Multi Modality Arena
1.0.0
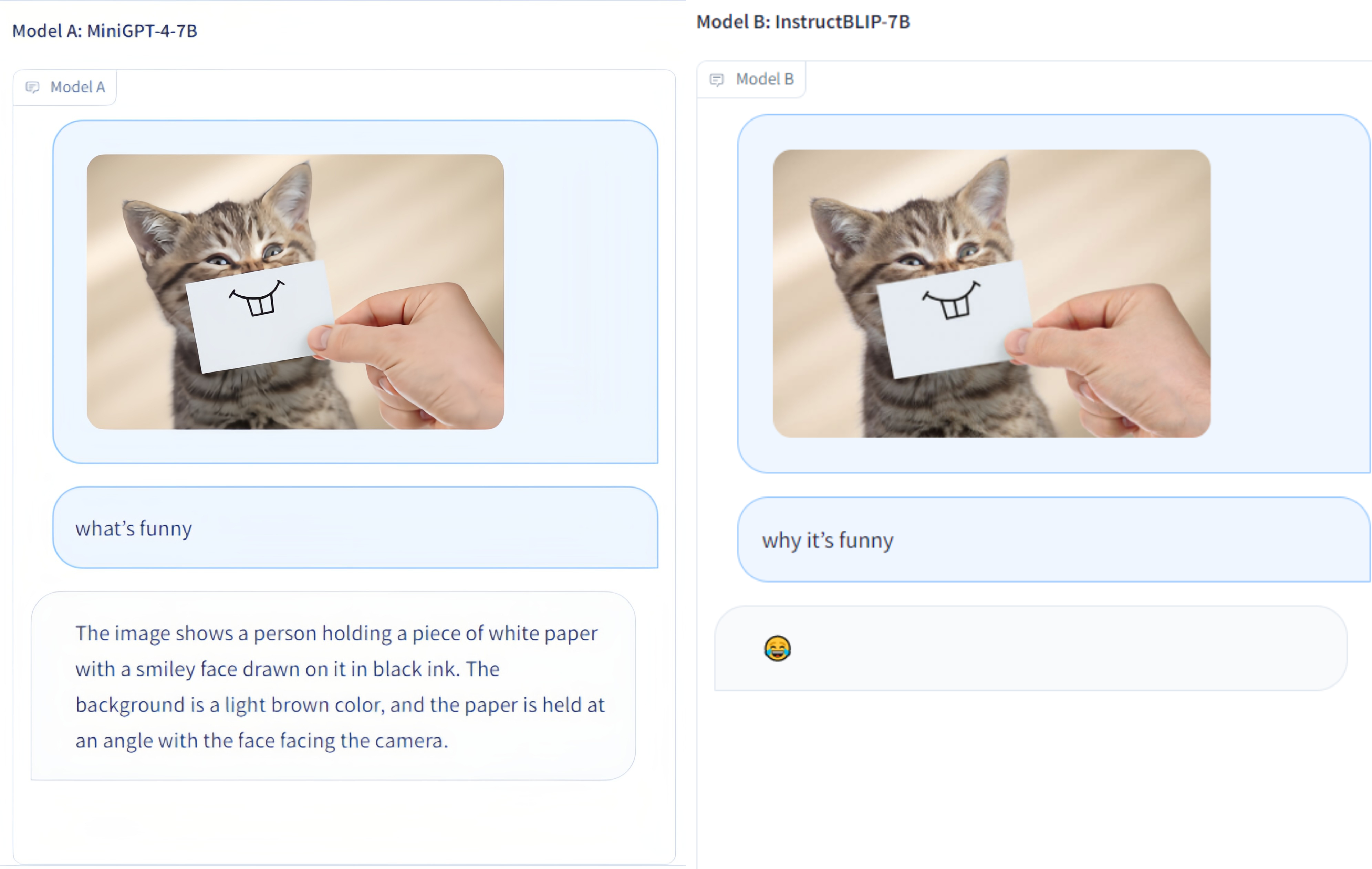
Multi-Modality Arena é uma plataforma de avaliação de grandes modelos multimodais. Seguindo o Fastchat, dois modelos anônimos lado a lado são comparados em uma tarefa visual de resposta a perguntas. Divulgamos a Demo e agradecemos a participação de todos nesta iniciativa de avaliação.
Conjunto de dados OmniMedVQA: contém 118.010 imagens com 127.995 itens de controle de qualidade, cobrindo 12 modalidades diferentes e referindo-se a mais de 20 regiões anatômicas humanas. O conjunto de dados pode ser baixado aqui.
12 modelos: 8 LVLMs de domínio geral e 4 LVLMs médicos especializados.
Conjuntos de dados minúsculos: apenas 50 amostras selecionadas aleatoriamente para cada conjunto de dados, ou seja, 42 benchmarks visuais relacionados a texto e 2,1 mil amostras no total para facilidade de uso.
Mais modelos: mais 4 modelos, ou seja, 12 modelos no total, incluindo o Google Bard .
Avaliação do conjunto ChatGPT : melhor concordância com a avaliação humana do que a abordagem anterior de correspondência de palavras.
LVLM-eHub é um benchmark de avaliação abrangente para grandes modelos multimodais (LVLM) disponíveis ao público. Avalia extensivamente
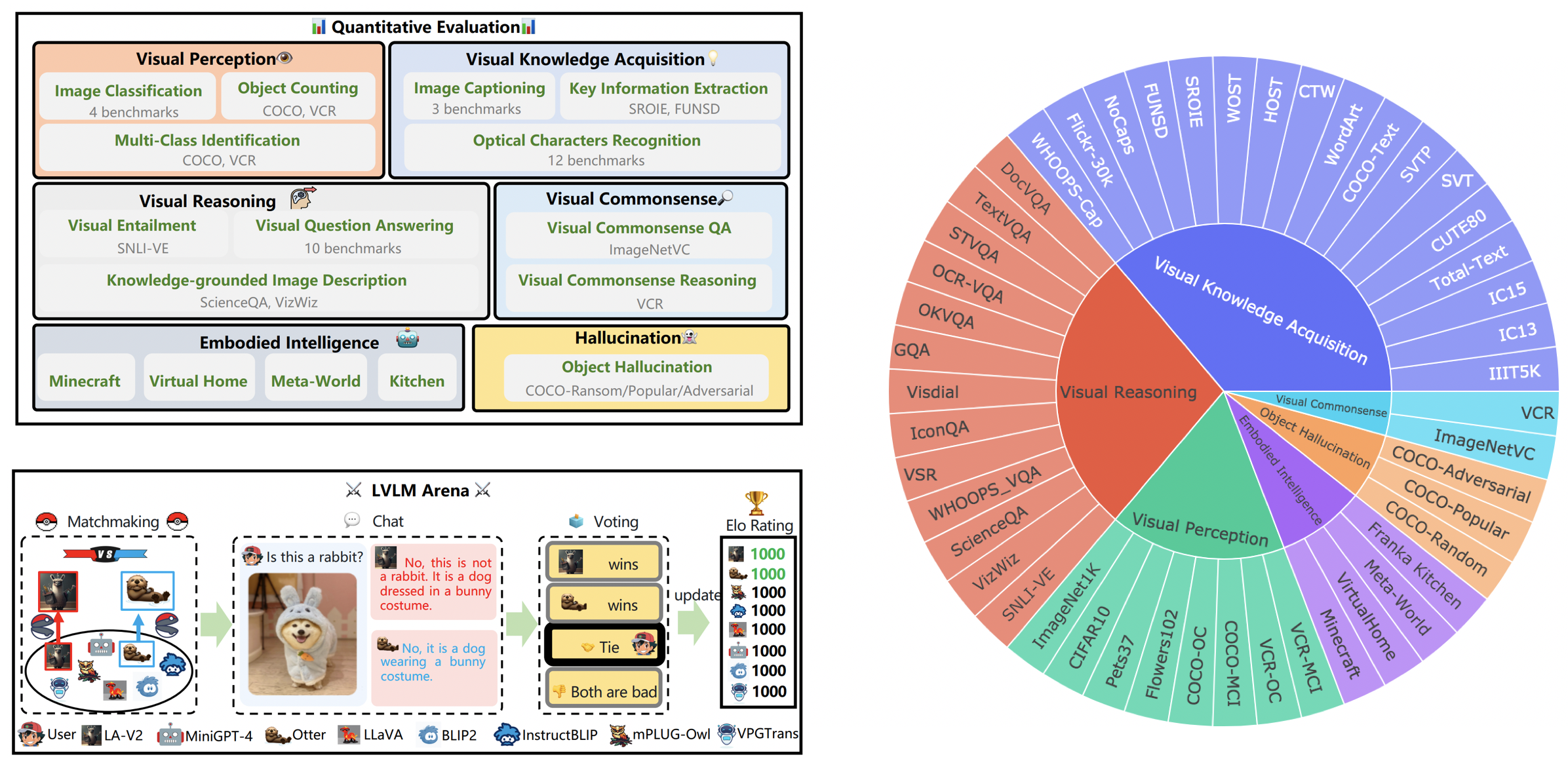
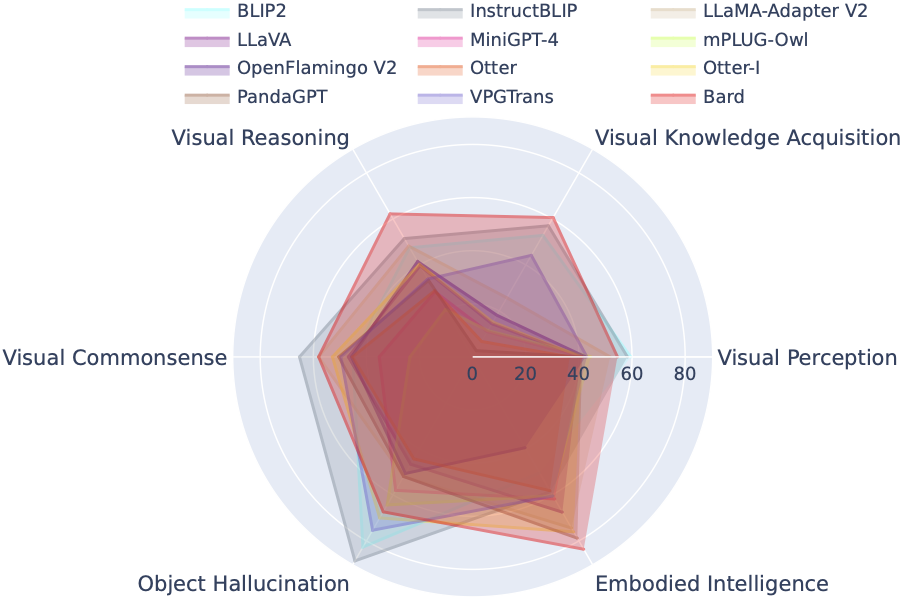
O Leaderboard LVLM categoriza sistematicamente os conjuntos de dados apresentados na Avaliação Tiny LVLM de acordo com suas habilidades específicas, incluindo percepção visual, raciocínio visual, senso comum visual, aquisição de conhecimento visual e alucinação de objetos. Esta tabela de classificação inclui modelos lançados recentemente para reforçar sua abrangência.
Você pode baixar o benchmark aqui e mais detalhes podem ser encontrados aqui.
| Classificação | Modelo | Versão | Pontuação |
|---|---|---|---|
| 1 | EstagiárioVL | EstagiárioVL-Chat | 327,61 |
| 2 | EstagiárioLM-XComposer-VL | EstagiárioLM-XComposer-VL-7B | 322,51 |
| 3 | Bardo | Bardo | 319,59 |
| 4 | Qwen-VL-Chat | Qwen-VL-Chat | 316,81 |
| 5 | LLaVA-1.5 | Vicunha-7B | 307.17 |
| 6 | InstruirBLIP | Vicunha-7B | 300,64 |
| 7 | EstagiárioLM-XComposer | EstagiárioLM-XComposer-7B | 288,89 |
| 8 | BLIP2 | FlaneT5xl | 284,72 |
| 9 | BLIVA | Vicunha-7B | 284,17 |
| 10 | Lince | Vicunha-7B | 279,24 |
| 11 | Chita | Vicunha-7B | 258,91 |
| 12 | Adaptador LLaMA-v2 | LLaMA-7B | 229.16 |
| 13 | VPGTrans | Vicunha-7B | 218,91 |
| 14 | Imagem de lontra | Lontra-9B-LA-InContext | 216,43 |
| 15 | VisualGLM-6B | VisualGLM-6B | 211,98 |
| 16 | mPLUG-Coruja | LLaMA-7B | 209,40 |
| 17 | LLaVA | Vicunha-7B | 200,93 |
| 18 | MiniGPT-4 | Vicunha-7B | 192,62 |
| 19 | Lontra | Lontra-9B | 180,87 |
| 20 | OFv2_4BI | RedPajama-INCITE-Instruct-3B-v1 | 176,37 |
| 21 | PandaGPT | Vicunha-7B | 174,25 |
| 22 | Lavin | LLaMA-7B | 97,51 |
| 23 | Microfone | FlaneT5xl | 94.09 |
31 de março de 2024. Lançamos OmniMedVQA, um benchmark de avaliação abrangente em larga escala para LVLMs médicos. Enquanto isso, temos 8 LVLMs de domínio geral e 4 LVLMs especializados em medicina. Para mais detalhes, visite o MedicalEval.
16 de outubro de 2023. Apresentamos uma divisão do conjunto de dados em nível de capacidade derivada do LVLM-eHub, complementada pela inclusão de oito modelos lançados recentemente. Para acesso às divisões do conjunto de dados, código de avaliação, resultados de inferência de modelo e tabelas de desempenho abrangentes, visite tiny_lvlm_evaluation ✅.
8 de agosto de 2023. Lançamos [Tiny LVLM-eHub] . Os códigos-fonte da avaliação e os resultados da inferência do modelo são de código aberto em tiny_lvlm_evaluation.
15 de junho de 2023. Lançamos [LVLM-eHub] , um benchmark de avaliação para grandes modelos de linguagem de visão. O código estará disponível em breve.
8 de junho de 2023. Obrigado, Dr. Zhang, autor do VPGTrans, por suas correções. Os autores do VPGTrans vêm principalmente da NUS e da Universidade Tsinghua. Anteriormente, tivemos alguns pequenos problemas ao reimplementar o VPGTrans, mas descobrimos que seu desempenho é realmente melhor. Para mais autores de modelos, entre em contato comigo para discussão no e-mail. Além disso, siga nossa lista de classificação de modelos, onde resultados mais precisos estarão disponíveis.
Poderia. 22, 2023. Obrigado, Dr. Ye, autor de mPLUG-Owl, por suas correções. Corrigimos alguns pequenos problemas em nossa implementação do mPLIG-Owl.
Os seguintes modelos estão envolvidos em batalhas aleatórias atualmente,
KAUST/MiniGPT-4
Salesforce/BLIP2
Salesforce/InstructBLIP
Academia DAMO/mPLUG-Coruja
NTU/Lontra
Universidade de Wisconsin-Madison/LLaVA
Laboratório de IA de Xangai/llama_adapter_v2
NUS/VPGTrans
Mais detalhes sobre esses modelos podem ser encontrados em ./model_detail/.model.jpg . Tentaremos agendar recursos computacionais para hospedar mais modelos multimodais na arena.
Se você estiver interessado em alguma peça da nossa plataforma VLarena, fique à vontade para entrar no grupo Wechat.

Criar ambiente conda
conda criar -n arena python=3.10 conda ativar arena
Instale os pacotes necessários para executar o controlador e o servidor
pip instalar numpy gradio uvicorn fastapi
Então, para cada modelo, eles podem exigir versões conflitantes de pacotes python. Recomendamos a criação de um ambiente específico para cada modelo com base em seu repositório GitHub.
Para servir usando a UI da web, você precisa de três componentes principais: servidores da web que fazem interface com os usuários, trabalhadores de modelo que hospedam dois ou mais modelos e um controlador para coordenar o servidor da web e os trabalhadores de modelo.
Aqui estão os comandos a seguir em seu terminal:
controlador python.py
Este controlador gerencia os trabalhadores distribuídos.
python model_worker.py --nome do modelo SELECTED_MODEL --device TARGET_DEVICE
Espere até que o processo termine de carregar o modelo e você veja "Uvicorn rodando em ...". O modelo de trabalho se registrará no controlador. Para cada modelo de trabalho, você precisa especificar o modelo e o dispositivo que deseja usar.
python servidor_demo.py
Esta é a interface do usuário com a qual os usuários interagirão.
Seguindo essas etapas, você poderá servir seus modelos usando a UI da web. Você pode abrir seu navegador e conversar com uma modelo agora. Se os modelos não aparecerem, tente reiniciar o servidor web Gradio.
Valorizamos profundamente todas as contribuições destinadas a melhorar a qualidade das nossas avaliações. Esta seção compreende dois segmentos principais: Contributions to LVLM Evaluation e Contributions to LVLM Arena .
Você pode acessar a versão mais recente do nosso código de avaliação na pasta LVLM_evaluation. Este diretório abrange um conjunto abrangente de códigos de avaliação, acompanhado dos conjuntos de dados necessários. Se você estiver entusiasmado em participar do processo de avaliação, não hesite em compartilhar seus resultados de avaliação ou a API de inferência de modelo conosco por e-mail em [email protected].
Agradecemos seu interesse em integrar seu modelo em nossa LVLM Arena! Caso deseje incorporar seu modelo em nossa Arena, por favor prepare um testador de modelo estruturado da seguinte forma:
class ModelTester:def __init__(self, device=None) -> None:# TODO: inicialização do modelo e pré-processadores necessáriosdef move_to_device(self, device) -> None:# TODO: esta função é usada para transferir o modelo entre CPU e GPU (opcional)def generate(self, image, question) -> str: # TODO: código de inferência do modelo
Além disso, estamos abertos a links de inferência de modelos online, como os fornecidos por plataformas como Gradio. Suas contribuições são sinceramente apreciadas.
Expressamos nossa gratidão à estimada equipe da ChatBot Arena e ao seu artigo Judging LLM-as-a-juiz por seu trabalho influente, que serviu de inspiração para nossos esforços de avaliação do LVLM. Gostaríamos também de estender o nosso sincero agradecimento aos fornecedores de LVLMs, cujas valiosas contribuições contribuíram significativamente para o progresso e avanço de grandes modelos de linguagem de visão. Por fim, agradecemos aos fornecedores dos conjuntos de dados utilizados em nosso LVLM-eHub.
O projeto é uma ferramenta de pesquisa experimental apenas para fins não comerciais. Possui salvaguardas limitadas e pode gerar conteúdo impróprio. Não pode ser usado para nada ilegal, prejudicial, violento, racista ou sexual.


