EasyNLU
1.0.0
EasyNLU é uma biblioteca Natural Language Understanding (NLU) escrita em Java para aplicativos móveis. Por ser baseado na gramática, é uma boa opção para domínios restritos, mas que exigem controle rígido.
O projeto tem um exemplo de aplicativo Android que pode agendar lembretes a partir de entrada em linguagem natural:
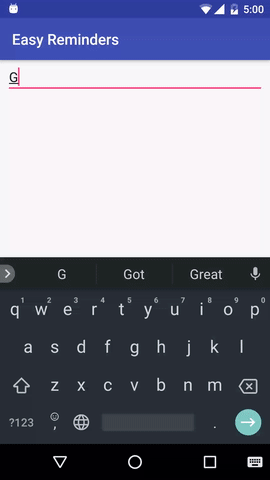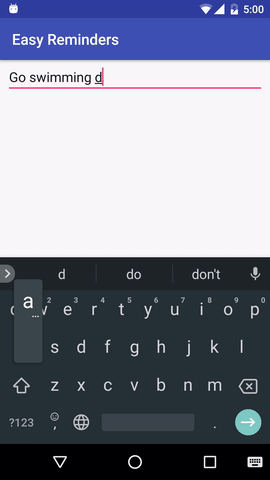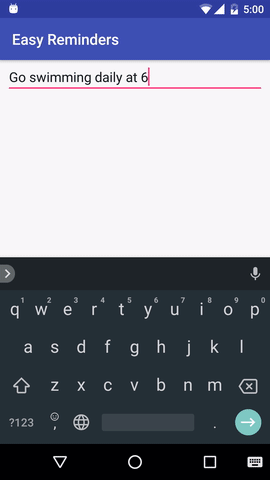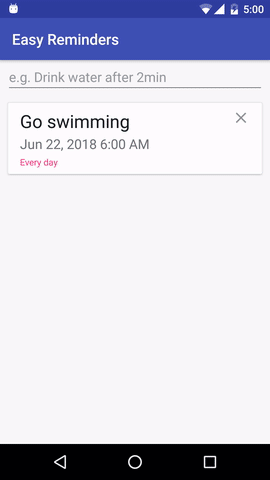
EasyNLU é licenciado sob Apache 2.0.
Em sua essência, EasyNLU é um analisador semântico baseado em CCG. Uma boa introdução à análise semântica pode ser encontrada aqui. Um analisador semântico pode analisar uma entrada como:
Vá ao dentista amanhã às 17h
em uma forma estruturada:
{task: "Go to the dentist", startTime:{offset:{day:1}, hour:5, shift:"pm"}}
EasyNLU fornece o formulário estruturado como um mapa Java recursivo. Este formulário estruturado pode então ser resolvido em um objeto específico de tarefa que é 'executado'. Por exemplo, no projeto de exemplo, o formulário estruturado é resolvido em um objeto Reminder que possui campos como task , startTime e repeat e é usado para configurar um alarme com o serviço AlarmManager.
Em geral, a seguir estão as etapas de alto nível para configurar o recurso NLU:
Antes de escrever qualquer regra devemos definir o escopo da tarefa e os parâmetros do formulário estruturado. Como exemplo de brinquedo, digamos que nossa tarefa seja ligar e desligar recursos do telefone como Bluetooh, Wifi e GPS. Então os campos são:
Um exemplo de formulário estruturado seria:
{feature: "bluetooth", action: "enable" }
Também ajuda ter alguns exemplos de entrada para entender as variações:
Continuando com o exemplo do brinquedo, podemos dizer que no nível superior temos uma ação de cenário que deve ter uma característica e uma ação. Em seguida, usamos regras para capturar essas informações:
Rule r1 = new Rule ( "$Setting" , "$Feature $Action" );
Rule r2 = new Rule ( "$Setting" , "$Action $Feature" ); Uma regra contém, no mínimo, um LHS e um RHS. Por convenção, acrescentamos um '$' a uma palavra para indicar uma categoria. Uma categoria representa uma coleção de palavras ou outras categorias. Nas regras acima, $Feature representa palavras como bluetooth, bt, wifi etc, que capturamos usando regras 'lexicais':
List < Rule > lexicals = Arrays . asList (
new Rule ( "$Feature" , "bluetooth" ),
new Rule ( "$Feature" , "bt" ),
new Rule ( "$Feature" , "wifi" ),
new Rule ( "$Feature" , "gps" ),
new Rule ( "$Feature" , "location" ),
); Para normalizar variações nos nomes dos recursos, estruturamos $Features em subrecursos:
List < Rule > featureRules = Arrays . asList (
new Rule ( "$Feature" , "$Bluetooth" ),
new Rule ( "$Feature" , "$Wifi" ),
new Rule ( "$Feature" , "$Gps" ),
new Rule ( "$Bluetooth" , "bt" ),
new Rule ( "$Bluetooth" , "bluetooth" ),
new Rule ( "$Wifi" , "wifi" ),
new Rule ( "$Gps" , "gps" ),
new Rule ( "$Gps" , "location" )
); Da mesma forma para $Action :
List < Rule > actionRules = Arrays . asList (
new Rule ( "$Action" , "$EnableDisable" ),
new Rule ( "$EnableDisable" , "?$Switch $OnOff" ),
new Rule ( "$EnableDisable" , "$Enable" ),
new Rule ( "$EnableDisable" , "$Disable" ),
new Rule ( "$OnOff" , "on" ),
new Rule ( "$OnOff" , "off" ),
new Rule ( "$Switch" , "switch" ),
new Rule ( "$Switch" , "turn" ),
new Rule ( "$Enable" , "enable" ),
new Rule ( "$Disable" , "disable" ),
new Rule ( "$Disable" , "kill" )
); Observe o '?' na terceira regra; isso significa que a categoria $Switch é opcional. Para determinar se uma análise foi bem-sucedida, o analisador procura uma categoria especial chamada categoria raiz. Por convenção, é denotado como $ROOT . Precisamos adicionar uma regra para chegar a esta categoria:
Rule root = new Rule ( "$ROOT" , "$Setting" );Com este conjunto de regras, nosso analisador deverá ser capaz de analisar os exemplos acima, convertendo-os nas chamadas árvores sintáticas.
A análise não é boa se não conseguirmos extrair o significado da frase. Este significado é capturado pela forma estruturada (forma lógica no jargão da PNL). No EasyNLU passamos um terceiro parâmetro na definição da regra para definir como a semântica será extraída. Usamos a sintaxe JSON com marcadores especiais para fazer isso:
new Rule ( "$Action" , "$EnableDisable" , "{action:@first}" ), @first diz ao analisador para escolher o valor da primeira categoria da regra RHS. Neste caso será 'habilitar' ou 'desabilitar' com base na frase. Outros marcadores incluem:
@identity : função de identidade@last : Escolha o valor da última categoria RHS@N : Escolha o valor da Nª categoria RHS, por exemplo, @3 escolherá a 3ª@merge : mescla valores de todas as categorias. Apenas valores nomeados (por exemplo {action: enable} ) serão mesclados@append : acrescenta valores de todas as categorias em uma lista. A lista resultante deve ser nomeada. Somente valores nomeados são permitidosDepois de adicionar marcadores semânticos, nossas regras se tornam:
List < Rule > rules = Arrays . asList (
new Rule ( "$ROOT" , "$Setting" , "@identity" ),
new Rule ( "$Setting" , "$Feature $Action" , "@merge" ),
new Rule ( "$Setting" , "$Action $Feature" , "@merge" ),
new Rule ( "$Feature" , "$Bluetooth" , "{feature: bluetooth}" ),
new Rule ( "$Feature" , "$Wifi" , "{feature: wifi}" ),
new Rule ( "$Feature" , "$Gps" , "{feature: gps}" ),
new Rule ( "$Bluetooth" , "bt" ),
new Rule ( "$Bluetooth" , "bluetooth" ),
new Rule ( "$Wifi" , "wifi" ),
new Rule ( "$Gps" , "gps" ),
new Rule ( "$Gps" , "location" ),
new Rule ( "$Action" , "$EnableDisable" , "{action: @first}" ),
new Rule ( "$EnableDisable" , "?$Switch $OnOff" , "@last" ),
new Rule ( "$EnableDisable" , "$Enable" , "enable" ),
new Rule ( "$EnableDisable" , "$Disable" , "disable" ),
new Rule ( "$OnOff" , "on" , "enable" ),
new Rule ( "$OnOff" , "off" , "disable" ),
new Rule ( "$Switch" , "switch" ),
new Rule ( "$Switch" , "turn" ),
new Rule ( "$Enable" , "enable" ),
new Rule ( "$Disable" , "disable" ),
new Rule ( "$Disable" , "kill" )
);Se o parâmetro semântico não for fornecido, o analisador criará um valor padrão igual ao RHS.
Para executar o analisador, clone este repositório e importe o módulo do analisador para seu projeto Android Studio/IntelliJ. O analisador EasyNLU usa um objeto Grammar que contém as regras, um objeto Tokenizer para converter a frase de entrada em palavras e uma lista opcional de objetos Annotator para anotar entidades como números, datas, lugares, etc. Execute o seguinte código após definir as regras:
Grammar grammar = new Grammar ( rules , "$ROOT" );
Parser parser = new Parser ( grammar , new BasicTokenizer (), Collections . emptyList ());
System . out . println ( parser . parse ( "kill bt" ));
System . out . println ( parser . parse ( "wifi on" ));
System . out . println ( parser . parse ( "enable location" ));
System . out . println ( parser . parse ( "turn off GPS" ));Você deve obter a seguinte saída:
23 rules
[{feature=bluetooth, action=disable}]
[{feature=wifi, action=enable}]
[{feature=gps, action=enable}]
[{feature=gps, action=disable}]
Experimente outras variações. Se uma análise falhar para uma variante de amostra, você não obterá saída. Você pode então adicionar ou modificar as regras e repetir o processo de engenharia gramatical.
EasyNLU agora oferece suporte a listas no formato estruturado. Para o domínio acima, ele pode lidar com entradas como
Desativar localização bt gps
Adicione estas 3 regras extras à gramática acima:
new Rule("$Setting", "$Action $FeatureGroup", "@merge"),
new Rule("$FeatureGroup", "$Feature $Feature", "{featureGroup: @append}"),
new Rule("$FeatureGroup", "$FeatureGroup $Feature", "{featureGroup: @append}"),
Execute uma nova consulta como:
System.out.println(parser.parse("disable location bt gps"));
Você deve obter esta saída:
[{action=disable, featureGroup=[{feature=gps}, {feature=bluetooth}, {feature=gps}]}]
Observe que essas regras são acionadas somente se houver mais de um recurso na consulta
Os anotadores facilitam a identificação de tipos específicos de tokens que, de outra forma, seriam complicados ou totalmente impossíveis de serem manipulados por meio de regras. Por exemplo, pegue a classe NumberAnnotator . Ele detectará e anotará todos os números como $NUMBER . Você pode então fazer referência direta à categoria em suas regras, por exemplo:
Rule r = new Rule("$Conversion", "$Convert $NUMBER $Unit $To $Unit", "{convertFrom: {unit: @2, quantity: @1}, convertTo: {unit: @last}}"
EasyNLU atualmente vem com alguns anotadores:
NumberAnnotator : anota númerosDateTimeAnnotator : anota alguns formatos de data. Também fornece suas próprias regras que você adiciona usando DateTimeAnnotator.rules()TokenAnnotator : anota cada token da entrada como $TOKENPhraseAnnotator : anota cada frase contígua de entrada como $PHRASE Para usar seu próprio anotador customizado, implemente a interface Annotator e passe-a para o analisador. Consulte os anotadores integrados para ter uma ideia de como implementá-los.
EasyNLU suporta regras de carregamento de arquivos de texto. Cada regra deve estar em uma linha separada. O LHS, RHS e a semântica devem ser separados por tabulações:
$EnableDisable ?$Switch $OnOff @last
Tenha cuidado para não usar IDEs que convertem automaticamente tabulações em espaços
À medida que mais regras são adicionadas ao analisador, você descobrirá que o analisador encontra múltiplas análises para determinadas entradas. Isto se deve à ambiguidade geral das línguas humanas. Para determinar a precisão do analisador para sua tarefa, você precisa executá-lo por meio de exemplos rotulados.
Como as regras anteriores, o EasyNLU usa exemplos definidos em texto simples. Cada linha deve ser um exemplo separado e deve conter o texto bruto e o formulário estruturado separados por uma tabulação:
take my medicine at 4pm {task:"take my medicine", startTime:{hour:4, shift:"pm"}}
É importante que você cubra um número aceitável de variações na entrada. Você obterá mais variedade se contratar pessoas diferentes para realizar essa tarefa. O número de exemplos depende da complexidade do domínio. O conjunto de dados de amostra fornecido neste projeto tem mais de 100 exemplos.
Depois de ter os dados, você pode transformá-los em um conjunto de dados. A parte de aprendizagem é feita pelo módulo trainer ; importe-o para o seu projeto. Carregue um conjunto de dados como este:
Dataset dataset = Dataset . fromText ( 'filename.txt' )Avaliamos o analisador para determinar dois tipos de precisões
Para executar a avaliação usamos a classe Model :
Model model = new Model(parser);
model.evaluate(dataset, 2);
O segundo parâmetro para a função de avaliação é o nível detalhado. Quanto maior o número, mais detalhada será a saída. A função evaluate() executa o analisador em cada exemplo e mostra análises incorretas, finalmente exibindo a precisão. Se você obtiver ambas as precisões na casa dos 90, o treinamento será desnecessário, você provavelmente conseguirá lidar com essas poucas análises ruins com o pós-processamento. Se a precisão do oráculo for alta, mas a precisão da previsão for baixa, o treinamento do sistema ajudará. Se a precisão do oráculo for baixa, você precisará fazer mais engenharia gramatical.
Para obter a análise correta, nós os pontuamos e escolhemos aquele com a pontuação mais alta. EasyNLU usa um modelo linear simples para calcular as pontuações. O treinamento é realizado usando Stochastic Gradient Descent (SGD) com função de perda de dobradiça. Os recursos de entrada são baseados em contagens de regras e campos no formulário estruturado. Os pesos treinados são então salvos em um arquivo de texto.
Você pode ajustar alguns dos parâmetros do modelo/treinamento para obter melhor precisão. Para os modelos de lembretes foram utilizados os seguintes parâmetros:
HParams hparams = HParams . hparams ()
. withLearnRate ( 0.08f )
. withL2Penalty ( 0.01f )
. set ( SVMOptimizer . CORRECT_PROB , 0.4f );Execute o código de treinamento da seguinte maneira:
Experiment experiment = new Experiment ( model , dataset , hparams , "yourdomain.weights" );
experiment . train ( 100 , false );Isso treinará o modelo por 100 épocas com uma divisão de teste de treinamento de 0,8. Ele exibirá as precisões no conjunto de teste e salvará os pesos do modelo no caminho do arquivo fornecido. Para treinar em todo o conjunto de dados, defina o parâmetro de implantação como verdadeiro. Você pode executar um modo interativo recebendo informações do console:
experiement.interactive();
NOTA: não é garantido que esse treinamento produza alta precisão, mesmo com um grande número de exemplos. Para determinados cenários, os recursos fornecidos podem não ser suficientemente discriminativos. Se você ficar preso nesse caso, registre um problema e poderemos encontrar recursos adicionais.
Os pesos do modelo são um arquivo de texto simples. Para um projeto Android você pode colocá-lo na pasta assets e carregá-lo usando o AssetManager. Consulte ReminderNlu.java para obter mais detalhes. Você pode até armazenar seus pesos e regras na nuvem e atualizar seu modelo remotamente (alguém no Firebase?).
Depois que o analisador estiver fazendo um bom trabalho ao converter a entrada da linguagem natural em um formato estruturado, você provavelmente desejará esses dados em um objeto específico da tarefa. Para alguns domínios, como o exemplo do brinquedo acima, pode ser bastante simples. Para outros, você pode ter que resolver referências a coisas como datas, lugares, contatos, etc. No exemplo de lembrete, as datas são frequentemente relativas (por exemplo, 'amanhã', 'depois de 2 horas', etc.), que precisam ser convertidas em valores absolutos. Consulte ArgumentResolver.java para ver como a resolução é feita.
DICA: Mantenha a lógica de resolução no mínimo ao definir regras e faça a maior parte dela no pós-processamento. Isso manterá as regras mais simples.


