idt
1.0.0

A ferramenta de conjunto de dados de imagens (IDT) é um aplicativo CLI desenvolvido para tornar mais fácil e rápido a criação de conjuntos de dados de imagens a serem usados para aprendizado profundo. A ferramenta consegue isso coletando imagens de vários mecanismos de busca, como duckgo, bing e deviantart. O IDT também otimiza o conjunto de dados de imagens, embora esse recurso seja opcional, o usuário pode reduzir e compactar as imagens para obter tamanhos e dimensões de arquivo ideais. Um conjunto de dados de amostra criado usando idt que contém uma quantidade total de 23.688 arquivos de imagem pesa apenas 559,2 megabytes.
Tenho orgulho de anunciar nossa mais nova versão! ??
O que mudou
Você pode instalá-lo via pip ou clonando este repositório.
user@admin:~ $ pip3 install idt
OU
user@admin:~ $ git clone https://github.com/deliton/idt.git && cd idt
user@admin:~/idt $ sudo python3 setup.py install
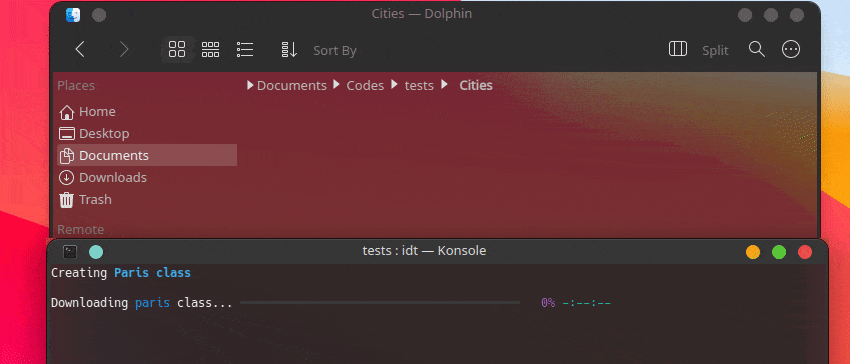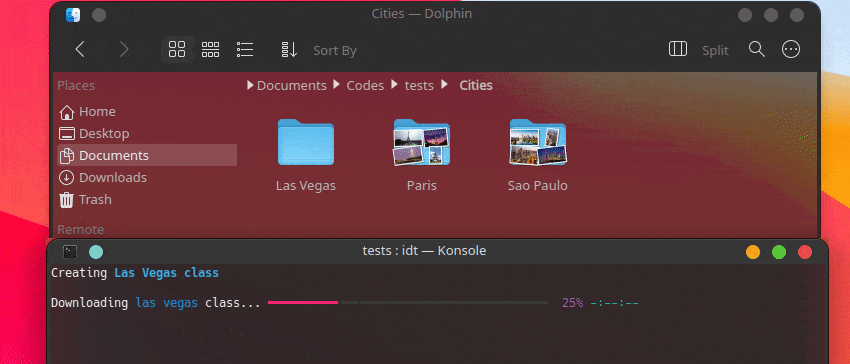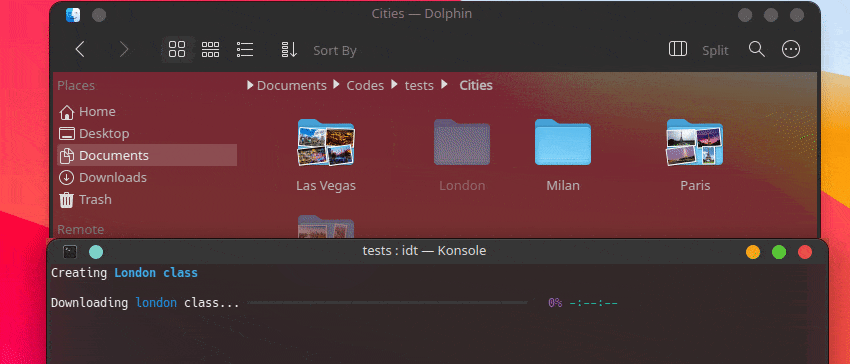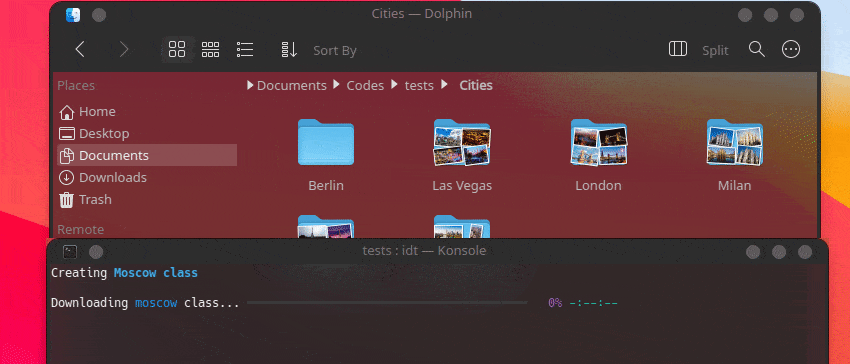
A maneira mais rápida de começar a usar o IDT é executar o simples comando “run”. Basta escrever no seu console favorito algo como:
user@admin:~ $ idt run -i apples Isso baixará rapidamente 50 imagens de maçãs. Por padrão, ele usa o mecanismo de pesquisa duckgo para fazer isso. O comando run aceita as seguintes opções:
| Opção | Descrição |
|---|---|
| -i ou --input | a palavra-chave para encontrar as imagens desejadas. |
| -s ou --size | a quantidade de imagens a serem baixadas. |
| -e ou --motor | o mecanismo de busca desejado (opções: duckgo, bing, bing_api e flickr_api) |
| --resize-método | escolha um método de redimensionamento de imagens. (opções: lado_longo, lado_curto e corte inteligente) |
| -is ou --image-size | opção para definir a proporção de tamanho de imagem desejada. padrão=512 |
| -ak ou --api-key | Se você estiver usando um mecanismo de pesquisa que requer uma chave API, esta opção é obrigatória |
O IDT requer um arquivo de configuração que informa como seu conjunto de dados deve ser organizado. Você pode criá-lo usando o seguinte comando:
user@admin:~ $ idt initEste comando acionará o criador do arquivo de configuração e solicitará os parâmetros do conjunto de dados desejados. Neste exemplo vamos criar um conjunto de dados contendo imagens dos seus carros favoritos. Os primeiros parâmetros que este comando irá perguntar são: qual nome seu conjunto de dados deve ter? Neste exemplo, vamos nomear nosso conjunto de dados como “Meus carros favoritos”
Insert a name for your dataset: : My favorite carsEm seguida, a ferramenta perguntará quantas amostras por pesquisa são necessárias para montar seu conjunto de dados. Para construir um bom conjunto de dados para aprendizado profundo, muitas imagens são necessárias e, como estamos usando um mecanismo de pesquisa para extrair imagens, muitas pesquisas com palavras-chave diferentes são necessárias para montar um conjunto de dados de bom tamanho. Este valor corresponderá a quantas imagens deverão ser baixadas a cada busca. Neste exemplo precisamos de um conjunto de dados com 250 imagens em cada classe, e usaremos 5 palavras-chave para montar cada classe. Portanto, se digitarmos o número 50 aqui, o IDT baixará 50 imagens de cada palavra-chave fornecida. Se fornecermos 5 palavras-chave, devemos obter as 250 imagens necessárias.
How many samples per search will be necessary? : 50A ferramenta agora solicitará a proporção do tamanho da imagem. Como usar imagens grandes para treinar redes neurais não é viável, podemos opcionalmente escolher uma das seguintes proporções de tamanho de imagem e reduzir nossas imagens para esse tamanho. Neste exemplo, optaremos por 512x512, embora 256x256 seja uma opção ainda melhor para esta tarefa.
Choose images resolution:
[1] 512 pixels / 512 pixels (recommended)
[2] 1024 pixels / 1024 pixels
[3] 256 pixels / 256 pixels
[4] 128 pixels / 128 pixels
[5] Keep original image size
ps: note that the aspect ratio of the image will not be changed,
so possibly the images received will have slightly different size
What is the desired image size ratio: 1E então escolha "longer_side" para o método de redimensionamento.
[1] Resize image based on longer side
[2] Resize image based on shorter side
[3] Smartcrop
ps: note that the aspect ratio of the image will not be changed,
so possibly the images received will have slightly different size
Desired Image resize method: : longer_side
Agora você deve escolher quantas classes/pastas seu conjunto de dados deve ter. Neste exemplo, essa parte pode ser bem pessoal, mas meus carros preferidos são: Chevrolet Impala, Range Rover Evoque, Tesla Model X e (por que não) AvtoVAZ Lada. Então neste caso temos 4 classes, uma para cada favorito.
How many image classes are required? : 4Depois, você será solicitado a escolher entre um dos motores de busca disponíveis. Neste exemplo, usaremos DuckGO para pesquisar imagens para nós.
Choose a search engine:
[1] Duck GO (recommended)
[2] Bing
[3] Bing API
[4] Flickr API
Select option:: 1Agora temos que fazer alguns preenchimentos repetitivos de formulários. Devemos nomear cada classe e todas as palavras-chave que serão utilizadas para encontrar as imagens. Observe que esta parte pode ser posteriormente alterada pelo seu próprio código, para gerar mais classes e palavras-chave.
Class 1 name: : Chevrolet ImpalaDepois de digitar o nome da primeira classe, seremos solicitados a fornecer todas as palavras-chave para encontrar o conjunto de dados. Lembre-se de que dissemos ao programa para baixar 50 imagens de cada palavra-chave, portanto, devemos fornecer 5 palavras-chave neste caso para obter todas as 250 imagens. Cada palavra-chave DEVE ser separada por vírgulas (,)
In order to achieve better results, choose several keywords that will
be provided to the search engine to find your class in different settings.
Example:
Class Name: Pineapple
keywords: pineapple, pineapple fruit, ananas, abacaxi, pineapple drawing
Type in all keywords used to find your desired class, separated by commas: Chevrolet Impala 1967 car photos,
chevrolet impala on the road, chevrolet impala vintage car, chevrolet impala convertible 1961, chevrolet impala 1964 lowrider
Em seguida, repita o processo de preenchimento do nome da turma e suas palavras-chave até preencher todas as 4 turmas exigidas.
Dataset YAML file has been created successfully. Now run idt build to mount your dataset!Seu arquivo de configuração do conjunto de dados foi criado. Agora é só enferrujar o seguinte comando e ver a mágica acontecer:
user@admin:~ $ idt buildE espere enquanto o conjunto de dados está sendo montado:
Creating Chevrolet Impala class
Downloading Chevrolet Impala 1967 car photos [#########################-----------] 72% 00:00:12
Ao final, todas as suas imagens estarão disponíveis em uma pasta com o nome do conjunto de dados. Além disso, um arquivo csv com as estatísticas do conjunto de dados também está incluído na pasta raiz do conjunto de dados.
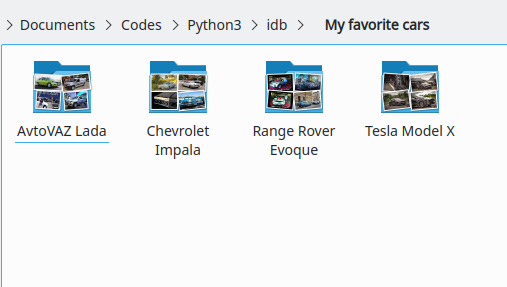
Como o aprendizado profundo geralmente exige que você divida seu conjunto de dados em um subconjunto de pastas de treinamento/validação, este projeto também pode fazer isso por você! Basta executar:
user@admin:~ $ idt splitAgora você deve escolher uma proporção trem/válido. Neste exemplo escolhi que 70% das imagens serão reservadas para treinamento, enquanto o restante será reservado para validação:
Choose the desired proportion of images of each class to be distributed in train/valid folders.
What percentage of images should be distributed towards training?
(0-100): 70
70 percent of the images will be moved to a train folder, while 30 percent of the remaining images
will be stored in a validation folder.
Is that ok? [Y/n]: yE é isso! A divisão do conjunto de dados agora deve ser encontrada com os subdiretórios train/valid correspondentes.
Este projeto está sendo desenvolvido nas minhas horas vagas e ainda precisa de muito esforço para ficar livre de bugs. Solicitações pull e contribuidores são muito apreciados, sinta-se à vontade para contribuir da maneira que puder!


