context search engine
1.0.0

O objetivo principal deste projeto é mostrar os recursos de pesquisa vetorial, fornecendo uma interface amigável que permite aos usuários realizar pesquisas contextuais em um corpus de documentos de texto. Ao aproveitar o poder do BERT do Hugging Face e do FAISS do Facebook, retornamos passagens de texto altamente relevantes com base no significado semântico da consulta do usuário, em vez de meras correspondências de palavras-chave. Este projeto serve como ponto de partida para desenvolvedores, pesquisadores e entusiastas que desejam se aprofundar no mundo da pesquisa de texto contextualizada e aprimorar suas aplicações com técnicas de PNL de última geração.
Meu objetivo é garantir que entendemos o banco de dados vetorial do zero.
Captura de tela do aplicativo:
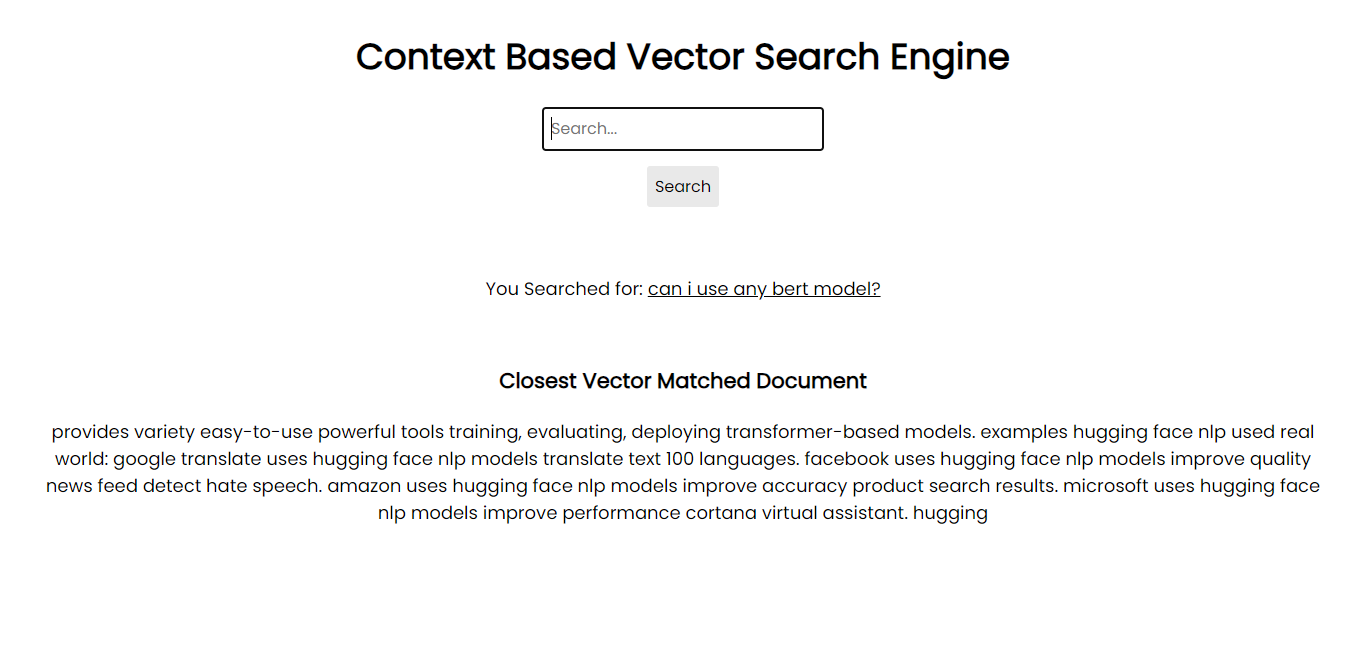
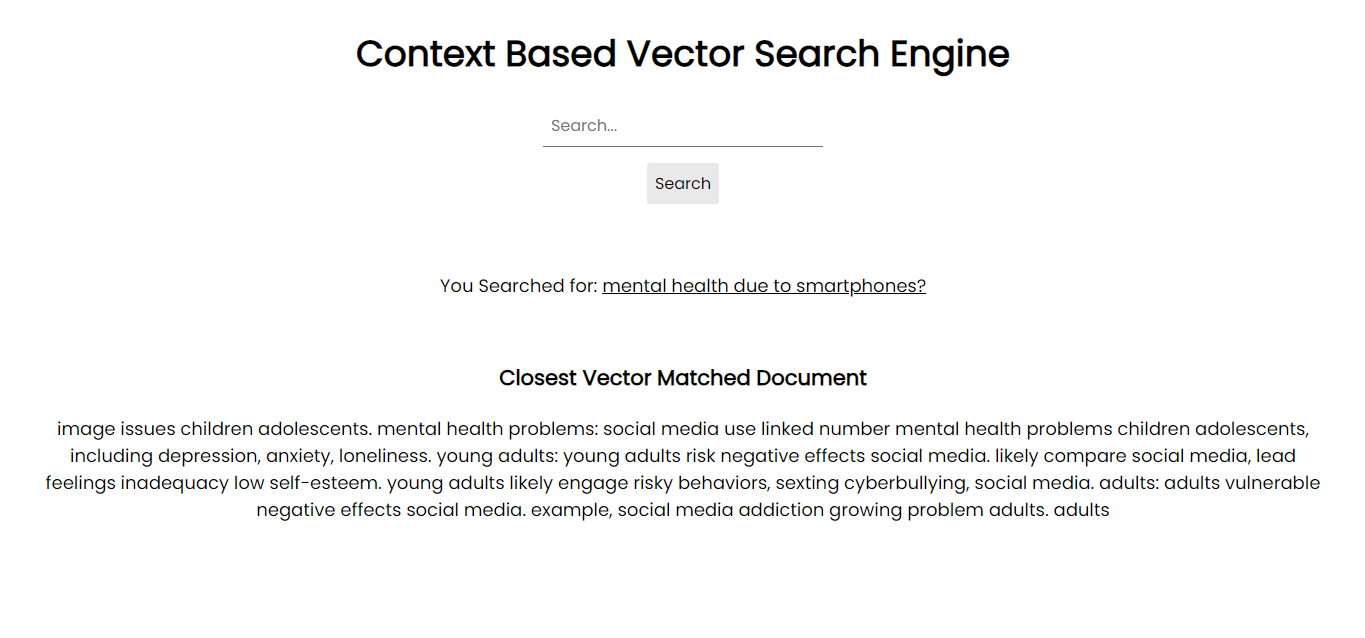
Para rodar em seu sistema, você pode instalar todos os pacotes necessários via pip usando os arquivos de requisitos:
pip install -r requirements.txtPara sua informação, estou usando Python 3.10.1.
No entanto, se você tiver uma GPU, será solicitado que você instale a GPU FAISS para integrações de banco de dados maiores e mais rápidas.
A versão atual deste projeto abrange:
Embora o projeto ofereça um sistema de pesquisa contextual funcional, ele foi projetado para ser modular, permitindo potencial expansão e integração em sistemas ou aplicações maiores.
A base deste projeto reside na crença de que as técnicas modernas de PNL podem oferecer resultados de pesquisa muito mais precisos e contextualmente relevantes em comparação com os métodos tradicionais baseados em palavras-chave. Aqui está um resumo de nossa abordagem:
Com base na abordagem, dividi o projeto em 2 seções:
Seção 1: Gerando dados vetoriais pesquisáveis
Nesta seção, primeiro lemos a entrada dos documentos, dividimos em pedaços menores, criamos vetores usando o modelo baseado em BERT e, em seguida, armazenamos de forma eficiente usando FAISS. Aqui está um diagrama de fluxo que ilustra o mesmo.
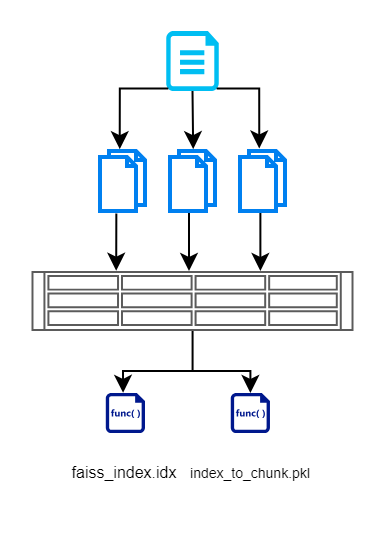
Criamos um arquivo de índice FAISS que contém representação vetorial do documento fragmentado. Também armazenamos o índice de cada pedaço. Isso é mantido para que não tenhamos que consultar o banco de dados/documentos novamente. Isso nos ajuda a remover operações de leitura redundantes.
Executamos esta seção usando create_index.py. Ele irá gerar os 2 arquivos acima. Se precisar usar outros modelos, você está aberto para fazê-lo no hub HuggingFace?
Nota: Se você encontrar problemas na configuração do hiperparâmetro para dimensão, verifique o arquivo config.json dos modelos para encontrar detalhes sobre a dimensão do modelo que você está tentando usar.
Seção 2: Construindo Interface de Aplicativo Pesquisável
Nesta seção, meu objetivo é construir uma interface que permita aos usuários interagir com os documentos. Priorizo o design minimalista sem causar obstáculos adicionais.
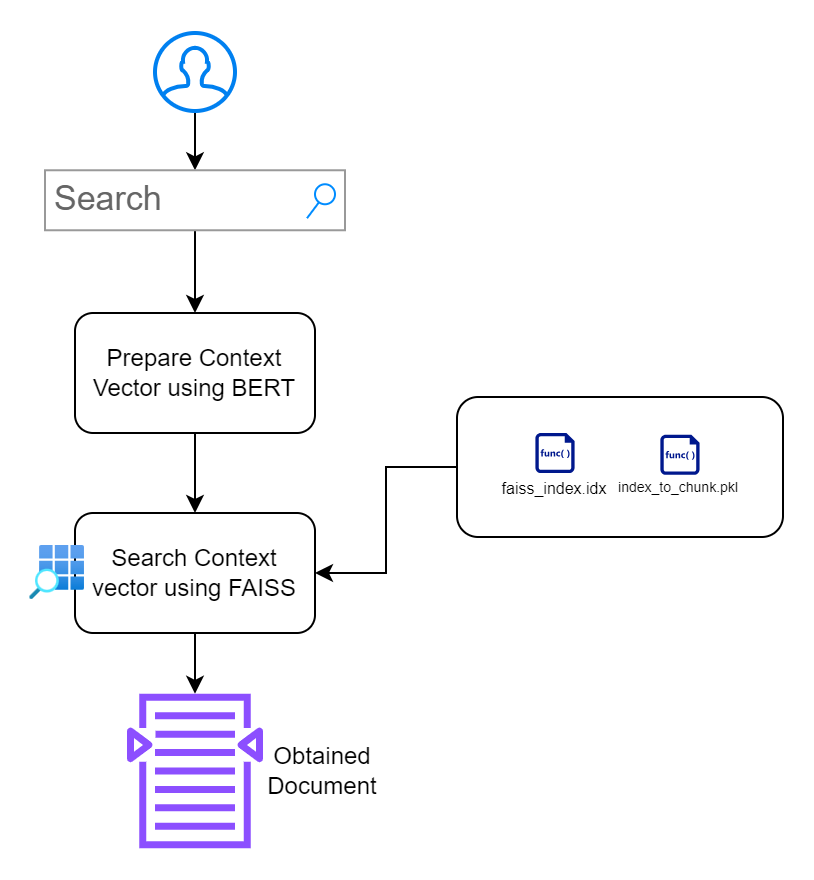
index.html : página HTML front-end para inserir consultas de pesquisa.app.py : aplicativo Flask que atende o front-end e lida com consultas de pesquisa.search_engine.py : contém lógica para geração de incorporação, pesquisa FAISS e destaque de palavras-chave. /context_search/
- templates/
- index.html
- static/
- css/
- style.css
- images/
- img1.png
- img2.png
- Approach.png files
- app.py
- search_engine.py
- create_index.py
- index_to_chunk.pkl
- faiss_index.idxfaiss_index.idx ) e um mapeamento do índice para o bloco de texto ( index_to_chunk.pkl ). python app.py
-- OR --
flask run --host=127.0.0.1 --port=5000
http://localhost:5000 .Sempre há espaço para melhorias. Aqui estão algumas melhorias potenciais e recursos adicionais que podem ser integrados:
Este projeto está sob a licença do MIT. Sinta-se à vontade para usar, citar, modificar, distribuir e contribuir. Leia mais.
Se você estiver interessado em melhorar este projeto, suas contribuições serão bem-vindas! Abra uma solicitação pull ou problema neste repositório. Estou essencialmente priorizando as coisas acima para fazer melhorias. Outras solicitações pull também serão consideradas, mas menos priorizadas.
Agradecemos antecipadamente pelo seu interesse. :feliz: .


