amazon bedrock rag
1.0.0
A Geração Aumentada de Recuperação (RAG) é o processo de otimização da saída de um modelo de linguagem grande, de modo que faz referência a uma base de conhecimento oficial fora de suas fontes de dados de treinamento antes de gerar uma resposta. Grandes Modelos de Linguagem (LLMs) são treinados em grandes volumes de dados e usam bilhões de parâmetros para gerar resultados originais para tarefas como responder perguntas, traduzir idiomas e completar frases. O RAG estende os já poderosos recursos dos LLMs a domínios específicos ou à base de conhecimento interna de uma organização, tudo sem a necessidade de retreinar o modelo. É uma abordagem económica para melhorar os resultados do LLM, pelo que permanece relevante, preciso e útil em vários contextos. Saiba mais sobre o RAG aqui.
O Amazon Bedrock é um serviço totalmente gerenciado que oferece uma variedade de modelos básicos (FMs) de alto desempenho de empresas líderes de IA, como AI21 Labs, Anthropic, Cohere, Meta, Stability AI e Amazon por meio de uma única API, juntamente com um amplo conjunto de recursos necessários para criar aplicativos generativos de IA com segurança, privacidade e IA responsável. Usando o Amazon Bedrock, você pode experimentar e avaliar facilmente os principais FMs para seu caso de uso, personalizá-los de forma privada com seus dados usando técnicas como ajuste fino e RAG e criar agentes que executam tarefas usando seus sistemas corporativos e fontes de dados. Como o Amazon Bedrock não tem servidor, você não precisa gerenciar nenhuma infraestrutura e pode integrar e implantar com segurança recursos de IA generativos em seus aplicativos usando os serviços da AWS com os quais você já está familiarizado.
As bases de conhecimento do Amazon Bedrock são um recurso totalmente gerenciado que ajuda a implementar todo o fluxo de trabalho do RAG, desde a ingestão até a recuperação e o aumento imediato, sem a necessidade de criar integrações personalizadas para fontes de dados e gerenciar fluxos de dados. O gerenciamento de contexto de sessão é integrado, para que seu aplicativo possa suportar prontamente conversas em vários turnos.
Como parte da criação de uma base de conhecimento, você configura uma fonte de dados e um armazenamento de vetores de sua escolha. Um conector de fonte de dados permite conectar seus dados proprietários a uma base de conhecimento. Depois de configurar um conector de fonte de dados, você poderá sincronizar ou manter seus dados atualizados com sua base de conhecimento e disponibilizá-los para consulta. O Amazon Bedrock primeiro divide seus documentos ou conteúdo em partes gerenciáveis para uma recuperação de dados eficiente. Os pedaços são então convertidos em embeddings e gravados em um índice vetorial (representação vetorial dos dados), mantendo um mapeamento para o documento original. As incorporações vetoriais permitem que os textos sejam comparados matematicamente quanto à similaridade.
Este projeto é implementado com duas fontes de dados; uma fonte de dados para documentos armazenados no Amazon S3 e outra fonte de dados para conteúdo publicado em um site. Uma coleção de pesquisa vetorial é criada no Amazon OpenSearch Serverless para armazenamento de vetores.
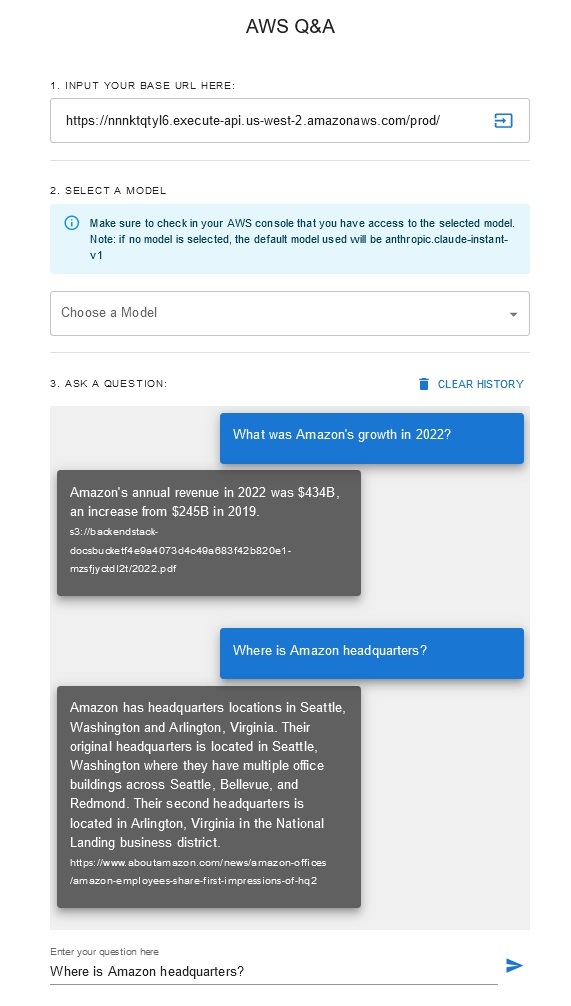
Chatbot de perguntas e respostas 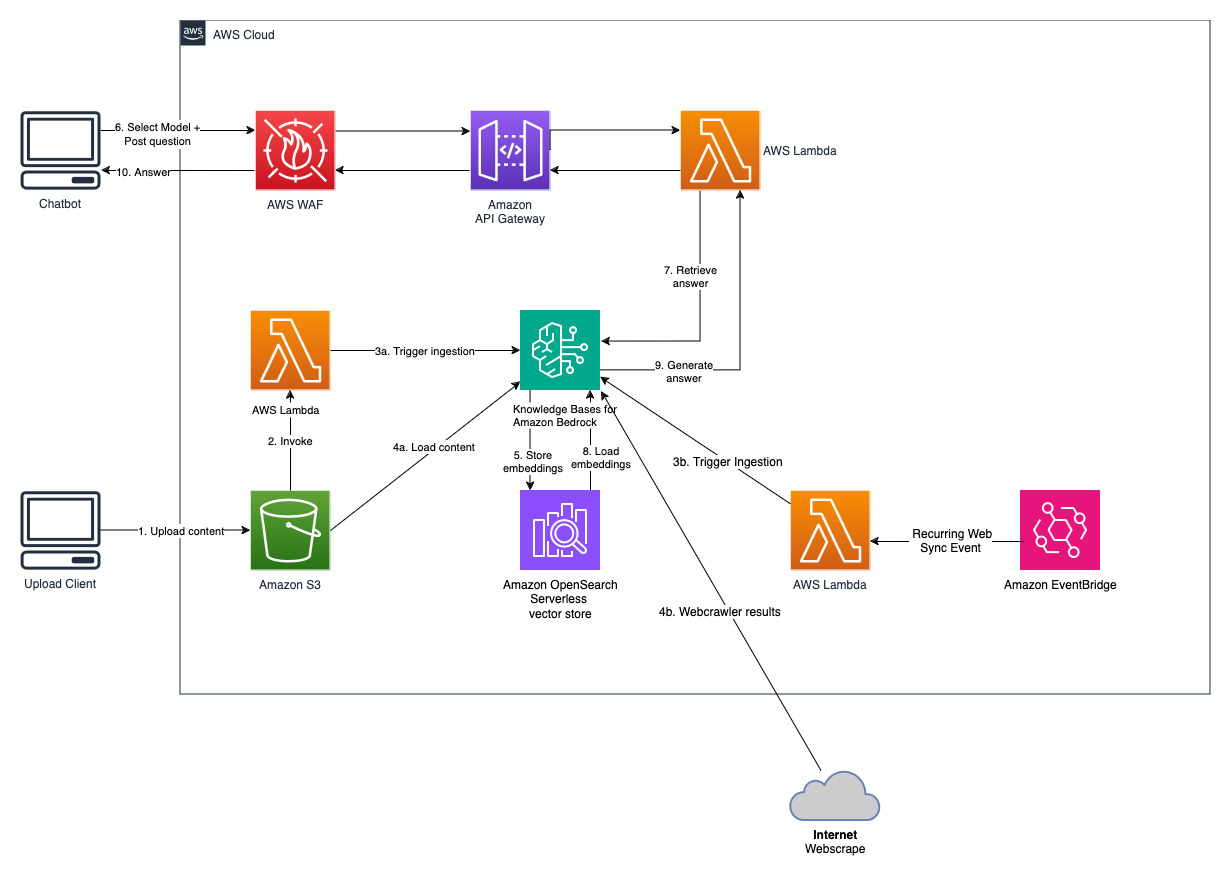
Adicionar novos sites para fonte de dados da web 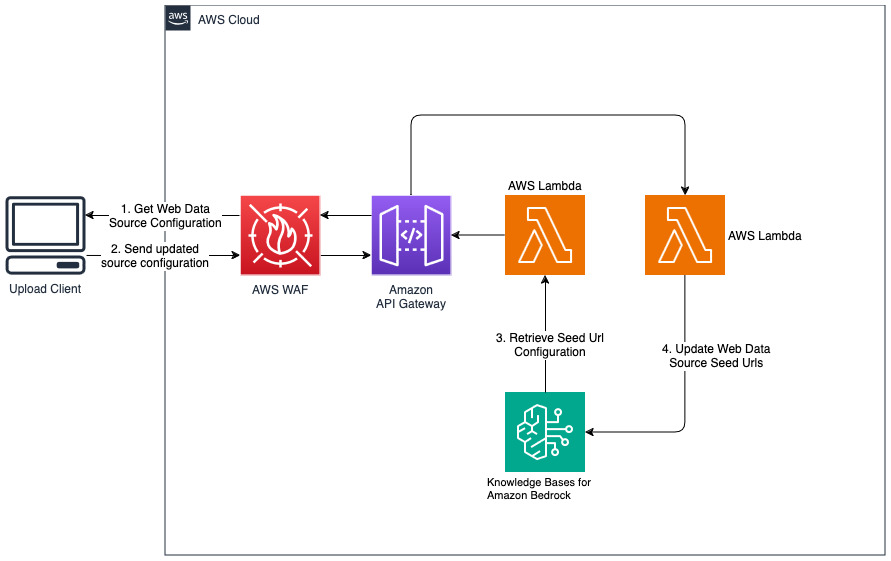
cdk deploy --context allowedip="xxx.xxx.xxx.xxx/32"
Forneça um endereço IP do cliente que tenha permissão para acessar o API Gateway no formato CIDR como parte da variável de contexto 'allowedip'.
Quando a implantação for concluída,
Esta solução permite que os usuários selecionem qual modelo fundamental desejam usar durante a fase de recuperação e geração. O modelo padrão é Antrópico Claude Instant . Para o modelo de incorporação da base de conhecimento, esta solução usa Amazon Titan Embeddings G1 – modelo de texto . Certifique-se de ter acesso a esses modelos de base.
Obtenha um relatório anual recente da Amazon disponível publicamente e copie-o para o nome do bucket S3 mencionado anteriormente. Para um teste rápido, você pode copiar o relatório anual de 2022 da Amazon usando o console AWS S3. O conteúdo do bucket S3 será sincronizado automaticamente com a base de conhecimento porque a implantação da solução monitora novos conteúdos no bucket S3 e aciona um fluxo de trabalho de ingestão.
A solução implementada inicializa a fonte de dados da web chamada "WebCrawlerDataSource" com o URL https://www.aboutamazon.com/news/amazon-offices . Você precisa sincronizar manualmente esta fonte de dados do Web Crawler com a base de conhecimento do console da AWS para pesquisar o conteúdo do site porque a ingestão do site está programada para acontecer no futuro. Selecione esta fonte de dados no console Knowledge based on Amazon Bedrock e inicie uma operação de "Sincronização". Consulte Sincronizar sua fonte de dados com sua base de conhecimento do Amazon Bedrock para obter detalhes. Observe que o conteúdo do site estará disponível para o chatbot de perguntas e respostas somente após a conclusão da sincronização. Use esta orientação ao configurar sites como fonte de dados.
Use "cdk destroy" para excluir a pilha de recursos de nuvem criados nesta implantação de solução.


