nlp lt
1.0.0
A principal intenção desta pesquisa é estudar e aprender os princípios do processamento de linguagem natural (PNL) para a língua lituana. É interessante analisar métodos clássicos de PNL e ver como eles funcionam nisso, então neste trabalho implementei classificação de texto, extração de tópicos, consulta de pesquisa e agrupamento de ideias. Detalhes de implementação e mais informações estão armazenados em paper/paper.pdf
A análise de dados não pode ser estabelecida sem dados textuais, por isso meu trabalho começou com a obtenção de dados brutos do site de notícias mais popular www.delfi.lt. Decidi rastrear artigos de 5 categorias (Criminosos[227 artigos], Música[120 artigos], Filmes[167 artigos], Esportes[136 artigos], Ciência[204 artigos]).
O desempenho da classificação é medido usando uma matriz de confusão onde as linhas são categorias verdadeiras e as colunas são categorias previstas. Além disso, tal abordagem atinge acima de 90% de recall e 90% de precisão. 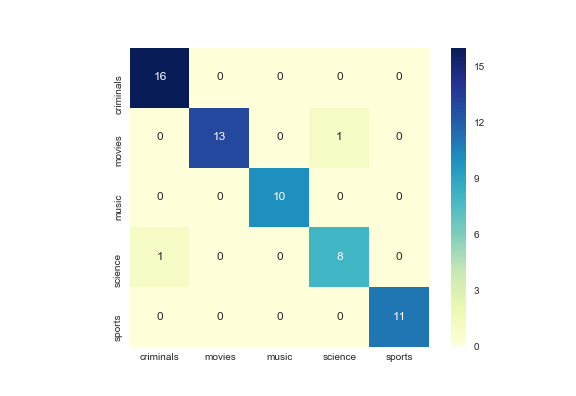
A figura mostra 6 componentes com 10 tokens para cada componente. A partir desses resultados podemos detectar as palavras mais importantes e adivinhar intuitivamente o tópico para cada componente principal. Por exemplo, 4 componentes principais armazenam informações sobre esportes e música, enquanto 6 componentes principais armazenam informações sobre criminosos.
Os principais resultados são apresentados a seguir: 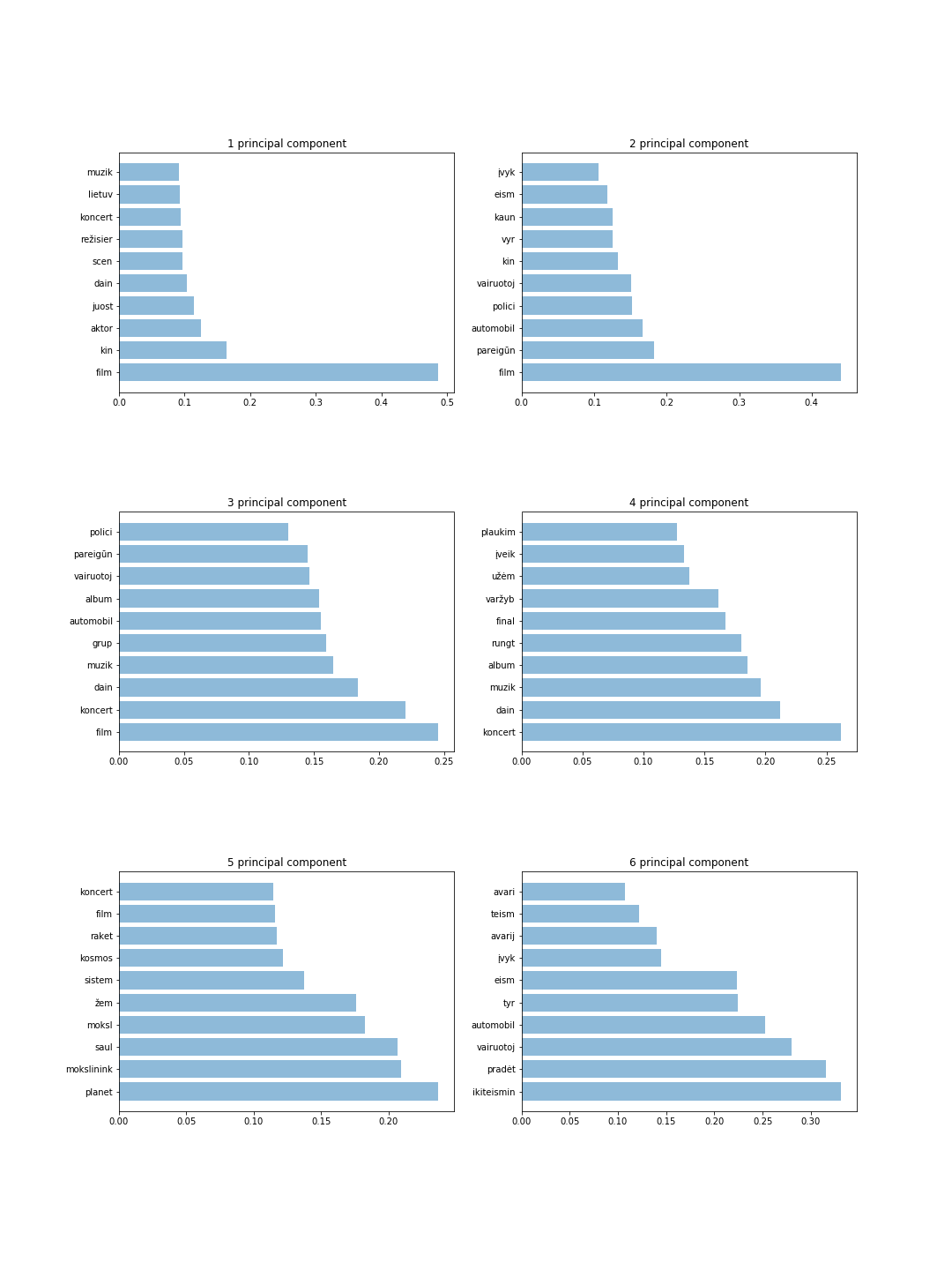
A pesquisa é baseada no artigo http://webhome.cs.uvic.ca/~thomo/svd.pdf, onde lsa é aplicado para encontrar documentos relacionados usando não apenas semelhanças exatas de consulta, mas também relações mais profundas entre documentos. 
Consulta = "švietim apdovanojam"
Resultado:
Em progresso


