T5Elasticsearch
1.0.0
Abaixo está um exemplo de procura de emprego:
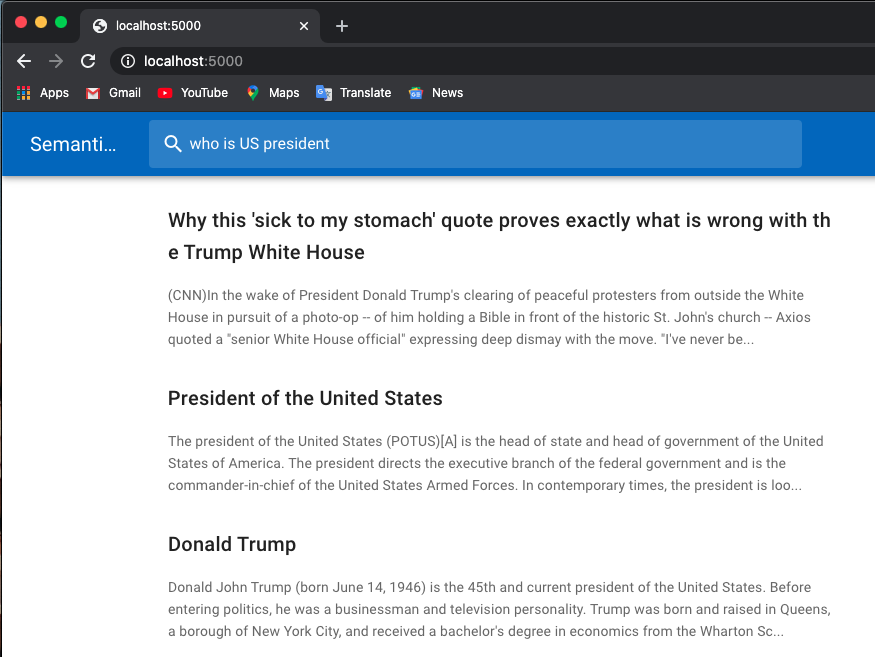
Eu uso modelos pré-treinados de transformadores huggingface.
Baixe manualmente o tokenizer pré-treinado e o modelo t5/bert nos diretórios locais. Você pode verificar os modelos aqui.
Eu uso o modelo 't5-small', verifique aqui e clique em List all files in model para baixar os arquivos. 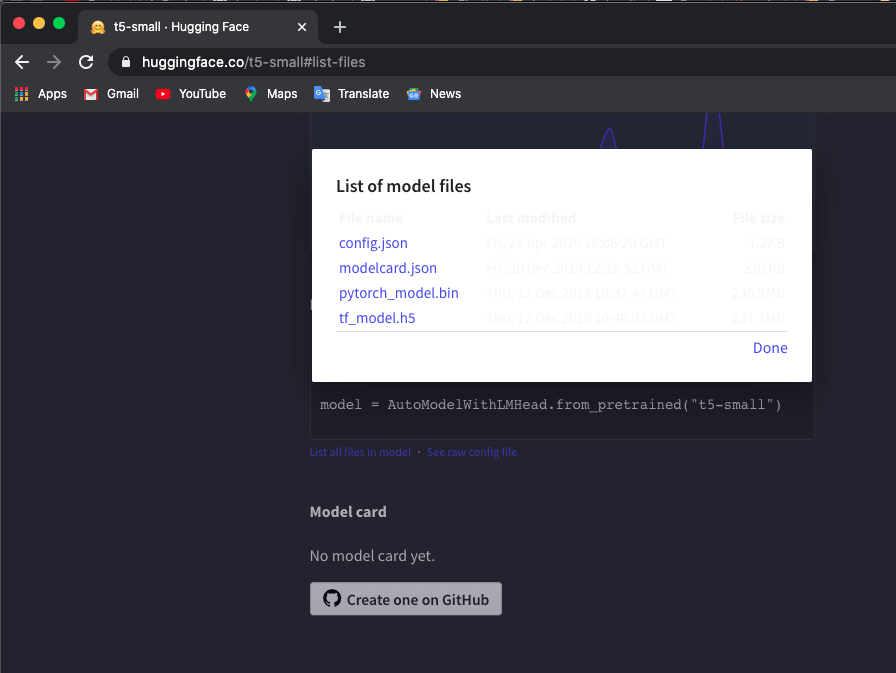
Observe a estrutura de diretórios dos arquivos baixados manualmente.
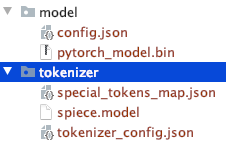
Você poderia usar outros modelos T5 ou Bert.
Se você baixar outros modelos, verifique a lista de modelos pré-trajados dos transformadores hugaface para verificar o nome do modelo.
$ export TOKEN_DIR=path_to_your_tokenizer_directory/tokenizer
$ export MODEL_DIR=path_to_your_model_directory/model
$ export MODEL_NAME=t5-small # or other model you downloaded
$ export INDEX_NAME=docsearch$ docker-compose up --build Eu também uso docker system prune para remover todos os contêineres, redes e imagens não utilizados para obter mais memória. Aumente a memória do docker (eu uso 8GB ) se você encontrar Container exits with non-zero exit code 137 .
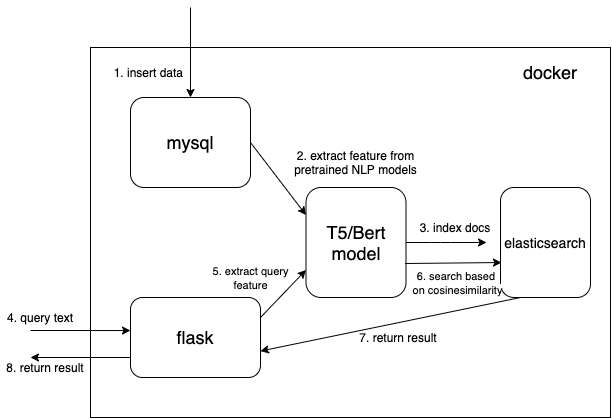
Usamos tipo de dados de vetor denso para salvar os recursos extraídos de modelos de PNL pré-treinados (t5 ou bert aqui, mas você mesmo pode adicionar seus modelos pré-treinados de interesse)
{
...
"text_vector" : {
"type" : " dense_vector " ,
"dims" : 512
}
...
} Dimensões dims:512 é para modelos T5. Altere dims para 768 se você usar modelos Bert.
Leia o documento do mysql e converta o documento no formato json correto para aumentar o volume no elasticsearch.
$ cd index_files
$ pip install -r requirements.txt
$ python indexing_files.py
# or you can customize your parameters
# $ python indexing_files.py --index_file='index.json' --index_name='docsearch' --data='documents.jsonl'Vá para http://127.0.0.1:5000.
O código-chave para usar o modelo pré-treinado para extrair recursos é a função get_emb nos arquivos ./index_files/indexing_files.py e ./web/app.py .
def get_emb ( inputs_list , model_name , max_length = 512 ):
if 't5' in model_name : #T5 models, written in pytorch
tokenizer = T5Tokenizer . from_pretrained ( TOKEN_DIR )
model = T5Model . from_pretrained ( MODEL_DIR )
inputs = tokenizer . batch_encode_plus ( inputs_list , max_length = max_length , pad_to_max_length = True , return_tensors = "pt" )
outputs = model ( input_ids = inputs [ 'input_ids' ], decoder_input_ids = inputs [ 'input_ids' ])
last_hidden_states = torch . mean ( outputs [ 0 ], dim = 1 )
return last_hidden_states . tolist ()
elif 'bert' in model_name : #Bert models, written in tensorlow
tokenizer = BertTokenizer . from_pretrained ( 'bert-base-multilingual-cased' )
model = TFBertModel . from_pretrained ( 'bert-base-multilingual-cased' )
batch_encoding = tokenizer . batch_encode_plus ([ "this is" , "the second" , "the thrid" ], max_length = max_length , pad_to_max_length = True )
outputs = model ( tf . convert_to_tensor ( batch_encoding [ 'input_ids' ]))
embeddings = tf . reduce_mean ( outputs [ 0 ], 1 )
return embeddings . numpy (). tolist ()Você pode alterar o código e usar seu modelo pré-treinado favorito. Por exemplo, você pode usar o modelo GPT2.
você também pode personalizar seu elasticsearch usando sua própria função de pontuação em vez de cosineSimilarity em .webapp.py .
Este representante é modificado com base em Hironsan/bertsearch, que usa pacotes bert-serving para extrair recursos bert. Limita a TF1.x


