donkeybot
1.0.0
Este repositório não é mantido e foi arquivado.
Donkeybot é um sistema completo de resposta a perguntas. Ele utiliza várias fontes de dados, uma tabela de perguntas frequentes e modelos de linguagem de aprendizagem por transferência, como BERT, para responder às perguntas de suporte do Rucio.
O objetivo do projeto no âmbito do GSoC 2020 é utilizar o Processamento de Linguagem Natural (PNL) para desenvolver um protótipo de bot inteligente capaz de fornecer respostas satisfatórias aos usuários do Rucio e lidar com solicitações de suporte até um determinado nível de complexidade, encaminhando apenas as restantes para o especialistas.
Donkeybot pode ser expandido e aplicado como um sistema de resposta a perguntas para suas necessidades. São necessárias alterações no código para usar o Donkeybot para seu caso de uso e dados específicos. A implementação atual se aplica a fontes de dados específicas do Rucio.
Armazenamento de dados : um armazenamento de dados que contém dados específicos do domínio Rucio. A implementação atual do módulo está em SQLite pela rápida prototipagem que ele fornece. As fontes de dados incluem e-mails de suporte seguros e anônimos de usuários do Rucio, problemas do Rucio GitHub e documentação do Rucio.
Detecção de perguntas : um módulo para detecção e extração de perguntas de qualquer texto. Isso está sendo usado para extrair perguntas anteriores de e-mails de suporte e problemas do GitHub, utilizando expressões regulares. Estas questões são arquivadas como documentos e utilizadas pelos outros módulos.
Recuperação de documentos : um módulo de mecanismo de busca que usa o algoritmo BM25 para a recuperação dos n documentos mais semelhantes (perguntas feitas anteriormente ou documentação do Rucio) para serem usados como contexto pelo módulo de detecção de respostas.
Detecção de resposta : O módulo de detecção de resposta que segue uma abordagem de aprendizagem por transferência e uma abordagem supervisionada.
Recursos adicionais incluem:
GUI de criação de FAQ : O usuário pode usar uma GUI fornecida como interface para interagir com o armazenamento de dados, inserir perguntas de FAQ, reindexar o mecanismo de pesquisa e expandir a base de conhecimento do Donkeybot.
Hashing de nome : um script que usa o tagger NER de Stanford para detectar informações privadas do usuário em e-mails de suporte e fazer hash deles. Assim, seguindo as diretrizes de privacidade do CERN e mantendo todos os dados anonimizados.
Consulte a documentação completa para exemplos, detalhes operacionais e outras informações.
Consulte FAQ: GSoC para obter um cronograma detalhado, informações dos alunos, problemas enfrentados, sugestões de melhorias futuras, uma lista de leituras e muito mais.
Você mesmo pode tentar perguntar ao Donkeybot!
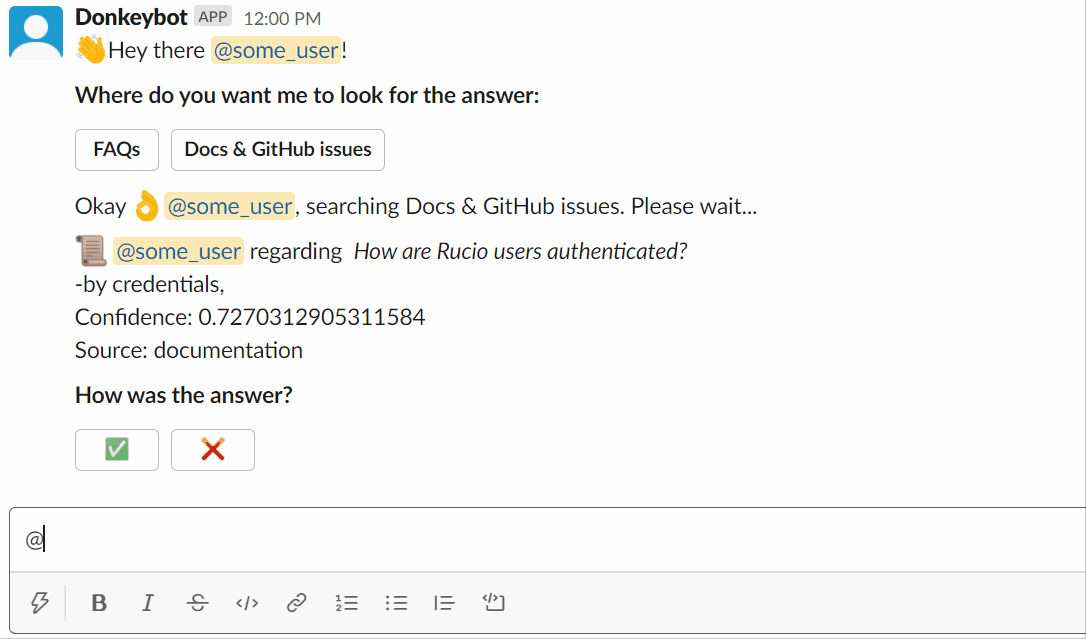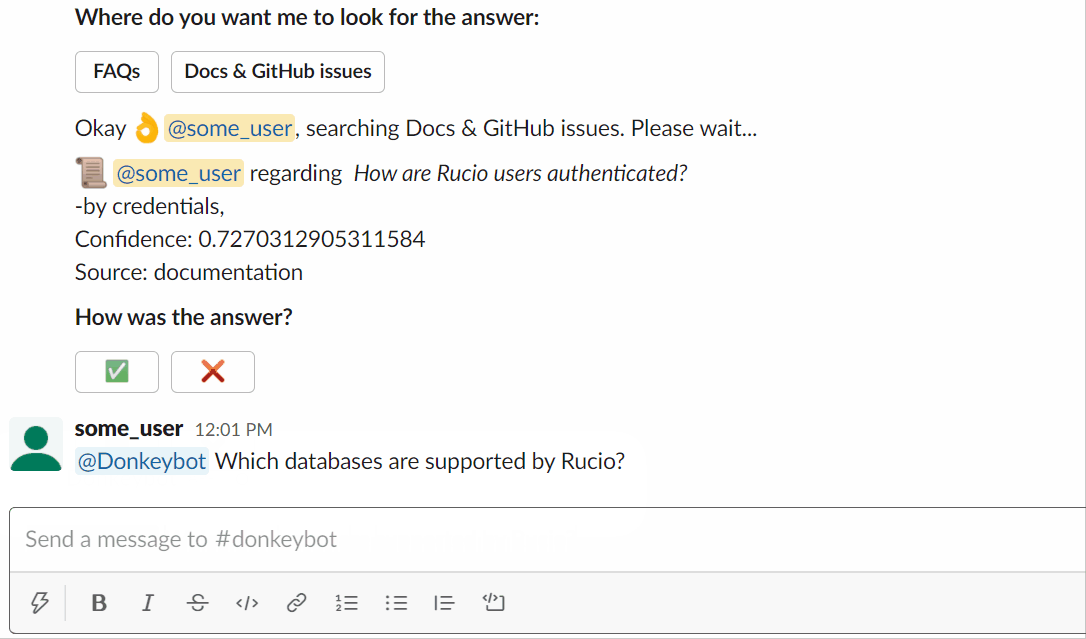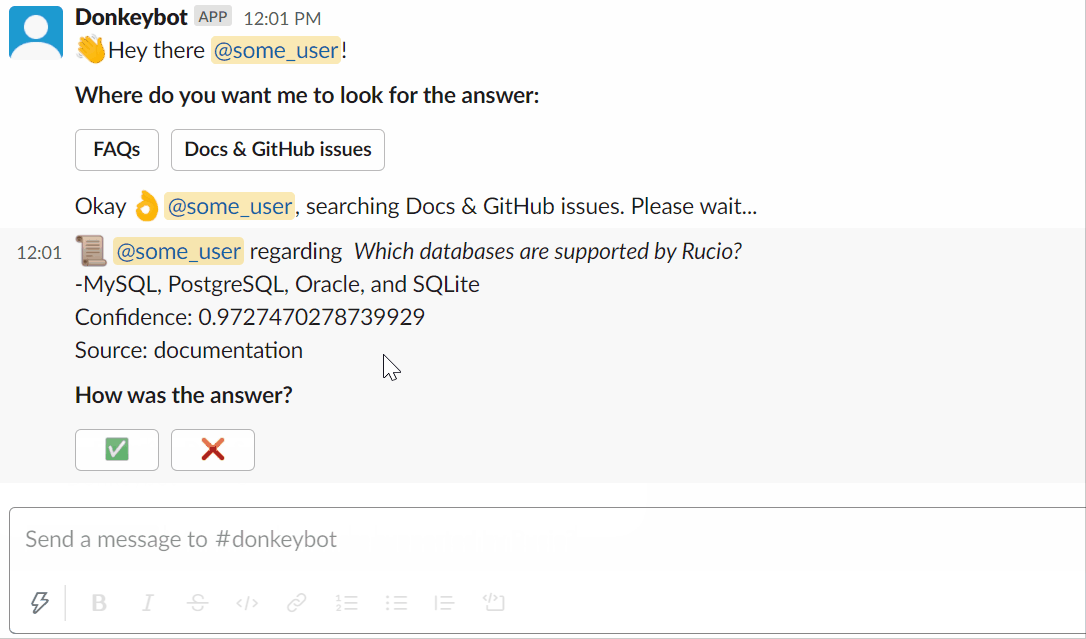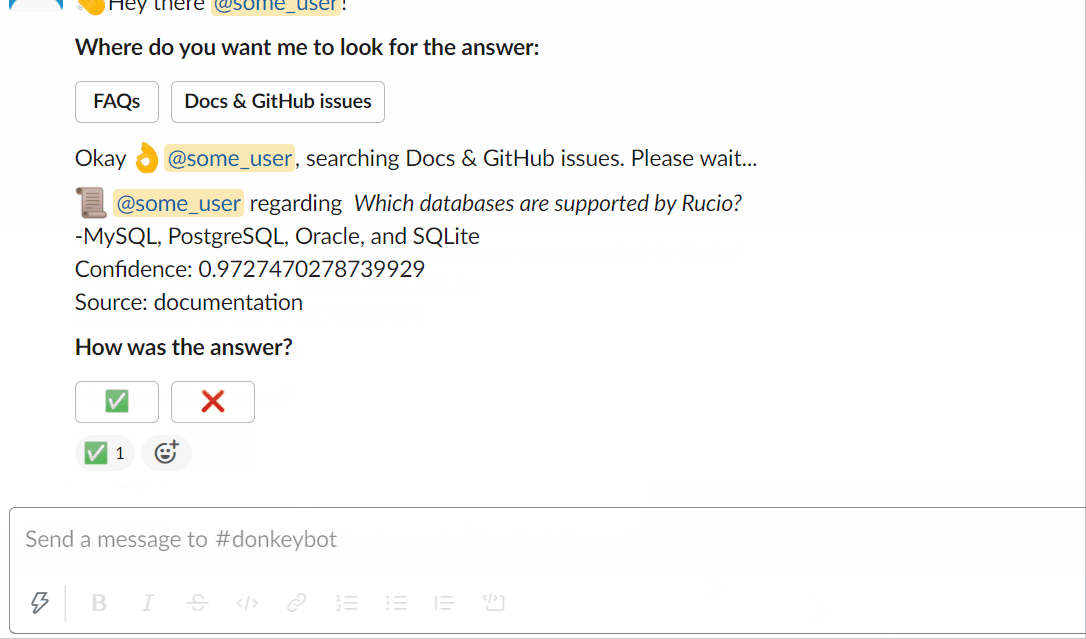
Usando o Slackbot:
Ou você pode usar a CLI:
$ python . s cripts a sk_donkeybot.py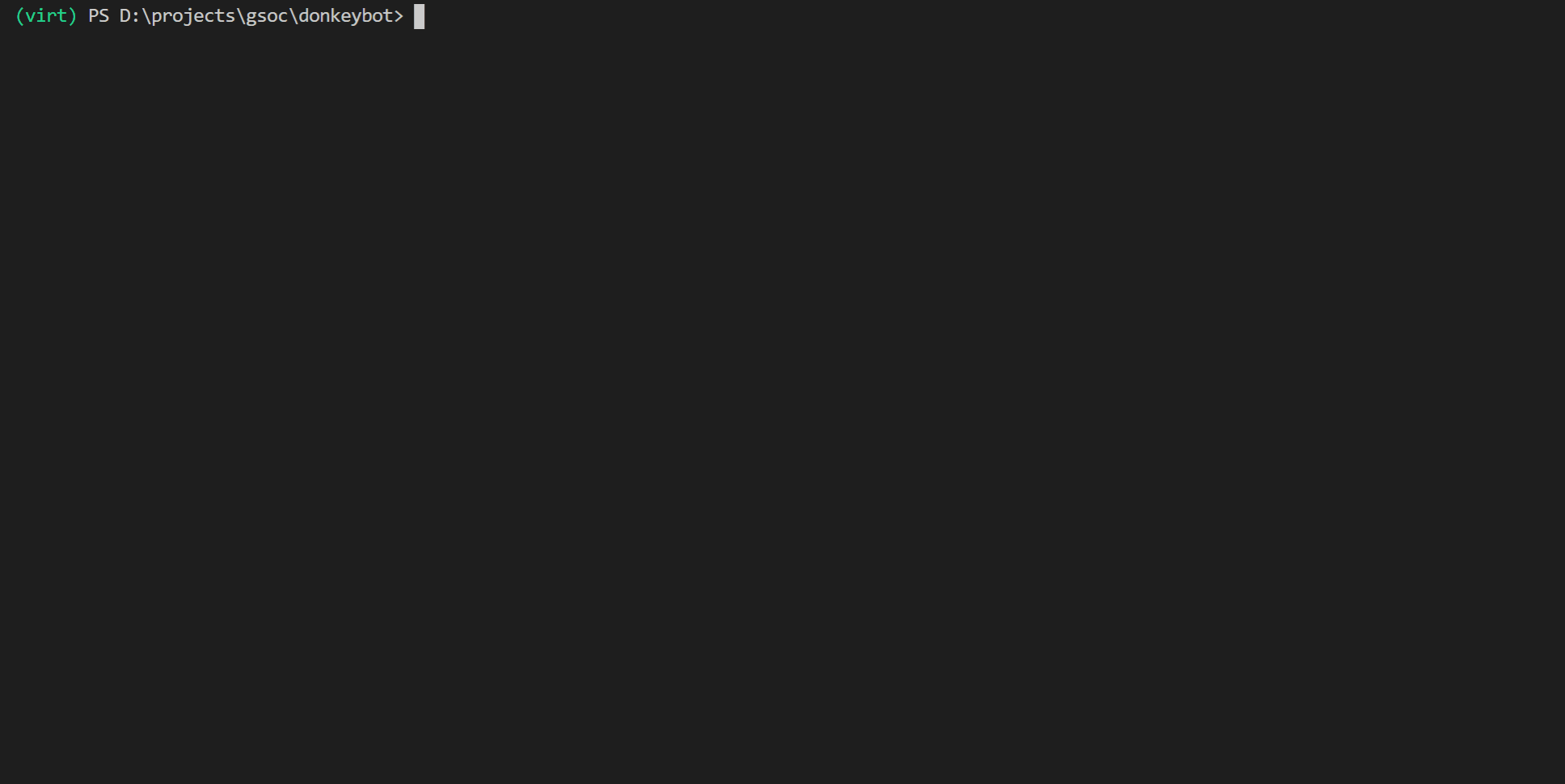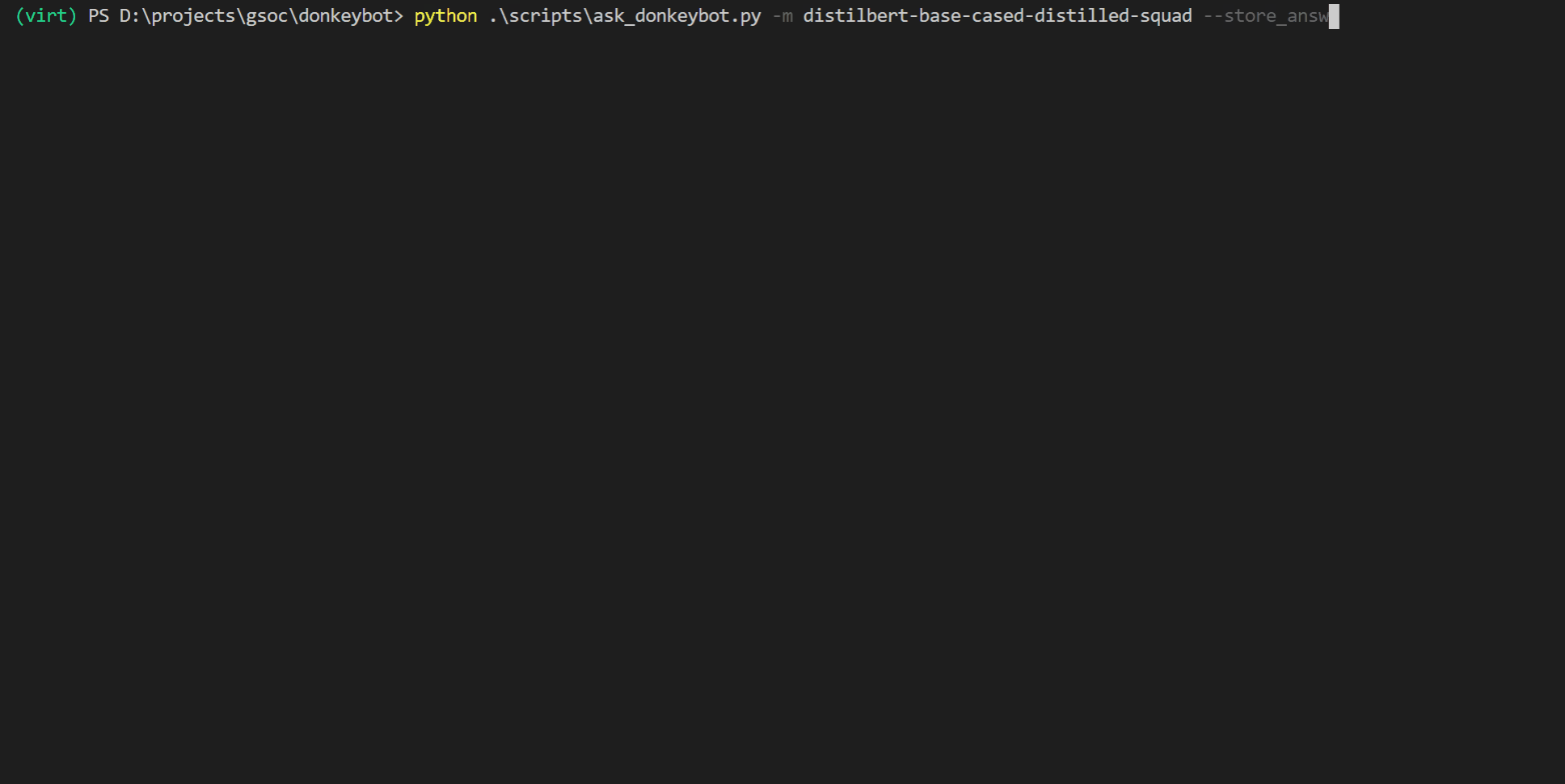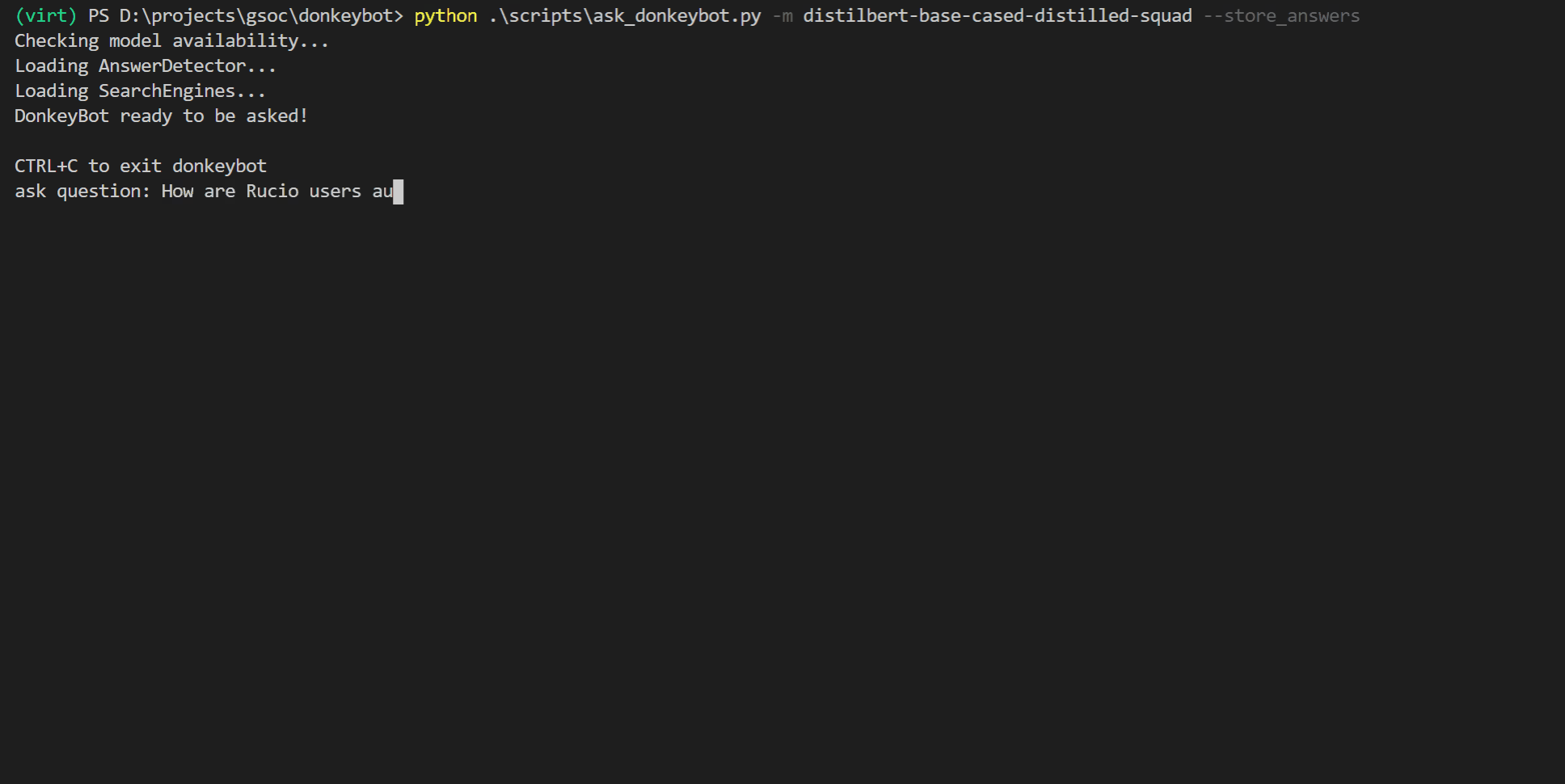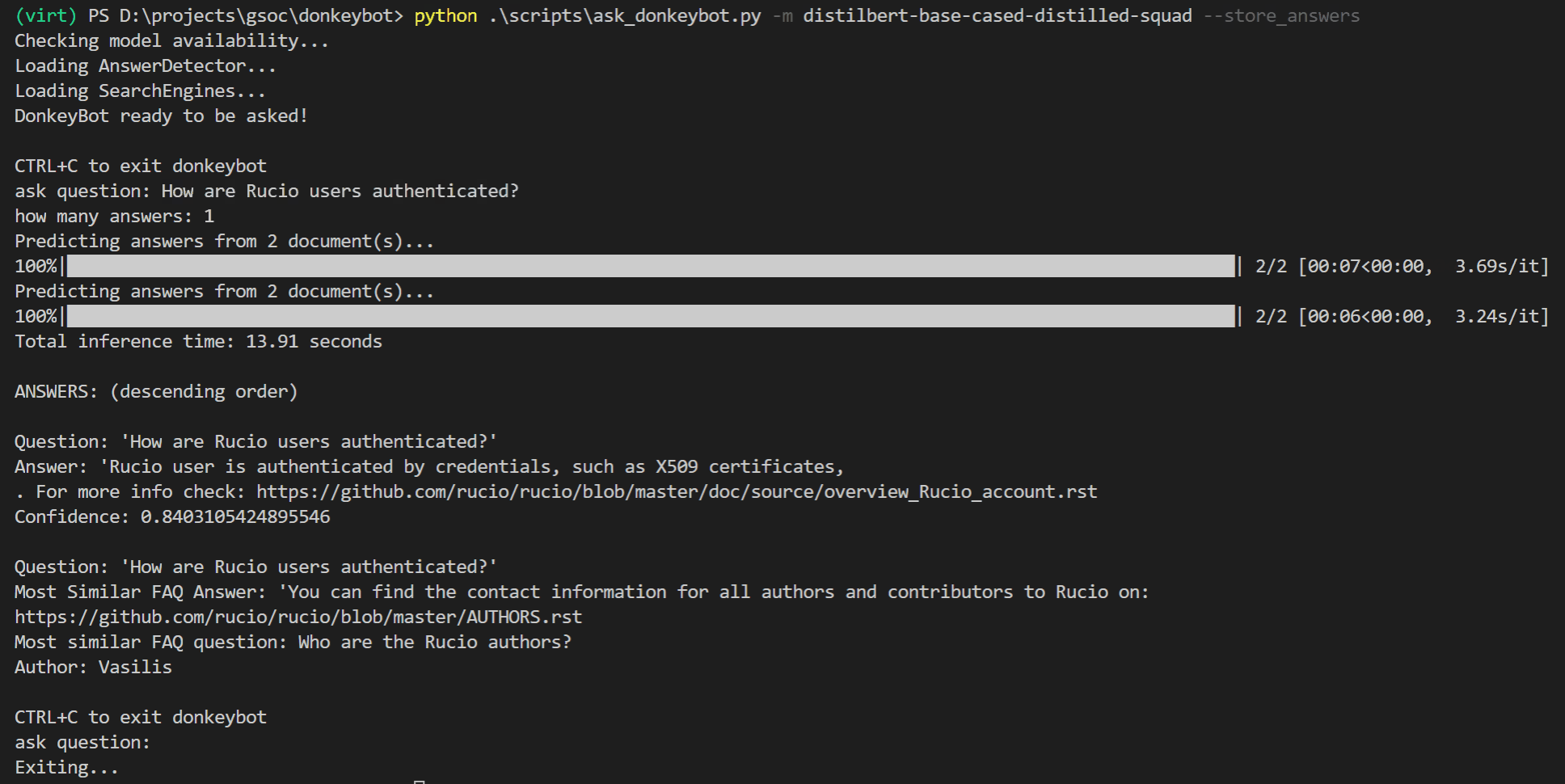
Mais exemplos e informações podem ser encontrados na seção Como usar.
Etapa 1: uma instalação do Python 3.x de 64 bits é exigida pelo PyTorch.
Passo 2: Para instalar o PyTorch, acesse https://pytorch.org/ e siga o guia de início rápido com base no seu sistema operacional.
# versions used in development
torch == 1.6 . 0 - - find - links https : // download . pytorch . org / whl / torch_stable . html
torchvision == 0.7 . 0 - - find - links https : // download . pytorch . org / whl / torch_stable . htmlEtapa 3: clone o repositório em sua máquina de desenvolvimento.
$ git clone https://github.com/rucio/donkeybot.git
$ cd donkeybotEtapa 4: Para requisitos adicionais, execute.
$ pip install -r requirements.txtEtapa 5: Construa e preencha o armazenamento de dados do Donkeybot.
$ python scripts/build_donkeybot -t < GITHUB_API_TOKEN >Consulte a página Primeiros passos para obter mais detalhes sobre como contribuir, iniciar o modo de desenvolvedor e testar.
Para bugs, dúvidas e discussões use o GitHub Issues ou entre em contato com o aluno @mageirakos.
Licenciado sob a Licença Apache, Versão 2.0;
http://www.apache.org/licenses/LICENSE-2.0


