Lihang
1.0.0
A segunda edição deste livro foi publicada. Todas as atualizações de conteúdo após maio de 2019 referem-se à primeira impressão da segunda edição.
Para o conteúdo da primeira edição, consulte Release first_edition
[TOC]
Para facilitar o aprendizado, algumas descrições de ferramentas são compiladas.
Se você precisar fazer referência a este repositório:
Formato: SmirkCao, Lihang, (2018), GitHub repository, https://github.com/SmirkCao/Lihang
ou
@misc{SmirkCao,
author = {SmirkCao},
title = {Lihang},
year = {2018},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {url{https://github.com/SmirkCao/Lihang}},
commit = {c5624a9bd757a5cc88e78b85b89e9221deb08270}
}
Esta parte do conteúdo não corresponde ao prefácio em "Métodos de Aprendizagem Estatística". O prefácio do livro também está bem escrito e é citado da seguinte forma:
- Em termos de seleção de conteúdo, focamos na introdução dos métodos mais importantes e comumente utilizados, especialmente métodos relacionados a problemas de classificação e rotulagem .
- Tente usar uma estrutura unificada para discutir todos os métodos, para que todo o livro não perca sua sistematicidade.
- Aplicável a estudantes universitários e estudantes de pós-graduação com especialização em recuperação de informações e processamento de linguagem natural.
Outra coisa a notar é a formação profissional do autor.
O autor tem se envolvido em pesquisas sobre vários processamentos inteligentes de dados de texto usando métodos de aprendizagem estatística, incluindo processamento de linguagem natural, recuperação de informações e mineração de dados de texto.
Se você usar meu modelo para implementar a pesquisa por similaridade, o livro que é semelhante ao livro do Sr. Li é "Dispositivos Optoeletrônicos Semicondutores". É uma pena que eu não o tenha estudado repetidamente quando era jovem.
Espero que, no processo de leitura repetida, o livro inteiro fique cada vez mais grosso. Todos os documentos e códigos desta série, salvo especificação em contrário, referem-se a "Métodos Estatísticos de Aprendizagem" de Li Hang. Conteúdos em outras referências serão vinculados se citados.
Algumas referências estão listadas nas Refs, algumas das quais são muito úteis para a compreensão do conteúdo do livro. Descrições e explicações desses arquivos serão adicionadas em Refs/README.md correspondente à seção de referência. Algumas notas sobre outras referências também foram adicionadas a este documento.
Para facilitar o download de referências, ref_downloader.sh foi adicionado durante a revisão02, que pode ser usado para baixar as referências listadas no livro. O processo de atualização é concluído gradualmente à medida que a revisão02 avança.
Além disso, este livro do professor Li Hang, É muito fino (a segunda versão não é mais fina) , mas quase todas as frases trazem muitos pontos à tona e vale a pena ler continuamente.
Há uma tabela de símbolos após o índice do livro, que explica as definições dos símbolos, portanto, se houver símbolos que você não entende, você pode procurar na tabela, há um índice no final do livro; e você pode usar o índice para encontrar o significado do símbolo correspondente que aparece no livro Localização. Neste Repo, um glossary_index.md é mantido para adicionar algumas explicações aos símbolos correspondentes e marcar diretamente os números das páginas correspondentes aos símbolos.
Após cada algoritmo ou exemplo, haverá um ◼️, indicando que o algoritmo ou exemplo termina aqui. Isso é chamado de símbolo de fim de prova. Você saberá disso se ler mais literatura.
Ao ler, muitas vezes temos dúvidas sobre a base dos logaritmos. Algumas das mais importantes são enfatizadas no livro. Alguns que não são enfatizados podem ser compreendidos através do contexto. Além disso, como existe uma fórmula para alterar a base, não importa muito qual seja a base. A diferença está em um coeficiente constante. No entanto, a escolha de bases diferentes terá significados físicos e considerações de resolução de problemas. Para análise desta questão, você pode ver a discussão sobre entropia no PRML 1.6 para entender.
Além disso, no que diz respeito à questão dos coeficientes constantes na fórmula, se for utilizada uma solução iterativa e por vezes a fórmula for simplificada até certo ponto, a velocidade de convergência pode ser melhorada. Os detalhes podem ser gradualmente compreendidos na prática.
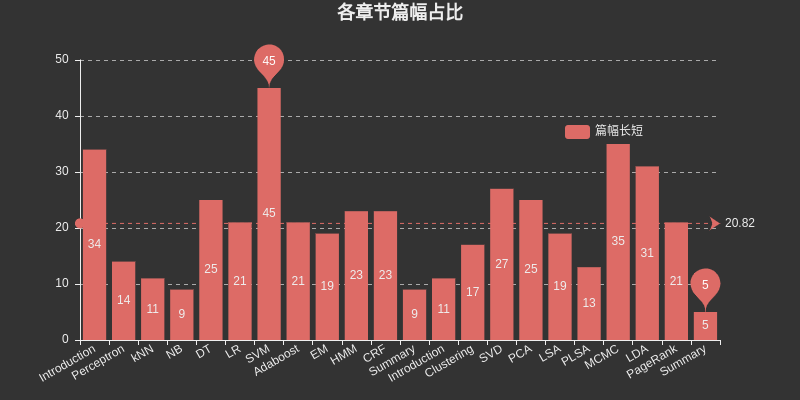
Insira aqui um gráfico para listar o espaço ocupado por cada capítulo Entre eles, SVM ocupa o maior espaço entre a aprendizagem supervisionada, MCMC ocupa o maior espaço entre a aprendizagem não supervisionada e DT, HMM, CRF, SVD, PCA, LDA e. PageRank também ocupa o maior espaço relativamente grande.
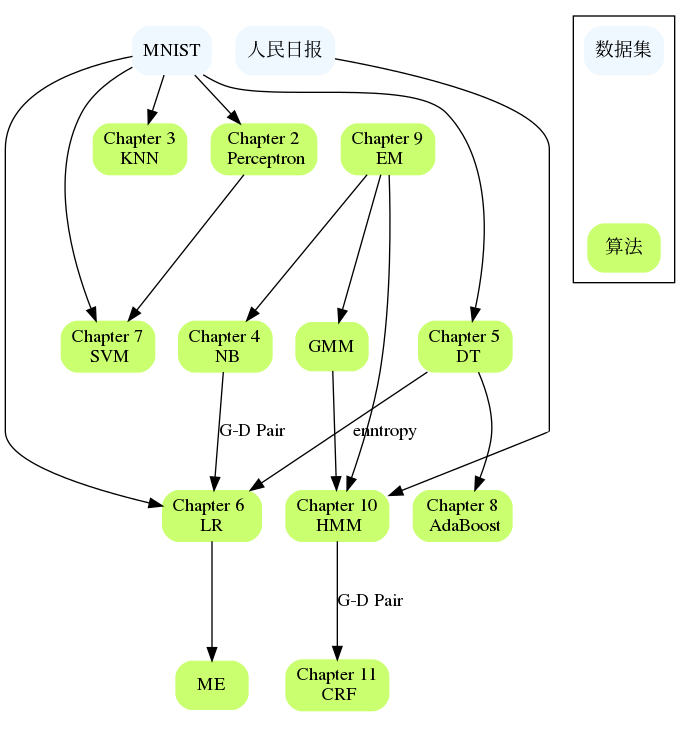
Os capítulos estão relacionados entre si, como NB e LR, DT e AdaBoost, Perceptron e SVM, HMM e CRF, etc. Se encontrar dificuldades em um capítulo grande, você pode revisar o conteúdo dos capítulos anteriores ou verificar as referências geralmente são fornecidas referências que descrevem o problema com mais detalhes e podem explicar onde você está preso.
Introdução
Três elementos dos métodos de aprendizagem estatística:
Modelo
Estratégia
algoritmo
A segunda edição reorganizou a estrutura de diretórios deste capítulo para torná-la mais clara.
Perceptron
kNN
N. B.
DT
LR
Em relação ao estudo da entropia máxima, recomenda-se a leitura da literatura de referência [1] neste capítulo, Berger, 1996, que é útil para compreender os exemplos do livro e compreender o princípio da entropia máxima.
Então, por que LR e Maxent são colocados em um capítulo?
Todos pertencem ao modelo linear logarítmico
Ambos podem ser usados para classificação binária e multiclassificação
Os métodos de aprendizagem dos dois modelos geralmente usam estimativa de máxima verossimilhança ou estimativa de máxima verossimilhança regularizada. Pode ser formalizado como um problema de otimização irrestrito e os métodos de solução incluem IIS, GD, BFGS, etc.
É descrito a seguir em Regressão logística,
A regressão logística, apesar do nome, é um modelo linear para classificação em vez de regressão. A regressão logística também é conhecida na literatura como regressão logit, classificação de entropia máxima (MaxEnt) ou classificador log-linear. Neste modelo, as probabilidades descrevem. os resultados possíveis de um único ensaio são modelados usando uma função logística.
Também existe essa descrição
A regressão logística é um caso especial de entropia máxima com dois rótulos +1 e −1.
A derivação neste capítulo usa a propriedade de $yin mathcal{Y}={0,1}$
Às vezes dizemos que a regressão logística se chama Maxent na PNL
SVM
Impulsionando
Vamos detalhar aqui, porque HMM e CRF geralmente levam à introdução de modelos gráficos probabilísticos. Em "Aprendizado de Máquina, Zhou Zhihua", um capítulo separado de modelo gráfico probabilístico é usado para incluir HMM, MRF, CRF e outros conteúdos. Além disso, existem muitos pontos relacionados do HMM ao próprio CRF.
No primeiro capítulo do livro são explicadas três aplicações da aprendizagem supervisionada: classificação, rotulagem e regressão. Existem suplementos no Capítulo 12. Este livro considera principalmente os métodos de aprendizagem dos dois primeiros. Conseqüentemente, a segmentação também é apropriada aqui. O modelo de classificação é introduzido anteriormente, e a regressão é mencionada em uma pequena parte. O problema de rotulagem é introduzido principalmente mais tarde.
EM
O algoritmo EM é um algoritmo iterativo usado para estimativa de máxima verossimilhança de parâmetros de modelos probabilísticos contendo variáveis ocultas, ou estimativa de máxima probabilidade posterior. (A estimativa de máxima verossimilhança e a estimativa de máxima probabilidade posterior aqui são estratégias de aprendizagem )
Se todas as variáveis do modelo de probabilidade forem variáveis observadas, então, dados os dados, os parâmetros do modelo podem ser estimados diretamente usando o método de estimativa de máxima verossimilhança ou o método de estimativa bayesiana.
Observe que se você não entender esta descrição no livro, consulte a parte de estimativa de parâmetros do método Naive Bayes em CH04.
Essa parte do código implementa BMM e GMM, vale a pena dar uma olhada
Em relação ao EM, pouco foi escrito sobre este capítulo. EM é um dos dez principais algoritmos e Hinton publicou o segundo artigo da Capsule Network "Matrix Capsules with EM Routing" no ICLR.
No CH22, o algoritmo EM é classificado como um método básico de aprendizado de máquina e não envolve modelos específicos de aprendizado de máquina. Ele pode ser usado para aprendizado não supervisionado, aprendizado supervisionado e aprendizado semissupervisionado.
HUM
CRF
Resumo
Este capítulo tem apenas algumas páginas. Você pode considerar a seguinte rotina de leitura:
Leia com o Capítulo 1
Se você encontrar questões pouco claras em estudos anteriores, leia este capítulo novamente.
Leia este capítulo com atenção e expanda deste capítulo para outros dez capítulos.
Observe que há a Figura 12.2 neste capítulo, que menciona a função de perda logística $y$ aqui deve ser definida em $cal{Y}={+1,-1}$. definido em $cal{Y}={0,1}$, preste atenção aqui.
O livro do professor Li realmente faz você ganhar algo novo cada vez que o lê.
A segunda edição adiciona oito métodos de aprendizagem não supervisionados: agrupamento, decomposição de valores singulares, análise de componentes principais, análise semântica latente, análise semântica latente probabilística, método Monte Carlo da cadeia de Markov, alocação latente de Dirichlet e PageRank.
Introdução
Agrupamento
Cada capítulo deste livro não é completamente independente. Esta parte pretende organizar as conexões entre os capítulos e os conjuntos de dados aplicáveis. Até que ponto o algoritmo é implementado e em quais conjuntos de dados ele pode ser executado também são um aspecto.