clearml fractional gpu
1.0.0
? Leave a star to support the project! ?
Compartilhar GPUs de última geração ou até mesmo GPUs de prosumidores e consumidores entre vários usuários é a maneira mais econômica de acelerar o desenvolvimento de IA. Infelizmente, até agora a única solução existente aplicada a GPUs de ponta MIG/Slicing (A100+) e Kubernetes necessários,
? Bem-vindo à GPU fracionária baseada em contêiner para qualquer placa Nvidia! ?
Apresentamos contêineres pré-empacotados com suporte para CUDA 11.x e CUDA 12.x com limitação de memória rígida pré-construída! Isso significa que vários contêineres podem ser iniciados na mesma GPU, garantindo que um usuário não possa alocar toda a memória da GPU do host! (Chega de processos gananciosos que ocupam toda a memória da GPU! Finalmente, temos uma opção de memória com limitação rígida no nível do driver).
ClearML oferece várias opções para otimizar a utilização de recursos de GPU particionando GPUs:
Com essas opções, o ClearML permite a execução de cargas de trabalho de IA com utilização de hardware e desempenho de carga de trabalho otimizados. Este repositório cobre GPUs fracionárias baseadas em contêiner. Para obter mais informações sobre as ofertas de GPU fracionária do ClearML, consulte a documentação do ClearML.
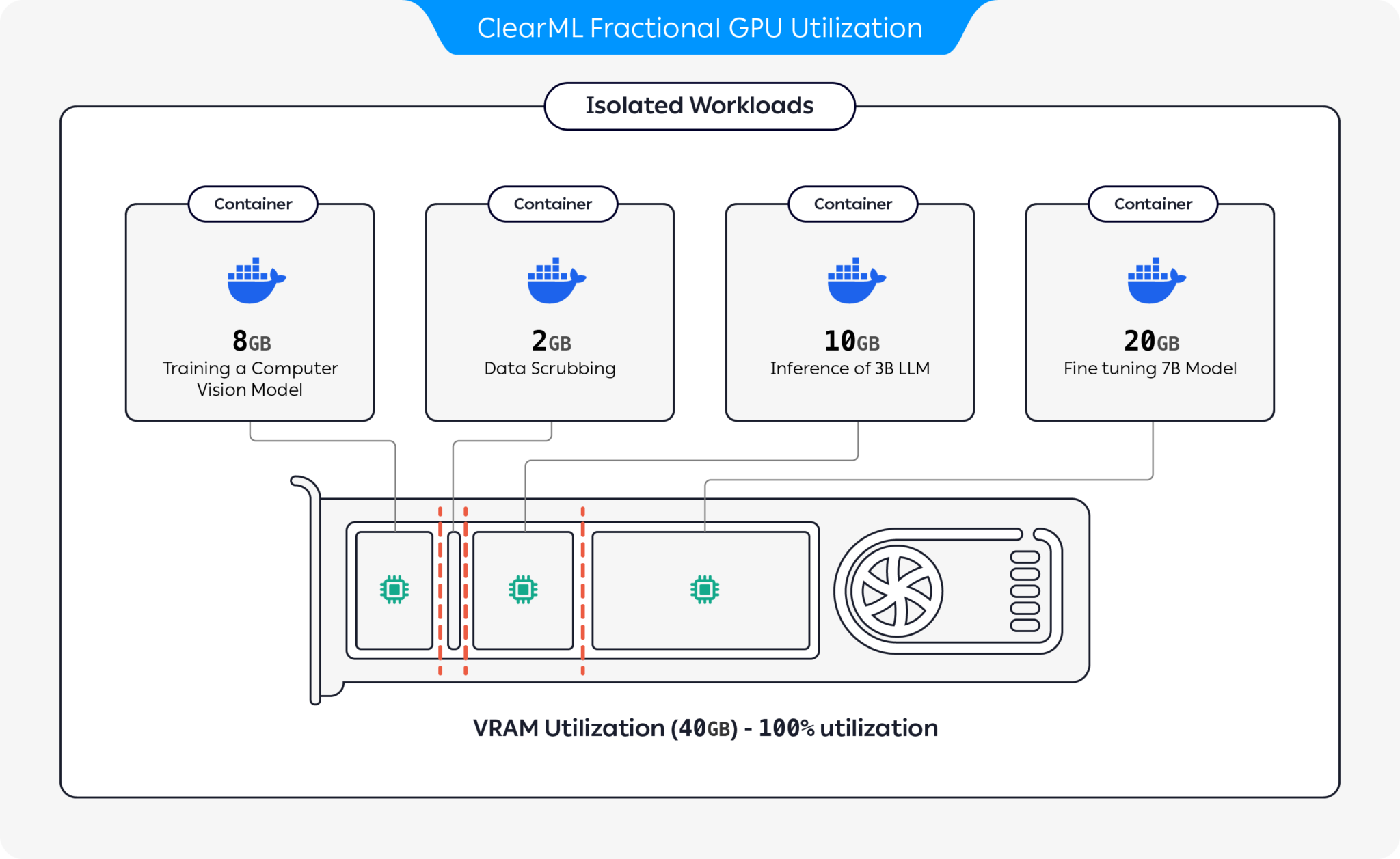
Escolha o contêiner que funciona para você e execute-o:
docker run -it --gpus 0 --ipc=host --pid=host clearml/fractional-gpu:u22-cu12.3-8gb bashPara verificar se o limite de memória da GPU está funcionando corretamente, execute dentro do contêiner:
nvidia-smiAqui está um exemplo de saída da GPU A100:
+---------------------------------------------------------------------------------------+
| NVIDIA-SMI 545.23.08 Driver Version: 545.23.08 CUDA Version: 12.3 |
|-----------------------------------------+----------------------+----------------------+
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+======================+======================|
| 0 A100-PCIE-40GB Off | 00000000:01:00.0 Off | N/A |
| 32% 33C P0 66W / 250W | 0MiB / 8128MiB | 3% Default |
| | | Disabled |
+-----------------------------------------+----------------------+----------------------+
+---------------------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=======================================================================================|
+---------------------------------------------------------------------------------------+
| Limite de memória | Versão CUDA | Ubuntu versão | Imagem Docker |
|---|---|---|---|
| 12 GB | 12.3 | 22.04 | clearml/fractional-gpu:u22-cu12.3-12gb |
| 12 GB | 12.3 | 20.04 | clearml/fractional-gpu:u20-cu12.3-12gb |
| 12GB | 11.7 | 22.04 | clearml/fractional-gpu:u22-cu11.7-12gb |
| 12GB | 11.1 | 20.04 | clearml/fractional-gpu:u20-cu11.1-12gb |
| 8 GB | 12.3 | 22.04 | clearml/fractional-gpu:u22-cu12.3-8gb |
| 8GB | 12.3 | 20.04 | clearml/fractional-gpu:u20-cu12.3-8gb |
| 8 GB | 11.7 | 22.04 | clearml/fractional-gpu:u22-cu11.7-8gb |
| 8 GB | 11.1 | 20.04 | clearml/fractional-gpu:u20-cu11.1-8gb |
| 4GB | 12.3 | 22.04 | clearml/fractional-gpu:u22-cu12.3-4gb |
| 4GB | 12.3 | 20.04 | clearml/fractional-gpu:u20-cu12.3-4gb |
| 4GB | 11.7 | 22.04 | clearml/fractional-gpu:u22-cu11.7-4gb |
| 4GB | 11.1 | 20.04 | clearml/fractional-gpu:u20-cu11.1-4gb |
| 2GB | 12.3 | 22.04 | clearml/fractional-gpu:u22-cu12.3-2gb |
| 2GB | 12.3 | 20.04 | clearml/fractional-gpu:u20-cu12.3-2gb |
| 2GB | 11.7 | 22.04 | clearml/fractional-gpu:u22-cu11.7-2gb |
| 2GB | 11.1 | 20.04 | clearml/fractional-gpu:u20-cu11.1-2gb |
Importante
Você deve executar o contêiner com --pid=host !
Observação
--pid=host é necessário para permitir que o driver diferencie entre os processos do contêiner e outros processos do host ao limitar o uso de memória/utilização
Dica
Os usuários do ClearML-Agent adicionam [--pid=host] à seção agent.extra_docker_arguments em seu arquivo de configuração
Construa seus próprios contêineres e herde os contêineres originais.
Você pode encontrar alguns exemplos aqui.
Os contêineres de GPU fracionários podem ser usados em execuções bare-metal, bem como em PODs do Kubernetes. Sim! Ao usar um dos contêineres de GPU fracionária, você pode limitar o consumo de memória de seu trabalho/pod e compartilhar GPUs facilmente sem temer que a memória delas falhe uma com a outra!
Aqui está um modelo POD simples do Kubernetes:
apiVersion : v1
kind : Pod
metadata :
name : train-pod
labels :
app : trainme
spec :
hostPID : true
containers :
- name : train-container
image : clearml/fractional-gpu:u22-cu12.3-8gb
command : ['python3', '-c', 'print(f"Free GPU Memory: (free, global) {torch.cuda.mem_get_info()}")'] Importante
Você deve executar o pod com hostPID: true !
Observação
hostPID: true é necessário para permitir que o driver diferencie entre os processos do pod e outros processos do host ao limitar o uso de memória/utilização
Os contêineres suportam drivers Nvidia <= 545.xx . Continuaremos atualizando e oferecendo suporte a novos drivers à medida que eles forem lançados
GPUs suportadas : RTX séries 10, 20, 30, 40, série A e Data-Center P100, A100, A10/A40, L40/s, H100
Limitações : Atualmente, as máquinas Windows Host não são suportadas. Se isso for importante para você, deixe uma solicitação na seção Problemas
P : A execução nvidia-smi dentro do contêiner reportará o consumo de GPU dos processos locais?
R : Sim, nvidia-smi está se comunicando diretamente com os drivers de baixo nível e relata a memória precisa da GPU do contêiner, bem como a limitação da memória local do contêiner.
Observe que a utilização da GPU será a utilização global da GPU (ou seja, do lado do host) e não a utilização específica da GPU do contêiner local.
P : Como posso ter certeza de que meu Python/Pytorch/Tensorflow tem memória limitada?
R : Para PyTorch você pode executar:
import torch
print ( f'Free GPU Memory: (free, global) { torch . cuda . mem_get_info () } ' )Exemplo Numba:
from numba import cuda
print ( f'Free GPU Memory: { cuda . current_context (). get_memory_info () } ' ) P : A limitação pode ser quebrada por um usuário?
R : Temos certeza de que um usuário mal-intencionado encontrará uma maneira. Nunca foi nossa intenção proteger contra usuários mal-intencionados.
Se você tem um usuário mal-intencionado com acesso às suas máquinas, as GPUs fracionárias não são o seu problema número 1?
P : Como posso detectar programaticamente a limitação de memória?
R : Você pode verificar a variável de ambiente do sistema operacional GPU_MEM_LIMIT_GB .
Observe que alterá-lo não removerá nem reduzirá a limitação.
P : A execução do contêiner com --pid=host é segura/segura?
R : Deve ser seguro e protegido. A principal ressalva do ponto de vista da segurança é que um processo de contêiner pode ver qualquer linha de comando em execução no sistema host. Se a linha de comando de um processo contiver um "segredo", então sim, isso pode se tornar um possível vazamento de dados. Observe que passar "segredos" na linha de comando é imprudente e, portanto, não consideramos isso um risco à segurança. Dito isto, se a segurança é fundamental, a edição empresarial (veja abaixo) elimina a necessidade de executar com pid-host e, portanto, é totalmente segura.
P : Você pode executar o contêiner sem --pid=host ?
R : Você pode! Mas você terá que usar a versão corporativa do contêiner clearml-fractional-gpu (caso contrário, o limite de memória será aplicado em todo o sistema, em vez de em todo o contêiner). Se esse recurso for importante para você, entre em contato com vendas e suporte da ClearML.
A licença para usar ClearML é concedida apenas para fins de pesquisa ou desenvolvimento. ClearML pode ser usado para uso educacional, pessoal ou comercial interno.
Uma licença comercial expandida para uso em um produto ou serviço está disponível como parte da solução ClearML Scale ou Enterprise.
ClearML oferece licença empresarial e comercial adicionando muitos recursos adicionais sobre GPUs fracionárias, incluindo orquestração, filas de prioridade, gerenciamento de cotas, painel de cluster de computação, gerenciamento de conjunto de dados e gerenciamento de experimentos, bem como segurança e suporte de nível empresarial. Saiba mais sobre o ClearML Orchestration ou fale conosco diretamente nas vendas do ClearML.
Conte a todos sobre isso! #ClearMLFractionalGPU
Junte-se ao nosso canal Slack
Informe-nos quando algo não estiver funcionando e ajude-nos a depurá-lo na página de problemas
Este produto é oferecido a você pela equipe ClearML com ❤️


