dstoolkit km solution accelerator
V1.6

Acelerador de soluções de mineração de conhecimento
Este repositório contém todo o código para implantar uma solução de Mineração de Conhecimento de ponta a ponta baseada no Azure Cognitive Search.
Ele é construído com base nos serviços padrão do Azure, como Functions, Web App Services, Congitive Services e Cognitive Search. Ele fornece um pipeline de implantação que permite a configuração rápida e fácil de pipelines de CI/CD para seus projetos.
Para documentação detalhada, consulte a seção de documentos do repositório que contém o wiki da solução.
Para configurar sua solução com êxito, você precisará ter acesso e/ou provisionar o seguinte:
Uma função de Proprietário ou Colaborador é assumida na assinatura do Azure ou no Grupo de Recursos direcionado.
Consulte o README para implantar este acelerador de solução.
As instruções fornecidas em todos os guias pressupõem que você tenha um conhecimento prático fundamental do portal do Azure, do Azure Functions, do Azure Cognitive Search, do Functions, do Armazenamento e dos Serviços Cognitivos do Azure.
Para treinamento e suporte adicionais, consulte:
A mineração de conhecimento (GC) é uma disciplina emergente em inteligência artificial (IA) que utiliza uma combinação de serviços inteligentes para aprender rapidamente a partir de grandes quantidades de informações. Ele permite que as organizações compreendam profundamente e explorem informações com facilidade, descubram insights ocultos e encontrem relacionamentos e padrões em grande escala.
Mineração de conhecimento no Azure
Este acelerador de solução KM tem como objetivo fornecer uma solução viável de mineração de conhecimento de ponta a ponta, composta por:
Com este acelerador baseado em nuvem, você obterá uma solução ponta a ponta com ferramentas para implantar, estender, operar e monitorar.
Nesse sentido, a solução fornece
Este acelerador de soluções de Mineração de Conhecimento é inspirado em outro acelerador, o Acelerador de Soluções de Mineração de Conhecimento.
Com base em nossa experiência de campo, desenvolvemos recursos/habilidades para enfrentar desafios comuns de dados não estruturados, com foco na usabilidade e na experiência de exploração de dados.
Abaixo está uma lista não exaustiva dos principais destaques:
Indexação de imagens incorporadas
Normalização de imagem :
Metadados
Conversão HTML
Extração de tabelas : informações tabulares são comuns em corpus de dados não estruturados. A solução extrairá, indexará e projetará tabelas para um armazenamento de conhecimento dedicado (opcional).
Tradução ": existem dois recursos de tradução nesta solução
Análise de texto : extraia entidades (nomeadas, vinculadas) de qualquer documento e texto de imagem com OCR.
Exportar para Excel : pergunta popular ao explorar dados não estruturados.
UI configurável : construir uma UI é demorado, queríamos trazer grande capacidade de configuração da UI para que você pudesse dar vida a novas soluções de GC em tempo hábil.
Este espírito acelerador de solução é de um cenário de GC de pesquisa de conteúdo.
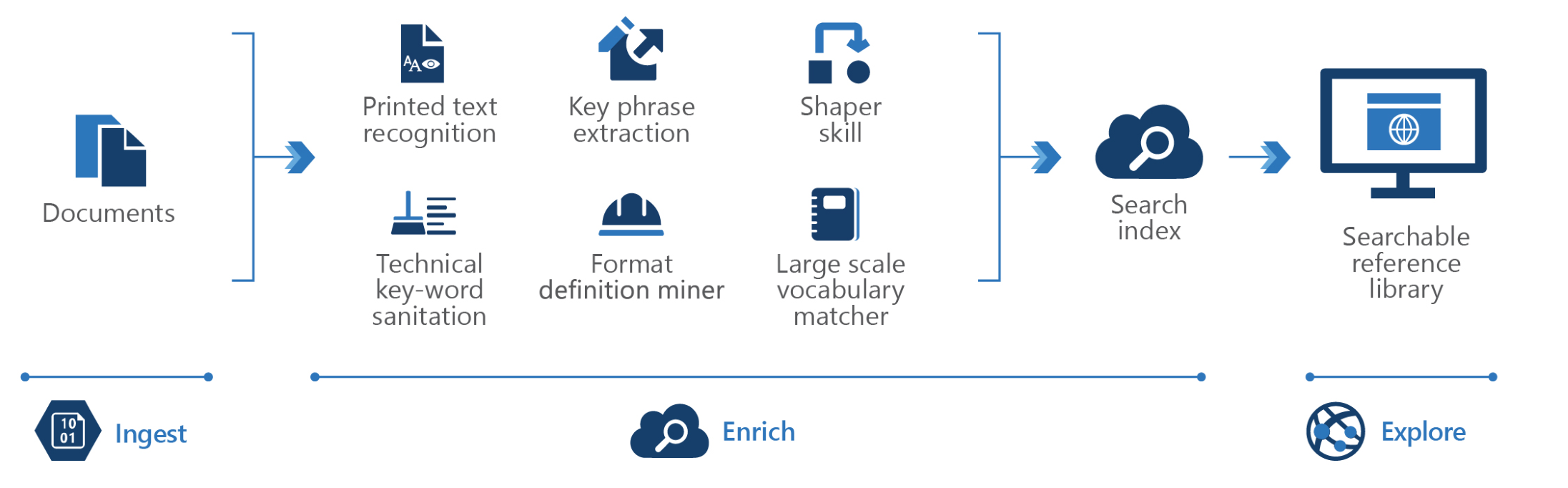
No entanto, como sua arquitetura é aberta, você pode usá-la como base para cenários de GC mais especializados.
Este acelerador de solução não é direcionado a nenhum domínio, embora sua extensibilidade forneça as ferramentas para torná-lo específico do domínio.
Alguns casos de uso inspiradores
Você pode pensar na produtização como um acelerador para sua organização.
Este acelerador de soluções é direcionado a quem precisa de
O objetivo do acelerador de solução também é facilitar a integração de módulos de ciência de dados em sua solução de mineração de conhecimento.
A equipe do Data Science Toolkit criou aceleradores para sua carga de trabalho de ciência de dados.
| Solução | Descrição |
|---|---|
| Versagilidade | Verseagility é um kit de ferramentas baseado em Python para acelerar sua tarefa personalizada de processamento de linguagem natural (PNL), permitindo que você traga seus próprios dados, use suas estruturas preferidas e coloque modelos em produção. É um componente central do Microsoft Data Science Toolkit. |
| Base MLOps | Este repositório contém a estrutura básica do repositório para projetos de machine learning baseados em tecnologias Azure (Azure ML e Azure DevOps). Os nomes das pastas e arquivos são escolhidos com base na experiência pessoal. Você pode encontrar os princípios e ideias por trás da estrutura, que recomendamos seguir ao personalizar seu próprio projeto e processo de MLOps. Além disso, esperamos que os usuários estejam familiarizados com os conceitos de aprendizado de máquina do Azure e como usar a tecnologia. |
| MLOps para DataBricks | Este repositório contém a estrutura de desenvolvimento do Databricks para entregar quaisquer projetos de engenharia de dados e projetos de aprendizado de máquina baseados nas tecnologias Azure. |
| Acelerador de soluções de classificação | Este repositório contém a estrutura básica do repositório para fornecer soluções de classificação para projetos de machine learning (ML) baseados em tecnologias Azure (Azure ML e Azure DevOps). |
| Acelerador de soluções de detecção de objetos | Este repositório contém todo o código para treinar modelos de detecção de objetos do TensorFlow no Azure Machine Learning (AML) com configurações para treinamento em computação do Azure, monitoramento de experimentos e implantação de endpoint como um serviço web. Ele é construído no MLOps Accelerator e fornece treinamento completo e pipelines de implantação, permitindo configuração rápida e fácil de pipelines de CI/CD para seus projetos. |
Você pode consultar a documentação do acelerador de solução da seguinte maneira:
| Tópico | Descrição | Link da documentação |
|---|---|---|
| Pré-requisitos | O que você precisa para implantar e operar a solução | LEIA-ME |
| Arquitetura | Como a solução é arquitetada | LEIA-ME |
| Implantação | Como implantar este acelerador de solução | LEIA-ME |
| Configuração | Tudo o que você precisa saber sobre a configuração do acelerador de soluções | LEIA-ME |
| Ciência de Dados | Integração com Ciência de Dados | LEIA-ME |
| Implantação | Como começar implantando a solução | LEIA-ME |
| Monitoramento | Como monitorar a solução | LEIA-ME |
| Procurar | Como a pesquisa é configurada e gerenciada | LEIA-ME |
| Pesquisar e explorar (IU) | Interface do usuário para pesquisar e explorar | LEIA-ME |
A estrutura do repositório deste acelerador é a seguinte
Clone ou baixe este repositório e navegue até a pasta Deployment, seguindo as etapas descritas no guia de implantação.
Ao concluir todas as etapas, você terá uma solução de mineração de conhecimento de ponta a ponta que combina a ingestão de fontes de dados com habilidades de enriquecimento de dados e um aplicativo Web desenvolvido pelo Azure Cognitive Search.
Esta solução é inspirada no trabalho original do
Os principais contribuidores deste acelerador de soluções são
A equipe de patrocínio do kit de ferramentas de ciência de dados
Para a ótima conversa sobre Mineração de Conhecimento e Dados Não Estruturados
Este projeto aceita contribuições e sugestões. A maioria das contribuições exige que você concorde com um Contrato de Licença de Colaborador (CLA), declarando que você tem o direito de nos conceder, e realmente nos concede, os direitos de uso de sua contribuição. Para obter detalhes, visite https://cla.opensource.microsoft.com.
Quando você envia uma solicitação pull, um bot CLA determinará automaticamente se você precisa fornecer um CLA e decorará o PR adequadamente (por exemplo, verificação de status, comentário). Basta seguir as instruções fornecidas pelo bot. Você só precisará fazer isso uma vez em todos os repositórios usando nosso CLA.
Este projeto adotou o Código de Conduta de Código Aberto da Microsoft. Para obter mais informações, consulte as Perguntas frequentes sobre o Código de Conduta ou entre em contato com [email protected] com perguntas ou comentários adicionais.
Este projeto pode conter marcas registradas ou logotipos de projetos, produtos ou serviços. O uso autorizado de marcas registradas ou logotipos da Microsoft está sujeito e deve seguir as Diretrizes de Marcas Registradas e Marcas da Microsoft. O uso de marcas registradas ou logotipos da Microsoft em versões modificadas deste projeto não deve causar confusão nem implicar patrocínio da Microsoft. Qualquer uso de marcas registradas ou logotipos de terceiros está sujeito às políticas desses terceiros.


