mind x
1.0.0

Este projeto demonstra a viabilidade de LLMs (ou LMMs) personalizados como assistentes pessoais, acompanhando o rápido crescimento destes modelos.
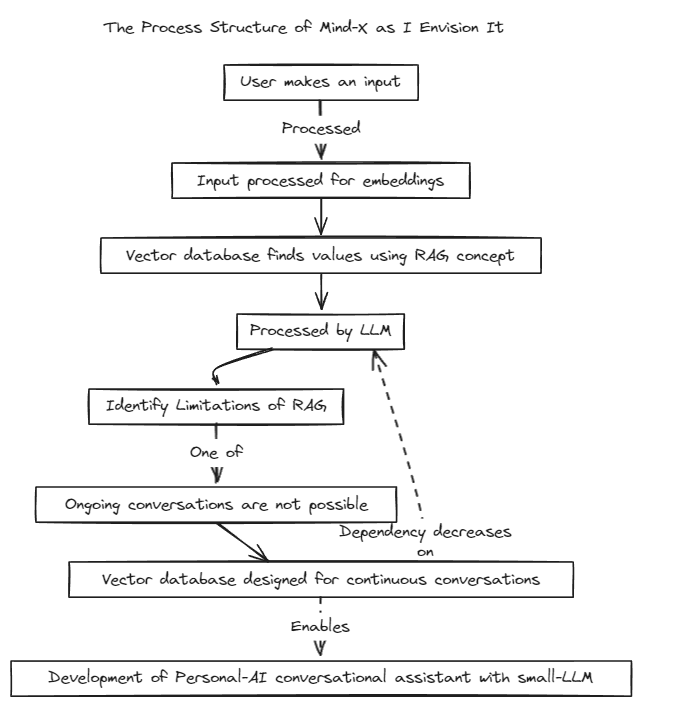
Introduzimos um método de geração aumentada de recuperação (RAG) para superar as limitações do ajuste de prompt tradicional, que tem limites de contexto, e do ajuste fino, que sofre de problemas com atualizações de dados em tempo real e alucinações.
Tradicionalmente, o RAG tem sido usado para pesquisar bancos de dados como o Chroma via LangChain como armazenamento, mas esse método opera em contextos fixos, o que é limitante.
Portanto, planejamos construir nosso próprio sistema RAG. Este processo pode envolver a abordagem de problemas de inferência e regressão que o LangChain pode oferecer.
Estamos comprometidos com o rápido desenvolvimento e em breve permitiremos a compatibilidade multilíngue. Atualmente, o sistema oferece suporte total ao inglês, com planos de oferecer suporte a coreano, japonês e outros idiomas em breve. Além disso, sistemas de regressão e inferência também serão incorporados em breve.
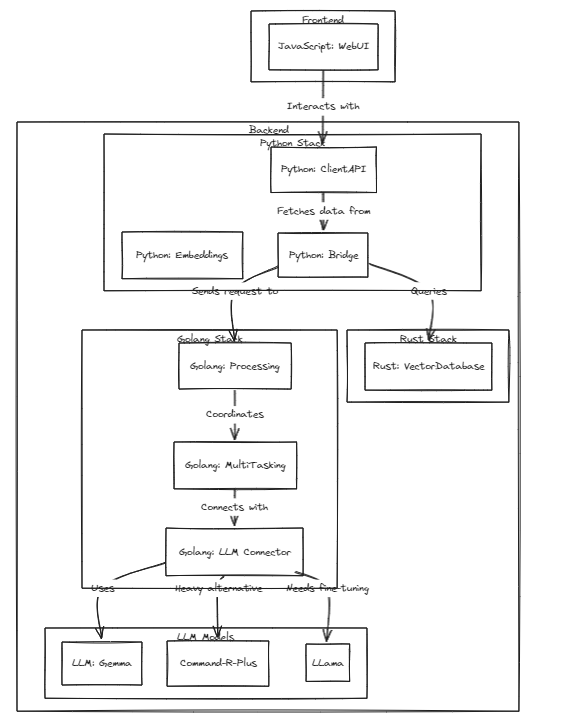
Para executar testes, execute o seguinte comando
# start embeddings server
cd embd & pip install -r requirements.txt
python app.py
# start mindx-v server (vector-database)
# not using cgo, only assembly
cd mindx-v & go run cmd/mxvd/main.go
# start processor server
cd processor & go run cmd/main.go
# start demo client
cd sample_client & npm start
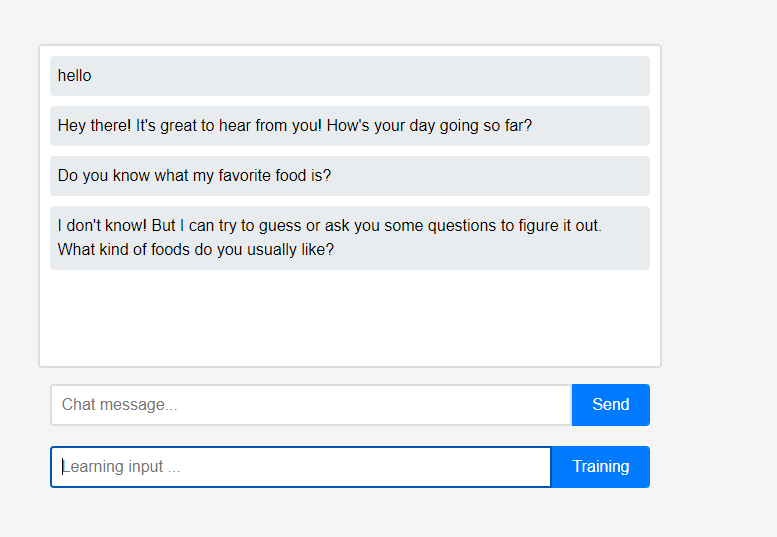 Inicialmente, o assistente nada sabe sobre o usuário.
Inicialmente, o assistente nada sabe sobre o usuário.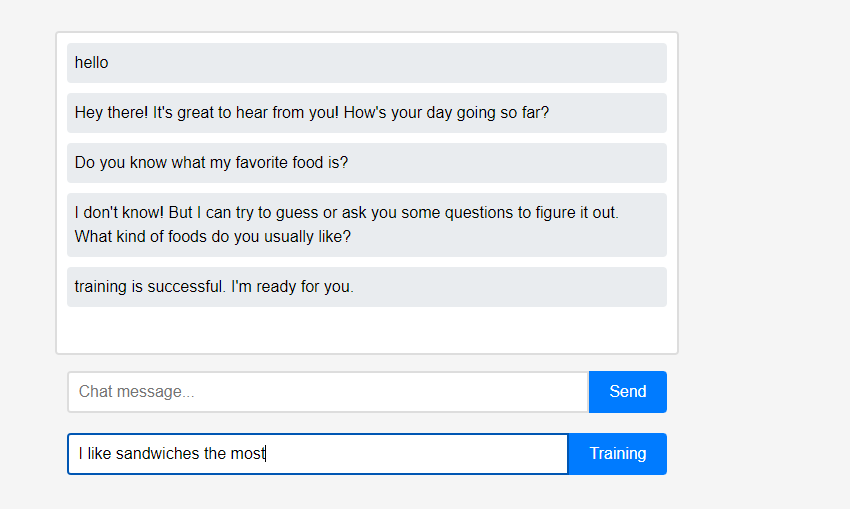 No entanto, os usuários podem ensinar o assistente sobre si mesmos em tempo real.
No entanto, os usuários podem ensinar o assistente sobre si mesmos em tempo real.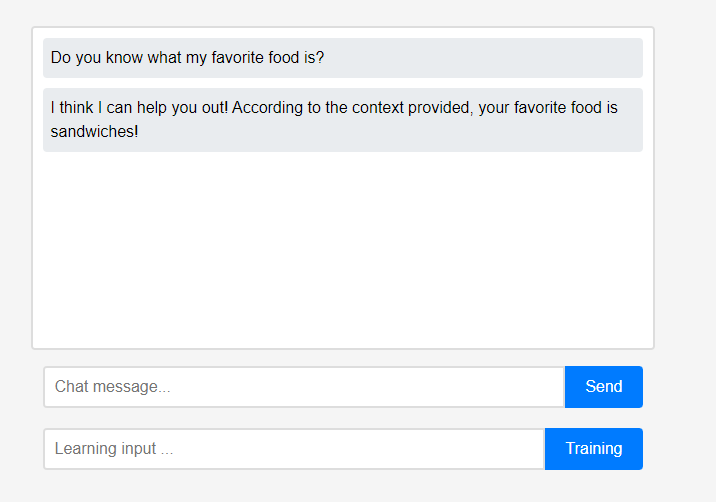 (Devido às características do LLM, pode ser mal interpretado que ele foi lembrado como uma cadeia de conversação em vez de aprendizagem, por isso foi feito após a atualização.) Os dados aprendidos foram refletidos imediatamente, e isso pode ser visto como a primeira personalização do assistente.
(Devido às características do LLM, pode ser mal interpretado que ele foi lembrado como uma cadeia de conversação em vez de aprendizagem, por isso foi feito após a atualização.) Os dados aprendidos foram refletidos imediatamente, e isso pode ser visto como a primeira personalização do assistente.
Todos esses recursos do projeto podem ser suportados localmente, sem a necessidade de integração externa em nuvem ou conexão com a Internet.



query = protobuf . search_pb2 . SearchRequest (
dataset_id = dataset_id ,
query = get_image_embedding ( "./test_data/bad.png" ),
k = 1
)
results = search . Search ( query )
try :
for result in results :
print ( "Search result:" , result . id , result . metadata , result . score )
except grpc . RpcError as e :
print ( "Search failed:" , e )
query = protobuf . search_pb2 . SearchRequest (
dataset_id = dataset_id ,
query = get_image_embedding ( "./test_data/good.png" ),
k = 1
)
results = search . Search ( query )
try :
for result in results :
print ( "Search result:" , result . id , result . metadata , result . score )
except grpc . RpcError as e :
print ( "Search failed:" , e )


