GenDataAttribution
1.0.0
Projeto | Papel
Sheng-Yu Wang 1 , Alexei A. Efros 2 , Jun-Yan Zhu 1 , Richard Zhang 3 .
Universidade Carnegie Mellon 1 , UC Berkeley 2 , Adobe Research 2
Em ICCV, 2023.
Embora grandes modelos de texto para imagem sejam capazes de sintetizar imagens "novas", essas imagens são necessariamente um reflexo dos dados de treinamento. O problema da atribuição de dados em tais modelos – quais das imagens no conjunto de treinamento são as mais responsáveis pela aparência de uma determinada imagem gerada – é difícil, mas importante. Como passo inicial em direção a esse problema, avaliamos a atribuição por meio de métodos de “customização”, que ajustam um modelo existente em grande escala a um determinado objeto ou estilo exemplar. Nosso principal insight é que isso nos permite criar com eficiência imagens sintéticas que são influenciadas computacionalmente pelo exemplar por construção. Com nosso novo conjunto de dados de imagens influenciadas por exemplares, somos capazes de avaliar vários algoritmos de atribuição de dados e diferentes espaços de recursos possíveis. Além disso, treinando em nosso conjunto de dados, podemos ajustar modelos padrão, como DINO, CLIP e ViT, para o problema de atribuição. Embora o procedimento seja ajustado para conjuntos de exemplares pequenos, mostramos generalização para conjuntos maiores. Finalmente, levando em consideração a incerteza inerente ao problema, podemos atribuir pontuações de atribuição suave sobre um conjunto de imagens de treinamento.
conda env create -f environment.yaml
conda activate gen-attr # Download precomputed features of 1M LAION images
bash feats/download_laion_feats.sh
# Download jpeg-ed 1M LAION images for visualization
bash dataset/download_dataset.sh laion_jpeg
# Download pretrained models
bash weights/download_weights.sh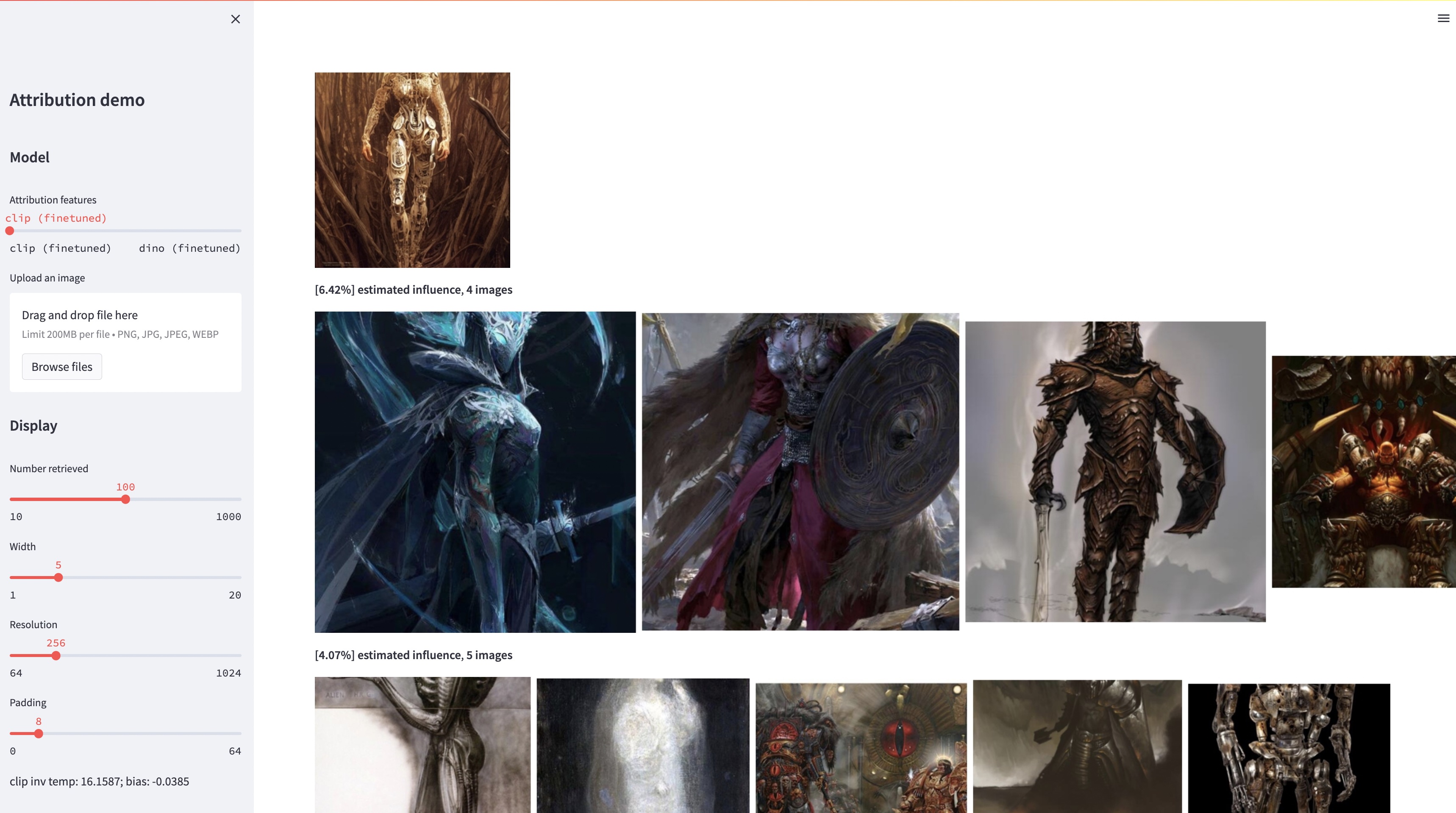
streamlit run streamlit_demo.pyLiberamos nosso conjunto de testes para avaliação. Para baixar o conjunto de dados:
# Download the exemplar real images
bash dataset/download_dataset.sh exemplar
# Download the testset portion of images synthesized from Custom Diffusion
bash dataset/download_dataset.sh testset
# (Optional, can download precomputed features instead!)
# Download the uncompressed 1M LAION subset in pngs
bash dataset/download_dataset.sh laionO conjunto de dados está estruturado da seguinte forma:
dataset
├── exemplar
│ ├── artchive
│ ├── bamfg
│ └── imagenet
├── synth
│ ├── artchive
│ ├── bamfg
│ └── imagenet
├── laion_subset
└── json
├──test_artchive.json
├──test_bamfg.json
├──...
Todas as imagens exemplares são armazenadas em dataset/exemplar , todas as imagens sintetizadas são armazenadas em dataset/synth e 1 milhão de imagens laion em pngs são armazenadas em dataset/laion_subset . Os arquivos JSON em dataset/json especificam as divisões train/val/test, incluindo diferentes casos de teste, e servem como rótulos de verdade. Cada entrada dentro de um arquivo JSON é um modelo exclusivo e ajustado. Uma entrada também registra as imagens exemplares usadas para ajuste fino e as imagens sintetizadas geradas pelo modelo. Temos quatro casos de teste: test_artchive.json , test_bamfg.json , test_observed_imagenet.json e test_unobserved_imagenet.json .
Após o download do conjunto de testes, dos recursos LAION pré-computados e dos pesos pré-treinados, podemos pré-calcular os recursos do conjunto de testes executando extract_feat.py e, em seguida, avaliar o desempenho executando eval.py . Abaixo estão os scripts bash que executam a avaliação em lotes:
# precompute all features from the testset
bash scripts/preprocess_feats.sh
# run evaluation in batches
bash scripts/run_eval.sh As métricas são armazenadas em arquivos .pkl nos results . Atualmente, o script executa cada comando sequencialmente. Sinta-se à vontade para modificá-lo para executar os comandos em paralelo. O comando a seguir analisará os arquivos .pkl em tabelas armazenadas como arquivos .csv :
python results_to_csv.py Atualização de 18/12/2023 Para baixar modelos treinados apenas em modelos centrados em objeto ou centrados em estilo, execute bash weights/download_style_object_ablation.sh
@inproceedings{wang2023evaluating,
title={Evaluating Data Attribution for Text-to-Image Models},
author={Wang, Sheng-Yu and Efros, Alexei A. and Zhu, Jun-Yan and Zhang, Richard},
booktitle={ICCV},
year={2023}
}
Agradecemos a Aaron Hertzmann pela leitura de um rascunho anterior e pelo feedback esclarecedor. Agradecemos aos colegas da Adobe Research, incluindo Eli Shechtman, Oliver Wang, Nick Kolkin, Taesung Park, John Collomosse e Sylvain Paris, juntamente com Alex Li e Yonglong Tian pela discussão útil. Agradecemos Nupur Kumari pela orientação com o treinamento de difusão personalizada, Ruihan Gao pela revisão do rascunho, Alex Li pelas dicas para extrair recursos de difusão estável e Dan Ruta pela ajuda com o conjunto de dados BAM-FG. Agradecemos a Bryan Russell pelas caminhadas e brainstorming sobre a pandemia. Este trabalho começou quando SYW era estagiário da Adobe e foi apoiado em parte por uma doação da Adobe e pelo prêmio de pesquisa do corpo docente do JP Morgan Chase.


