Seq2seqChatbots
1.0.0
Um wrapper em torno do tensor2tensor para treinar, interagir e gerar dados de maneira flexível para chatbots neurais.
O wiki contém minhas notas e resumos de mais de 150 publicações recentes relacionadas à modelagem de diálogo neural.
? Execute seus próprios treinamentos ou experimente modelos pré-treinados
✅ 4 conjuntos de dados de diálogo diferentes integrados ao tensor2tensor
? Funciona perfeitamente com qualquer modelo ou hiperparâmetro definido em tensor2tensor
Classe base facilmente extensível para problemas de diálogo
Execute setup.py, que instala os pacotes necessários e orienta você no download de dados adicionais:
python setup.py
Você pode baixar todos os modelos treinados usados neste artigo aqui. Cada treinamento contém dois pontos de verificação, um para o mínimo de perda de validação e outro após 150 épocas. Os dados e a estrutura da pasta de treinamentos correspondem exatamente.
python t2t_csaky/main.py --mode=train
O argumento mode pode ser um dos quatro seguintes: {generate_data, train, decode, experiment} . No modo de experiência você pode especificar o que fazer dentro da função de experiência do arquivo de execução . Uma explicação detalhada é fornecida abaixo sobre o que cada modo faz.
Você pode controlar os sinalizadores e parâmetros de cada modo diretamente neste arquivo. Para cada execução iniciada, esse arquivo será copiado para o diretório apropriado, para que você possa acessar rapidamente os parâmetros de qualquer execução. Existem alguns sinalizadores que você deve definir para cada modo (o dicionário FLAGS no arquivo de configuração):
t2t_usr_dir : Caminho para o diretório onde meu código reside. Você não precisa alterar isso, a menos que renomeie o diretório.
data_dir : o caminho para o diretório onde você deseja gerar os pares de origem e destino e outros dados. O conjunto de dados será baixado um nível acima deste diretório para uma pasta raw_data .
problema : Este é o nome de um problema registrado que o tensor2tensor precisa. Detalhado na seção generate_data abaixo. Todos os caminhos devem vir da raiz do repositório.
Este modo baixará e pré-processará os dados e gerará pares de origem e destino. Atualmente existem 6 problemas cadastrados, que você pode utilizar além dos indicados pelo tensor2tensor:
persona_chat_chatbot : Este problema implementa o conjunto de dados Persona-Chat (sem o uso de personas).
daily_dialog_chatbot : Este problema implementa o conjunto de dados DailyDialog (sem o uso de tópicos, atos de diálogo ou emoções).
opensubtitles_chatbot : Este problema pode ser usado para trabalhar com o conjunto de dados OpenSubtitles.
cornell_chatbot_basic : Este problema implementa o Cornell Movie-Dialog Corpus.
cornell_chatbot_separate_names : Este problema usa o mesmo corpus Cornell, porém os nomes dos locutores e destinatários de cada enunciado são anexados, resultando em enunciados de origem como abaixo.
BIANCA_m0 que coisa boa? CAMERON_m0
character_chatbot : Este é um problema geral baseado em caracteres que funciona com qualquer conjunto de dados. Antes de usar isso, os arquivos .txt gerados por qualquer um dos problemas acima devem ser colocados dentro do diretório de dados, e depois disso este problema pode ser usado para gerar arquivos de dados baseados em caracteres tensor2tensor.
O dicionário PROBLEM_HPARAMS no arquivo de configuração contém parâmetros específicos do problema que você pode definir antes de gerar dados:
num_train_shards / num_dev_shards : se você deseja que os dados de treinamento ou desenvolvimento gerados sejam fragmentados em vários arquivos.
vocabulário_size : Tamanho do vocabulário que queremos usar para o problema. Palavras fora deste vocabulário serão substituídas pelo token.
dataset_size : Número de pares de enunciados, caso não queiramos usar o conjunto de dados completo (definido por 0).
dataset_split : Especifique uma divisão train-val-test para o problema.
dataset_version : Isto é relevante apenas para o conjunto de dados opensubtitles, uma vez que existem várias versões deste conjunto de dados, você pode especificar o ano do conjunto de dados que deseja baixar.
name_vocab_size : Isso é relevante apenas para o problema Cornell com nomes separados. Você pode definir o tamanho do vocabulário contendo apenas as personas.
Este modo permite treinar um modelo com o problema e hiperparâmetros especificados. O código apenas chama o script de treinamento tensor2tensor, portanto, qualquer modelo que esteja em tensor2tensor pode ser usado. Além destes, existe também um modelo subclassificado com pequenas modificações:
gradiente_checkpointed_seq2seq : Pequena modificação do modelo seq2seq baseado em lstm, para que os próprios hparams possam ser usados inteiramente. Antes de calcular o softmax, as unidades ocultas LSTM são projetadas para 2.048 unidades lineares como aqui. Por fim, tentei implementar o checkpoint de gradiente neste modelo, mas atualmente ele foi retirado porque não deu bons resultados.
Existem vários sinalizadores adicionais que você pode especificar para uma execução de treinamento no dicionário FLAGS no arquivo de configuração, alguns dos quais são:
train_dir : Nome do diretório onde serão salvos os arquivos do checkpoint de treinamento.
model : Nome do modelo: um dos acima ou um modelo definido por tensor2tensor.
hparams : Especifique um hparams_set registrado ou deixe em branco se desejar definir hparams no arquivo de configuração. Para especificar hparams para um modelo seq2seq ou transformador , você pode usar os dicionários SEQ2SEQ_HPARAMS e TRANSFORMER_HPARAMS no arquivo de configuração (verifique para mais detalhes).
Com este modo você pode decodificar a partir dos modelos treinados. Os seguintes parâmetros afetam a decodificação (no dicionário FLAGS no arquivo de configuração):
decode_mode : Pode ser interativo , onde você pode conversar com o modelo usando a linha de comando. o modo de arquivo permite que você especifique um arquivo com declarações de origem para as quais gerar respostas, e o modo de conjunto de dados amostrará aleatoriamente os dados de validação fornecidos e produzirá respostas.
decode_dir : diretório onde você pode fornecer o arquivo para decodificação e as respostas geradas serão salvas aqui.
input_file_name : Nome do arquivo que você deve fornecer no modo arquivo (colocado em decode_dir ).
output_file_name : Nome do arquivo, dentro de decode_dir , onde as respostas de saída serão salvas.
beam_size : Tamanho do feixe, ao usar a pesquisa de feixe.
return_beams : Se False retornar apenas a viga superior, caso contrário, retornará beam_size o número de vigas.
Os resultados a seguir são desses dois artigos.
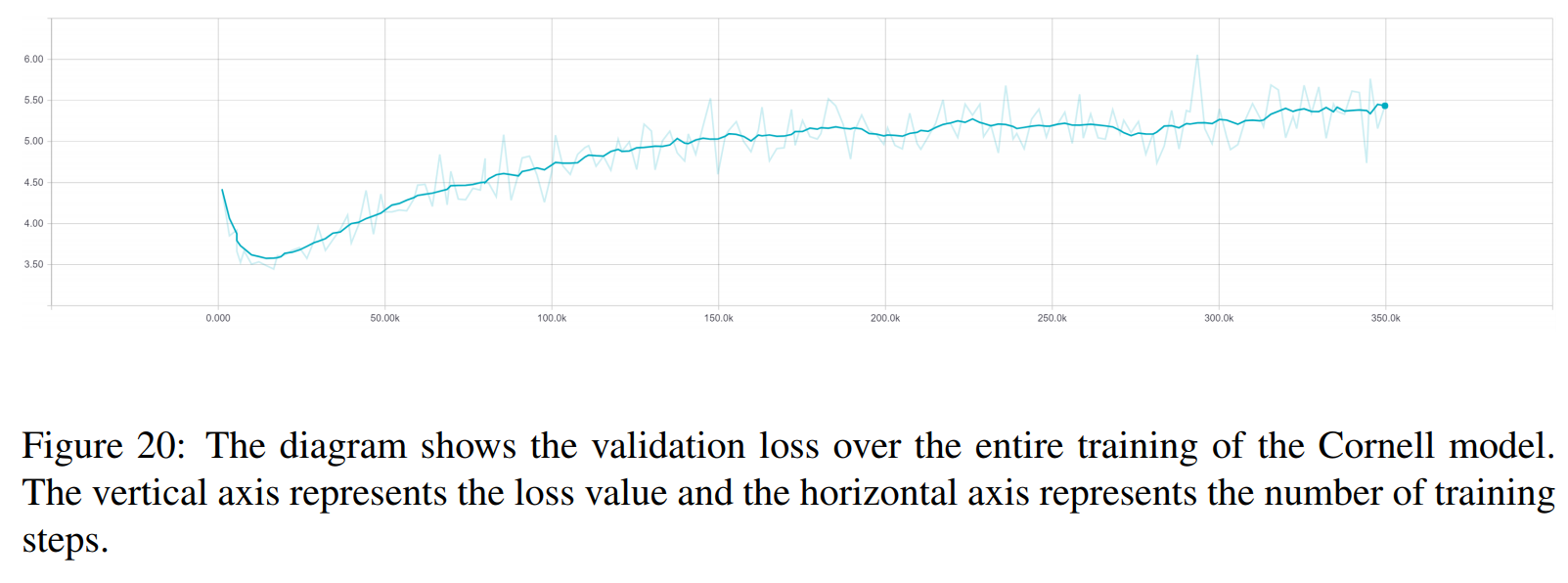

TRF é o modelo Transformer, enquanto RT significa respostas selecionadas aleatoriamente do conjunto de treinamento e GT significa respostas verdadeiras. Para uma explicação das métricas, consulte o artigo.
S2S é um modelo seq2seq simples com LSTMs treinados em Cornell, outros são modelos Transformer. Opensubtitles F é pré-treinado em Opensubtitles e ajustado em Cornell. 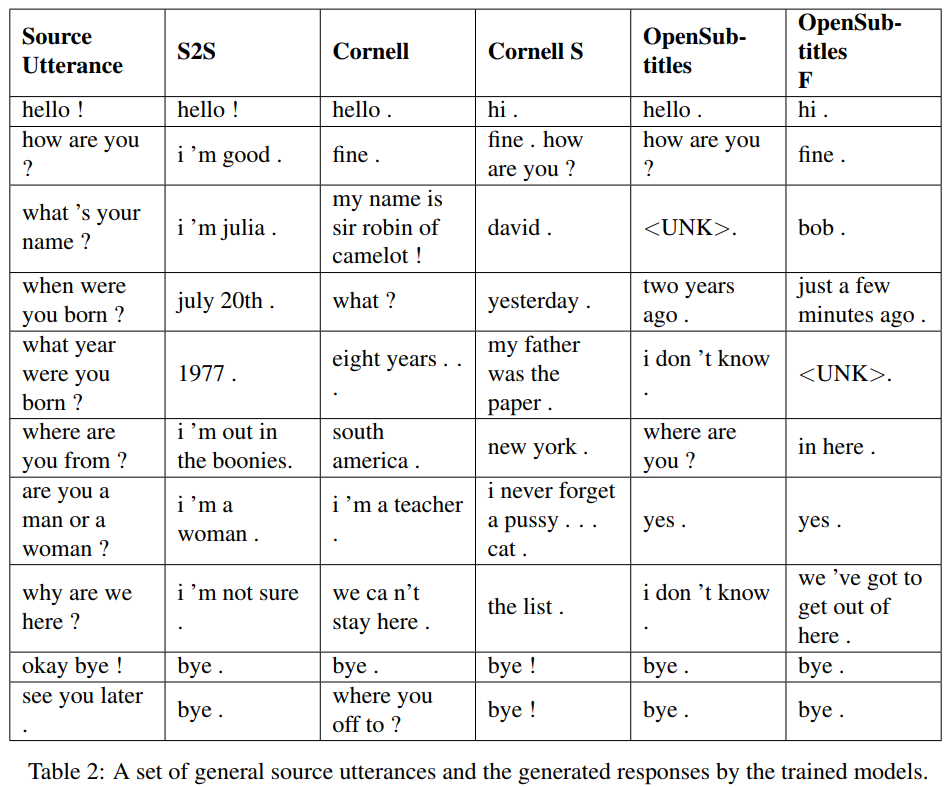
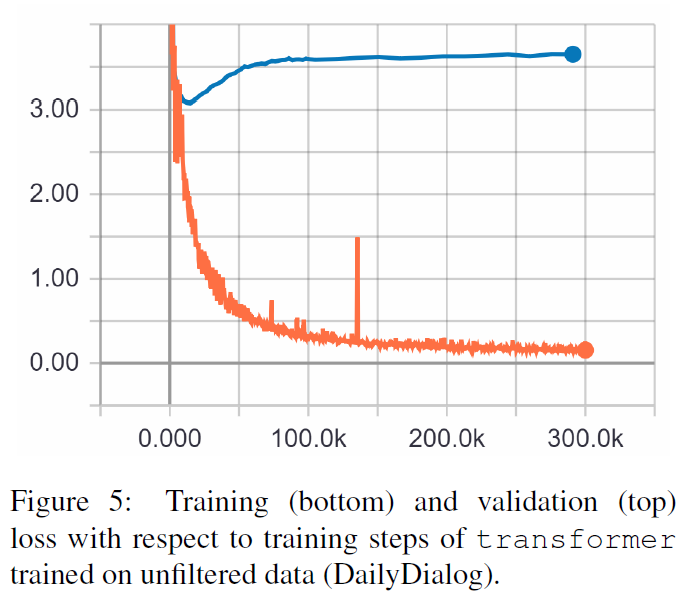

TRF é o modelo Transformer, enquanto RT significa respostas selecionadas aleatoriamente do conjunto de treinamento e GT significa respostas verdadeiras. Para uma explicação das métricas, consulte o artigo.
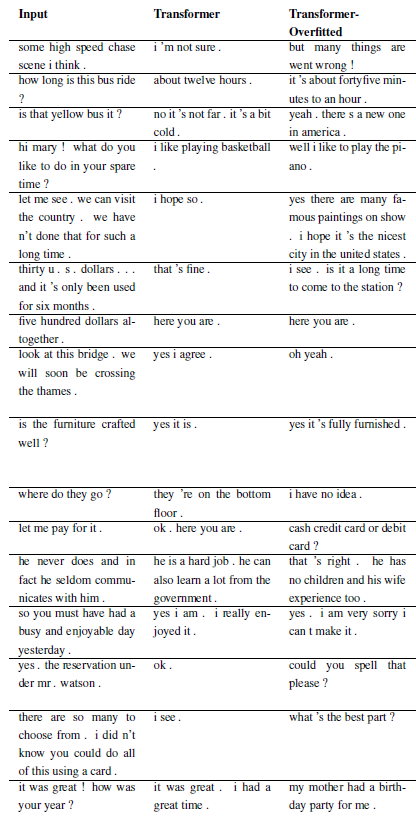
Novos problemas podem ser registrados subclassificando WordChatbot, ou melhor ainda, subclassificando CornellChatbotBasic ou OpensubtitleChatbot, pois implementam algumas funcionalidades adicionais. Geralmente é suficiente substituir as funções preprocess e create_data . Verifique a documentação para mais detalhes e veja daily_dialog_chatbot para ver um exemplo.
Novos modelos e hiperparâmetros podem ser adicionados seguindo o tutorial tensor2tensor.
Richard Csaky (se precisar de ajuda para executar o código: [email protected])
Este projeto está licenciado sob a licença MIT - consulte o arquivo LICENSE para obter detalhes.
Inclua um link para este repositório se você usá-lo em seu trabalho e considere citar o seguinte artigo:
@InProceedings{Csaky:2017,
title = {Deep Learning Based Chatbot Models},
author = {Csaky, Richard},
year = {2019},
publisher={National Scientific Students' Associations Conference},
url ={https://tdk.bme.hu/VIK/DownloadPaper/asdad},
note={https://tdk.bme.hu/VIK/DownloadPaper/asdad}
} 

