoção da diversidade para geração de diálogo neural
Os autores pertencem ao Instituto Nara de Ciência e Tecnologia, também conhecido como NAIST.
Eles propõem a nova função objetivo de geração de diálogo neural.
Espero que este método possa me ajudar a resolver esse problema.
no Google Drive.
Os pacotes necessários são
Se ocorrerem erros por causa dos pacotes, instale os pacotes ausentes.
Exemplo se você usar conda.
# create new environment
$ conda create -n dialog python=3.7
# activate new environment
$ activate dialog
# install pytorch
$ conda install pytorch torchvision cudatoolkit={YOUR_VERSION} -c pytorch
# install rest of depending package except for MeCab
$ pip install transformers tqdm neologdn emoji
# #### Already installed MeCab #####
# ## Ubuntu ###
$ pip install mecab-python3
# ## Windows ###
# check that "path/to/MeCab/bin" are added to system envrionment variable
$ pip install mecab-python-windows
# #### Not Installed MeCab #####
# install Mecab in accordance with your OS.
# method described in below is one of the way,
# so you can use your way if you'll be able to use transformers.BertJapaneseTokenizer.
# ## Ubuntu ###
# if you've not installed MeCab, please execute following comannds.
$ apt install aptitude
$ aptitude install mecab libmecab-dev mecab-ipadic-utf8 git make curl xz-utils file -y
$ pip install mecab-python3
# ## Windows ###
# Install MeCab from https://github.com/ikegami-yukino/mecab/releases/tag/v0.996
# and add "path/to/Mecab/bin" to system environment variable.
# then run the following command.
$ pip install mecab-python-windows # in config.py, line 24
# default value is './data'
data_dir = 'path/to/dir_contains_training_data'se você estiver pronto para começar o treinamento, execute o script principal.
$ python main.py # in config.py, line 24
# default value is './data'
data_dir = 'path/to/dir_contains_pretrained'$ python run_eval.pySe você quiser obter mais dados de conversas, use get_tweet.py
Observe que você precisa alterar consumer_key e access_token para usar este script.
E então, execute os seguintes comandos.
# usage
$ python get_tweet.py " query " " Num of continuous utterances "
# Example
# This command works until occurs errors
# and makes a file named "tweet_data_私は_5.txt" in "./data"
$ python get_tweet.py 私は 5Se você executar o comando Exemplo, o script começará a coletar 5 sentenças consecutivas se a última sentença contiver "私は".
Independentemente de como você definir 3 ou mais números para "enunciados contínuos", make_training_data.py criará automaticamente um par de enunciados.
Em seguida, execute o seguinte comando.
$ python make_training_data.pyEste script cria dados de treinamento usando './data/tweet_data_*.txt', assim como o nome.
Codificador: BERT
Decodificador: Decodificador do Vanilla Transformer
Perda: CrossEntropy
Otimizador: AdamW
Tokenizador: BertJapaneseTokenizer
Se você quiser mais informações sobre a arquitetura do BERT ou Transformer, consulte o artigo a seguir.


