system design primer
1.0.0
Inglês ∙ 日本語 ∙ 简体中文 ∙ 繁體中文 | العَرَبِيَّة ∙ বাংলা ∙ Português do Brasil ∙ Deutsch ∙ ελληνικά ∙ עברית ∙ Italiano ∙ 한국어 ∙ فارسی ∙ Polski ∙ русский язык ∙ Español ∙ ภาษาไทย ∙ Türkçe ∙ tiếng Việt ∙ Français | Adicionar tradução
Ajude a traduzir este guia!
Aprenda como projetar sistemas em grande escala.
Prepare-se para a entrevista de design do sistema.
Aprender como projetar sistemas escaláveis o ajudará a se tornar um engenheiro melhor.
O design do sistema é um tópico amplo. Há uma grande quantidade de recursos espalhados pela web sobre princípios de design de sistemas.
Este repositório é uma coleção organizada de recursos para ajudá-lo a aprender como construir sistemas em escala.
Este é um projeto de código aberto continuamente atualizado.
Contribuições são bem-vindas!
Além da codificação das entrevistas, o design do sistema é um componente obrigatório do processo de entrevista técnica em muitas empresas de tecnologia.
Pratique perguntas comuns de entrevistas sobre design de sistemas e compare seus resultados com exemplos de soluções : discussões, códigos e diagramas.
Tópicos adicionais para preparação para entrevistas:
Os decks de flashcard Anki fornecidos usam repetição espaçada para ajudá-lo a reter os principais conceitos de design do sistema.
Ótimo para usar em trânsito.
Procurando recursos para ajudá-lo a se preparar para a entrevista de codificação ?
Confira o repositório irmão Interactive Coding Challenges , que contém um deck Anki adicional:
Aprenda com a comunidade.
Sinta-se à vontade para enviar solicitações pull para ajudar:
Conteúdo que precisa de algum polimento é colocado em desenvolvimento.
Revise as Diretrizes de Contribuição.
Resumos de vários tópicos de design de sistema, incluindo prós e contras. Tudo é uma troca .
Cada seção contém links para recursos mais detalhados.
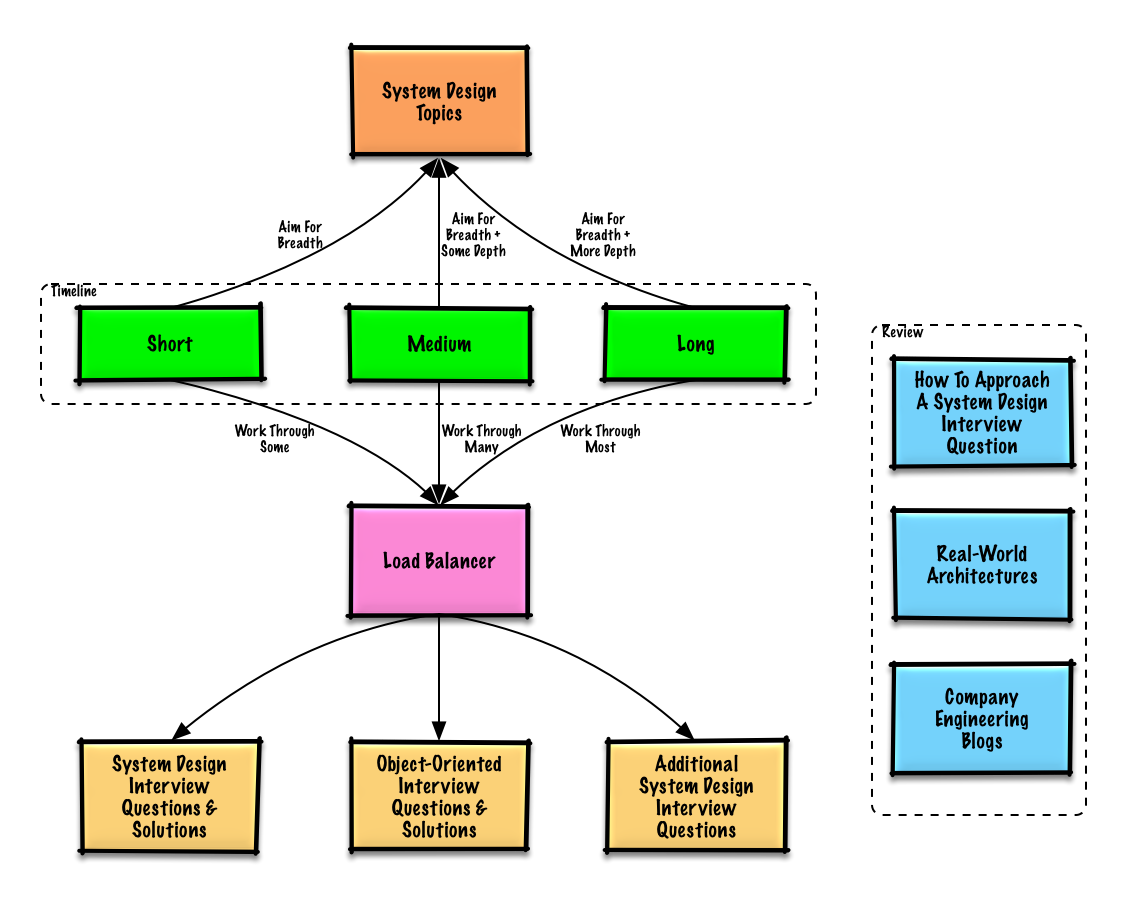
Tópicos sugeridos para revisão com base no cronograma da sua entrevista (curta, média, longa).
P: Para entrevistas, preciso saber tudo aqui?
R: Não, você não precisa saber tudo aqui para se preparar para a entrevista .
O que lhe é perguntado em uma entrevista depende de variáveis como:
Geralmente, espera-se que candidatos mais experientes saibam mais sobre design de sistemas. Pode-se esperar que os arquitetos ou líderes de equipe saibam mais do que colaboradores individuais. As principais empresas de tecnologia provavelmente terão uma ou mais rodadas de entrevistas de design.
Comece amplo e aprofunde-se em algumas áreas. Ajuda saber um pouco sobre vários tópicos importantes de design de sistema. Ajuste o guia a seguir com base em seu cronograma, experiência, para quais cargos você está entrevistando e para quais empresas você está entrevistando.
| Curto | Médio | Longo | |
|---|---|---|---|
| Leia os tópicos de design de sistema para obter uma compreensão ampla de como os sistemas funcionam | ? | ? | ? |
| Leia alguns artigos nos blogs de engenharia da empresa para as empresas com as quais você está entrevistando | ? | ? | ? |
| Leia algumas arquiteturas do mundo real | ? | ? | ? |
| Revise Como abordar uma pergunta de entrevista de design de sistema | ? | ? | ? |
| Trabalhe nas perguntas da entrevista de design de sistema com soluções | Alguns | Muitos | Maioria |
| Trabalhe com perguntas de entrevistas de design orientado a objetos com soluções | Alguns | Muitos | Maioria |
| Revise as perguntas adicionais da entrevista sobre design de sistema | Alguns | Muitos | Maioria |
Como responder a uma questão de entrevista de design de sistema.
A entrevista de design do sistema é uma conversa aberta . Espera-se que você o lidere.
Você pode usar as etapas a seguir para orientar a discussão. Para ajudar a solidificar esse processo, trabalhe na seção Perguntas da entrevista de design de sistema com soluções usando as etapas a seguir.
Reúna os requisitos e avalie o problema. Faça perguntas para esclarecer casos de uso e restrições. Discuta suposições.
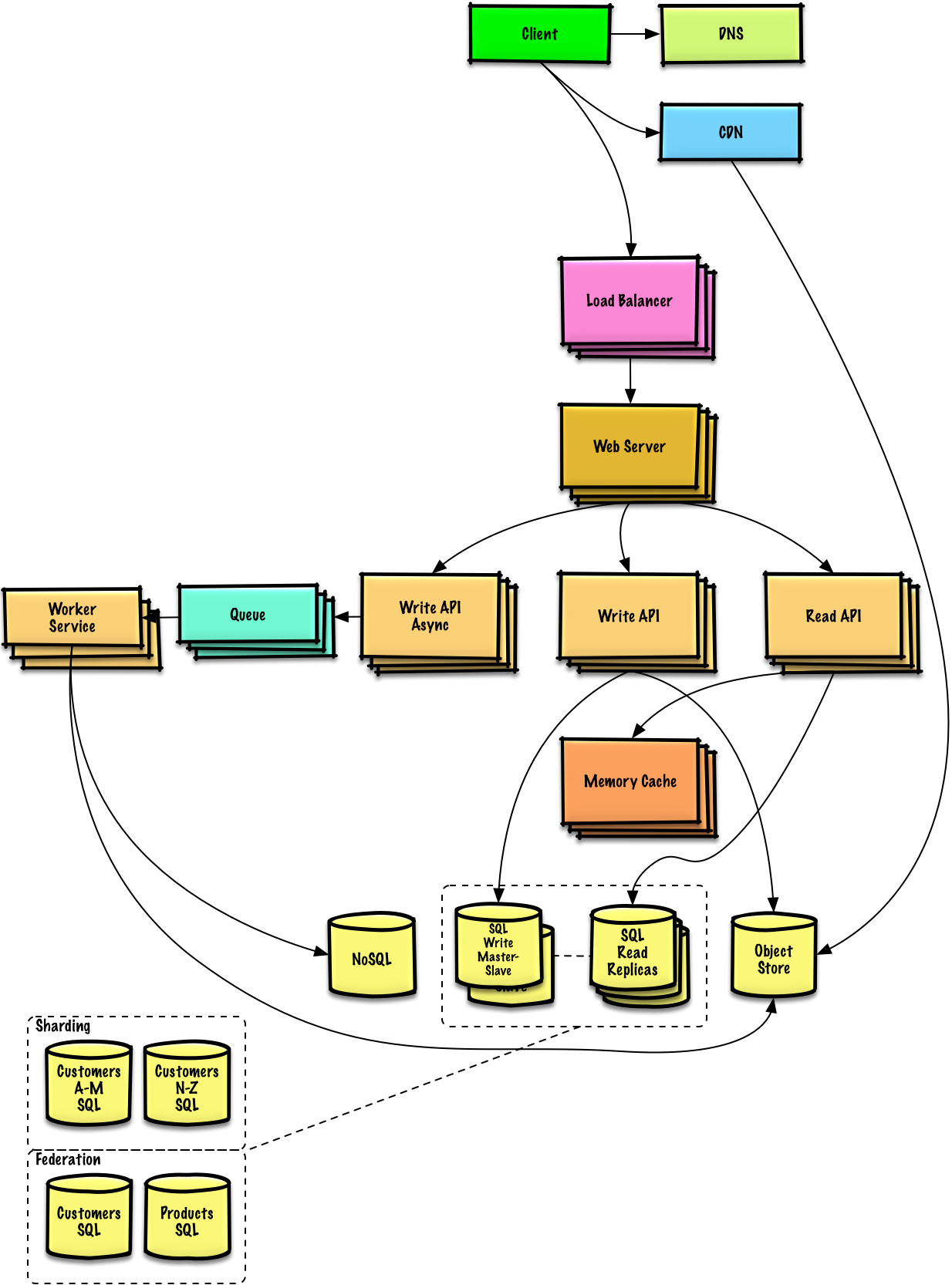
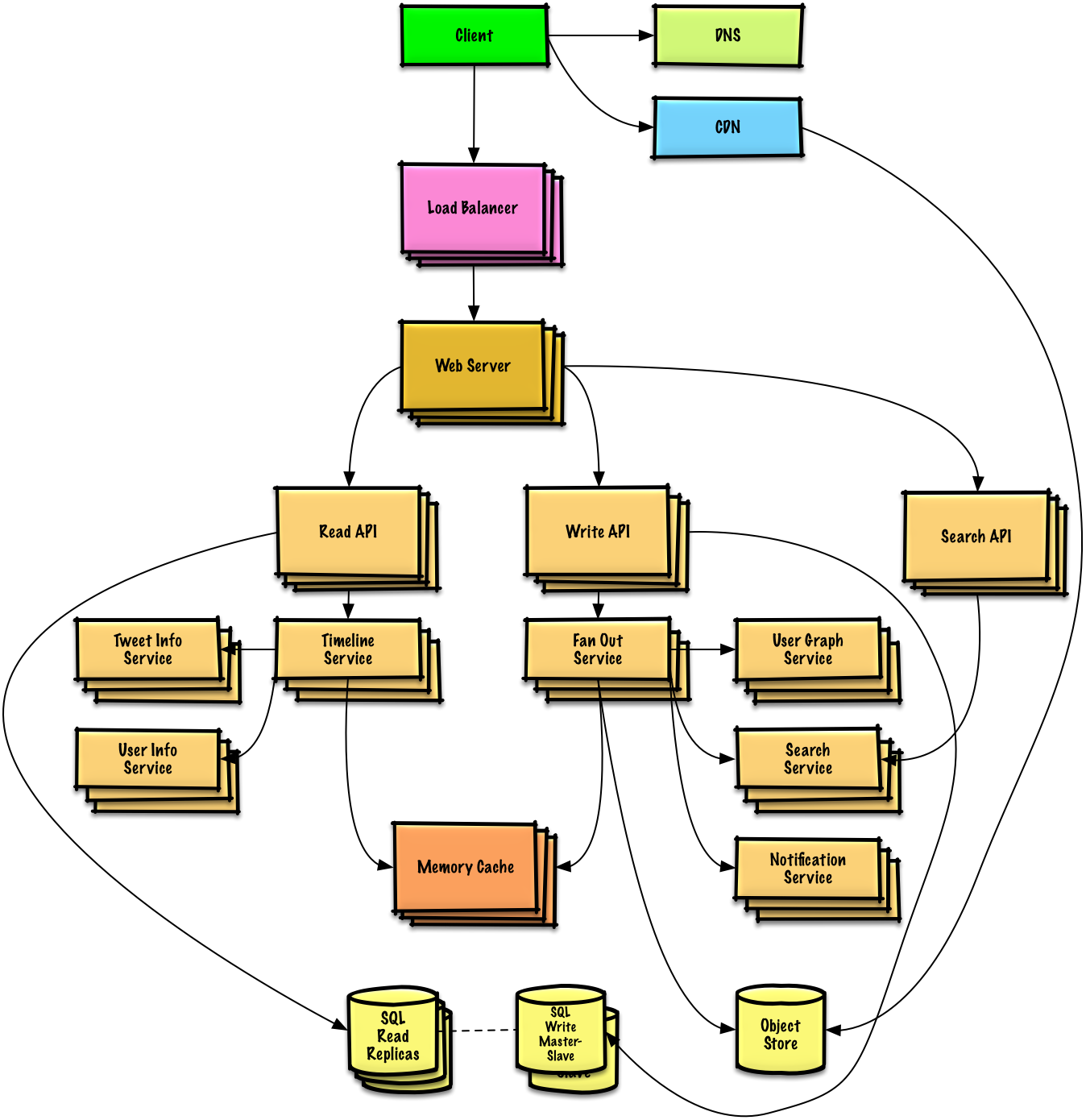
Descreva um design de alto nível com todos os componentes importantes.
Mergulhe nos detalhes de cada componente principal. Por exemplo, se você foi solicitado a criar um serviço de encurtamento de URL, discuta:
Identifique e resolva os gargalos, dadas as restrições. Por exemplo, você precisa do seguinte para resolver problemas de escalabilidade?
Discuta possíveis soluções e compensações. Tudo é uma troca. Resolva gargalos usando princípios de design de sistema escalonável.
Você pode ser solicitado a fazer algumas estimativas manualmente. Consulte o Apêndice para os seguintes recursos:
Confira os links a seguir para ter uma ideia melhor do que esperar:
Perguntas comuns de entrevistas sobre design de sistema com exemplos de discussões, códigos e diagramas.
Soluções vinculadas ao conteúdo da pasta
solutions/.
| Pergunta | |
|---|---|
| Crie Pastebin.com (ou Bit.ly) | Solução |
| Projete a linha do tempo e a pesquisa do Twitter (ou feed e pesquisa do Facebook) | Solução |
| Projete um rastreador da web | Solução |
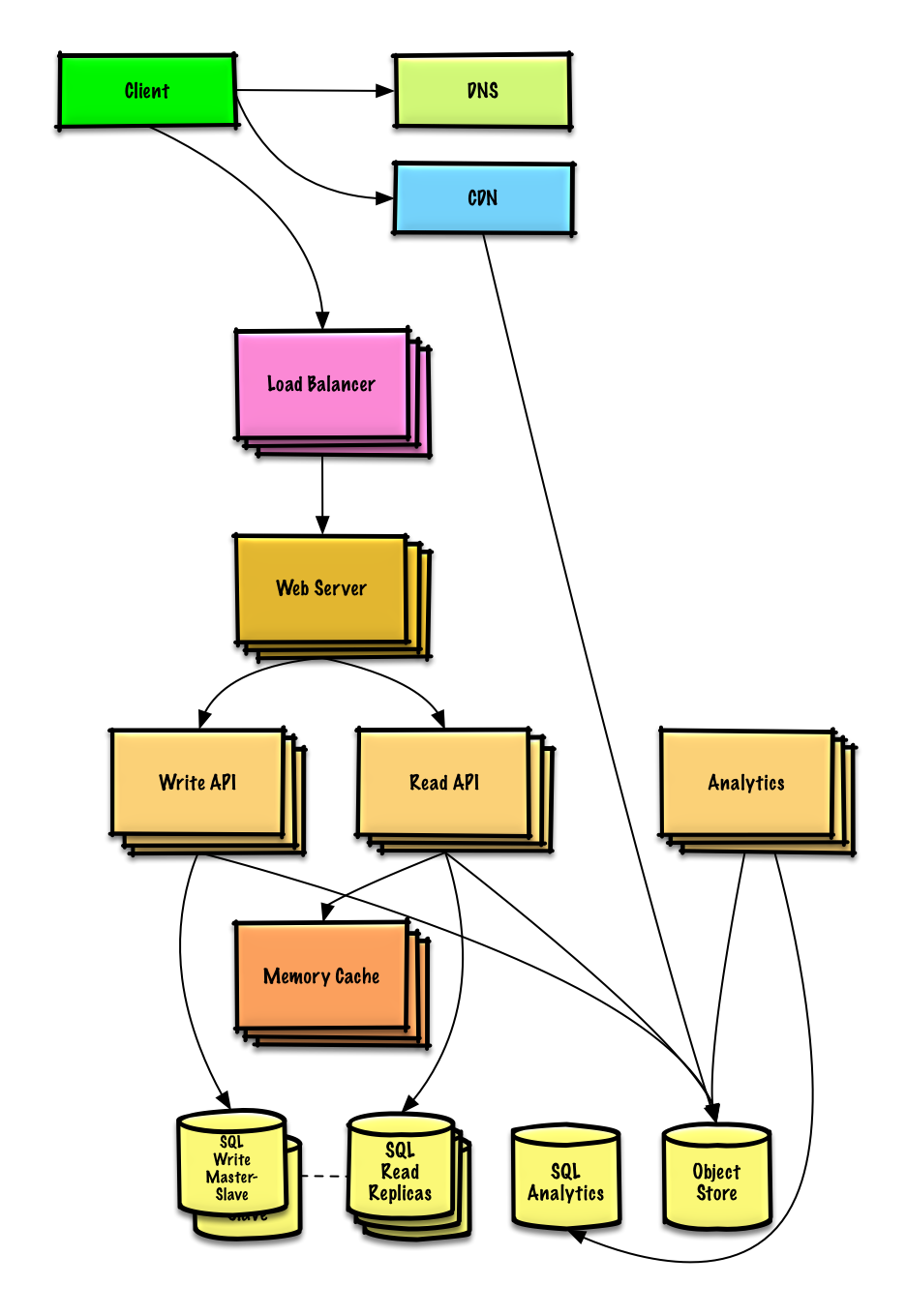
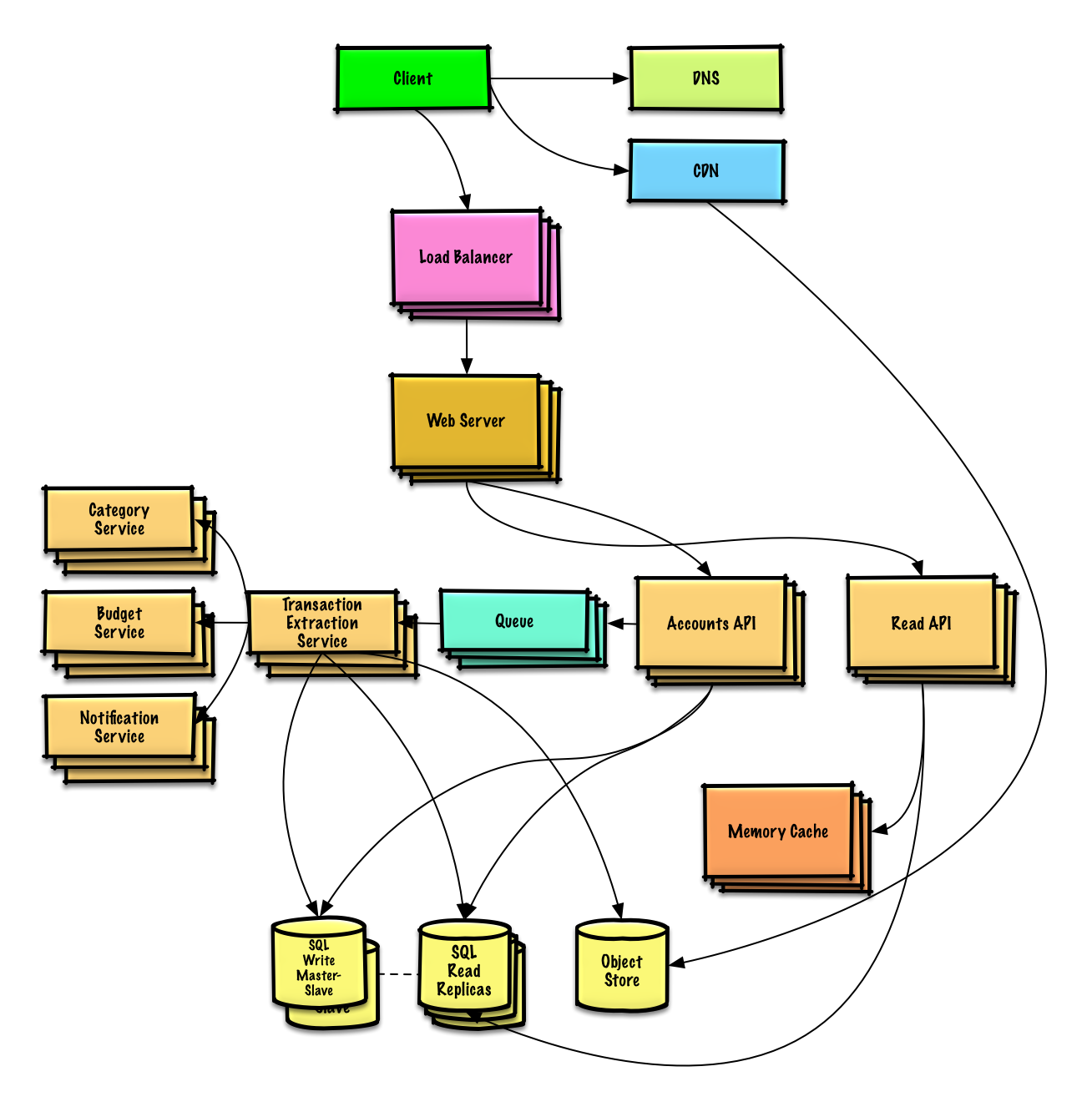
| Design Mint.com | Solução |
| Projete as estruturas de dados para uma rede social | Solução |
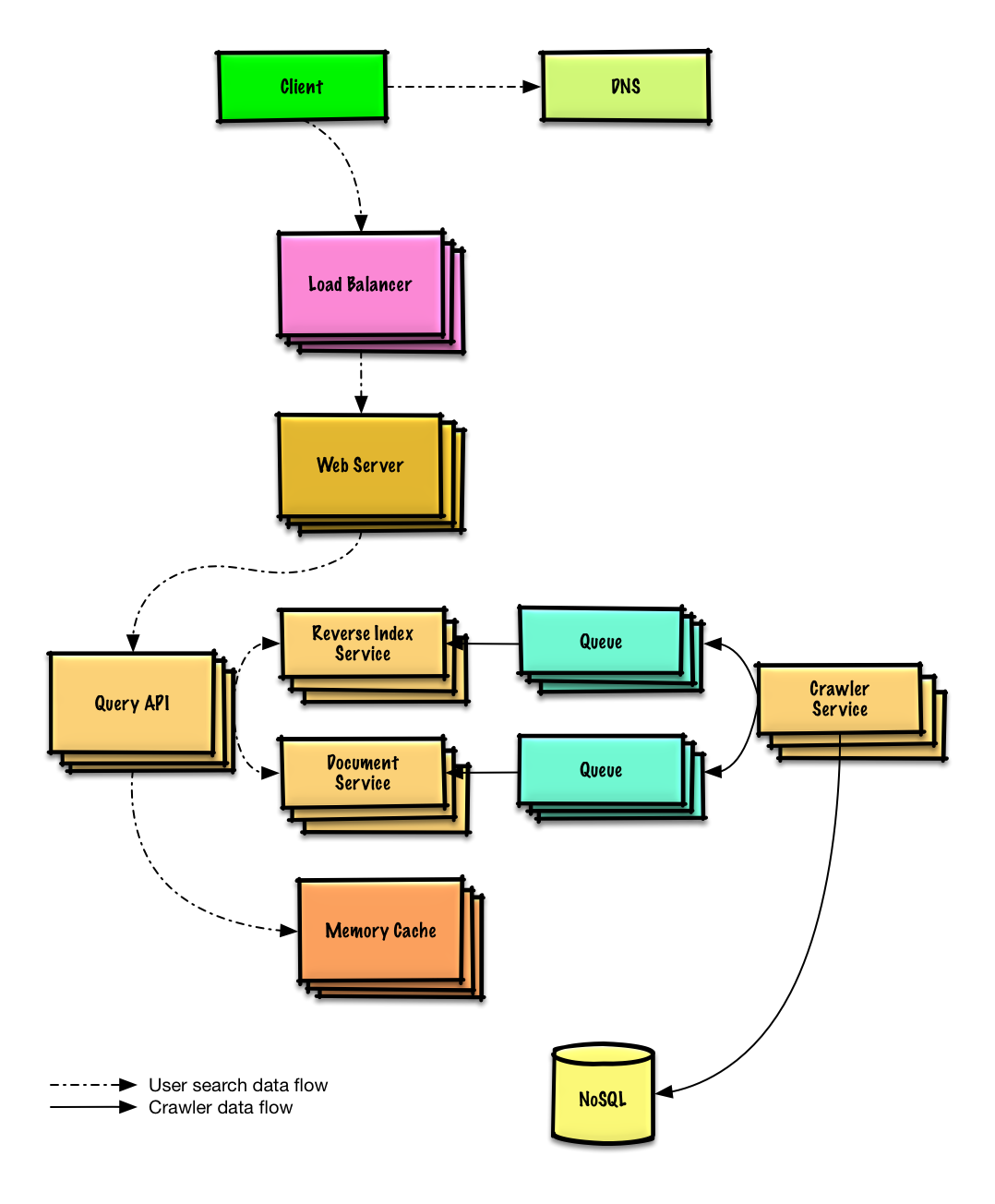
| Projete um armazenamento de valores-chave para um mecanismo de pesquisa | Solução |
| Projete a classificação de vendas da Amazon por recurso de categoria | Solução |
| Projete um sistema que seja dimensionado para milhões de usuários na AWS | Solução |
| Adicione uma pergunta de design de sistema | Contribuir |
Ver exercício e solução
Ver exercício e solução
Ver exercício e solução
Ver exercício e solução
Ver exercício e solução
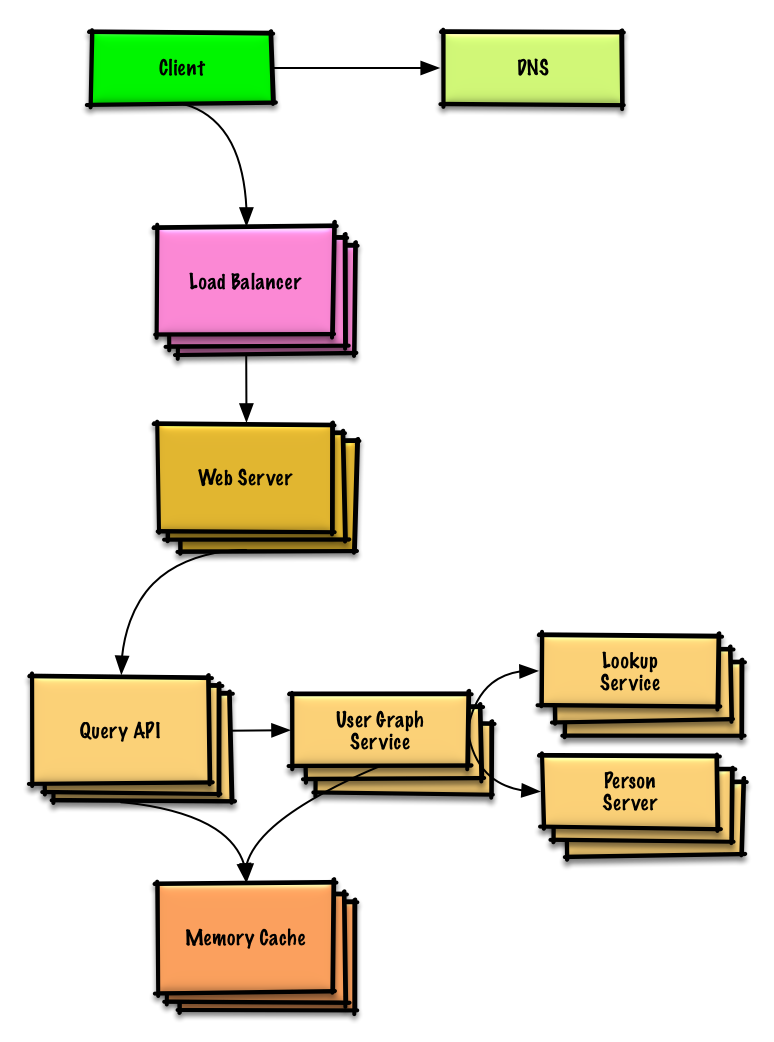
Ver exercício e solução
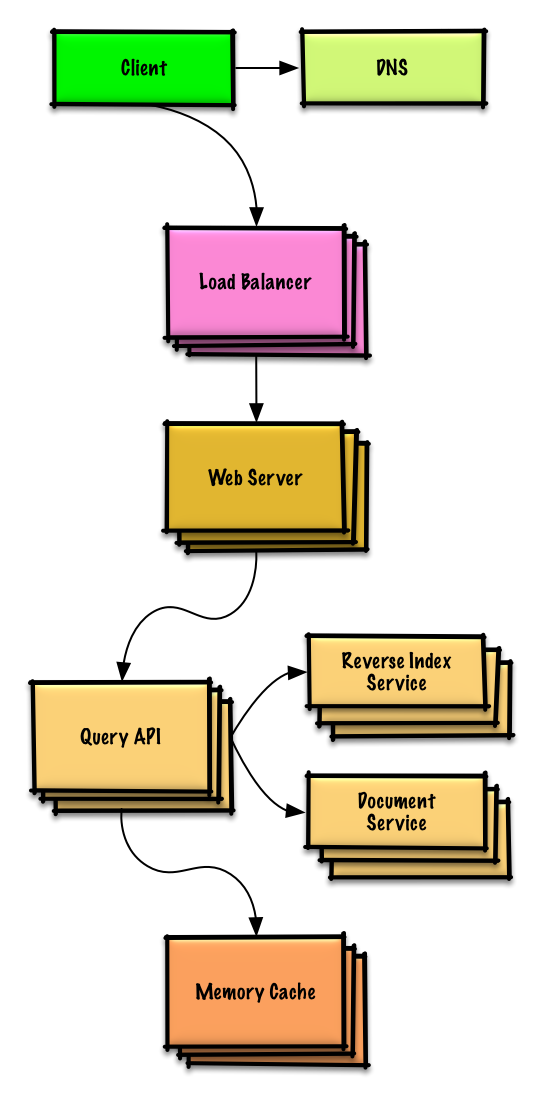
Ver exercício e solução
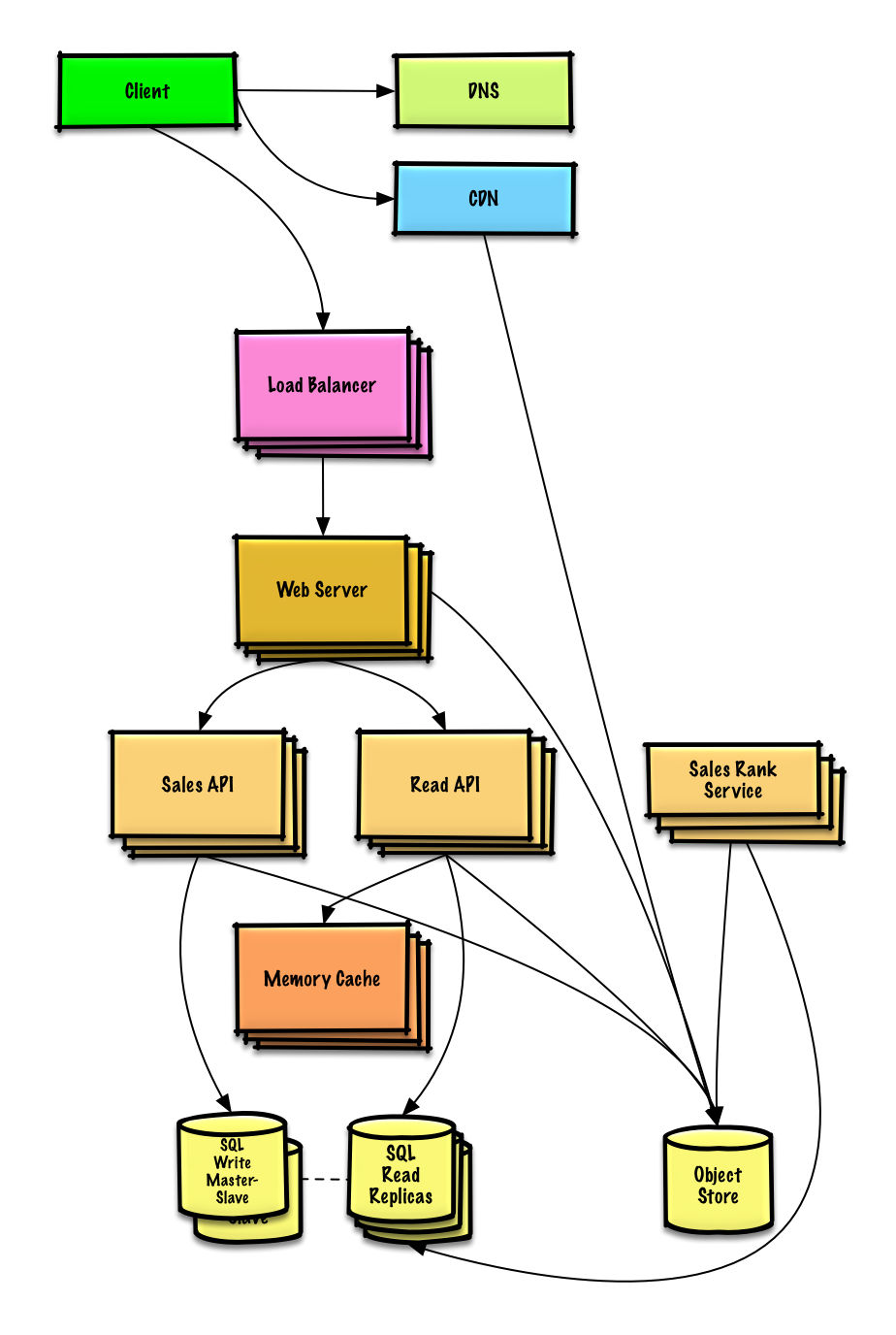
Ver exercício e solução
Perguntas comuns de entrevistas de design orientado a objetos com exemplos de discussões, códigos e diagramas.
Soluções vinculadas ao conteúdo da pasta
solutions/.
Nota: Esta seção está em desenvolvimento
| Pergunta | |
|---|---|
| Projete um mapa hash | Solução |
| Projete um cache usado menos recentemente | Solução |
| Projete uma central de atendimento | Solução |
| Projete um baralho de cartas | Solução |
| Projete um estacionamento | Solução |
| Projete um servidor de bate-papo | Solução |
| Projete uma matriz circular | Contribuir |
| Adicione uma pergunta de design orientado a objetos | Contribuir |
Novo no design de sistemas?
Primeiro, você precisará de uma compreensão básica dos princípios comuns, aprendendo o que são, como são usados e seus prós e contras.
Palestra sobre escalabilidade em Harvard
Escalabilidade
A seguir, veremos as compensações de alto nível:
Tenha em mente que tudo é uma troca .
Em seguida, nos aprofundaremos em tópicos mais específicos, como DNS, CDNs e balanceadores de carga.
Um serviço é escalável se resultar em aumento de desempenho de maneira proporcional aos recursos adicionados. Geralmente, aumentar o desempenho significa servir mais unidades de trabalho, mas também pode significar lidar com unidades de trabalho maiores, como quando os conjuntos de dados crescem. 1
Outra maneira de analisar desempenho versus escalabilidade:
Latência é o tempo para realizar alguma ação ou produzir algum resultado.
A taxa de transferência é o número de tais ações ou resultados por unidade de tempo.
Geralmente, você deve buscar o rendimento máximo com latência aceitável .
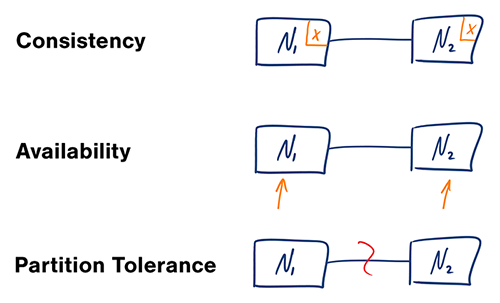
Fonte: teorema CAP revisitado
Em um sistema de computador distribuído, você só pode oferecer suporte a duas das seguintes garantias:
As redes não são confiáveis, então você precisará oferecer suporte à tolerância de partição. Você precisará fazer uma troca de software entre consistência e disponibilidade.
Aguardar uma resposta do nó particionado pode resultar em um erro de tempo limite. CP é uma boa escolha se suas necessidades de negócios exigirem leituras e gravações atômicas.
As respostas retornam a versão mais prontamente disponível dos dados disponíveis em qualquer nó, que pode não ser a mais recente. As gravações podem levar algum tempo para serem propagadas quando a partição for resolvida.
O AP é uma boa escolha se a empresa precisar permitir consistência eventual ou quando o sistema precisar continuar funcionando apesar de erros externos.
Com múltiplas cópias dos mesmos dados, nos deparamos com opções sobre como sincronizá-los para que os clientes tenham uma visão consistente dos dados. Lembre-se da definição de consistência do teorema CAP – cada leitura recebe a gravação mais recente ou um erro.
Depois de uma gravação, as leituras podem ou não vê-la. Uma abordagem de melhor esforço é adotada.
Essa abordagem é vista em sistemas como o memcached. A consistência fraca funciona bem em casos de uso em tempo real, como VoIP, chat de vídeo e jogos multijogador em tempo real. Por exemplo, se você estiver em uma ligação e perder a recepção por alguns segundos, ao recuperar a conexão você não ouvirá o que foi falado durante a perda de conexão.
Após uma gravação, as leituras acabarão por vê-la (normalmente em milissegundos). Os dados são replicados de forma assíncrona.
Essa abordagem é vista em sistemas como DNS e email. A consistência eventual funciona bem em sistemas altamente disponíveis.
Depois de escrever, os leitores verão. Os dados são replicados de forma síncrona.
Essa abordagem é vista em sistemas de arquivos e RDBMSes. A consistência forte funciona bem em sistemas que precisam de transações.
Existem dois padrões complementares para suportar alta disponibilidade: failover e replicação .
Com o failover ativo-passivo, as pulsações são enviadas entre o servidor ativo e o passivo em espera. Se a pulsação for interrompida, o servidor passivo assume o endereço IP do ativo e retoma o serviço.
A duração do tempo de inatividade é determinada pelo fato de o servidor passivo já estar em execução no modo de espera “quente” ou se precisar inicializar a partir do modo de espera “frio”. Somente o servidor ativo lida com o tráfego.
O failover ativo-passivo também pode ser chamado de failover mestre-escravo.
No ativo-ativo, ambos os servidores gerenciam o tráfego, distribuindo a carga entre eles.
Se os servidores forem voltados para o público, o DNS precisará saber sobre os IPs públicos de ambos os servidores. Se os servidores estiverem voltados para dentro, a lógica do aplicativo precisará conhecer ambos os servidores.
O failover ativo-ativo também pode ser chamado de failover mestre-mestre.
Este tópico é discutido mais detalhadamente na seção Banco de dados:
A disponibilidade é frequentemente quantificada pelo tempo de atividade (ou tempo de inatividade) como uma porcentagem do tempo em que o serviço está disponível. A disponibilidade é geralmente medida em número de 9s – um serviço com 99,99% de disponibilidade é descrito como tendo quatro 9s.
| Duração | Tempo de inatividade aceitável |
|---|---|
| Tempo de inatividade por ano | 8h 45min 57s |
| Tempo de inatividade por mês | 43m 49,7s |
| Tempo de inatividade por semana | 10m 4,8s |
| Tempo de inatividade por dia | 1m 26,4s |
| Duração | Tempo de inatividade aceitável |
|---|---|
| Tempo de inatividade por ano | 52min 35,7s |
| Tempo de inatividade por mês | 4m 23s |
| Tempo de inatividade por semana | 1m 5s |
| Tempo de inatividade por dia | 8,6s |
Se um serviço consistir em vários componentes propensos a falhas, a disponibilidade geral do serviço dependerá de os componentes estarem em sequência ou em paralelo.
A disponibilidade geral diminui quando dois componentes com disponibilidade < 100% estão em sequência:
Availability (Total) = Availability (Foo) * Availability (Bar)
Se Foo e Bar tivessem 99,9% de disponibilidade cada, sua disponibilidade total na sequência seria de 99,8%.
A disponibilidade geral aumenta quando dois componentes com disponibilidade < 100% estão em paralelo:
Availability (Total) = 1 - (1 - Availability (Foo)) * (1 - Availability (Bar))
Se Foo e Bar tivessem 99,9% de disponibilidade cada, sua disponibilidade total em paralelo seria de 99,9999%.
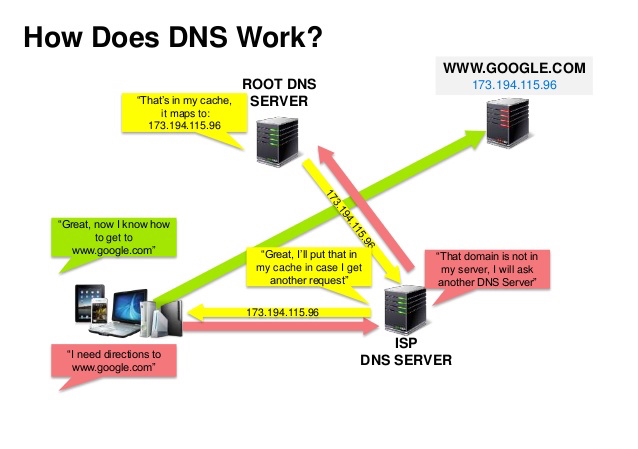
Fonte: apresentação de segurança DNS
Um Sistema de Nomes de Domínio (DNS) traduz um nome de domínio como www.example.com em um endereço IP.
O DNS é hierárquico, com alguns servidores autorizados no nível superior. Seu roteador ou ISP fornece informações sobre quais servidores DNS contatar ao fazer uma pesquisa. Mapeamentos de cache de servidores DNS de nível inferior, que podem ficar obsoletos devido a atrasos na propagação do DNS. Os resultados de DNS também podem ser armazenados em cache pelo seu navegador ou sistema operacional por um determinado período de tempo, determinado pelo tempo de vida (TTL).
CNAME (example.com para www.example.com) ou para um registro AServiços como CloudFlare e Route 53 fornecem serviços DNS gerenciados. Alguns serviços DNS podem rotear o tráfego através de vários métodos:
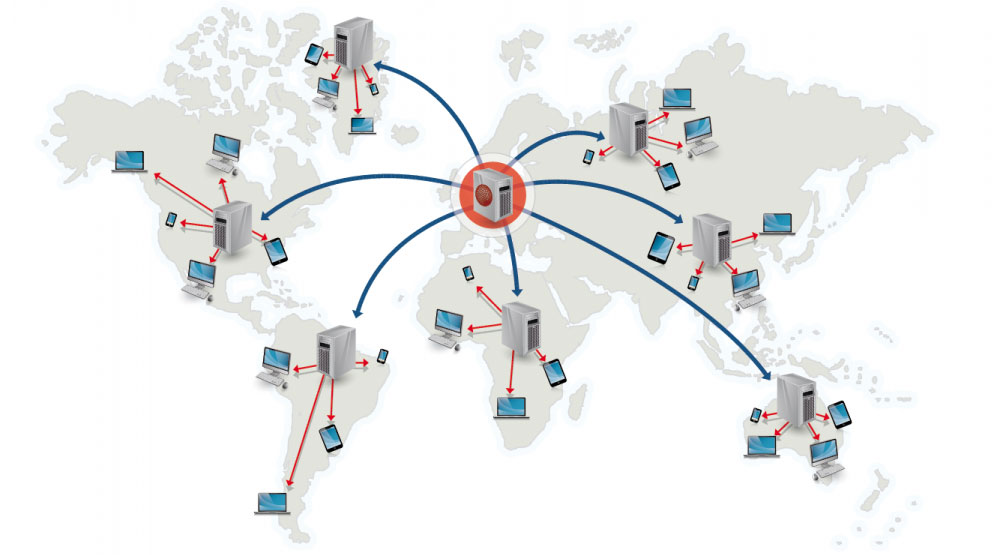
Fonte: Por que usar um CDN
Uma rede de entrega de conteúdo (CDN) é uma rede distribuída globalmente de servidores proxy, servindo conteúdo de locais mais próximos do usuário. Geralmente, arquivos estáticos como HTML/CSS/JS, fotos e vídeos são servidos a partir de CDN, embora alguns CDNs, como o CloudFront da Amazon, suportem conteúdo dinâmico. A resolução DNS do site informará aos clientes qual servidor contatar.
Servir conteúdo de CDNs pode melhorar significativamente o desempenho de duas maneiras:
Push CDNs recebem novo conteúdo sempre que ocorrem alterações em seu servidor. Você assume total responsabilidade por fornecer conteúdo, fazer upload diretamente para o CDN e reescrever URLs para apontar para o CDN. Você pode configurar quando o conteúdo expira e quando é atualizado. O conteúdo é carregado apenas quando é novo ou alterado, minimizando o tráfego, mas maximizando o armazenamento.
Sites com uma pequena quantidade de tráfego ou sites com conteúdo que não é atualizado com frequência funcionam bem com CDNs push. O conteúdo é colocado nas CDNs uma vez, em vez de ser extraído novamente em intervalos regulares.
Pull CDNs capturam novo conteúdo do seu servidor quando o primeiro usuário solicita o conteúdo. Você deixa o conteúdo em seu servidor e reescreve os URLs para apontar para o CDN. Isso resulta em uma solicitação mais lenta até que o conteúdo seja armazenado em cache na CDN.
Um tempo de vida (TTL) determina por quanto tempo o conteúdo é armazenado em cache. Os CDNs pull minimizam o espaço de armazenamento no CDN, mas podem criar tráfego redundante se os arquivos expirarem e forem extraídos antes de serem realmente alterados.
Sites com tráfego intenso funcionam bem com CDNs pull, pois o tráfego é distribuído de maneira mais uniforme, permanecendo apenas o conteúdo solicitado recentemente no CDN.
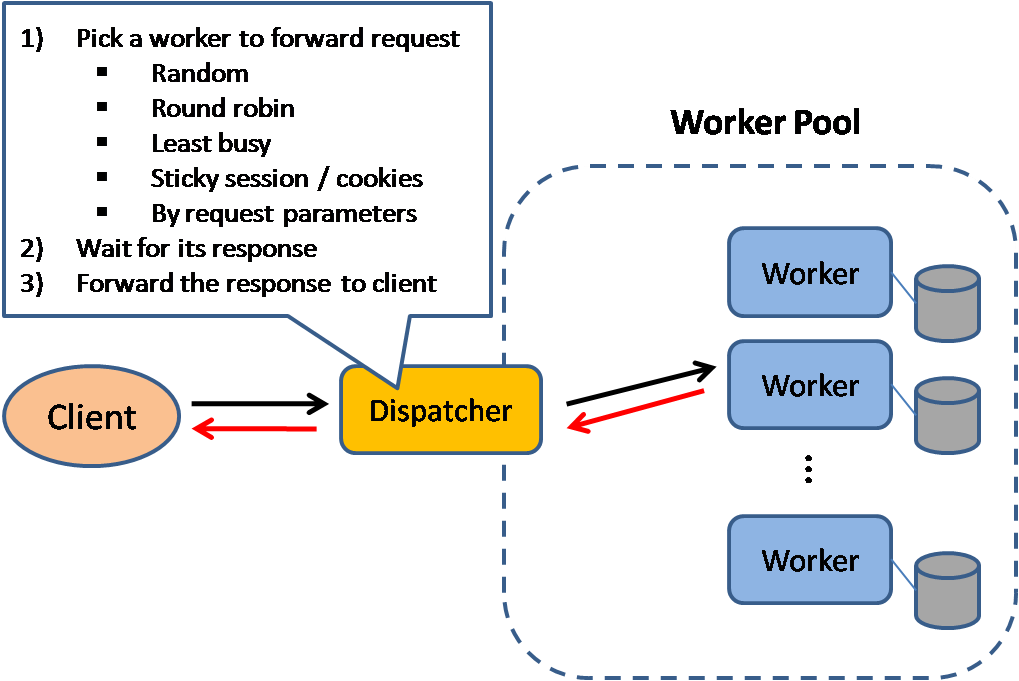
Fonte: Padrões de design de sistema escaláveis
Os balanceadores de carga distribuem solicitações recebidas de clientes para recursos de computação, como servidores de aplicativos e bancos de dados. Em cada caso, o balanceador de carga retorna a resposta do recurso de computação para o cliente apropriado. Os balanceadores de carga são eficazes em:
Os balanceadores de carga podem ser implementados com hardware (caro) ou com software como HAProxy.
Os benefícios adicionais incluem:
Para se proteger contra falhas, é comum configurar vários balanceadores de carga, seja no modo ativo-passivo ou ativo-ativo.
Os balanceadores de carga podem rotear o tráfego com base em várias métricas, incluindo:
Os balanceadores de carga da camada 4 analisam as informações da camada de transporte para decidir como distribuir as solicitações. Geralmente, isso envolve os endereços IP de origem e de destino e as portas no cabeçalho, mas não o conteúdo do pacote. Os balanceadores de carga da Camada 4 encaminham pacotes de rede de e para o servidor upstream, realizando Network Address Translation (NAT).
Os balanceadores de carga da camada 7 analisam a camada de aplicação para decidir como distribuir as solicitações. Isso pode envolver o conteúdo do cabeçalho, da mensagem e dos cookies. Os balanceadores de carga da Camada 7 encerram o tráfego de rede, lêem a mensagem, tomam uma decisão de balanceamento de carga e, em seguida, abrem uma conexão com o servidor selecionado. Por exemplo, um balanceador de carga de camada 7 pode direcionar o tráfego de vídeo para servidores que hospedam vídeos, ao mesmo tempo que direciona o tráfego de faturamento de usuários mais sensível para servidores com segurança reforçada.
Ao custo da flexibilidade, o balanceamento de carga da camada 4 requer menos tempo e recursos de computação do que a camada 7, embora o impacto no desempenho possa ser mínimo em hardware comum moderno.
Os balanceadores de carga também podem ajudar no dimensionamento horizontal, melhorando o desempenho e a disponibilidade. A expansão usando máquinas comuns é mais econômica e resulta em maior disponibilidade do que a expansão de um único servidor em hardware mais caro, chamada Escala Vertical . Também é mais fácil contratar talentos que trabalham em hardware comum do que em sistemas empresariais especializados.
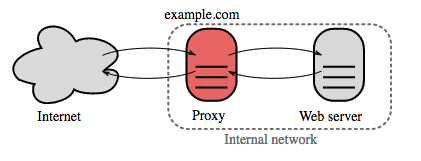
Fonte: Wikipédia
Um proxy reverso é um servidor web que centraliza serviços internos e fornece interfaces unificadas ao público. As solicitações dos clientes são encaminhadas para um servidor que pode atendê-las antes que o proxy reverso retorne a resposta do servidor ao cliente.
Os benefícios adicionais incluem:
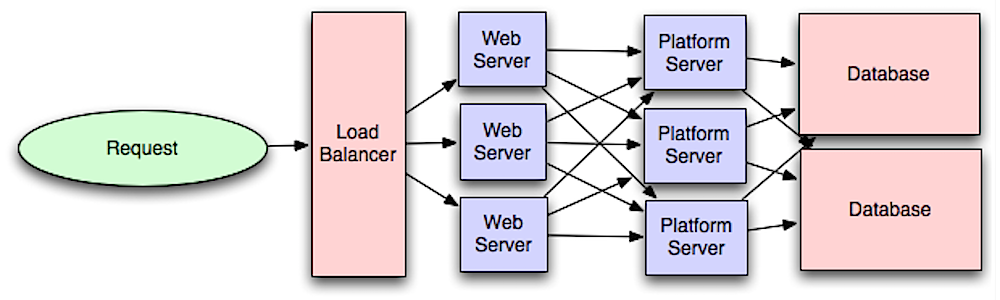
Fonte: Introdução à arquitetura de sistemas em escala
Separar a camada web da camada de aplicação (também conhecida como camada de plataforma) permite dimensionar e configurar ambas as camadas de forma independente. Adicionar uma nova API resulta na adição de servidores de aplicativos sem necessariamente adicionar servidores web adicionais. O princípio da responsabilidade única defende serviços pequenos e autónomos que trabalham em conjunto. Equipes pequenas com serviços pequenos podem planejar de forma mais agressiva para um crescimento rápido.
Os trabalhadores na camada de aplicação também ajudam a permitir o assincronismo.
Relacionados a esta discussão estão os microsserviços, que podem ser descritos como um conjunto de serviços pequenos e modulares, implementáveis de forma independente. Cada serviço executa um processo exclusivo e se comunica por meio de um mecanismo leve e bem definido para atender a uma meta de negócios. 1
O Pinterest, por exemplo, poderia ter os seguintes microsserviços: perfil de usuário, seguidor, feed, pesquisa, upload de fotos, etc.
Sistemas como Consul, Etcd e Zookeeper podem ajudar os serviços a se encontrarem, monitorando nomes, endereços e portas registrados. As verificações de integridade ajudam a verificar a integridade do serviço e geralmente são feitas usando um terminal HTTP. Tanto o Consul quanto o Etcd possuem um armazenamento de chave-valor integrado que pode ser útil para armazenar valores de configuração e outros dados compartilhados.
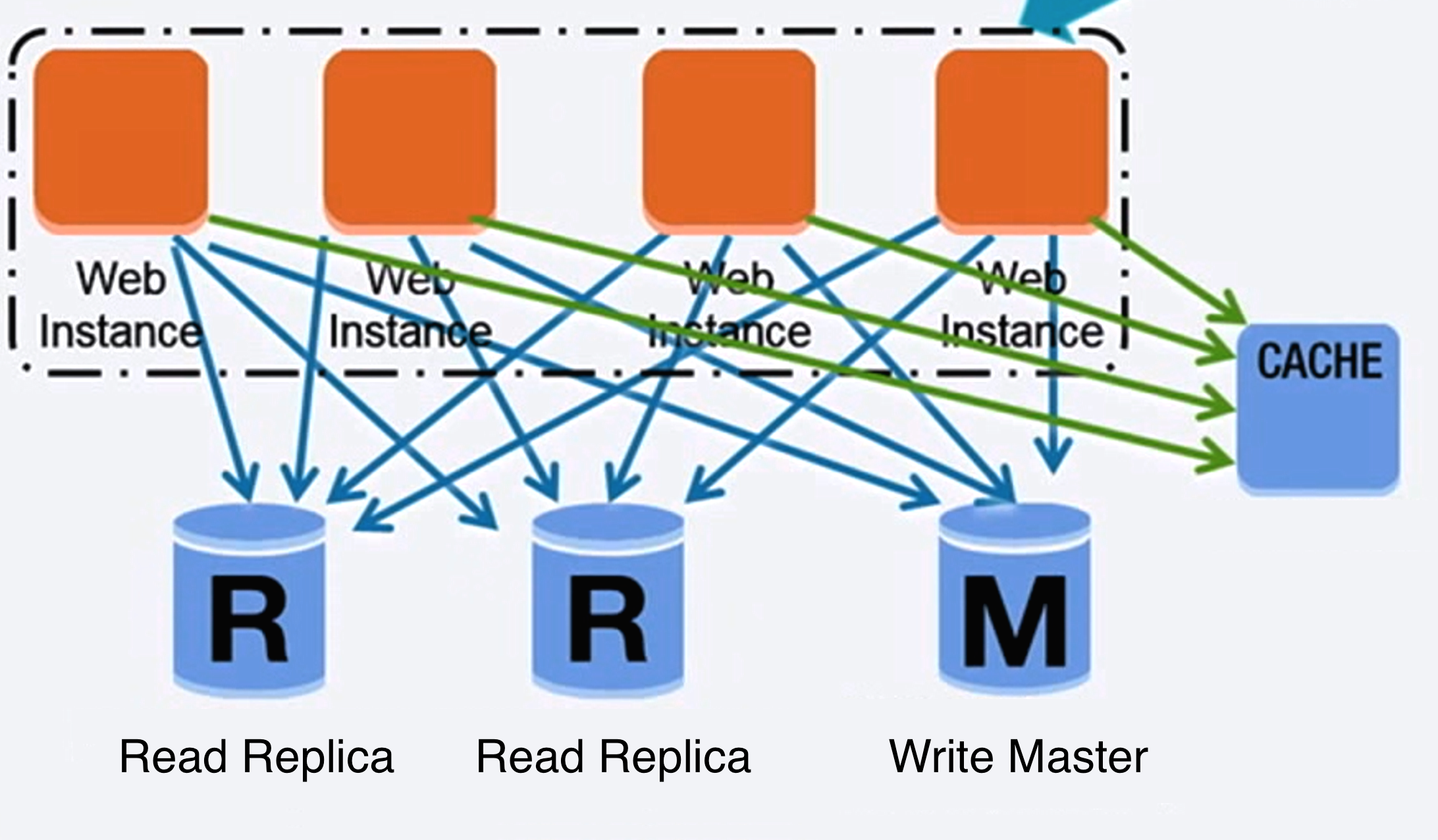
Fonte: Ampliando para seus primeiros 10 milhões de usuários
Um banco de dados relacional como SQL é uma coleção de itens de dados organizados em tabelas.
ACID é um conjunto de propriedades de transações de banco de dados relacional.
Existem muitas técnicas para escalar um banco de dados relacional: replicação mestre-escravo , replicação mestre-mestre , federação , fragmentação , desnormalização e ajuste de SQL .
O mestre serve leituras e escritas, replicando escritas para um ou mais escravos, que servem apenas leituras. Os escravos também podem replicar para escravos adicionais em forma de árvore. Se o mestre ficar off-line, o sistema poderá continuar a operar no modo somente leitura até que um escravo seja promovido a mestre ou um novo mestre seja provisionado.
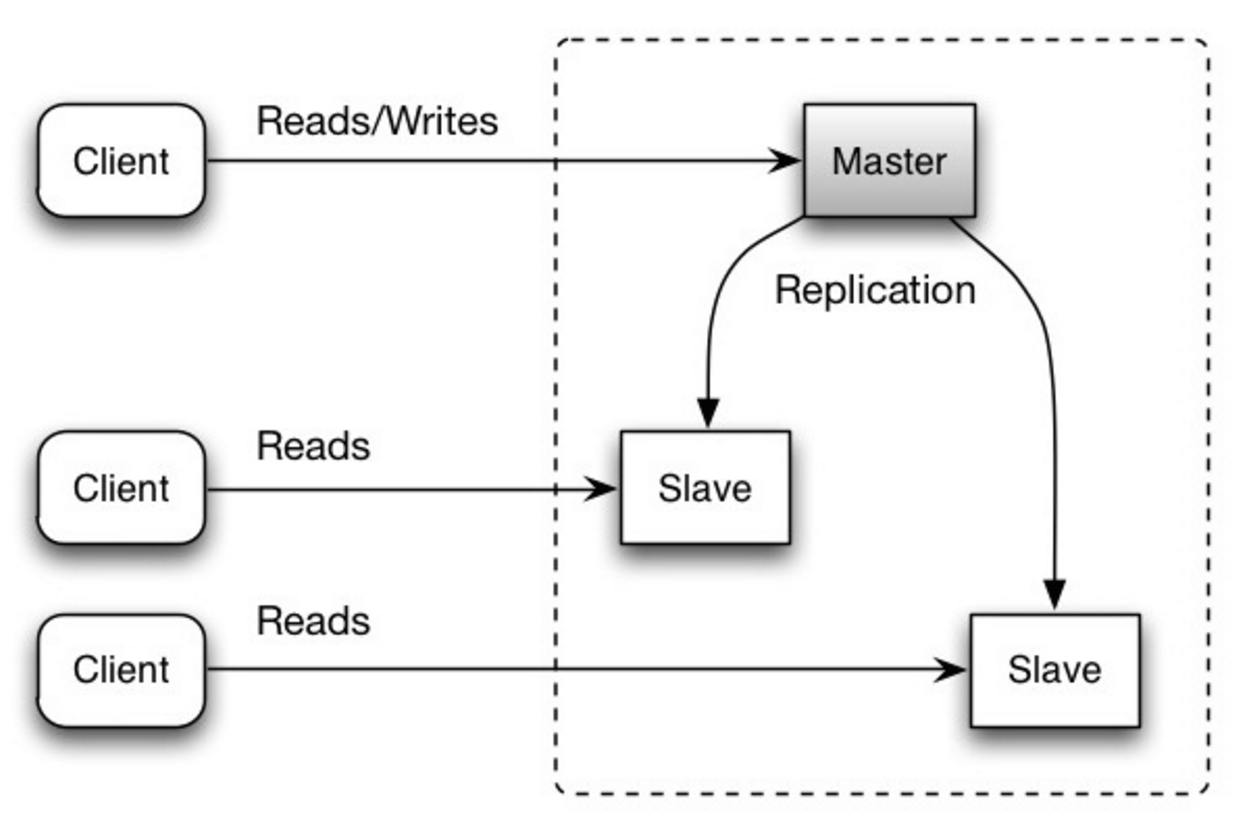
Fonte: Escalabilidade, disponibilidade, estabilidade, padrões
Ambos os mestres atendem leituras e gravações e coordenam entre si nas gravações. Se um dos mestres falhar, o sistema poderá continuar a operar com leituras e gravações.
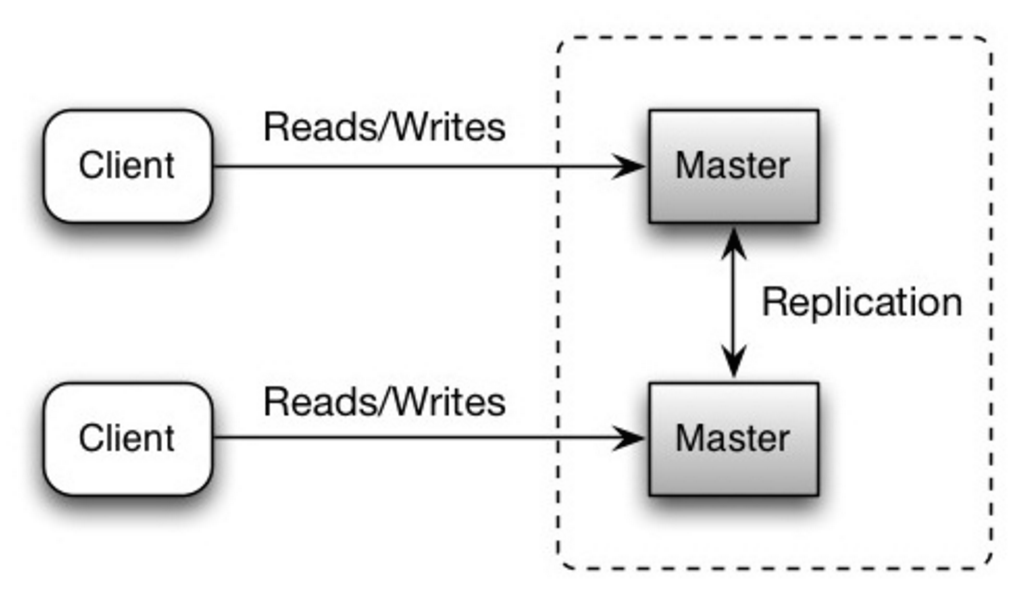
Fonte: Escalabilidade, disponibilidade, estabilidade, padrões
Fonte: Ampliando para seus primeiros 10 milhões de usuários
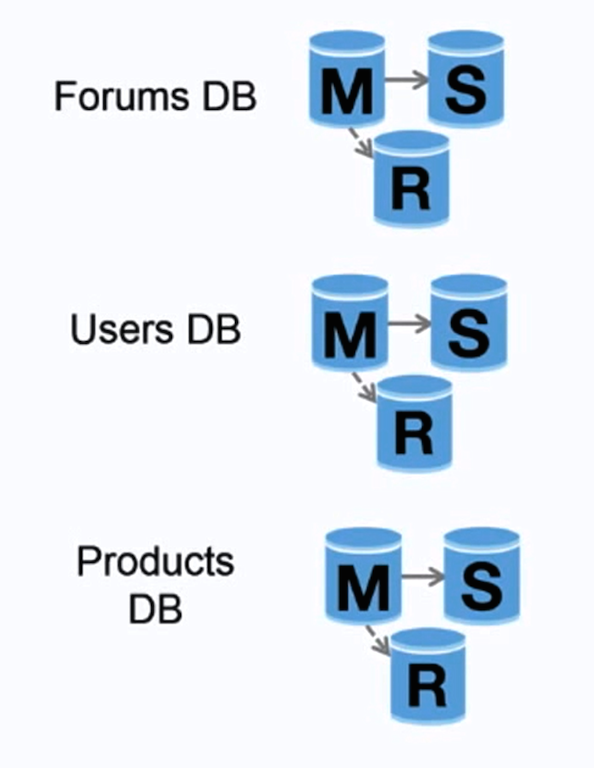
A federação (ou particionamento funcional) divide os bancos de dados por função. Por exemplo, em vez de um único banco de dados monolítico, você poderia ter três bancos de dados: forums , users e products , resultando em menos tráfego de leitura e gravação para cada banco de dados e, portanto, menos atraso de replicação. Bancos de dados menores resultam em mais dados que cabem na memória, o que, por sua vez, resulta em mais acessos ao cache devido à melhoria da localização do cache. Sem um único mestre central serializando gravações, você pode escrever em paralelo, aumentando o rendimento.
Fonte: Escalabilidade, disponibilidade, estabilidade, padrões
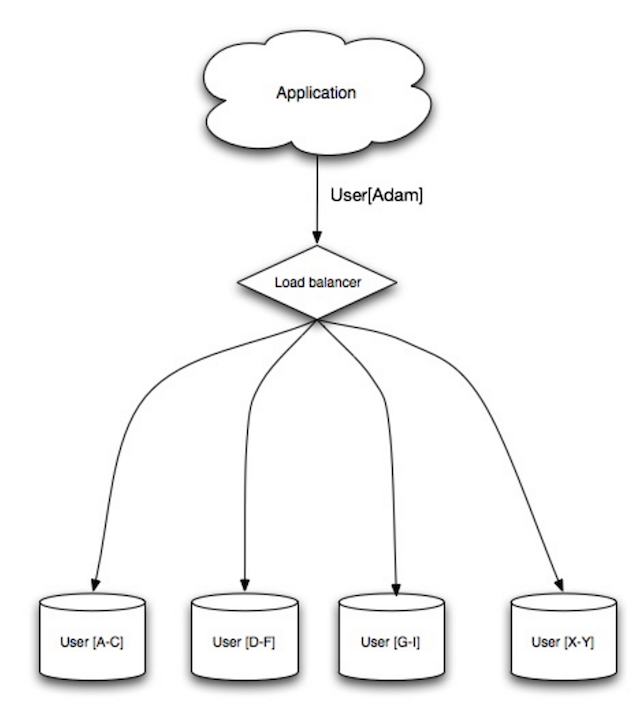
A fragmentação distribui dados entre diferentes bancos de dados, de modo que cada banco de dados possa gerenciar apenas um subconjunto de dados. Tomando como exemplo um banco de dados de usuários, à medida que o número de usuários aumenta, mais fragmentos são adicionados ao cluster.
Semelhante às vantagens da federação, a fragmentação resulta em menos tráfego de leitura e gravação, menos replicação e mais acessos ao cache. O tamanho do índice também é reduzido, o que geralmente melhora o desempenho com consultas mais rápidas. Se um fragmento falhar, os outros fragmentos ainda estarão operacionais, embora você queira adicionar alguma forma de replicação para evitar perda de dados. Assim como a federação, não há um único mestre central serializando gravações, permitindo que você escreva em paralelo com maior rendimento.
Maneiras comuns de fragmentar uma tabela de usuários são por meio da inicial do sobrenome do usuário ou da localização geográfica do usuário.
A desnormalização tenta melhorar o desempenho da leitura às custas de algum desempenho de gravação. Cópias redundantes dos dados são escritas em várias tabelas para evitar junções caras. Alguns RDBMs, como PostgreSQL e Oracle Suport, vistas materializadas que lidam com o trabalho de armazenar informações redundantes e manter cópias redundantes consistentes.
Uma vez que os dados são distribuídos com técnicas como federação e sharding, o gerenciamento de junções entre data centers aumenta ainda mais a complexidade. A desnormalização pode contornar a necessidade de junções tão complexas.
Na maioria dos sistemas, as leituras podem ser fortemente superadas, grava 100: 1 ou até 1000: 1. Uma leitura resultando em uma junção complexa de banco de dados pode ser muito cara, gastando uma quantidade significativa de tempo nas operações de disco.
O ajuste do SQL é um tópico amplo e muitos livros foram escritos como referência.
É importante comparar e perfil para simular e descobrir gargalos.
O benchmarking e o perfil podem apontar para as seguintes otimizações.
CHAR em vez de VARCHAR para campos de comprimento fixo.CHAR permite efetivamente acesso rápido e aleatório, enquanto que com VARCHAR , você deve encontrar o final de uma string antes de passar para o próximo.TEXT para grandes blocos de texto, como postagens de blog. TEXT também permite pesquisas booleanas. O uso de um campo TEXT resulta no armazenamento de um ponteiro no disco usado para localizar o bloco de texto.INT para números maiores de até 2^32 ou 4 bilhões.DECIMAL para moeda para evitar erros de representação de pontos flutuantes.BLOBS grandes, armazene a localização de onde obter o objeto.VARCHAR(255) é o maior número de caracteres que podem ser contados em um número de 8 bits, maximizando o uso de um byte em alguns RDBMs.NOT NULL , quando aplicável para melhorar o desempenho da pesquisa. SELECT , GROUP BY , ORDER BY , JOIN ) podem ser mais rápidas com os índices.O NOSQL é uma coleção de itens de dados representados em um armazenamento de valor-chave , armazenamento de documentos , armazenamento de colunas amplo ou um banco de dados de gráfico . Os dados são desnormalizados e as junções geralmente são feitas no código do aplicativo. A maioria das lojas NoSQL não possui transações com ácido verdadeiras e favorece a consistência eventual.
A base é frequentemente usada para descrever as propriedades dos bancos de dados NoSQL. Em comparação com o teorema do CAP, a base escolhe a disponibilidade em vez da consistência.
Além de escolher entre SQL ou NOSQL, é útil entender qual tipo de banco de dados NoSQL se encaixa melhor nos seus casos de uso. Analisaremos lojas de valor-chave , lojas de documentos , lojas de colunas amplas e bancos de dados de gráficos na próxima seção.
Abstração: tabela de hash
Uma loja de valores-chave geralmente permite ler e gravar o (1) e geralmente é apoiado por memória ou SSD. Os armazenamentos de dados podem manter as chaves na ordem lexicográfica, permitindo uma recuperação eficiente dos principais intervalos. As lojas de valor-chave podem permitir o armazenamento de metadados com um valor.
As lojas de valor-chave fornecem alto desempenho e são frequentemente usadas para modelos de dados simples ou para dados em rápida mudança, como uma camada de cache na memória. Como eles oferecem apenas um conjunto limitado de operações, a complexidade é deslocada para a camada de aplicação se forem necessárias operações adicionais.
Uma loja de valores-chave é a base para sistemas mais complexos, como um armazenamento de documentos e, em alguns casos, um banco de dados de gráficos.
Abstração: armazenamento de valor-chave com documentos armazenados como valores
Uma loja de documentos está centrada em documentos (XML, JSON, Binário, etc.), onde um documento armazena todas as informações para um determinado objeto. As lojas de documentos fornecem APIs ou um idioma de consulta para consultar com base na estrutura interna do próprio documento. Observe que muitas lojas de valor-chave incluem recursos para trabalhar com os metadados de um valor, embaçando as linhas entre esses dois tipos de armazenamento.
Com base na implementação subjacente, os documentos são organizados por coleções, tags, metadados ou diretórios. Embora os documentos possam ser organizados ou agrupados, os documentos podem ter campos completamente diferentes um do outro.
Algumas lojas de documentos como MongoDB e CouchDB também fornecem uma linguagem do tipo SQL para executar consultas complexas. O DynamoDB suporta valores-chave e documentos.
As lojas de documentos oferecem alta flexibilidade e são frequentemente usadas para trabalhar com os dados ocasionalmente.
Fonte: SQL & Nosql, uma breve história
Abstração: mapa aninhado
ColumnFamily<RowKey, Columns<ColKey, Value, Timestamp>>
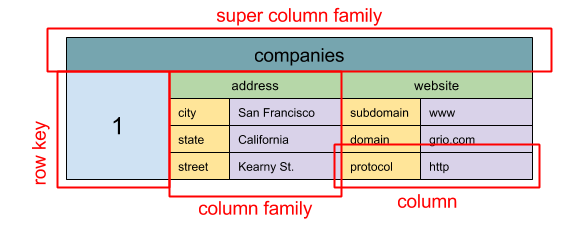
A unidade básica de dados de uma loja de colunas ampla é uma coluna (name/value par). Uma coluna pode ser agrupada em famílias de colunas (análoga a uma tabela SQL). Famílias de super colunas adicionais famílias de colunas em grupo. Você pode acessar cada coluna de forma independente com uma chave de linha e colunas com a mesma tecla de linha uma linha. Cada valor contém um registro de data e hora para a versão e a resolução de conflitos.
O Google introduziu a BigTable como a primeira loja de colunas ampla, que influenciou o HBase de código aberto, muitas vezes usado no ecossistema Hadoop, e Cassandra do Facebook. Lojas como BigTable, HBase e Cassandra mantêm as chaves em ordem lexicográfica, permitindo uma recuperação eficiente de faixas de chave seletivas.
As lojas de colunas amplas oferecem alta disponibilidade e alta escalabilidade. Eles são frequentemente usados para conjuntos de dados muito grandes.
Fonte: Banco de dados de gráfico
Abstração: gráfico
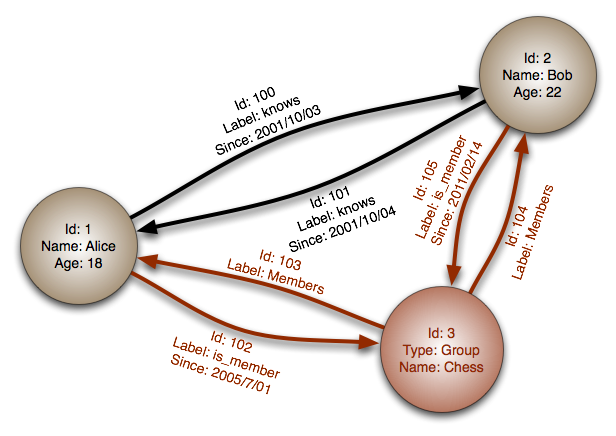
Em um banco de dados de gráficos, cada nó é um registro e cada arco é uma relação entre dois nós. Os bancos de dados de gráficos são otimizados para representar relacionamentos complexos com muitas chaves estrangeiras ou relacionamentos muitos para muitos.
Os bancos de dados de gráficos oferecem alto desempenho para modelos de dados com relacionamentos complexos, como uma rede social. Eles são relativamente novos e ainda não são amplamente utilizados; Pode ser mais difícil encontrar ferramentas e recursos de desenvolvimento. Muitos gráficos só podem ser acessados com APIs REST.
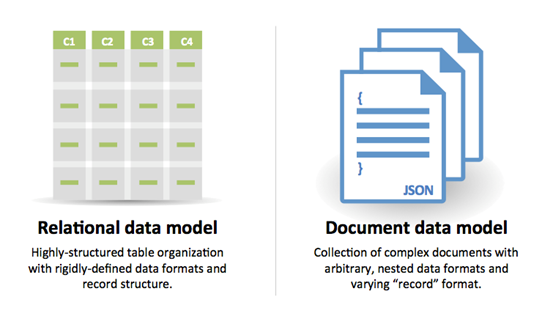
Fonte: Fazendo a transição de RDBMS para NoSQL
Razões para SQL :
Razões para NoSQL :
Dados de amostra bem adequados para NoSQL:
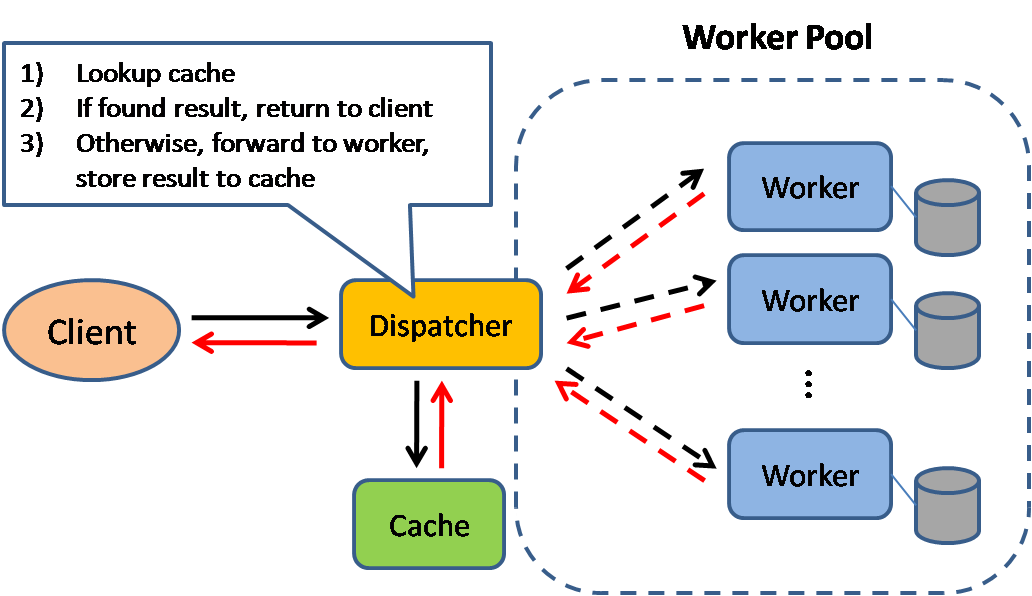
Fonte: Padrões de design de sistema escaláveis
O cache melhora os tempos de carregamento da página e pode reduzir a carga em seus servidores e bancos de dados. Neste modelo, o despachante primeiro procurará se a solicitação já foi feita antes e tentar encontrar o resultado anterior para retornar, a fim de salvar a execução real.
Os bancos de dados geralmente se beneficiam de uma distribuição uniforme de leituras e gravações em suas partições. Os itens populares podem distribuir a distribuição, causando gargalos. Colocar um cache na frente de um banco de dados pode ajudar a absorver cargas e picos desiguais no tráfego.
Os caches podem estar localizados no lado do cliente (OS ou navegador), lado do servidor ou em uma camada de cache distinta.
CDNs são considerados um tipo de cache.
Proxies e caches reversos, como o verniz, podem servir diretamente e conteúdo estático e dinâmico. Os servidores da Web também podem cache solicitações, retornando respostas sem precisar entrar em contato com servidores de aplicativos.
Seu banco de dados geralmente inclui algum nível de armazenamento em cache em uma configuração padrão, otimizada para um caso de uso genérico. Ajustar essas configurações para padrões de uso específicos podem aumentar ainda mais o desempenho.
Os caches na memória, como Memcached e Redis, são lojas de valor-chave entre seu aplicativo e seu armazenamento de dados. Como os dados são mantidos na RAM, é muito mais rápido que os bancos de dados típicos em que os dados são armazenados no disco. A RAM é mais limitada que o disco, portanto, os algoritmos de invalidação do cache, como menos usados recentemente (LRU), podem ajudar a invalidar as entradas 'frio' e manter os dados 'quentes' na RAM.
Redis tem os seguintes recursos adicionais:
Existem vários níveis que você pode cache que se enquadra em duas categorias gerais: consultas e objetos de banco de dados:
Geralmente, você deve tentar evitar o cache baseado em arquivos, pois dificulta a clonagem e a escala automática.
Sempre que você consultar o banco de dados, hash a consulta como chave e armazena o resultado no cache. Esta abordagem sofre de problemas de expiração:
Veja seus dados como um objeto, semelhante ao que você faz com o código do seu aplicativo. Peça ao seu aplicativo montar o conjunto de dados do banco de dados em uma instância de classe ou em uma (s) estrutura (s) de dados:
Sugestões do que cache:
Como você só pode armazenar uma quantidade limitada de dados em cache, você precisará determinar qual estratégia de atualização do cache funciona melhor para o seu caso de uso.
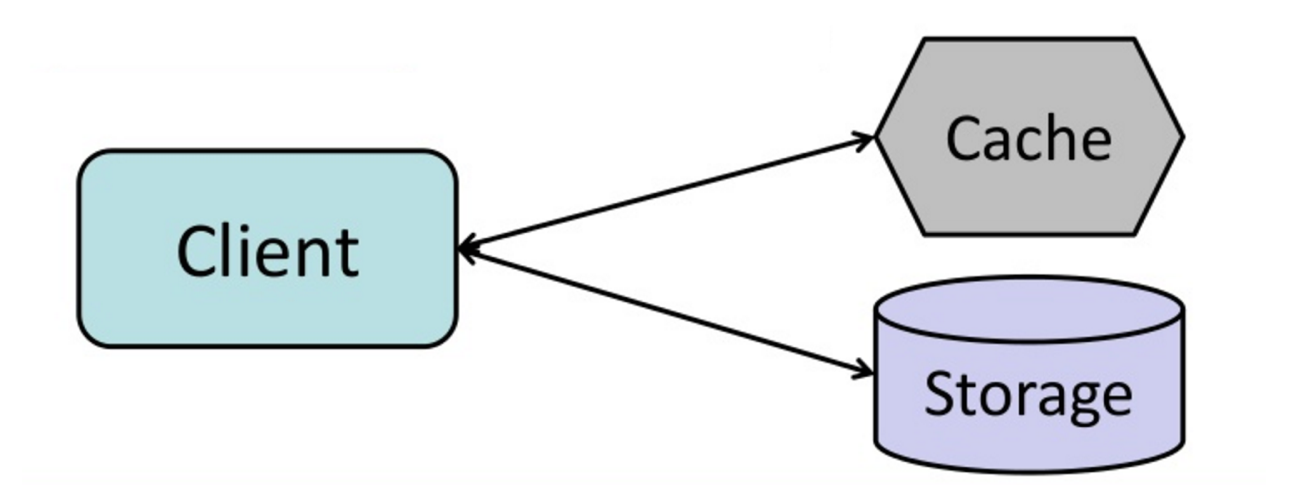
Fonte: do cache à grade de dados na memória
O aplicativo é responsável por ler e escrever a partir do armazenamento. O cache não interage diretamente com o armazenamento. O aplicativo faz o seguinte:
def get_user ( self , user_id ):
user = cache . get ( "user.{0}" , user_id )
if user is None :
user = db . query ( "SELECT * FROM users WHERE user_id = {0}" , user_id )
if user is not None :
key = "user.{0}" . format ( user_id )
cache . set ( key , json . dumps ( user ))
return userO memcached é geralmente usado dessa maneira.
As leituras subsequentes dos dados adicionadas ao cache são rápidas. O cache-aside também é chamado de carregamento preguiçoso. Somente dados solicitados são armazenados em cache, o que evita preencher o cache com dados que não são solicitados.
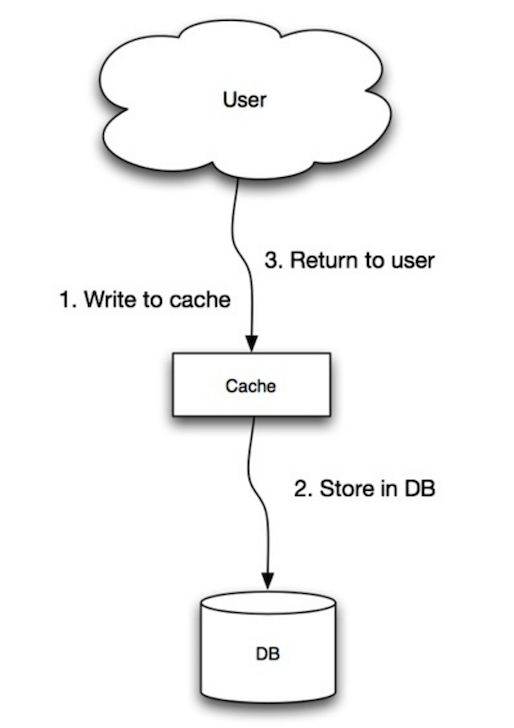
Fonte: escalabilidade, disponibilidade, estabilidade, padrões
O aplicativo usa o cache como o principal armazenamento de dados, lendo e escrevendo dados, enquanto o cache é responsável por ler e escrever no banco de dados:
Código do aplicativo:
set_user ( 12345 , { "foo" : "bar" })Código de cache:
def set_user ( user_id , values ):
user = db . query ( "UPDATE Users WHERE id = {0}" , user_id , values )
cache . set ( user_id , user )A gravação é uma operação geral lenta devido à operação de gravação, mas as leituras subsequentes de dados apenas escritos são rápidos. Os usuários geralmente são mais tolerantes à latência ao atualizar dados do que a leitura de dados. Os dados no cache não são obsoletos.
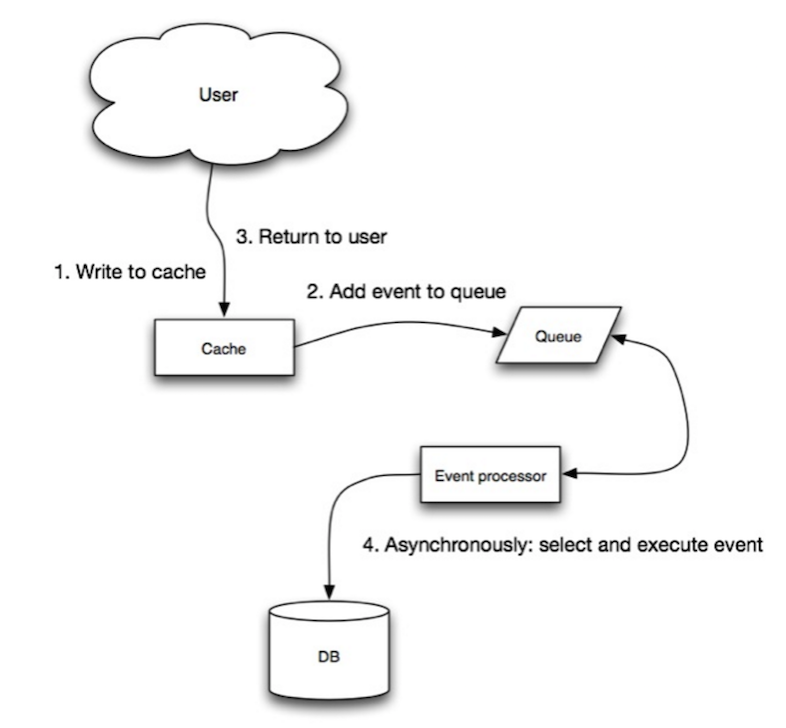
Fonte: escalabilidade, disponibilidade, estabilidade, padrões
Em Write-Behind, o aplicativo faz o seguinte:
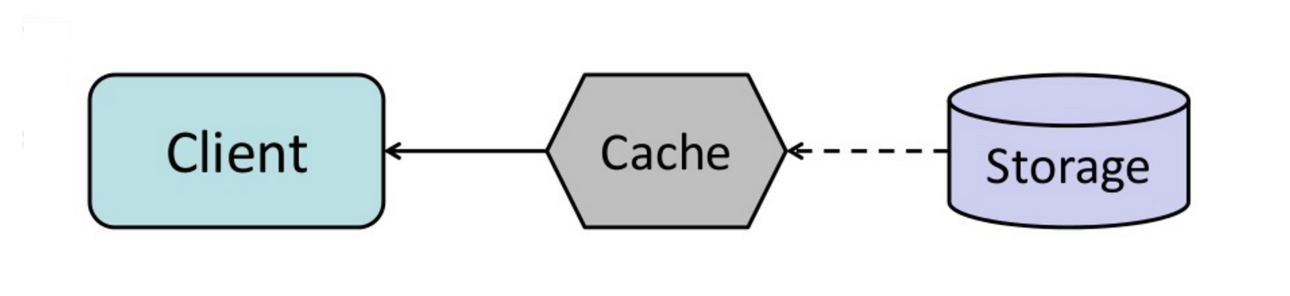
Fonte: do cache à grade de dados na memória
Você pode configurar o cache para atualizar automaticamente qualquer entrada de cache acessada recentemente antes de sua expiração.
O Aéu de Refresh pode resultar em latência reduzida versus leitura se o cache puder prever com precisão quais itens provavelmente serão necessários no futuro.
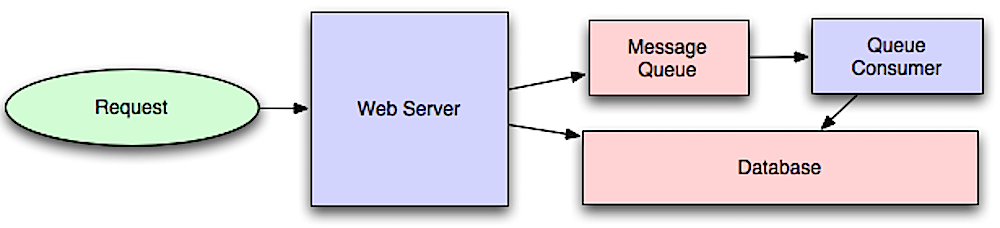
Fonte: Introdução a sistemas de arquitetura para escala
Os fluxos de trabalho assíncronos ajudam a reduzir os tempos de solicitação para operações caras que, de outra forma, seriam executadas em linha. Eles também podem ajudar a fazer trabalhos demorados com antecedência, como a agregação periódica de dados.
As filas de mensagens recebem, seguram e entregam mensagens. Se uma operação for muito lenta para executar em linha, você poderá usar uma fila de mensagens com o seguinte fluxo de trabalho:
O usuário não está bloqueado e o trabalho é processado em segundo plano. Durante esse período, o cliente pode opcionalmente fazer uma pequena quantidade de processamento para fazer parecer que a tarefa foi concluída. Por exemplo, se postar um tweet, o tweet poderá ser publicado instantaneamente na sua linha do tempo, mas isso pode levar algum tempo antes que seu tweet seja realmente entregue a todos os seus seguidores.
Redis é útil como um corretor de mensagens simples, mas as mensagens podem ser perdidas.
O RabbitMQ é popular, mas exige que você se adapte ao protocolo 'AMQP' e gerencie seus próprios nós.
O Amazon SQS está hospedado, mas pode ter alta latência e tem a possibilidade de as mensagens serem entregues duas vezes.
As tarefas de tarefas recebem tarefas e seus dados relacionados, as executa e fornece seus resultados. Eles podem suportar programação e podem ser usados para executar trabalhos intensivos em computação em segundo plano.
A aipo tem suporte para agendamento e principalmente possui suporte ao Python.
Se as filas começarem a crescer significativamente, o tamanho da fila pode se tornar maior que a memória, resultando em erros de cache, leituras de disco e desempenho ainda mais lento. A pressão das costas pode ajudar a limitar o tamanho da fila, mantendo assim uma alta taxa de transferência e bons tempos de resposta para trabalhos já na fila. Depois que a fila preenche, os clientes ficam ocupados ou o código de status HTTP 503 para tentar novamente mais tarde. Os clientes podem tentar novamente a solicitação posteriormente, talvez com o retorno exponencial.
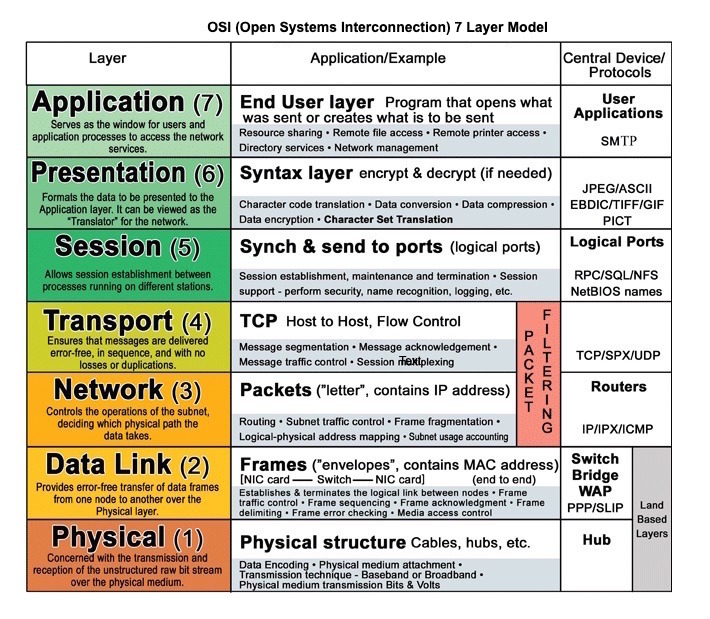
Fonte: OSI 7 Camada Modelo
O HTTP é um método para codificar e transportar dados entre um cliente e um servidor. É um protocolo de solicitação/resposta: os clientes emitem solicitações e servidores que emitem respostas com conteúdo relevante e informações sobre status de conclusão sobre a solicitação. O HTTP é independente, permitindo que solicitações e respostas fluam através de muitos roteadores e servidores intermediários que executam balanceamento de carga, cache, criptografia e compactação.
Uma solicitação HTTP básica consiste em um verbo (método) e um recurso (endpoint). Abaixo estão os verbos HTTP comuns:
| Verbo | Descrição | Idempotente* | Seguro | Armazenável em cache |
|---|---|---|---|---|
| PEGAR | Lê um recurso | Sim | Sim | Sim |
| PUBLICAR | Cria um recurso ou acionar um processo que lida com dados | Não | Não | Sim se a resposta contém informações de frescura |
| COLOCAR | Cria ou substitua um recurso | Sim | Não | Não |
| CORREÇÃO | Atualiza parcialmente um recurso | Não | Não | Sim se a resposta contém informações de frescura |
| EXCLUIR | Exclui um recurso | Sim | Não | Não |
*Pode ser chamado muitas vezes sem resultados diferentes.
HTTP é um protocolo de camada de aplicação que confia em protocolos de nível inferior, como TCP e UDP .
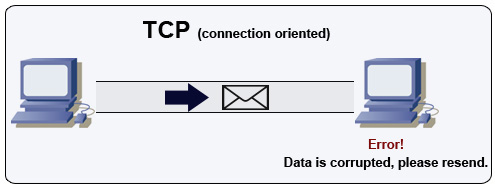
Fonte: como fazer um jogo multiplayer
O TCP é um protocolo orientado a conexão em uma rede IP. A conexão é estabelecida e terminada usando um aperto de mão. Todos os pacotes enviados são garantidos para chegar ao destino na ordem original e sem corrupção por meio de:
Se o remetente não receber uma resposta correta, ele reenviará os pacotes. Se houver vários tempos limite, a conexão será descartada. O TCP também implementa o controle de fluxo e o controle de congestionamento. Essas garantias causam atrasos e geralmente resultam em transmissão menos eficiente que o UDP.
Para garantir a alta taxa de transferência, os servidores da Web podem manter um grande número de conexões TCP abertas, resultando em alto uso da memória. Pode ser caro ter um grande número de conexões abertas entre os threads do servidor da web e dizer, um servidor de memcached. O pool de conexões pode ajudar, além de mudar para o UDP, quando aplicável.
O TCP é útil para aplicativos que requerem alta confiabilidade, mas são menos críticos. Alguns exemplos incluem servidores da Web, informações do banco de dados, SMTP, FTP e SSH.
Use TCP sobre UDP quando:
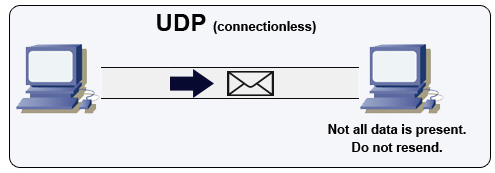
Fonte: como fazer um jogo multiplayer
UDP é sem conexão. Os datagramas (análogos aos pacotes) são garantidos apenas no nível do datagrama. Os datagramas podem chegar a seu destino fora de ordem ou não. O UDP não suporta o controle de congestionamento. Sem as garantias de que o suporte ao TCP, o UDP geralmente é mais eficiente.
O UDP pode transmitir, enviando datagramas para todos os dispositivos na sub -rede. Isso é útil no DHCP porque o cliente ainda não recebeu um endereço IP, impedindo assim uma maneira de o TCP transmitir sem o endereço IP.
O UDP é menos confiável, mas funciona bem em casos de uso em tempo real, como VoIP, Chat de vídeo, streaming e jogos multiplayer em tempo real.
Use UDP no TCP quando:
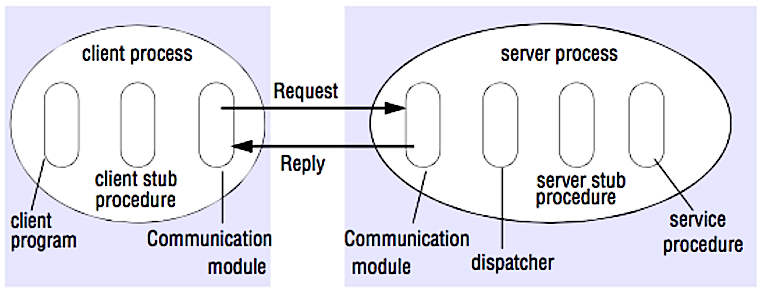
Fonte: quebrar a entrevista de design do sistema
Em um RPC, um cliente faz com que um procedimento seja executado em um espaço de endereço diferente, geralmente um servidor remoto. O procedimento é codificado como se fosse uma chamada de procedimento local, abstraindo os detalhes de como se comunicar com o servidor do programa cliente. As chamadas remotas geralmente são mais lentas e menos confiáveis que as chamadas locais, por isso é útil distinguir chamadas de RPC de chamadas locais. As estruturas populares do RPC incluem Protobuf, Thrift e Avro.
RPC é um protocolo de solicitação-resposta:
Exemplo de chamadas de RPC:
GET /someoperation?data=anId
POST /anotheroperation
{
"data":"anId";
"anotherdata": "another value"
}
O RPC está focado em expor comportamentos. Os RPCs são frequentemente usados por razões de desempenho com comunicações internas, pois você pode ser chamadas nativas para artesanato para melhor se adequar aos seus casos de uso.
Escolha uma biblioteca nativa (também conhecida como SDK) quando:
As APIs HTTP a seguir tendem a ser usadas com mais frequência para APIs públicas.
REST é um estilo arquitetônico que aplica um modelo de cliente/servidor em que o cliente age em um conjunto de recursos gerenciados pelo servidor. O servidor fornece uma representação de recursos e ações que podem manipular ou obter uma nova representação de recursos. Toda a comunicação deve ser apátrida e em cache.
Existem quatro qualidades de uma interface repousante:
Amostra de chamadas de descanso:
GET /someresources/anId
PUT /someresources/anId
{"anotherdata": "another value"}
O REST está focado em expor dados. Ele minimiza o acoplamento entre cliente/servidor e é frequentemente usado para APIs HTTP públicas. O REST usa um método mais genérico e uniforme de expor recursos através de URIs, representação através de cabeçalhos e ações através de verbos como Get, Post, Put, Excluir e Patch. Sendo sem estado, o descanso é ótimo para escala e partição horizontais.
| Operação | RPC | DESCANSAR |
|---|---|---|
| Inscrever-se | Postagem /inscrição | Post /pessoas |
| Renunciar | Postar /renunciar { "PersonId": "1234" } | Excluir /pessoas /1234 |
| Leia uma pessoa | Get /ReadPerson? PersonID = 1234 | GET /PESSONS /1234 |
| Leia a lista de itens de uma pessoa | Get /readUsersitemslist? PersonID = 1234 | GET /PESSONS/1234/itens |
| Adicione um item aos itens de uma pessoa | Post /addItemTouserSitemslist { "PersonId": "1234"; "ItemId": "456" } | POST /PESSONS/1234/itens { "ItemId": "456" } |
| Atualize um item | Publicar /modifyItem { "ItemId": "456"; "Chave": "Valor" } | Put /Itens /456 { "Chave": "Valor" } |
| Exclua um item | Publique /remova { "ItemId": "456" } | Excluir /itens /456 |
Fonte: você realmente sabe por que você prefere descansar sobre RPC
Esta seção pode usar algumas atualizações. Considere contribuir!
A segurança é um tópico amplo. A menos que você tenha uma experiência considerável, um histórico de segurança ou esteja se candidatando a uma posição que requer conhecimento de segurança, provavelmente não precisará saber mais do que o básico:
Às vezes, você será solicitado a fazer estimativas de 'volta do envelope'. Por exemplo, pode ser necessário determinar quanto tempo levará para gerar 100 miniaturas de imagem a partir do disco ou quanta memória uma estrutura de dados levará. Os poderes de dois números de tabela e latência que todo programador deve saber são referências úteis.
Power Exact Value Approx Value Bytes
---------------------------------------------------------------
7 128
8 256
10 1024 1 thousand 1 KB
16 65,536 64 KB
20 1,048,576 1 million 1 MB
30 1,073,741,824 1 billion 1 GB
32 4,294,967,296 4 GB
40 1,099,511,627,776 1 trillion 1 TB
Latency Comparison Numbers
--------------------------
L1 cache reference 0.5 ns
Branch mispredict 5 ns
L2 cache reference 7 ns 14x L1 cache
Mutex lock/unlock 25 ns
Main memory reference 100 ns 20x L2 cache, 200x L1 cache
Compress 1K bytes with Zippy 10,000 ns 10 us
Send 1 KB bytes over 1 Gbps network 10,000 ns 10 us
Read 4 KB randomly from SSD* 150,000 ns 150 us ~1GB/sec SSD
Read 1 MB sequentially from memory 250,000 ns 250 us
Round trip within same datacenter 500,000 ns 500 us
Read 1 MB sequentially from SSD* 1,000,000 ns 1,000 us 1 ms ~1GB/sec SSD, 4X memory
HDD seek 10,000,000 ns 10,000 us 10 ms 20x datacenter roundtrip
Read 1 MB sequentially from 1 Gbps 10,000,000 ns 10,000 us 10 ms 40x memory, 10X SSD
Read 1 MB sequentially from HDD 30,000,000 ns 30,000 us 30 ms 120x memory, 30X SSD
Send packet CA->Netherlands->CA 150,000,000 ns 150,000 us 150 ms
Notes
-----
1 ns = 10^-9 seconds
1 us = 10^-6 seconds = 1,000 ns
1 ms = 10^-3 seconds = 1,000 us = 1,000,000 ns
Métricas úteis com base em números acima:
Perguntas comuns para o design do sistema, com links para recursos sobre como resolver cada um.
| Pergunta | Referência (s) |
|---|---|
| Projete um serviço de sincronização de arquivo como o Dropbox | youtube.com |
| Projete um mecanismo de pesquisa como o Google | Queue.Acm.org stackexchange.com ardendertat.com Stanford.edu |
| Projete um rastreador escalável da web como o Google | quora.com |
| Projete o Google Docs | code.google.com neil.fraser.name |
| Projetar uma loja de valores-chave como Redis | slideShare.net |
| Projetar um sistema de cache como o memcached | slideShare.net |
| Projetar um sistema de recomendação como a Amazon's | hulu.com ijcai13.org |
| Projetar um sistema tinyurl como bitly | n00tc0d3r.blogspot.com |
| Projetar um aplicativo de bate -papo como o whatsapp | highscalability.com |
| Projete um sistema de compartilhamento de imagens como o Instagram | highscalability.com highscalability.com |
| Projete a função do feed de notícias do Facebook | quora.com quora.com slideShare.net |
| Projete a função da linha do tempo do Facebook | facebook.com highscalability.com |
| Projete a função de bate -papo no Facebook | erlang-factory.com facebook.com |
| Projetar uma função de pesquisa de gráfico como o Facebook's | facebook.com facebook.com facebook.com |
| Projete uma rede de entrega de conteúdo como Cloudflare | figshare.com |
| Projetar um sistema de tópicos de tendência como o Twitter | Michael-noll.com snikolov .wordpress.com |
| Projetar um sistema de geração de identificação aleatória | blog.twitter.com github.com |
| Retorne os principais pedidos de K durante um intervalo de tempo | cs.ucsb.edu wpi.edu |
| Projetar um sistema que serve dados de vários data centers | highscalability.com |
| Projete um jogo de cartão multiplayer online | indieflashblog.com BuildNewGames.com |
| Projetar um sistema de coleta de lixo | stuffwithstuff.com Washington.edu |
| Projetar um limitador de taxa de API | https://stripe.com/blog/ |
| Projete uma bolsa de valores (como NASDAQ ou BINANCIA) | Jane Street Implementação de Golang Implementação vá |
| Adicione uma pergunta de design do sistema | Contribuir |
Artigos sobre como os sistemas do mundo real são projetados.
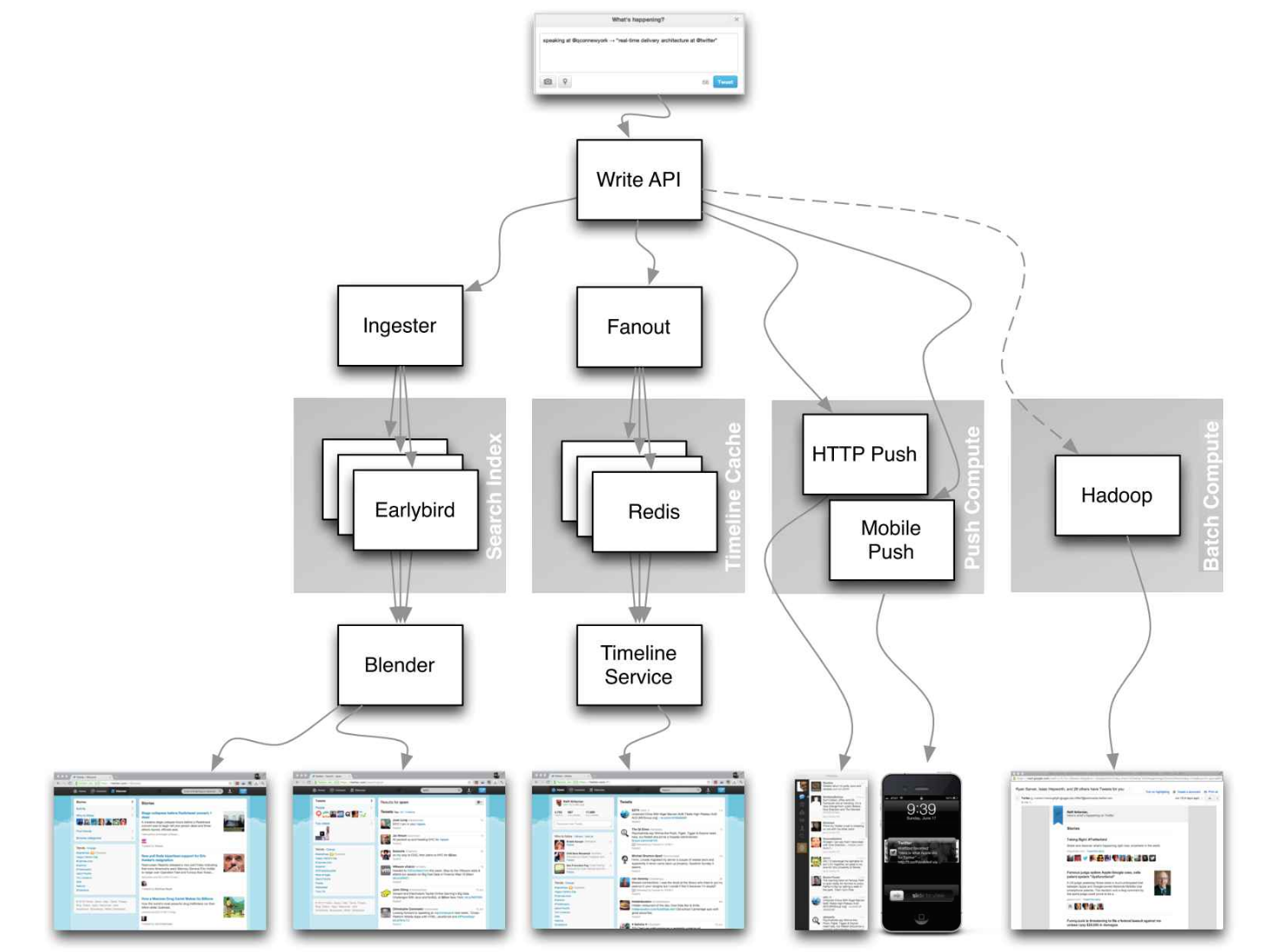
Fonte: Twitter Timelines em escala
Não se concentre nos detalhes da NITTY para os seguintes artigos: em vez disso:
| Tipo | Sistema | Referência (s) |
|---|---|---|
| Processamento de dados | MapReduce - Processamento de dados distribuído do Google | pesquisa.google.com |
| Processamento de dados | Spark - Processamento de dados distribuído de Databricks | slideShare.net |
| Processamento de dados | Storm - Processamento de dados distribuído do Twitter | slideShare.net |
| Armazenamento de dados | BIGTABLE - Banco de dados orientado para coluna distribuído do Google | Harvard.edu |
| Armazenamento de dados | HBASE - Implementação de código aberto do BIGTABLE | slideShare.net |
| Armazenamento de dados | Cassandra - Banco de dados orientado para coluna distribuído do Facebook | slideShare.net |
| Armazenamento de dados | DynamoDB - Banco de dados orientado a documentos da Amazon | Harvard.edu |
| Armazenamento de dados | MongoDB - Banco de dados orientado a documentos | slideShare.net |
| Armazenamento de dados | Spanner - Banco de dados distribuído globalmente do Google | pesquisa.google.com |
| Armazenamento de dados | Memcached - Sistema de cache de memória distribuído | slideShare.net |
| Armazenamento de dados | Redis - Distributed memory caching system with persistence and value types | slideshare.net |
| File system | Google File System (GFS) - Distributed file system | research.google.com |
| File system | Hadoop File System (HDFS) - Open source implementation of GFS | apache.org |
| Diversos | Chubby - Lock service for loosely-coupled distributed systems from Google | research.google.com |
| Diversos | Dapper - Distributed systems tracing infrastructure | research.google.com |
| Diversos | Kafka - Pub/sub message queue from LinkedIn | slideshare.net |
| Diversos | Zookeeper - Centralized infrastructure and services enabling synchronization | slideshare.net |
| Add an architecture | Contribuir |
| Empresa | Reference(s) |
|---|---|
| Amazônia | Amazon architecture |
| Cinchcast | Producing 1,500 hours of audio every day |
| DataSift | Realtime datamining At 120,000 tweets per second |
| Dropbox | How we've scaled Dropbox |
| ESPN | Operating At 100,000 duh nuh nuhs per second |
| Google architecture | |
| 14 million users, terabytes of photos What powers Instagram | |
| Justin.tv | Justin.Tv's live video broadcasting architecture |
| Scaling memcached at Facebook TAO: Facebook's distributed data store for the social graph Facebook's photo storage How Facebook Live Streams To 800,000 Simultaneous Viewers | |
| Flickr | Flickr architecture |
| Caixa de correio | From 0 to one million users in 6 weeks |
| Netflix | A 360 Degree View Of The Entire Netflix Stack Netflix: What Happens When You Press Play? |
| From 0 To 10s of billions of page views a month 18 million visitors, 10x growth, 12 employees | |
| Playfish | 50 million monthly users and growing |
| PlentyOfFish | PlentyOfFish architecture |
| Força de vendas | How they handle 1.3 billion transactions a day |
| Stack Overflow | Stack Overflow architecture |
| TripAdvisor | 40M visitors, 200M dynamic page views, 30TB data |
| Tumblr | 15 billion page views a month |
| Making Twitter 10000 percent faster Storing 250 million tweets a day using MySQL 150M active users, 300K QPS, a 22 MB/S firehose Timelines at scale Big and small data at Twitter Operations at Twitter: scaling beyond 100 million users How Twitter Handles 3,000 Images Per Second | |
| Uber | How Uber scales their real-time market platform Lessons Learned From Scaling Uber To 2000 Engineers, 1000 Services, And 8000 Git Repositories |
| The WhatsApp architecture Facebook bought for $19 billion | |
| YouTube | YouTube scalability YouTube architecture |
Architectures for companies you are interviewing with.
Questions you encounter might be from the same domain.
Looking to add a blog? To avoid duplicating work, consider adding your company blog to the following repo:
Interested in adding a section or helping complete one in-progress? Contribuir!
Credits and sources are provided throughout this repo.
Special thanks to:
Feel free to contact me to discuss any issues, questions, or comments.
My contact info can be found on my GitHub page.
I am providing code and resources in this repository to you under an open source license. Because this is my personal repository, the license you receive to my code and resources is from me and not my employer (Facebook).
Copyright 2017 Donne Martin
Creative Commons Attribution 4.0 International License (CC BY 4.0)
http://creativecommons.org/licenses/by/4.0/


