Sound Content Music Recommendation System
1.0.0

Se você é como eu, você adora música. Eu amo música e adoro encontrar novas músicas. O Spotify é um dos principais serviços de streaming de música da internet e já inclui ferramentas incríveis que ajudam você a descobrir novas músicas com base no que você ouve. Isso é feito por meio de uma combinação de diferentes algoritmos, incluindo filtragem colaborativa, onde o uso semelhante entre usuários é rastreado e usado para gerar recomendações ou recomendações baseadas em conteúdo que recomendam novas músicas com base em informações semelhantes entre as informações vinculadas a uma música. Gosta de uma música? No Spotify, você pode ouvir a ‘rádio’ daquela música, que reunirá um grupo de músicas semelhantes a essa música de alguma forma ou uma combinação de maneiras. E se você gosta de uma música, mas não se importa com nenhuma informação além do som dela? Às vezes, isso é tudo que quero ouvir.
Criei este projeto para fazer um sistema de recomendação musical baseado apenas nas informações do som da música. Isso ajudará o usuário a encontrar novas músicas por meio de músicas com sons semelhantes. Para fazer isso, também explorará as semelhanças entre todas as músicas e tentará capturar matematicamente o timbre, o ritmo e o estilo de uma música.
O som está sempre ao nosso redor. Ao longo de nossas vidas, crescemos para discernir sons diferentes dos outros. A música não é diferente - existem muitos tipos de música e a música é muitas vezes uma combinação de muitos tipos diferentes de sons e ritmos que também podemos distinguir dos outros. Mas podemos quantificar essa informação por nós mesmos? Às vezes, a música é categorizada em gêneros, o que significa que um gênero é um grupo de músicos com qualidades semelhantes de estilo, forma, ritmo, timbre, instrumentos ou cultura. Mas nem todo artista musical cria som do mesmo gênero, e nem todo gênero contém o mesmo tipo de música. Então, o que é som e como discernimos os diferentes tipos de som?
O som é uma vibração de ondas acústicas que percebemos através de nossos ouvidos quando essas ondas vibram em nossos tímpanos. Uma onda sonora é um sinal e a velocidade com que esse sinal vibra é conhecida como frequência. Se a frequência de um som for mais alta, percebemos que esse som tem um tom mais alto. Na música, instrumentos como o baixo ou o bumbo criam sons que vibram em uma frequência mais baixa, enquanto os tons agudos têm uma frequência mais alta. Soa como o choque de um prato ou de um chimbal é uma combinação de muitas ondas em frequências diferentes e é representado por uma onda 'ruidosa', de aparência quase aleatória.
Como é o som? Uma maneira de visualizar o som é representar graficamente um sinal ao longo do tempo:
À medida que encurtamos a janela de tempo em cada subtrama, podemos ver o sinal do áudio muito mais próximo. Observe na imagem mais ampliada do sinal que a onda é uma coleção de frequências diferentes. Pode haver um sinal de baixa frequência que se combina com sinais menores de alta frequência.
Assim, podemos visualizar um sinal ao longo do tempo, mas já podemos dizer que é difícil entender muito sobre aquela onda sonora apenas olhando para esta visualização. Que tipos de frequências estão presentes nessa janela de 0,01 segundo? Para responder a isso, usaremos uma transformada de Fourier para calcular um espectrograma.
A transformada de Fourier é um método de cálculo da amplitude das frequências presentes em uma seção de um sinal de áudio. Como você pode ver no gráfico acima, as ondas podem ser complexas e cada variação no sinal representa uma frequência diferente (a velocidade da vibração). Uma transformada de Fourier extrairá essencialmente as frequências para cada seção de tempo e produzirá uma matriz bidimensional de amplitudes de frequência em função do tempo. O produto de uma transformada de Fourier é um espectrograma. A partir do espectrograma, convertemos as frequências produzidas para a escala mel para criar um espectrograma mel. O espectrograma mel representa melhor a distância percebida entre as frequências conforme as ouvimos.
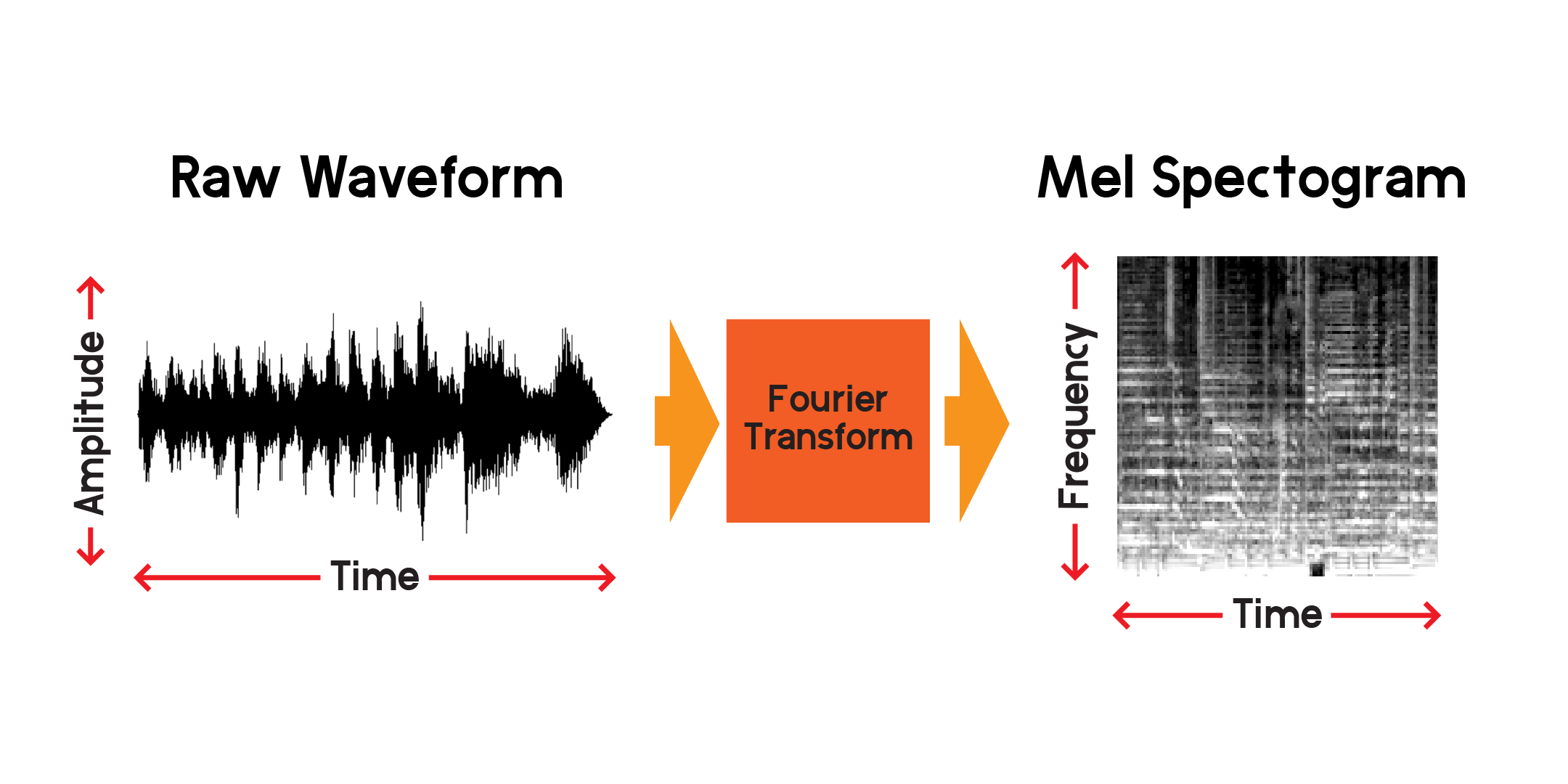
Vamos traçar um exemplo de espectrograma mel da mesma amostra de áudio que plotamos acima:
Usando a API pública do Spotify, colei informações da música em um notebook anterior. A partir daí, posso baixar uma prévia de mp3 de 30 segundos de cada música e convertê-la em um espectrograma mel para usar em uma rede neural que treina em imagens. Primeiro, vamos dar uma olhada no quadro de dados que usaremos para coletar as visualizações de mp3.
Em outro notebook, peguei links de visualização da API do Spotify, baixei os mp3s e converti os arquivos de som em uma imagem composta que contém o espectrograma mel, o coeficiente cepstral de frequência Mel e o cromagrama. Criei esta imagem composta com a intenção de poder usar essas outras transformações, mas para este projeto, treinarei apenas a rede neural nos espectrogramas mel.
Para fazer recomendações de músicas semelhantes com base apenas no conteúdo sonoro, precisarei criar recursos que de alguma forma expliquem o conteúdo das músicas. Além disso, para fazer isso rapidamente, precisarei compactar as informações de cada música em um conjunto menor de números do que a entrada dos espectrogramas mel.
Para cada arquivo de visualização de música, existem mais de 600.000 amostras. Em cada espectrograma mel, existem 512 x 128 pixels totalizando 65.536 pixels. Mesmo uma imagem de 128x128 contém 16.384 pixels. Este modelo de autoencoder compactará o conteúdo de uma música em apenas 256 números. Assim que o autoencoder for treinado o suficiente, a rede será capaz de reconstruir uma música a partir daquele vetor de comprimento 256 com uma perda mínima.
Um autoencoder é um tipo de rede neural composta por um codificador e um decodificador . Primeiro, o codificador comprimirá as informações de entrada em uma quantidade muito menor de dados e o decodificador reconstruirá os dados para ficarem o mais próximo possível da saída original.
Um autoencoder também é um tipo especial de rede neural, pois não é supervisionado, embora não seja totalmente não supervisionado. É autosupervisionado porque usa suas entradas para treinar as saídas do modelo.
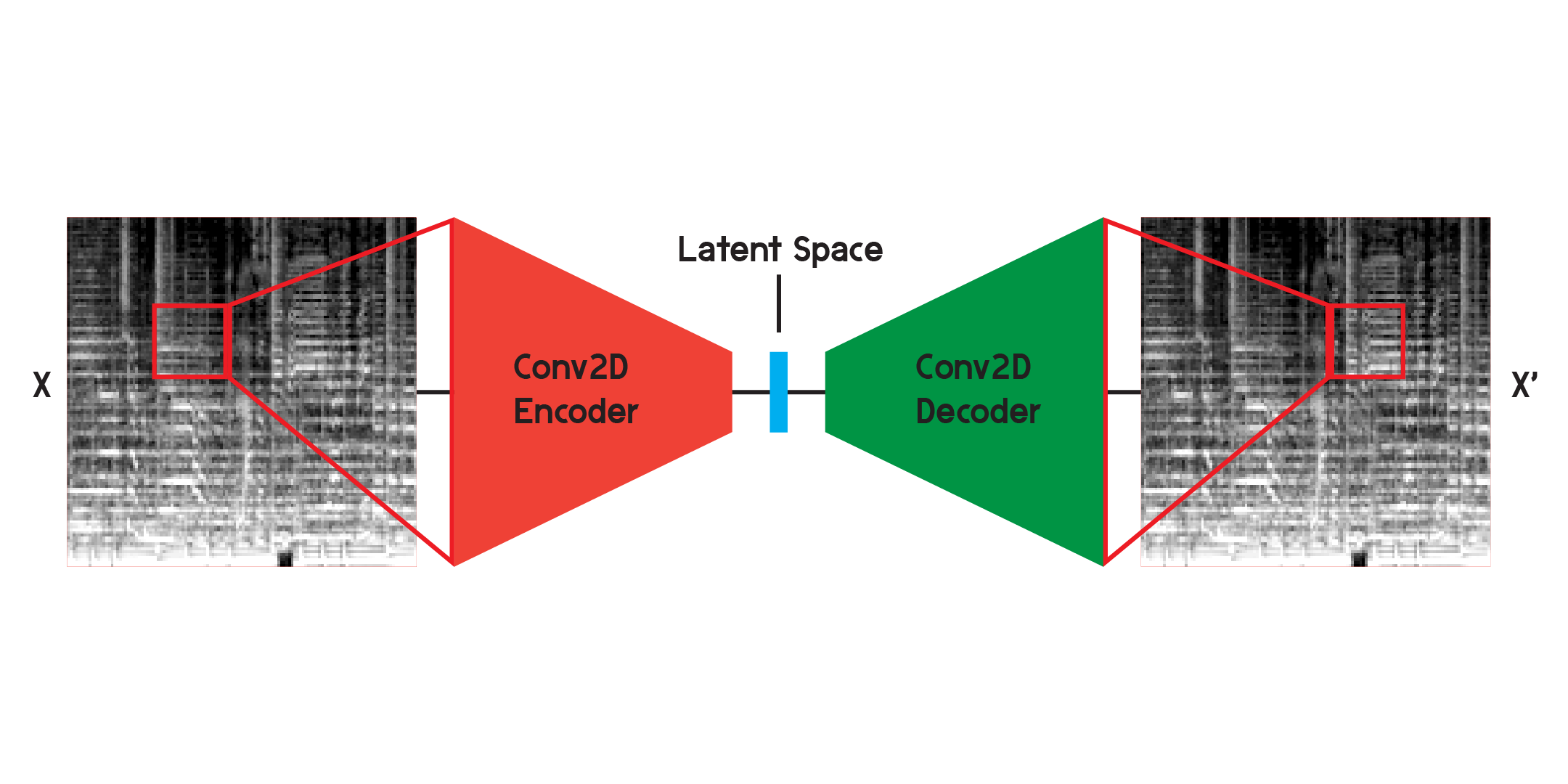
Ao trabalhar com imagens, o codificador é uma sequência de camadas convolucionais bidimensionais, que criam filtros ponderados para extrair padrões na imagem, ao mesmo tempo que comprime a imagem em um formato cada vez menor. O decodificador é um reflexo espelhado do processo no codificador, remodelando e expandindo uma pequena quantidade de dados em uma quantidade maior. O modelo minimiza o erro quadrático médio entre o original e a reconstrução. Uma vez treinado o suficiente, o erro quadrático médio entre o original e a saída do modelo será muito pequeno. Embora o erro quadrático médio seja mínimo, ainda há uma diferença visual entre a reconstrução e a imagem original, especialmente nos mínimos detalhes. O autoencoder é um redutor de ruído. Queremos extrair o máximo de detalhes possível, mas, em última análise, o autoencoder também combinará alguns detalhes.
Inicialmente treinei a rede usando a estrutura ilustrada acima, mas descobri que faltavam muitos detalhes nas reconstruções. As camadas convolucionais procuram padrões que são apenas uma pequena fatia de toda a imagem. Mas depois de treinar e observar os filtros, é difícil intuir os padrões extraídos.
Autoencoders como esses podem ser usados em diversos problemas diferentes e, com camadas convolucionais, existem muitas aplicações para reconhecimento e geração de imagens. Mas como o espectrograma mel não é apenas uma imagem, mas um gráfico de frequências no conteúdo sonoro ao longo do tempo, acredito que uma estrutura ligeiramente diferente pode ser implementada para minimizar a perda na reconstrução, ao mesmo tempo que minimiza a incerteza criada pela convolução bidimensional. camadas.
No modelo utilizado para os resultados finais do modelo, divido o codificador em dois codificadores separados. Cada codificador usa camadas convolucionais unidimensionais para compactar o espaço da imagem. Um codificador está treinando em X, enquanto o outro está treinando na transposição X ou em uma versão girada de 90 graus da entrada. Dessa forma, um codificador aprende informações do eixo do tempo da imagem e o outro aprende do eixo da frequência.
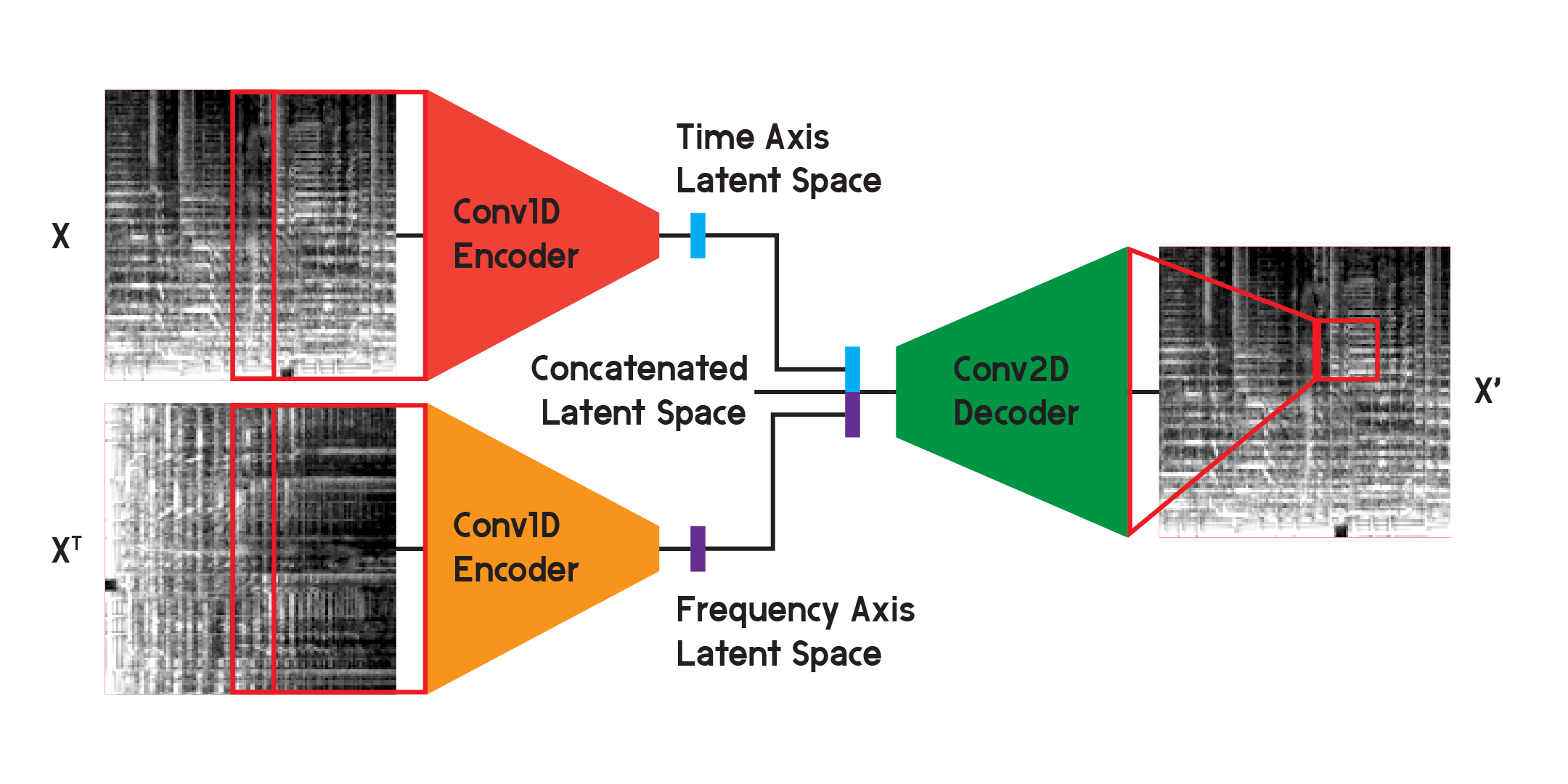
Depois que a entrada passa por cada codificador, os vetores codificados resultantes são concatenados em um vetor e inseridos no decodificador convolucional bidimensional, conforme ilustrado anteriormente. As saídas são treinadas para minimizar a perda entre as entradas como antes.
Ao final, a perda no modelo final foi bem menor do que na estrutura básica, atingindo um erro quadrático médio de 0,0037 (treinamento) e 0,0037 (validação) após 20 épocas, com 125.440 imagens no conjunto de treinamento e 2.560 no conjunto de treinamento. conjunto de validação.
Estaremos construindo o modelo aqui apenas para fins demonstrativos, pois treinei o modelo em outro notebook e carregarei os pesos do modelo treinado assim que ele for construído.
Usando uma classe personalizada para executar inferência pela rede e salvar os resultados, podemos construir o espaço latente para cada espectrograma mel que temos. Podemos fazer isso executando os dados apenas através do codificador e recebendo um vetor do tamanho que inicializamos o modelo com, neste caso, 256 dimensões.
Para explorar a paisagem abstrata criada pelo espaço latente dos dados através do modelo, podemos usar a redução de dimensionalidade. UMAP, assim como o T-SNE, pode reduzir um espaço multidimensional em 2 dimensões para visualização em um gráfico.
A classe LatentSpace personalizada procurará recomendações usando similaridade de cosseno para cada vetor.
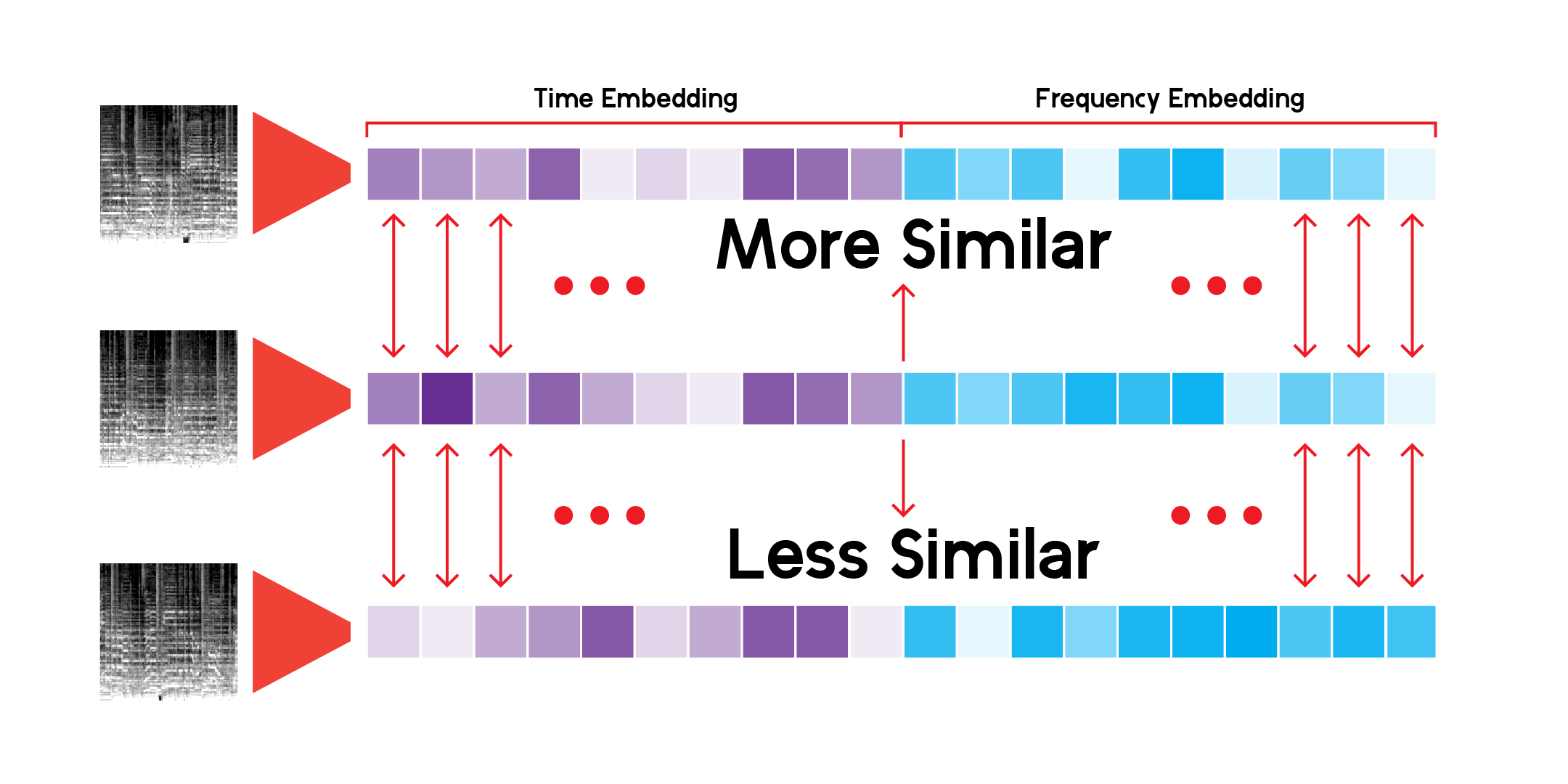
Tenho pesquisado incessantemente esse sistema de recomendação e estou satisfeito com o fato de o modelo poder detectar conexões muito interessantes entre sons musicais diferentes, mas também semelhantes. Aqui estão algumas das minhas conclusões:
O que quero dizer com isso é que o modelo faz recomendações com base no conteúdo sonoro de cada música, mas não está ouvindo a música. Ele cria um espectrograma mel e faz uma comparação matemática.
Às vezes, o sistema recomenda uma música com base na idade. Se uma música foi gravada há muito tempo, essas frequências específicas do material ou equipamento de gravação serão captadas pelo modelo e exibirão os resultados.
Além disso, o modelo é muito bom para captar vozes ou instrumentos específicos. Por causa disso, se uma música tem muita conversa ou canto, ela pode recomendar apenas faixas faladas. Além disso, se houver muita distorção em uma música, pode ser recomendado sons de chuva ou cantos de pássaros.
Algumas prévias de faixas não estão disponíveis na API do Spotify, conforme apontado em meu EDA inicial. Portanto, sua contribuição para o modelo também está faltando e não será uma recomendação quando eles puderem ser perfeitos para um. Por exemplo, não há músicas de James Brown, dos Beatles ou de Prince. Precisa de mais dados.
O sistema está usando mais de 278 mil visualizações para fazer recomendações, e isso ainda não é suficiente. Olhando para a projeção UMAP para todas as trilhas, há muita continuidade nos dados, mas existem algumas lacunas. Idealmente, o sistema poderia usar muito mais dados para se basear.
O que torna um sistema/serviços de recomendação como o Spotify tão bom em fazer recomendações é que ele combina muitos tipos diferentes de sistemas de recomendação e recursos como este para fornecer recomendações. Desde rastrear o que você ouve regularmente até usar filtragem colaborativa para encontrar recomendações com base no uso semelhante de usuários, o Spotify pode fazer previsões muito mais equilibradas sobre o que alguém vai gostar e ouvir. Acho esse modelo interessante para fazer previsões, mas ele pode ser aprimorado adicionando mais recursos, como gêneros semelhantes, anos de lançamento e dados de usuários semelhantes, para fazer previsões melhores.
Em suma, além de fazer previsões e recomendações, sinto que a verdadeira importância deste modelo existe para explicar a continuidade e o espectro da linguagem musical e do som. Géneros são rótulos que as pessoas atribuem a um artista ou som, mas os géneros misturam-se e todos os sons existem neste espaço contínuo, pelo menos matematicamente.
Além disso, a música não tem barreiras. Na maioria das vezes, ao consultar uma música no sistema de recomendação, os resultados virão de todas as épocas e lugares diferentes. Como nenhum dos metadados de uma música é uma entrada para o autoencoder, os resultados são baseados em sua semelhança sonora e nada mais.


