
Este repositório contém perguntas e exercícios sobre vários tópicos técnicos, às vezes relacionados a DevOps e SRE
Existem atualmente 2.624 exercícios e questões
️ Você pode usá-los para se preparar para uma entrevista, mas a maioria das perguntas e exercícios não representa uma entrevista real. Por favor, leia a página de perguntas frequentes para mais detalhes
? Se você está interessado em seguir uma carreira como engenheiro DevOps, aprender alguns dos conceitos mencionados aqui seria útil, mas você deve saber que não se trata de aprender todos os tópicos e tecnologias mencionados neste repositório.
Você pode adicionar mais exercícios enviando pull requests :) Leia sobre as diretrizes de contribuição aqui

DevOps | 
Git | 
Rede | 
Hardware | 
Kubernetes |

Desenvolvimento de software | 
Pitão | 
Ir | 
Perl | 
Regex |

Nuvem | 
AWS | 
Azul | 
Plataforma Google Cloud | 
OpenStack |

Sistema operacional | 
Linux | 
Virtualização | 
DNS | 
Script de shell |

Bancos de dados | 
SQL | 
Mongo | 
Teste | 
Grandes dados |

CI/CD | 
Certificados | 
Recipientes | 
OpenShift | 
Armazenar |

Terraforma | 
Fantoche | 
Distribuído | 
Perguntas que você pode fazer | 
Ansible |

Observabilidade | 
Prometeu | 
Círculo CI | 
| 
Grafana |

Argo | 
Habilidades interpessoais | 
Segurança | 
Projeto do sistema |

Engenharia do Caos | 
Diversos | 
Elástico | 
Kafka | 
NodeJs |
Rede
Em geral, o que você precisa para se comunicar?
- Uma linguagem comum (para os dois lados entenderem)
- Uma forma de se dirigir a quem você deseja se comunicar
- Uma Conexão (para que o conteúdo da comunicação possa chegar aos destinatários)
O que é TCP/IP?
Um conjunto de protocolos que definem como dois ou mais dispositivos podem se comunicar entre si.
Para saber mais sobre TCP/IP, leia aqui
O que é Ethernet?
Ethernet simplesmente se refere ao tipo mais comum de rede local (LAN) usada atualmente. Uma LAN – em contraste com uma WAN (Wide Area Network), que abrange uma área geográfica maior – é uma rede conectada de computadores em uma área pequena, como seu escritório, campus universitário ou até mesmo sua casa.
O que é um endereço MAC? Para que é usado?
Um endereço MAC é um número ou código de identificação exclusivo usado para identificar dispositivos individuais na rede.
Os pacotes enviados na Ethernet sempre vêm de um endereço MAC e são enviados para um endereço MAC. Se um adaptador de rede estiver recebendo um pacote, ele comparará o endereço MAC de destino do pacote com o endereço MAC do próprio adaptador.
Quando este endereço MAC é usado?: ff:ff:ff:ff:ff:ff
Quando um dispositivo envia um pacote para o endereço MAC de transmissão (FF:FF:FF:FF:FF:FF), ele é entregue a todas as estações da rede local. As transmissões Ethernet são usadas para resolver endereços IP em endereços MAC (por ARP) na camada de enlace de dados.
O que é um endereço IP?
Um endereço de protocolo da Internet (endereço IP) é um rótulo numérico atribuído a cada dispositivo conectado a uma rede de computadores que usa o protocolo da Internet para comunicação. Um endereço IP serve duas funções principais: identificação de host ou interface de rede e endereçamento de localização.
Explique a máscara de sub-rede e dê um exemplo
Uma máscara de sub-rede é um número de 32 bits que mascara um endereço IP e divide os endereços IP em endereços de rede e endereços de host. A máscara de sub-rede é feita configurando os bits de rede para todos os "1" e definindo os bits do host para todos os "0". Dentro de uma determinada rede, do total de endereços de host utilizáveis, dois são sempre reservados para fins específicos e não podem ser alocados a nenhum host. Estes são o primeiro endereço, que é reservado como endereço de rede (também conhecido como ID de rede), e o último endereço usado para transmissão de rede.
Exemplo
O que é um endereço IP privado? Em quais cenários/projetos de sistema devo usá-lo?
Endereços IP privados são atribuídos aos hosts na mesma rede para se comunicarem entre si. Como o nome “privado” sugere, os dispositivos com endereços IP privados atribuídos não podem ser acessados pelos dispositivos de nenhuma rede externa. Por exemplo, se eu estiver morando em um albergue e quiser que meus colegas de albergue entrem no servidor de jogo que hospedei, pedirei que eles se conectem através do endereço IP privado do meu servidor, já que a rede é local do albergue. O que é um endereço IP público? Em quais cenários/projetos de sistema devo usá-lo?
Um endereço IP público é um endereço IP público. Caso você esteja hospedando um servidor de jogo ao qual deseja que seus amigos participem, você fornecerá a eles seu endereço IP público para permitir que seus computadores identifiquem e localizem sua rede e servidor para que a conexão ocorra. Uma vez que você não precisaria usar um endereço IP público, caso estivesse jogando com amigos que estivessem conectados à mesma rede que você, nesse caso, você usaria um endereço IP privado. Para que alguém possa se conectar ao seu servidor localizado internamente, você terá que configurar um encaminhamento de porta para informar ao seu roteador para permitir o tráfego do domínio público em sua rede e vice-versa. Explique o modelo OSI. Quais camadas existem? Pelo que cada camada é responsável?
- Aplicação: usuário final (HTTP está aqui)
- Apresentação: estabelece o contexto entre entidades da camada de aplicação (a criptografia está aqui)
- Sessão: estabelece, gerencia e finaliza as conexões
- Transporte: transfere sequências de dados de comprimento variável de um host de origem para um host de destino (TCP & UDP estão aqui)
- Rede: transfere datagramas de uma rede para outra (IP está aqui)
- Link de dados: fornece um link entre dois nós diretamente conectados (MAC está aqui)
- Físico: as especificações elétricas e físicas da conexão de dados (Bits estão aqui )
Você pode ler mais sobre o modelo OSI em penguintutor.com
Para cada um dos itens a seguir determina a qual camada OSI ele pertence:- Correção de erros
- Roteamento de pacotes
- Cabos e sinais elétricos
- Endereço MAC
- Endereço IP
- Encerrar conexões
- Aperto de mão de 3 vias
Correção de erros - Roteamento de pacotes de link de dados - Cabos de rede e sinais elétricos - Endereço MAC físico - Endereço IP do link de dados - Rede Terminar conexões - Sessão Aperto de mão de 3 vias - Transporte Com quais esquemas de entrega você está familiarizado?
Unicast: Comunicação um-para-um onde há um remetente e um destinatário.
Broadcast: Envio de uma mensagem para todos na rede. O endereço ff:ff:ff:ff:ff:ff é usado para transmissão. Dois protocolos comuns que usam transmissão são ARP e DHCP.
Multicast: Envio de uma mensagem para um grupo de assinantes. Pode ser um para muitos ou muitos para muitos.
O que é CSMA/CD? É usado em redes Ethernet modernas?
CSMA/CD significa Carrier Sense Multiple Access/Colision Detection. Seu foco principal é gerenciar o acesso a um meio/barramento compartilhado onde apenas um host pode transmitir em um determinado momento.
Algoritmo CSMA/CD:
Antes de enviar um quadro, verifica se outro host já está transmitindo um quadro.- Se ninguém estiver transmitindo, ele inicia a transmissão do quadro.
- Se dois hosts transmitem ao mesmo tempo, temos uma colisão.
- Ambos os hosts param de enviar o quadro e enviam a todos um 'sinal de congestionamento' notificando a todos que ocorreu uma colisão
- Eles estão esperando um tempo aleatório antes de enviar novamente
- Depois que cada host esperou um tempo aleatório, eles tentam enviar o quadro novamente e assim o ciclo recomeça
Descreva os seguintes dispositivos de rede e a diferença entre eles:
Um roteador, switch e hub são todos dispositivos de rede usados para conectar dispositivos em uma rede local (LAN). Porém, cada dispositivo opera de maneira diferente e tem seus casos de uso específicos. Aqui está uma breve descrição de cada dispositivo e as diferenças entre eles:
Roteador: um dispositivo de rede que conecta vários segmentos de rede. Opera na camada de rede (camada 3) do modelo OSI e utiliza protocolos de roteamento para direcionar dados entre redes. Os roteadores usam endereços IP para identificar dispositivos e rotear pacotes de dados para o destino correto.- Switch: um dispositivo de rede que conecta vários dispositivos em uma LAN. Ele opera na camada de enlace de dados (camada 2) do modelo OSI e usa endereços MAC para identificar dispositivos e direcionar pacotes de dados ao destino correto. Os switches permitem que dispositivos na mesma rede se comuniquem entre si de forma mais eficiente e podem evitar colisões de dados que podem ocorrer quando vários dispositivos enviam dados simultaneamente.
- Hub: um dispositivo de rede que conecta vários dispositivos por meio de um único cabo e é usado para conectar vários dispositivos sem segmentar uma rede. No entanto, ao contrário de um switch, ele opera na camada física (camada 1) do modelo OSI e simplesmente transmite pacotes de dados para todos os dispositivos conectados a ele, independentemente de o dispositivo ser o destinatário pretendido ou não. Isso significa que podem ocorrer colisões de dados e, como resultado, a eficiência da rede pode ser prejudicada. Os hubs geralmente não são usados em configurações de rede modernas, pois os switches são mais eficientes e fornecem melhor desempenho de rede.
O que é um “Domínio de Colisão”?
Um domínio de colisão é um segmento de rede no qual os dispositivos podem potencialmente interferir uns com os outros ao tentar transmitir dados ao mesmo tempo. Quando dois dispositivos transmitem dados ao mesmo tempo, pode causar uma colisão, resultando em perda ou corrupção de dados. Num domínio de colisão, todos os dispositivos partilham a mesma largura de banda e qualquer dispositivo pode interferir potencialmente na transmissão de dados por outros dispositivos. O que é um “domínio de transmissão”?
Um domínio de broadcast é um segmento de rede no qual todos os dispositivos podem se comunicar entre si enviando mensagens de broadcast. Uma mensagem de difusão é uma mensagem enviada para todos os dispositivos em uma rede, e não para um dispositivo específico. Num domínio de broadcast, todos os dispositivos podem receber e processar mensagens de broadcast, independentemente de a mensagem ser destinada a eles ou não. três computadores conectados a um switch. Quantos domínios de colisão existem? Quantos domínios de transmissão?
Três domínios de colisão e um domínio de transmissão
Como funciona um roteador?
Um roteador é um dispositivo físico ou virtual que transmite informações entre duas ou mais redes de computadores comutadas por pacotes. Um roteador inspeciona o endereço de protocolo da Internet (endereço IP) de destino de um determinado pacote de dados, calcula a melhor maneira de chegar ao seu destino e, em seguida, o encaminha de acordo.
O que é NAT?
A tradução de endereços de rede (NAT) é um processo no qual um ou mais endereços IP locais são traduzidos em um ou mais endereços IP globais e vice-versa, a fim de fornecer acesso à Internet aos hosts locais.
O que é um proxy? Como funciona? Para que precisamos disso?
Um servidor proxy atua como um gateway entre você e a Internet. É um servidor intermediário que separa os usuários finais dos sites que eles navegam.
Se você estiver usando um servidor proxy, o tráfego da Internet fluirá através do servidor proxy até o endereço solicitado. A solicitação então volta através do mesmo servidor proxy (há exceções a esta regra) e então o servidor proxy encaminha os dados recebidos do site para você.
Os servidores proxy fornecem vários níveis de funcionalidade, segurança e privacidade, dependendo do seu caso de uso, necessidades ou política da empresa.
O que é TCP? Como funciona? Qual é o aperto de mão de três vias?
Handshake de três vias TCP ou handshake de três vias é um processo usado em uma rede TCP/IP para fazer uma conexão entre servidor e cliente.
Um handshake de três vias é usado principalmente para criar uma conexão de soquete TCP. Funciona quando:
Um nó cliente envia um pacote de dados SYN através de uma rede IP para um servidor na mesma rede ou em uma rede externa. O objetivo deste pacote é perguntar/inferir se o servidor está aberto para novas conexões.- O servidor de destino deve ter portas abertas que possam aceitar e iniciar novas conexões. Quando o servidor recebe o pacote SYN do nó cliente, ele responde e retorna um recebimento de confirmação – o pacote ACK ou pacote SYN/ACK.
- O nó cliente recebe o SYN/ACK do servidor e responde com um pacote ACK.
O que é atraso de ida e volta ou tempo de ida e volta?
Da Wikipedia: "o tempo que leva para um sinal ser enviado mais o tempo que leva para que um reconhecimento desse sinal seja recebido"
Pergunta bônus: qual é o RTT da LAN?
Como funciona um handshake SSL?
O handshake SSL é um processo que estabelece uma conexão segura entre um cliente e um servidor. O cliente envia uma mensagem Client Hello ao servidor, que inclui a versão do protocolo SSL/TLS do cliente, uma lista dos algoritmos criptográficos suportados pelo cliente e um valor aleatório.- O servidor responde com uma mensagem Server Hello, que inclui a versão do servidor do protocolo SSL/TLS, um valor aleatório e um ID de sessão.
- O servidor envia uma mensagem de certificado, que contém o certificado do servidor.
- O servidor envia uma mensagem Server Hello Done, que indica que o servidor concluiu o envio de mensagens para a fase Server Hello.
- O cliente envia uma mensagem Client Key Exchange, que contém a chave pública do cliente.
- O cliente envia uma mensagem Change Cipher Spec, que notifica o servidor de que o cliente está prestes a enviar uma mensagem criptografada com a nova especificação de cifra.
- O cliente envia uma mensagem de handshake criptografada, que contém o segredo pré-mestre criptografado com a chave pública do servidor.
- O servidor envia uma mensagem Change Cipher Spec, que notifica o cliente de que o servidor está prestes a enviar uma mensagem criptografada com a nova especificação de cifra.
- O servidor envia uma mensagem de handshake criptografada, que contém o segredo pré-mestre criptografado com a chave pública do cliente.
- O cliente e o servidor agora podem trocar dados de aplicativos.
Qual é a diferença entre TCP e UDP?
O TCP estabelece uma conexão entre o cliente e o servidor para garantir a ordem dos pacotes, por outro lado, o UDP não estabelece uma conexão entre o cliente e o servidor e não trata os pedidos dos pacotes. Isso torna o UDP mais leve que o TCP e um candidato perfeito para serviços como streaming.
Penguintutor.com fornece uma boa explicação.
Com quais protocolos TCP/IP você está familiarizado?
Explique o "gateway padrão"
Um gateway padrão serve como um ponto de acesso ou roteador IP que um computador em rede usa para enviar informações a um computador em outra rede ou na Internet.
O que é ARP? Como funciona?
ARP significa Protocolo de resolução de endereços. Quando você tenta executar ping em um endereço IP em sua rede local, digamos 192.168.1.1, seu sistema precisa transformar o endereço IP 192.168.1.1 em um endereço MAC. Isso envolve o uso de ARP para resolver o endereço, daí seu nome.
Os sistemas mantêm uma tabela de consulta ARP onde armazenam informações sobre quais endereços IP estão associados a quais endereços MAC. Ao tentar enviar um pacote para um endereço IP, o sistema irá primeiro consultar esta tabela para ver se já conhece o endereço MAC. Se houver um valor armazenado em cache, o ARP não será usado.
O que é TTL? O que isso ajuda a prevenir?
TTL (Time to Live) é um valor em um pacote IP (Internet Protocol) que determina quantos saltos ou roteadores um pacote pode percorrer antes de ser descartado. Cada vez que um pacote é encaminhado por um roteador, o valor TTL diminui em um. Quando o valor TTL chega a zero, o pacote é descartado e uma mensagem ICMP (Internet Control Message Protocol) é enviada de volta ao remetente indicando que o pacote expirou.- O TTL é usado para evitar que pacotes circulem indefinidamente na rede, o que pode causar congestionamento e degradar o desempenho da rede.
- Também ajuda a evitar que os pacotes fiquem presos em loops de roteamento, onde os pacotes viajam continuamente entre o mesmo conjunto de roteadores sem nunca chegar ao seu destino.
- Além disso, o TTL pode ser usado para ajudar a detectar e prevenir ataques de falsificação de IP, onde um invasor tenta se passar por outro dispositivo na rede usando um endereço IP falso ou falso. Ao limitar o número de saltos que um pacote pode percorrer, o TTL pode ajudar a evitar que os pacotes sejam roteados para destinos que não são legítimos.
O que é DHCP? Como funciona?
Significa Dynamic Host Configuration Protocol e aloca endereços IP, máscaras de sub-rede e gateways para hosts. É assim que funciona:
- Um host ao entrar em uma rede transmite uma mensagem em busca de um servidor DHCP (DHCP DISCOVER)
- Uma mensagem de oferta é enviada de volta pelo servidor DHCP como um pacote contendo tempo de concessão, máscara de sub-rede, endereços IP, etc. (OFERTA DHCP)
- Dependendo de qual oferta for aceita, o cliente envia de volta uma transmissão de resposta informando todos os servidores DHCP (PEDIDO DHCP)
- O servidor envia uma confirmação (DHCP ACK)
Leia mais aqui
Você pode ter dois servidores DHCP na mesma rede? Como funciona?
É possível ter dois servidores DHCP na mesma rede, porém isso não é recomendado, sendo importante configurá-los com cuidado para evitar conflitos e problemas de configuração.
Quando dois servidores DHCP são configurados na mesma rede, existe o risco de ambos os servidores atribuirem endereços IP e outras configurações de rede ao mesmo dispositivo, o que pode causar conflitos e problemas de conectividade. Além disso, se os servidores DHCP estiverem configurados com configurações ou opções de rede diferentes, os dispositivos na rede poderão receber definições de configuração conflitantes ou inconsistentes.- Contudo, em alguns casos, pode ser necessário ter dois servidores DHCP na mesma rede, como em grandes redes onde um servidor DHCP pode não ser capaz de lidar com todas as solicitações. Nesses casos, os servidores DHCP podem ser configurados para atender diferentes intervalos de endereços IP ou diferentes sub-redes, para que não interfiram entre si.
O que é túnel SSL? Como funciona?
- O tunelamento SSL (Secure Sockets Layer) é uma técnica usada para estabelecer uma conexão segura e criptografada entre dois pontos de extremidade em uma rede insegura, como a Internet. O túnel SSL é criado encapsulando o tráfego em uma conexão SSL, que fornece confidencialidade, integridade e autenticação.
Veja como funciona o tunelamento SSL:
Um cliente inicia uma conexão SSL com um servidor, que envolve um processo de handshake para estabelecer a sessão SSL.- Uma vez estabelecida a sessão SSL, o cliente e o servidor negociam parâmetros de criptografia, como o algoritmo de criptografia e o comprimento da chave, e então trocam certificados digitais para autenticar um ao outro.
- O cliente então envia o tráfego através do túnel SSL para o servidor, que descriptografa o tráfego e o encaminha ao seu destino.
- O servidor envia o tráfego de volta através do túnel SSL para o cliente, que descriptografa o tráfego e o encaminha para o aplicativo.
O que é um soquete? Onde você pode ver a lista de soquetes em seu sistema?
Um soquete é um endpoint de software que permite a comunicação bidirecional entre processos em uma rede. Os soquetes fornecem uma interface padronizada para comunicação em rede, permitindo que aplicativos enviem e recebam dados através de uma rede. Para visualizar a lista de soquetes abertos em um sistema Linux: netstat -an- Este comando exibe uma lista de todos os soquetes abertos, juntamente com seu protocolo, endereço local, endereço externo e estado.
O que é IPv6? Por que deveríamos considerar usá-lo se temos IPv4?
- IPv6 (Protocolo de Internet versão 6) é a versão mais recente do Protocolo de Internet (IP), usado para identificar e comunicar-se com dispositivos em uma rede. Os endereços IPv6 são endereços de 128 bits e são expressos em notação hexadecimal, como 2001:0db8:85a3:0000:0000:8a2e:0370:7334.
Existem vários motivos pelos quais devemos considerar o uso de IPv6 em vez de IPv4:
Espaço de endereçamento: O IPv4 possui um espaço de endereçamento limitado, que está esgotado em muitas partes do mundo. O IPv6 fornece um espaço de endereço muito maior, permitindo trilhões de endereços IP exclusivos.- Segurança: O IPv6 inclui suporte integrado para IPsec, que fornece criptografia e autenticação ponta a ponta para o tráfego de rede.
- Desempenho: O IPv6 inclui recursos que podem ajudar a melhorar o desempenho da rede, como roteamento multicast, que permite que um único pacote seja enviado para vários destinos simultaneamente.
- Configuração de rede simplificada: O IPv6 inclui recursos que podem simplificar a configuração de rede, como a configuração automática sem estado, que permite que os dispositivos configurem automaticamente seus próprios endereços IPv6 sem a necessidade de um servidor DHCP.
- Melhor suporte à mobilidade: O IPv6 inclui recursos que podem melhorar o suporte à mobilidade, como o Mobile IPv6, que permite que os dispositivos mantenham seus endereços IPv6 à medida que se movem entre diferentes redes.
O que é VLAN?
- Uma VLAN (Virtual Local Area Network) é uma rede lógica que agrupa um conjunto de dispositivos em uma rede física, independentemente de sua localização física. As VLANs são criadas configurando switches de rede para atribuir um ID de VLAN específico aos quadros enviados por dispositivos conectados a uma porta ou grupo de portas específico no switch.
O que é MTU?
MTU significa Unidade Máxima de Transmissão. É o tamanho da maior PDU (Unidade de Dados de Protocolo) que pode ser enviada em uma única transação.
O que acontece se você enviar um pacote maior que o MTU?
Com o protocolo IPv4, o roteador pode fragmentar a PDU e então enviar toda a PDU fragmentada por meio da transação.
Com o protocolo IPv6, gera um erro no computador do usuário.
Verdadeiro ou Falso? Ping está usando UDP porque não se preocupa com conexão confiável
Falso. Na verdade, o Ping está usando ICMP (Internet Control Message Protocol), que é um protocolo de rede usado para enviar mensagens de diagnóstico e mensagens de controle relacionadas à comunicação de rede.
O que é SDN?
SDN significa Rede Definida por Software. É uma abordagem ao gerenciamento de rede que enfatiza a centralização do controle da rede, permitindo aos administradores gerenciar o comportamento da rede através de uma abstração de software.- Em uma rede tradicional, dispositivos de rede como roteadores, switches e firewalls são configurados e gerenciados individualmente, usando software especializado ou interfaces de linha de comando. Por outro lado, o SDN separa o plano de controle da rede do plano de dados, permitindo que os administradores gerenciem o comportamento da rede por meio de um controlador de software centralizado.
O que é ICMP? Para que é usado?
- ICMP significa Protocolo de Mensagens de Controle da Internet. É um protocolo utilizado para fins de diagnóstico e controle em redes IP. Faz parte do conjunto de protocolos da Internet, operando na camada de rede.
As mensagens ICMP são usadas para diversos fins, incluindo:
Relatório de erros: mensagens ICMP são usadas para relatar erros que ocorrem na rede, como um pacote que não pôde ser entregue ao seu destino.- Ping: ICMP é usado para enviar mensagens de ping, que são usadas para testar se um host ou rede está acessível e para medir o tempo de ida e volta dos pacotes.
- Descoberta de MTU de caminho: o ICMP é usado para descobrir a Unidade Máxima de Transmissão (MTU) de um caminho, que é o maior tamanho de pacote que pode ser transmitido sem fragmentação.
- Traceroute: ICMP é usado pelo utilitário traceroute para rastrear o caminho que os pacotes percorrem na rede.
- Descoberta de roteador: ICMP é usado para descobrir os roteadores em uma rede.
O que é NAT? Como funciona?
NAT significa Tradução de Endereço de Rede. É uma forma de mapear vários endereços privados locais para um público antes de transferir as informações. As organizações que desejam que vários dispositivos empreguem um único endereço IP usam NAT, assim como a maioria dos roteadores domésticos. Por exemplo, o IP privado do seu computador poderia ser 192.168.1.100, mas o seu roteador mapeia o tráfego para o seu IP público (por exemplo, 1.1.1.1). Qualquer dispositivo na Internet veria o tráfego proveniente do seu IP público (1.1.1.1) em vez do seu IP privado (192.168.1.100).
Qual número de porta é usado em cada um dos seguintes protocolos?:- SSH
- SMTP
- HTTP
- DNS
- HTTPS
- FTP
- SFTP
SSH-22- SMTP-25
- HTTP-80
- DNS-53
- HTTPS-443
- FTP - 21
- SFTP-22
Quais fatores afetam o desempenho da rede?
Vários fatores podem afetar o desempenho da rede, incluindo:
Largura de banda: A largura de banda disponível de uma conexão de rede pode impactar significativamente seu desempenho. Redes com largura de banda limitada podem apresentar taxas de transferência de dados lentas, alta latência e baixa capacidade de resposta.- Latência: Latência se refere ao atraso que ocorre quando os dados são transmitidos de um ponto para outro em uma rede. A alta latência pode resultar em desempenho lento da rede, especialmente para aplicações em tempo real, como videoconferência e jogos online.
- Congestionamento de rede: Quando muitos dispositivos estão usando uma rede ao mesmo tempo, pode ocorrer congestionamento de rede, levando a taxas de transferência de dados lentas e baixo desempenho da rede.
- Perda de pacotes: A perda de pacotes ocorre quando pacotes de dados são descartados durante a transmissão. Isso pode resultar em velocidades de rede mais lentas e menor desempenho geral da rede.
- Topologia de rede: O layout físico de uma rede, incluindo o posicionamento de switches, roteadores e outros dispositivos de rede, pode afetar o desempenho da rede.
- Protocolo de rede: Diferentes protocolos de rede têm características de desempenho diferentes, o que pode afetar o desempenho da rede. Por exemplo, o TCP é um protocolo confiável que pode garantir a entrega de dados, mas também pode resultar em desempenho mais lento devido à sobrecarga necessária para verificação de erros e retransmissão.
- Segurança da rede: medidas de segurança como firewalls e criptografia podem afetar o desempenho da rede, especialmente se exigirem poder de processamento significativo ou introduzirem latência adicional.
- Distância: A distância física entre dispositivos em uma rede pode afetar o desempenho da rede, especialmente em redes sem fio onde a intensidade do sinal e a interferência podem afetar a conectividade e as taxas de transferência de dados.
O que é APIPA?
APIPA é um conjunto de endereços IP que os dispositivos são alocados quando o servidor DHCP principal não está acessível
Qual faixa de IP a APIPA usa?
APIPA usa o intervalo de IP: 169.254.0.1 - 169.254.255.254.
Plano de controle e plano de dados
A que se refere "plano de controle"?
O plano de controle é uma parte da rede que decide como rotear e encaminhar pacotes para um local diferente.
A que se refere "plano de dados"?
O plano de dados é uma parte da rede que realmente encaminha os dados/pacotes.
A que se refere o “plano de gestão”?
Refere-se a funções de monitoramento e gerenciamento.
A qual plano (dados, controle, ...) pertence a criação de tabelas de roteamento?
Plano de controle.
Explique o protocolo Spanning Tree (STP).
O que é agregação de links? Por que é usado?
O que é roteamento assimétrico? Como lidar com isso?
Com quais protocolos de sobreposição (túnel) você está familiarizado?
O que é GRE? Como funciona?
O que é VXLAN? Como funciona?
O que é o SNAT?
Explique o OSPF.
OSPF (Open Shortest Path First) é um protocolo de roteamento que pode ser implementado em vários tipos de roteadores. Em geral, o OSPF é compatível com a maioria dos roteadores modernos, incluindo os de fornecedores como Cisco, Juniper e Huawei. O protocolo foi projetado para funcionar com redes baseadas em IP, incluindo IPv4 e IPv6. Além disso, utiliza um design de rede hierárquico, onde os roteadores são agrupados em áreas, com cada área tendo seu próprio mapa de topologia e tabela de roteamento. Esse design ajuda a reduzir a quantidade de informações de roteamento que precisam ser trocadas entre roteadores e a melhorar a escalabilidade da rede.
Os tipos de roteadores OSPF 4 são:
- Roteador Interno
- Roteadores de fronteira de área
- Roteadores de limite de sistemas autônomos
- Roteadores de backbone
Saiba mais sobre os tipos de roteador OSPF: https://www.educba.com/ospf-router-types/
O que é latência?
Latência é o tempo que a informação leva para chegar ao seu destino a partir da fonte.
O que é largura de banda?
Largura de banda é a capacidade de um canal de comunicação medir a quantidade de dados que este pode manipular durante um período de tempo específico. Mais largura de banda implicaria mais manipulação de tráfego e, portanto, mais transferência de dados.
O que é rendimento?
A taxa de transferência refere-se à medição da quantidade real de dados transferidos durante um determinado período de tempo em qualquer canal de transmissão.
Ao realizar uma consulta de pesquisa, o que é mais importante: latência ou taxa de transferência? E como garantir que gerimos a infraestrutura global?
Latência. Para ter uma boa latência, uma consulta de pesquisa deve ser encaminhada para o data center mais próximo.
Ao enviar um vídeo, o que é mais importante: latência ou taxa de transferência? E como garantir isso?
Taxa de transferência. Para ter um bom rendimento, o fluxo de upload deve ser roteado para um link subutilizado.
Que outras considerações (exceto latência e taxa de transferência) existem ao encaminhar solicitações?
- Mantenha os caches atualizados (o que significa que a solicitação pode não ser encaminhada para o data center mais próximo)
Explique Espinha e Folha
"Spine & Leaf" é uma topologia de rede comumente usada em ambientes de data center para conectar vários switches e gerenciar o tráfego de rede com eficiência. Também é conhecida como arquitetura "spine-leaf" ou topologia "leaf-spine". Esse design oferece alta largura de banda, baixa latência e escalabilidade, tornando-o ideal para data centers modernos que lidam com grandes volumes de dados e tráfego. Dentro de uma rede Spine & Leaf existem duas tipologias principais de switches:
- Spine Switches: Os Spine Switches são interruptores de alto desempenho dispostos em uma camada de coluna. Esses switches atuam como o núcleo da rede e normalmente são interconectados com cada switch folha. Cada switch espinhal está conectado a todos os switches leaf no data center.
- Switches Leaf: Os switches Leaf são conectados a dispositivos finais, como servidores, matrizes de armazenamento e outros equipamentos de rede. Cada switch leaf está conectado a cada switch de coluna no data center. Isso cria uma conectividade sem bloqueio e de malha completa entre switches leaf e Spine, garantindo que qualquer switch leaf possa se comunicar com qualquer outro switch leaf com rendimento máximo.
A arquitetura Spine & Leaf tem se tornado cada vez mais popular em data centers devido à sua capacidade de lidar com as demandas da computação em nuvem moderna, virtualização e aplicativos de big data, fornecendo uma infraestrutura de rede escalonável, de alto desempenho e confiável.
O que é congestionamento de rede? O que pode causar isso?
O congestionamento da rede ocorre quando há muitos dados para transmitir em uma rede e ela não tem capacidade suficiente para atender à demanda.
Isso pode levar ao aumento da latência e perda de pacotes. As causas podem ser múltiplas, como alto uso da rede, grandes transferências de arquivos, malware, problemas de hardware ou problemas de design de rede.
Para evitar o congestionamento da rede, é importante monitorar o uso da rede e implementar estratégias para limitar ou gerenciar a demanda.
O que você pode me dizer sobre o formato do pacote UDP? E quanto ao formato do pacote TCP? Como é diferente?
Qual é o algoritmo de espera exponencial? Onde é usado?
Usando o código de Hamming, qual seria a palavra de código para a seguinte palavra de dados 100111010001101?
00110011110100011101
Dê exemplos de protocolos encontrados na camada de aplicação
Protocolo de transferência de hipertexto (HTTP) - usado para páginas da web na internet- Simple Mail Transfer Protocol (SMTP) - transmissão de e-mail
- Rede de Telecomunicações - (TELNET) - emulação de terminal para permitir que um cliente acesse um servidor telnet
- File Transfer Protocol (FTP) - facilita a transferência de arquivos entre quaisquer duas máquinas
- Sistema de Nomes de Domínio (DNS) - tradução de nomes de domínio
- Protocolo de configuração dinâmica de host (DHCP) - aloca endereços IP, máscaras de sub-rede e gateways para hosts
- Simple Network Management Protocol (SNMP) - coleta dados em dispositivos na rede
Dê exemplos de protocolos encontrados na camada de rede
Protocolo de Internet (IP) - auxilia no roteamento de pacotes de uma máquina para outra- Internet Control Message Protocol (ICMP) - permite saber o que está acontecendo, como mensagens de erro e informações de depuração
O que é HSTS?
HTTP Strict Transport Security é uma diretiva de servidor web que informa aos agentes de usuário e navegadores web como lidar com sua conexão por meio de um cabeçalho de resposta enviado no início e de volta ao navegador. Isso força conexões por criptografia HTTPS, desconsiderando qualquer chamada de script para carregar qualquer recurso nesse domínio por HTTP. Leia mais [aqui](https://www.globalsign.com/en/blog/what-is-hsts-and-how-do-i-use-it#:~:text=HTTP%20Strict%20Transport%20Security %20(HSTS,e%20de volta%20para%20o%20navegador.)
Rede - Diversos
O que é a Internet? É o mesmo que a World Wide Web?
A internet se refere a uma rede de redes que transfere enormes quantidades de dados ao redor do mundo.
A World Wide Web é um aplicativo executado em milhões de servidores, na Internet, acessado por meio do que é conhecido como navegador da web.
O que é o ISP?
O ISP (provedor de serviços de Internet) é o provedor de empresas de internet local.
Sistema operacional
Exercícios do sistema operacional
| Nome | Tópico | Objetivo e instruções | Solução | Comentários |
|---|
| Fork 101 | Garfo | Link | Link | |
| Fork 102 | Garfo | Link | Link | |
Sistema operacional - auto -avaliação
O que é um sistema operacional?
Do livro "Sistemas operacionais: três peças fáceis":
"Responsável por facilitar a execução de programas (mesmo permitindo que você execute muitos ao mesmo tempo), permitindo que os programas compartilhem memória, permitindo que os programas interajam com os dispositivos e outras coisas divertidas como essa".
Sistema Operacional - Processo
Você pode explicar o que é um processo?
Um processo é um programa em execução. Um programa é uma ou mais instruções e o programa (ou processo) é executado pelo sistema operacional.
Se você tivesse que projetar uma API para processos em um sistema operacional, como seria essa API?
Apoiaria o seguinte:
Criar - Permitir criar novos processos- Excluir - deixe remover/destruir processos
- Estado - deixe verificar o estado do processo, seja em execução, parado, esperando etc.
- Pare - deixe parar um processo de corrida
Como um processo é criado?
O sistema operacional está lendo o código do programa e quaisquer dados adicionais relevantes- O código do programa é carregado na memória ou mais especificamente, no espaço de endereço do processo.
- A memória é alocada para a pilha do programa (aka em tempo de execução). A pilha também é inicializada pelo sistema operacional com dados como ARGV, ARGC e parâmetros para main ()
- A memória é alocada para a pilha do programa, necessária para dados alocados dinamicamente, como as estruturas de dados vinculadas listas e tabelas de hash
- As tarefas de inicialização de E/S são executadas, como nos sistemas baseados em UNIX/Linux, onde cada processo possui 3 descritores de arquivos (entrada, saída e erro)
- OS está executando o programa, a partir de Main ()
Verdadeiro ou Falso? O carregamento do programa na memória é feito ansiosamente (tudo de uma vez)
Falso. Era verdade no passado, mas os sistemas operacionais de hoje realizam carregamento preguiçoso, o que significa que apenas as peças relevantes necessárias para a execução do processo são carregadas primeiro.
Quais são os diferentes estados de um processo?
Running - está executando instruções- Pronto - está pronto para correr, mas por diferentes razões está em espera
- Bloqueado - está esperando que alguma operação seja concluída, por exemplo, solicitação de disco de E/S
Quais são algumas das razões para um processo ser bloqueado?
Operações de E/S (por exemplo, leitura de um disco)- Esperando por um pacote de uma rede
O que é a comunicação entre processos (IPC)?
A comunicação entre processos (IPC) refere-se aos mecanismos fornecidos por um sistema operacional que permite aos processos gerenciar dados compartilhados.
O que é "tempo compartilhado"?
Mesmo ao usar um sistema com uma CPU física, é possível permitir que vários usuários trabalhem nele e executem programas. Isso é possível com o compartilhamento de tempo, onde os recursos de computação são compartilhados de uma maneira que parece para o usuário, o sistema possui várias CPUs, mas na verdade é simplesmente uma CPU compartilhada aplicando multiprogramação e multitarefa.
O que é "compartilhamento de espaço"?
Um pouco o oposto de compartilhar o tempo. Enquanto, no tempo, o compartilhamento de um recurso é usado por um tempo por uma entidade e, em seguida, o mesmo recurso pode ser usado por outro recurso, no espaço compartilhando o espaço é compartilhado por várias entidades, mas de uma maneira que não está sendo transferida entre eles.
É usado por uma entidade, até que essa entidade decida se livrar dela. Tomemos, por exemplo, armazenamento. No armazenamento, um arquivo é seu, até você decidir excluí -lo.
Qual componente determina qual processo é executado em um determinado momento?
Agendador da CPU
Sistema operacional - memória
O que é "memória virtual" e que propósito serve?
A memória virtual combina a RAM do seu computador com o espaço temporário em seu disco rígido. Quando a RAM é baixa, a memória virtual ajuda a mover dados de RAM para um espaço chamado arquivo de paginação. Mover dados para o arquivo de paginação pode liberar a RAM, para que seu computador possa concluir seu trabalho. Em geral, quanto mais ram o seu computador, mais rápido os programas são executados. https://www.minitool.com/lib/virtual-memory.html
O que é a Pagada de Demand?
A paginação de demanda é uma técnica de gerenciamento de memória em que as páginas são carregadas na memória física somente quando acessadas por um processo. Ele otimiza o uso da memória carregando páginas sob demanda, reduzindo a latência de inicialização e a sobrecarga do espaço. No entanto, introduz alguma latência ao acessar as páginas pela primeira vez. No geral, é uma abordagem econômica para gerenciar recursos de memória em sistemas operacionais.
O que é cópia-on-write?
Copy-on-Write (Cow) é um conceito de gerenciamento de recursos, com o objetivo de reduzir a cópia desnecessária de informações. É um conceito, que é implementado, por exemplo, no Posix Fork Syscall, que cria um processo duplicado do processo de chamada. A ideia:
Se os recursos forem compartilhados entre 2 ou mais entidades (por exemplo, segmentos de memória compartilhada entre 2 processos), os recursos não precisam ser copiados para todas as entidades, mas todas as entidades têm uma permissão de acesso à operação de leitura no recurso compartilhado. (Os segmentos compartilhados são marcados como somente leitura) (pense em todas as entidades tendo um ponteiro para a localização do recurso compartilhado, que pode ser desreferenciado em ler seu valor)- Se uma entidade executaria uma operação de gravação em um recurso compartilhado, surgiria um problema, pois o recurso também seria alterado permanentemente para todas as outras entidades que o compartilham. (Pense em um processo modificando algumas variáveis na pilha ou alocando alguns dados dinamicamente na pilha, essas alterações no recurso compartilhado também se aplicariam a todos os outros processos, esse é definitivamente um comportamento indesejável)
- Apenas como uma solução, se uma operação de gravação estiver prestes a ser executada em um recurso compartilhado, esse recurso é copiado primeiro e depois as alterações são aplicadas.
O que é um kernel e o que ele faz?
O kernel faz parte do sistema operacional e é responsável por tarefas como:
Alocando memória- Agendar processos
- Controle CPU
Verdadeiro ou Falso? Algumas partes do código no kernel são carregadas em áreas protegidas da memória para que os aplicativos não os substituam.
Verdadeiro
O que é Posix?
O POSIX (interface do sistema operacional portátil) é um conjunto de padrões que definem a interface entre um sistema operacional do tipo UNIX e programas de aplicativos.
Explique o que é semáforo e qual o seu papel nos sistemas operacionais.
Um semáforo é um primitivo de sincronização usado em sistemas operacionais e programação simultânea para controlar o acesso a recursos compartilhados. É um tipo de dados variável ou abstrato que atua como um contador ou um mecanismo de sinalização para gerenciar o acesso a recursos por vários processos ou threads.
O que é cache? O que é buffer?
Cache: o cache geralmente é usado quando os processos estão lendo e escrevendo no disco para tornar o processo mais rápido, tornando os dados semelhantes usados por diferentes programas facilmente acessíveis. Buffer: Local reservado na RAM, que é usado para manter dados para fins temporários.
Virtualização
O que é virtualização?
A virtualização usa o software para criar uma camada de abstração sobre o hardware do computador, que permite que os elementos de hardware de um único computador - processadores, memória, armazenamento e muito mais - sejam divididos em vários computadores virtuais, comumente chamados de máquinas virtuais (VMs).
O que é um hipervisor?
Red Hat: "Um hipervisor é um software que cria e executa máquinas virtuais (VMs). Um hipervisor, às vezes chamado de monitor de máquina virtual (VMM), isola o sistema operacional do hipervisor e os recursos das máquinas virtuais e permite a criação e o gerenciamento daqueles Vm. "
Leia mais aqui
Que tipos de hipervisores existem?
Hipervisores hospedados e hipervisores de metal nu.
Quais são as vantagens e desvantagens do hipervisor nua-metal sobre um hipervisor hospedado?
Devido a ter seus próprios drivers e um acesso direto aos componentes de hardware, um hipervisor Baremetal geralmente terá melhores desempenhos, juntamente com estabilidade e escalabilidade.
Por outro lado, provavelmente haverá alguma limitação em relação ao carregamento (qualquer) drivers, para que um hipervisor hospedado geralmente se beneficie de ter uma melhor compatibilidade de hardware.
Que tipos de virtualização existem?
Sistema operacional Virtualização Funções de Rede de Virtualização Virtualização Virtualização de Desktop
A contêinerização é um tipo de virtualização?
Sim, é uma virtualização no nível do sistema operacional, onde o kernel é compartilhado e permite usar várias instâncias de espaços de usuário isolados.
Como a introdução de máquinas virtuais mudou a indústria e a maneira como as aplicações foram implantadas?
A introdução de máquinas virtuais permitiu às empresas implantar vários aplicativos de negócios no mesmo hardware, enquanto cada aplicativo é separado um do outro de maneira segura, onde cada um está em execução em seu próprio sistema operacional separado.
Máquinas Virtuais
Precisamos de máquinas virtuais na era dos contêineres? Eles ainda são relevantes?
Sim, as máquinas virtuais ainda são relevantes, mesmo na era dos contêineres. Enquanto os contêineres fornecem uma alternativa leve e portátil às máquinas virtuais, eles têm certas limitações. As máquinas virtuais ainda importam porque oferecem isolamento e segurança, podem executar diferentes sistemas operacionais e são bons para aplicativos legados. As limitações de contêineres, por exemplo, estão compartilhando o kernel do host.
Prometeu
O que é Prometeu? Quais são alguns dos principais recursos de Prometheus?
O Prometheus é um popular kit de ferramentas de monitoramento e alerta de sistemas de código aberto, originalmente desenvolvido no SoundCloud. Ele foi projetado para coletar e armazenar dados de séries temporais e permitir a consulta e análise desses dados usando um poderoso idioma de consulta chamado Promql. O Prometeu é frequentemente usado para monitorar aplicativos nativos de nuvem, microsserviços e outras infraestruturas modernas.
Algumas das principais características do Prometeu incluem:
1. Data model: Prometheus uses a flexible data model that allows users to organize and label their time-series data in a way that makes sense for their particular use case. Labels are used to identify different dimensions of the data, such as the source of the data or the environment in which it was collected.
2. Pull-based architecture: Prometheus uses a pull-based model to collect data from targets, meaning that the Prometheus server actively queries its targets for metrics data at regular intervals. This architecture is more scalable and reliable than a push-based model, which would require every target to push data to the server.
3. Time-series database: Prometheus stores all of its data in a time-series database, which allows users to perform queries over time ranges and to aggregate and analyze their data in various ways. The database is optimized for write-heavy workloads, and can handle a high volume of data with low latency.
4. Alerting: Prometheus includes a powerful alerting system that allows users to define rules based on their metrics data and to send alerts when certain conditions are met. Alerts can be sent via email, chat, or other channels, and can be customized to include specific details about the problem.
5. Visualization: Prometheus has a built-in graphing and visualization tool, called PromDash, which allows users to create custom dashboards to monitor their systems and applications. PromDash supports a variety of graph types and visualization options, and can be customized using CSS and JavaScript.
No geral, o Prometheus é uma ferramenta poderosa e flexível para monitorar e analisar sistemas e aplicações e é amplamente utilizada no setor para monitoramento e observabilidade nativos da nuvem.
Em que cenários pode ser melhor não usar o Prometeu?
Da documentação do Prometheus: "Se você precisar de 100% de precisão, como o faturamento por solicitação".
Descreva a arquitetura e componentes do Prometheus
A arquitetura Prometheus consiste em quatro componentes principais:
1. Prometheus Server: The Prometheus server is responsible for collecting and storing metrics data. It has a simple built-in storage layer that allows it to store time-series data in a time-ordered database.
2. Client Libraries: Prometheus provides a range of client libraries that enable applications to expose their metrics data in a format that can be ingested by the Prometheus server. These libraries are available for a range of programming languages, including Java, Python, and Go.
3. Exporters: Exporters are software components that expose existing metrics from third-party systems and make them available for ingestion by the Prometheus server. Prometheus provides exporters for a range of popular technologies, including MySQL, PostgreSQL, and Apache.
4. Alertmanager: The Alertmanager component is responsible for processing alerts generated by the Prometheus server. It can handle alerts from multiple sources and provides a range of features for deduplicating, grouping, and routing alerts to appropriate channels.
No geral, a arquitetura de Prometheus foi projetada para ser altamente escalável e resiliente. As bibliotecas de servidor e clientes podem ser implantadas de maneira distribuída para apoiar o monitoramento em ambientes altamente dinâmicos em larga escala e dinâmicos
Você pode comparar Prometeu com outras soluções como o InfluxDB, por exemplo?
Comparado a outras soluções de monitoramento, como o InfluxDB, o Prometheus é conhecido por seu alto desempenho e escalabilidade. Ele pode lidar com grandes volumes de dados e pode ser facilmente integrado a outras ferramentas no ecossistema de monitoramento. O InfluxDB, por outro lado, é conhecido por sua facilidade de uso e simplicidade. Possui uma interface amigável e fornece APIs fáceis de usar para coletar e consultar dados.
Outra solução popular, Nagios, é um sistema de monitoramento mais tradicional que se baseia em um modelo baseado em push para coletar dados. Nagios existe há muito tempo e é conhecido por sua estabilidade e confiabilidade. No entanto, em comparação com o Prometeu, o Nagios carece de alguns dos recursos mais avançados, como o modelo de dados multidimensional e a poderosa linguagem de consulta.
No geral, a escolha de uma solução de monitoramento depende das necessidades e requisitos específicos da organização. Embora o Prometheus seja uma ótima opção para monitoramento e alerta em larga escala, o InfluxDB pode ser um ajuste melhor para ambientes menores que requerem facilidade de uso e simplicidade. Nagios continua sendo uma escolha sólida para organizações que priorizam a estabilidade e a confiabilidade em relação aos recursos avançados.
O que é um alerta?
Em Prometeu, um alerta é uma notificação acionada quando uma condição ou limite específico é atingido. Os alertas podem ser configurados para acionar quando certas métricas cruzam um determinado limite ou quando ocorrem eventos específicos. Depois que um alerta é acionado, ele pode ser roteado para vários canais, como email, pager ou bate -papo, para notificar equipes ou indivíduos relevantes para tomar as medidas apropriadas. Os alertas são um componente crítico de qualquer sistema de monitoramento, pois permitem que as equipes detectem e respondam proativamente aos problemas antes de afetarem os usuários ou causarem o tempo de inatividade do sistema. O que é uma instância? O que é um trabalho?
Em Prometheus, uma instância refere -se a um único alvo que está sendo monitorado. Por exemplo, um único servidor ou serviço. Um trabalho é um conjunto de instâncias que desempenham a mesma função, como um conjunto de servidores da Web que servem o mesmo aplicativo. Os trabalhos permitem definir e gerenciar um grupo de metas juntos.
Em essência, uma instância é um alvo individual que o Prometeu coleta métricas, enquanto um trabalho é uma coleção de instâncias semelhantes que podem ser gerenciadas como um grupo.
Quais são os tipos de métricas principais que a Prometheus suporta?
O Prometeu suporta vários tipos de métricas, incluindo: 1. Counter: A monotonically increasing value used for tracking counts of events or samples. Examples include the number of requests processed or the total number of errors encountered. 2. Gauge: A value that can go up or down, such as CPU usage or memory usage. Unlike counters, gauge values can be arbitrary, meaning they can go up and down based on changes in the system being monitored. 3. Histogram: A set of observations or events that are divided into buckets based on their value. Histograms help in analyzing the distribution of a metric, such as request latencies or response sizes. 4. Summary: A summary is similar to a histogram, but instead of buckets, it provides a set of quantiles for the observed values. Summaries are useful for monitoring the distribution of request latencies or response sizes over time.
O Prometheus também suporta várias funções e operadores para agregar e manipular métricas, como Sum, Max, Min e Taxa. Esses recursos o tornam uma ferramenta poderosa para monitorar e alertar as métricas do sistema.
O que é um exportador? Para que é usado?
O exportador serve como uma ponte entre o sistema de terceiros ou a aplicação e o Prometheus, possibilitando a Prometheus monitorar e coletar dados desse sistema ou aplicação. O exportador atua como um servidor, ouvindo uma porta de rede específica para solicitações de Prometheus para raspar métricas. Ele coleta métricas do sistema ou aplicação de terceiros e as transforma em um formato que pode ser entendido por Prometheus. O exportador expõe essas métricas a Prometheus por meio de um terminal HTTP, disponibilizando -as para coleta e análise.
Os exportadores são comumente usados para monitorar vários tipos de componentes de infraestrutura, como bancos de dados, servidores da Web e sistemas de armazenamento. Por exemplo, existem exportadores disponíveis para monitorar bancos de dados populares como MySQL e PostgreSQL, bem como servidores da Web como Apache e Nginx.
No geral, os exportadores são um componente crítico do ecossistema Prometheus, permitindo o monitoramento de uma ampla gama de sistemas e aplicações e fornecendo um alto grau de flexibilidade e extensibilidade à plataforma.
Quais práticas recomendadas de Prometheus?
Aqui estão três deles: 1. Label carefully: Careful and consistent labeling of metrics is crucial for effective querying and alerting. Labels should be clear, concise, and include all relevant information about the metric. 2. Keep metrics simple: The metrics exposed by exporters should be simple and focus on a single aspect of the system being monitored. This helps avoid confusion and ensures that the metrics are easily understandable by all members of the team. 3. Use alerting sparingly: While alerting is a powerful feature of Prometheus, it should be used sparingly and only for the most critical issues. Setting up too many alerts can lead to alert fatigue and result in important alerts being ignored. It is recommended to set up only the most important alerts and adjust the thresholds over time based on the actual frequency of alerts.
Como obter solicitações totais em um determinado período de tempo?
Para obter as solicitações totais em um determinado período de tempo usando o Prometeu, você pode usar a função * soma * junto com a função * taxa *. Aqui está um exemplo de consulta que fornecerá o número total de solicitações na última hora: sum(rate(http_requests_total[1h]))
Nesta consulta, http_requests_total é o nome da métrica que rastreia o número total de solicitações HTTP, e a função de taxa calcula a taxa por segundo de solicitações na última hora. A função SUM então somente todas as solicitações para fornecer o número total de solicitações na última hora.
Você pode ajustar o intervalo de tempo alterando a duração na função de taxa . Por exemplo, se você quiser obter o número total de solicitações no último dia, poderá alterar a função para avaliar (http_requests_total [1d]) .
O que significa HA em Prometeu?
HA significa alta disponibilidade. Isso significa que o sistema foi projetado para ser altamente confiável e sempre disponível, mesmo diante de falhas ou outros problemas. Na prática, isso normalmente envolve a criação de várias instâncias de Prometeu e garantir que todos sejam sincronizados e capazes de trabalhar juntos sem problemas. Isso pode ser alcançado através de uma variedade de técnicas, como balanceamento de carga, replicação e mecanismos de failover. Ao implementar o HA em Prometeu, os usuários podem garantir que seus dados de monitoramento estejam sempre disponíveis e atualizados, mesmo diante de falhas de hardware ou software, problemas de rede ou outros problemas que, de outra forma, poderiam causar tempo de inatividade ou perda de dados.
Como você se junta a duas métricas?
Em Prometheus, ingressar em duas métricas pode ser alcançada usando a função * junção () *. A função * junção () * combina duas ou mais séries temporais com base nos valores dos rótulos. São necessários dois argumentos obrigatórios: *na *e *tabela *. O argumento on especifica os rótulos para ingressar * no * e no argumento * tabela * especifica a série temporal para participar. Aqui está um exemplo de como ingressar em duas métricas usando a função junção () :
sum_series(
join(
on(service, instance) request_count_total,
on(service, instance) error_count_total,
)
)
Neste exemplo, a função junção () combina as séries temporais request_count_total e error_count_total com base em seus valores de serviço e etiqueta de instância . A função SUM_SERIES () calcula a soma da série temporal resultante
Como escrever uma consulta que retorne o valor de um rótulo?
Para escrever uma consulta que retorne o valor de um rótulo em Prometheus, você pode usar a função * LABEL_VALUES *. A função * label_values * leva dois argumentos: o nome do rótulo e o nome da métrica. Por exemplo, se você possui uma métrica chamada http_requests_total com um rótulo chamado método e deseja retornar todos os valores do rótulo do método , você pode usar a seguinte consulta:
label_values(http_requests_total, method)
Isso retornará uma lista de todos os valores para o rótulo do método na métrica http_requests_total . Você pode usar esta lista em consultas adicionais ou para filtrar seus dados.
Como você converte CPU_USER_SECONDS para uso da CPU em porcentagem?
Para converter * CPU_USER_SECONDS * para o uso da CPU em porcentagem, você precisa dividi -lo pelo tempo total decorrido e pelo número de núcleos da CPU e, em seguida, multiplicar por 100. A fórmula é a seguinte: 100 * sum(rate(process_cpu_user_seconds_total{job="<job-name>"}[<time-period>])) by (instance) / (<time-period> * <num-cpu-cores>)
Aqui, é o nome do trabalho que você deseja consultar, é o intervalo de tempo que você deseja consultar (por exemplo, 5m , 1h ) e é o número de núcleos da CPU na máquina que você está consultando.
Por exemplo, para obter o uso da CPU em porcentagem nos últimos 5 minutos para um trabalho chamado My-Job em uma máquina com 4 núcleos de CPU, você pode usar a seguinte consulta:
100 * sum(rate(process_cpu_user_seconds_total{job="my-job"}[5m])) by (instance) / (5m * 4)
Ir
Quais são algumas das características da linguagem de programação Go?
- Digitação forte e estática - o tipo de variável não pode ser alterado ao longo do tempo e elas precisam ser definidas no tempo de compilação
- simplicidade
- de compilação rápida tempos
de - concorrência
- de lixo
- de
- simulta
- será compilado em um binário. Muito útil para gerenciamento de versão em tempo de execução.
GO também tem uma boa comunidade.
Qual é a diferença entre var x int = 2 e x := 2 ?
O resultado é o mesmo, uma variável com o valor 2.
Com var x int = 2 estamos definindo o tipo de variável como inteiro enquanto com x := 2 estamos deixando ir descobrir por si só o tipo.
Verdadeiro ou Falso? No Go, podemos redeclare variáveis e, uma vez declaramos, devemos usá -lo.
Falso. Não podemos redeclare variáveis, mas sim, devemos usar variáveis declaradas.
Que bibliotecas de Go você usou?
Isso deve ser respondido com base no seu uso, mas alguns exemplos são:
Qual é o problema com o seguinte bloco de código? Como consertar isso? func main() {
var x float32 = 13.5
var y int
y = x
}
O bloco a seguir do código tenta converter o número inteiro 101 em uma string, mas, em vez disso, obtemos "e". Por que é que? Como consertar isso? package main
import "fmt"
func main () {
var x int = 101
var y string
y = string ( x )
fmt . Println ( y )
}
Parece qual valor Unicode está definido em 101 e o usa para converter o número inteiro em uma string. Se você quiser obter "101", use o pacote "strConv" e substitua y = string(x) por y = strconv.Itoa(x)
O que há de errado com o seguinte código?: package main
func main() {
var x = 2
var y = 3
const someConst = x + y
}
As constantes em Go só podem ser declaradas usando expressões constantes. Mas x , y e sua soma é variável.
const initializer x + y is not a constant
Qual será a saída do seguinte bloco de código?: package main
import "fmt"
const (
x = iota
y = iota
)
const z = iota
func main () {
fmt . Printf ( "%v n " , x )
fmt . Printf ( "%v n " , y )
fmt . Printf ( "%v n " , z )
}
O identificador de IOTA de Go é usado em declarações const para simplificar as definições de incrementação de números. Como pode ser usado em expressões, fornece uma generalidade além da das enumerações simples.
x e y no primeiro grupo IOTA, z no segundo.
Página IOTA em Go Wiki
Para que _ é usado para ir?
Evita ter que declarar todas as variáveis para os valores de retorno. É chamado de identificador em branco.
Responda em So
Qual será a saída do seguinte bloco de código?: package main
import "fmt"
const (
_ = iota + 3
x
)
func main () {
fmt . Printf ( "%v n " , x )
}
Como o primeiro iota é declarado com o valor 3 ( + 3 ), o próximo tem o valor 4
Qual será a saída do seguinte bloco de código?: package main
import (
"fmt"
"sync"
"time"
)
func main () {
var wg sync. WaitGroup
wg . Add ( 1 )
go func () {
time . Sleep ( time . Second * 2 )
fmt . Println ( "1" )
wg . Done ()
}()
go func () {
fmt . Println ( "2" )
}()
wg . Wait ()
fmt . Println ( "3" )
}
Saída: 2 1 3
Arritcle sobre Sync/WaitGroup
Golang Package Sync
Qual será a saída do seguinte bloco de código?: package main
import (
"fmt"
)
func mod1 ( a [] int ) {
for i := range a {
a [ i ] = 5
}
fmt . Println ( "1:" , a )
}
func mod2 ( a [] int ) {
a = append ( a , 125 ) // !
for i := range a {
a [ i ] = 5
}
fmt . Println ( "2:" , a )
}
func main () {
s1 := [] int { 1 , 2 , 3 , 4 }
mod1 ( s1 )
fmt . Println ( "1:" , s1 )
s2 := [] int { 1 , 2 , 3 , 4 }
mod2 ( s2 )
fmt . Println ( "2:" , s2 )
}
Saída:
1 [5 5 5 5]
1 [5 5 5 5]
2 [5 5 5 5 5]
2 [1 2 3 4]
No mod1 A é o link e, quando estamos usando a[i] , estamos alterando o valor s1 para. Mas no mod2 , append cria uma nova fatia e estamos mudando apenas a valor, não s2 .
Arritcle sobre matrizes, postagem de blog sobre append
Qual será a saída do seguinte bloco de código?: package main
import (
"container/heap"
"fmt"
)
// An IntHeap is a min-heap of ints.
type IntHeap [] int
func ( h IntHeap ) Len () int { return len ( h ) }
func ( h IntHeap ) Less ( i , j int ) bool { return h [ i ] < h [ j ] }
func ( h IntHeap ) Swap ( i , j int ) { h [ i ], h [ j ] = h [ j ], h [ i ] }
func ( h * IntHeap ) Push ( x interface {}) {
// Push and Pop use pointer receivers because they modify the slice's length,
// not just its contents.
* h = append ( * h , x .( int ))
}
func ( h * IntHeap ) Pop () interface {} {
old := * h
n := len ( old )
x := old [ n - 1 ]
* h = old [ 0 : n - 1 ]
return x
}
func main () {
h := & IntHeap { 4 , 8 , 3 , 6 }
heap . Init ( h )
heap . Push ( h , 7 )
fmt . Println (( * h )[ 0 ])
}
Saída: 3
Pacote de contêiner/heap Golang
Mongo
Quais são as vantagens do MongoDB? Ou, em outras palavras, por que escolher o MongoDB e não outra implementação do NOSQL?
As vantagens do MongoDB são as seguintes:
- Esquema
- Fácil de ampliar
- Nenhum complexo se junta
- Estrutura de um único objeto é claro
Qual é a diferença entre SQL e NoSQL?
A principal diferença é que os bancos de dados SQL são estruturados (os dados são armazenados na forma de tabelas com linhas e colunas - como uma tabela de planilha do Excel), enquanto o NOSQL não é estruturado, e o armazenamento de dados pode variar dependendo de como o NOSQL db é configurado, como par de valores-chave, orientação a documentos, etc.
Em que cenários você prefere usar o NoSQL/Mongo sobre o SQL?
Dados heterogêneos que mudam frequentemente- A consistência e a integridade dos dados não são a principal prioridade
- Melhor se o banco de dados precisar escalar rapidamente
O que é um documento? O que é uma coleção?
Um documento é um registro no MongoDB, que é armazenado no formato BSON (Binário JSON) e é a unidade básica de dados no MongoDB.- Uma coleção é um grupo de documentos relacionados armazenados em um único banco de dados em MongoDB.
O que é um agregador?
- Um agregador é uma estrutura no MongoDB que executa operações em um conjunto de dados para retornar um único resultado calculado.
O que é melhor? Documentos incorporados ou referenciados?
- Não há uma resposta definitiva para o que é melhor, depende do caso de uso e requisitos específicos. Algumas explicações: os documentos incorporados fornecem atualizações atômicas, enquanto os documentos referenciados permitem uma melhor normalização.
Você realizou otimizações de recuperação de dados em Mongo? Caso contrário, você pode pensar em maneiras de otimizar uma recuperação lenta de dados?
- Algumas maneiras de otimizar a recuperação de dados no MongoDB são: indexação, design de esquema adequado, otimização de consultas e balanceamento de carga do banco de dados.
Consultas
Explique esta consulta: db.books.find({"name": /abc/})
Explique esta consulta: db.books.find().sort({x:1})
Qual é a diferença entre find () e find_one ()?
find() retorna todos os documentos que correspondem às condições da consulta.- find_one () retorna apenas um documento que corresponde às condições da consulta (ou nulo se nenhuma correspondência for encontrada).
Como você pode exportar dados do Mongo DB?
MongoExport- linguagens de programação
SQL
Exercícios SQL
| Nome | Tópico | Objetivo e instruções | Solução | Comentários |
|---|
| Funções vs. comparações | Melhorias de consulta | Exercício | Solução | |
Auto -avaliação SQL
O que é SQL?
O SQL (linguagem de consulta estruturada) é uma linguagem padrão para bancos de dados relacionais (como MySQL, MariaDB, ...).
É usado para leitura, atualização, remoção e criação de dados em um banco de dados relacional.
Como o SQL é diferente de NoSQL
A principal diferença é que os bancos de dados SQL são estruturados (os dados são armazenados na forma de tabelas com linhas e colunas - como uma tabela de planilha do Excel) enquanto o NOSQL é não estruturado, e o armazenamento de dados pode variar dependendo de como o NOSQL db é configurado, como par de valores-chave, orientação a documentos, etc.
Quando é melhor usar o SQL? Sem SQL?
SQL - Melhor usado quando a integridade dos dados é crucial. O SQL é normalmente implementado com muitas empresas e áreas no campo financeiro devido à sua conformidade com ácido.
NOSQL - Ótimo se você precisar escalar as coisas rapidamente. O NOSQL foi projetado com aplicativos da Web em mente, por isso funciona muito bem se você precisar espalhar rapidamente as mesmas informações para vários servidores
Além disso, como o NOSQL não adere à tabela estrita com colunas e linhas estrutura que os bancos de dados relacionais exigem, você pode armazenar diferentes tipos de dados juntos.
SQL prático - básico
Para essas perguntas, usaremos as tabelas de clientes e pedidos mostradas abaixo:
Clientes
| Customer_id | Customer_name | Itens_in_cart | Cash_SPENT_TO_DATE |
|---|
| 100204 | João Smith | 0 | 20h00 |
| 100205 | Jane Smith | 3 | 40,00 |
| 100206 | Bobby Frank | 1 | 100.20 |
Ordens
| Customer_id | Order_id | Item | Preço | Date_sold |
|---|
| 100206 | A123 | Patinho de borracha | 2.20 | 2019-09-18 |
| 100206 | A123 | Banho de espuma | 8h00 | 2019-09-18 |
| 100206 | Q987 | 80 pacote tp | 90,00 | 2019-09-20 |
| 100205 | Z001 | Comida de gato - atum peixe | 10h00 | 2019-08-05 |
| 100205 | Z001 | Comida de gato - frango | 10h00 | 2019-08-05 |
| 100205 | Z001 | Comida de gato - carne bovina | 10h00 | 2019-08-05 |
| 100205 | Z001 | Comida de gato - Questy Quesadilla | 10h00 | 2019-08-05 |
| 100204 | X202 | Café | 20h00 | 2019-04-29 |
Como eu selecionaria todos os campos desta tabela?
Selecione *
De clientes;
Quantos itens há no carrinho de John?
Selecione itens_in_cart
De clientes
Onde cliente_name = "John Smith";
Qual é a soma de todo o dinheiro gasto em todos os clientes?
Selecione Sum (Cash_SPENT_TO_DATE) como SUM_CASH
De clientes;
Quantas pessoas têm itens em seu carrinho?
Selecione a contagem (1) como número_of_people_w_items
De clientes
onde itens_in_cart> 0;
Como você se juntaria à tabela do cliente na tabela de pedidos?
Você se juntaria a eles na chave única. Nesse caso, a chave exclusiva é cliente_id na tabela de clientes e na tabela de pedidos
Como você mostraria qual cliente encomendou quais itens?
Selecione C.Customer_Name, O.Item
Dos clientes c
Pedidos de junção de esquerda o
Em c.customer_id = o.customer_id;
Usando uma declaração com a declaração, como você mostraria quem pediu comida de gato e a quantidade total de dinheiro gasto?
com cat_food como (
Selecione Customer_id, Sum (Price) como Total_price
De ordens
Onde item como "%de gato alimento%"
Grupo por Customer_id
)
Selecione Customer_Name, Total_Price
Dos clientes c
INNER JONE CAT_FOOD F
Em c.customer_id = f.customer_id
onde c.customer_id in (selecione Customer_id de Cat_Food);
Embora essa tenha sido uma afirmação simples, a cláusula "com" realmente brilha quando uma consulta complexa precisa ser executada em uma mesa antes de se juntar a outra. Com as declarações, é bom, porque você cria uma pseudo -temperatura ao executar sua consulta, em vez de criar uma tabela totalmente nova.
A soma de todas as compras de comida de gato não estava prontamente disponível, então usamos uma declaração com a declaração para criar a tabela pseudo para recuperar a soma dos preços gastos por cada cliente e depois participar da tabela normalmente.
Qual das consultas a seguir você usaria? SELECT count(*) SELECT count(*)
FROM shawarma_purchases FROM shawarma_purchases
WHERE vs. WHERE
YEAR(purchased_at) == '2017' purchased_at >= '2017-01-01' AND
purchased_at <= '2017-31-12'
SELECT count(*) FROM shawarma_purchases WHERE purchased_at >= '2017-01-01' AND purchased_at <= '2017-31-12'
Quando você usa uma função ( YEAR(purchased_at) ), ele precisa digitalizar todo o banco de dados, em oposição ao uso de índices e basicamente a coluna como é, em seu estado natural.
OpenStack
Com quais componentes/projetos do OpenStack você está familiarizado?
Você pode me dizer pelo que cada um dos seguintes serviços/projetos é responsável?:- Nova
- Nêutron
- Cinza
- Olhar
- Pedra angular
Nova - Gerenciar instâncias virtuais- Neutron - Gerenciar redes fornecendo a rede como um serviço (NAAS)
- Cinder - Block Storage
- Olhe - Gerencie imagens para máquinas e contêineres virtuais (pesquise, obtenha e registre)
- Keystone - Serviço de autenticação em toda a nuvem
Identifique o serviço/projeto usado para cada um dos seguintes:- Instâncias de copiar ou instantâneo
- GUI para visualizar e modificar recursos
- Bloquear armazenamento
- Gerenciar instâncias virtuais
Olhar - Serviço de imagens. Também usado para copiar ou instantâneos instâncias- Horizon - GUI para visualizar e modificar recursos
- Cinder - Block Storage
- Nova - Gerenciar instâncias virtuais
O que é um inquilino/projeto?
Determinar verdadeiro ou falso:- OpenStack é gratuito para usar
- O serviço responsável pela rede é olhar
- O objetivo do inquilino/projeto é compartilhar recursos entre diferentes projetos e usuários do OpenStack
Descreva em detalhes como você traz uma instância com um IP flutuante
Você recebe uma ligação de um cliente dizendo: "Eu posso pingar minha instância, mas não consigo conectar (ssh)". Qual pode ser o problema?
Que tipos de redes o OpenStack suporta?
Como você depurar problemas de armazenamento OpenStack? (Ferramentas, logs, ...)
Como você depurar problemas de computação OpenStack? (Ferramentas, logs, ...)
OpenStack Deployment & Triboo
Você já implantou o OpenStack no passado? Se sim, você pode descrever como você fez isso?
Você está familiarizado com o Triplo? Como é diferente de Devstack ou PackStack?
Você pode ler sobre o Triplo bem aqui
OpenStack Compute
Você pode descrever a Nova em detalhes?
Usado para provisionar e gerenciar instâncias virtuais- Ele suporta multi-cinemas em diferentes níveis-registro, controle do usuário final, auditoria, etc.
- Altamente escalável
- A autenticação pode ser feita usando sistema interno ou LDAP
- Suporta vários tipos de armazenamento em bloco
- Tenta ser hardware e hipervisor Agnostice
O que você sabe sobre a arquitetura e componentes da Nova?
Nova -Api - o servidor que serve metadados e computação APIs- Os diferentes componentes da Nova se comunicam usando uma fila (normalmente RabbitMQ) e um banco de dados
- Uma solicitação de criação de uma instância é inspecionada por Nova-Scheduler, que determina onde a instância será criada e executando
- Nova Compute é o componente responsável por se comunicar com o hipervisor para criar a instância e gerenciar seu ciclo de vida
OpenStack Networking (Neutron)
Explique o nêutron em detalhes
Um dos principais componentes do OpenStack e um projeto independente- A nêutrons focou em entregar a rede como um serviço
- Com o Neutron, os usuários podem configurar redes na nuvem e configurar e gerenciar uma variedade de serviços de rede
- O nêutrons interage com:
Keystone - Autorizar chamadas de API
- Nova - Nova se comunica com o Neutron para conectar o NICS em uma rede
- Horizon - suporta entidades de rede no painel e também fornece uma visão de topologia, que inclui detalhes de rede
Explique cada um dos seguintes componentes:- nêutrons-dhcp-agent
- nêutrons-l3-agente
- agente de nêutrons-medering
- nêutron-*-agtent
- Nutron-Server
Nutron-L3-Agent-L3/NAT Encaminhamento (fornece acesso externo à rede para VMs, por exemplo)- Neutron-DHCP-Agent-Serviços DHCP
- AGENT-AGENT-AGENT-L3 Medição de tráfego
- Neutron-*-Agtent-gerencia a configuração local do vswitch em cada computação (com base no plug-in escolhido)
- Nutron -Server - expõe a API de rede e passa solicitações para outros plugins, se necessário
Explique estes tipos de rede:- Rede de gerenciamento
- Rede de convidados
- Rede de API
- Rede externa
Rede de gerenciamento - usada para comunicação interna entre os componentes do OpenStack. Qualquer endereço IP nesta rede é acessível apenas dentro do datacetner- Rede de convidados - usada para comunicação entre instâncias/VMs
- Rede de API - usada para comunicação da API de serviços. Qualquer endereço IP nesta rede é acessível ao público
- Rede externa - usada para comunicação pública. Qualquer endereço IP nesta rede é acessível por qualquer pessoa na Internet
Em que ordem você deve remover as seguintes entidades:- Rede
- Porta
- Roteador
- Subnet
- Rede
- de roteador
- de sub -rede
- de porta
Existem muitas razões para isso. Por exemplo: você não pode remover o roteador se houver portas ativas atribuídas a ele.
O que é uma rede de provedores?
Quais componentes e serviços existem para L2 e L3?
O que é o plug-in ML2? Explique sua arquitetura
Qual é o agente L2? Como funciona e pelo que é responsável?
Qual é o agente L3? Como funciona e pelo que é responsável?
Explique pelo que o agente de metadados é responsável
Quais são os suportes de neutrons de entidades de networking?
How do you debug OpenStack networking issues? (tools, logs, ...)
OpenStack - Glance
Explain Glance in detail
Glance is the OpenStack image service- It handles requests related to instances disks and images
- Glance also used for creating snapshots for quick instances backups
- Users can use Glance to create new images or upload existing ones
Describe Glance architecture
glance-api - responsible for handling image API calls such as retrieval and storage. It consists of two APIs: 1. registry-api - responsible for internal requests 2. user API - can be accessed publicly- glance-registry - responsible for handling image metadata requests (eg size, type, etc). This component is private which means it's not available publicly
- metadata definition service - API for custom metadata
- database - for storing images metadata
- image repository - for storing images. This can be a filesystem, swift object storage, HTTP, etc.
OpenStack - Swift
Explain Swift in detail
Swift is Object Store service and is an highly available, distributed and consistent store designed for storing a lot of data- Swift is distributing data across multiple servers while writing it to multiple disks
- One can choose to add additional servers to scale the cluster. All while swift maintaining integrity of the information and data replications.
Can users store by default an object of 100GB in size?
Not by default. Object Storage API limits the maximum to 5GB per object but it can be adjusted.
Explain the following in regards to Swift:
Container - Defines a namespace for objects.- Account - Defines a namespace for containers
- Object - Data content (eg image, document, ...)
Verdadeiro ou Falso? there can be two objects with the same name in the same container but not in two different containers
Falso. Two objects can have the same name if they are in different containers.
OpenStack - Cinder
Explain Cinder in detail
Cinder is OpenStack Block Storage service- It basically provides used with storage resources they can consume with other services such as Nova
- One of the most used implementations of storage supported by Cinder is LVM
- From user perspective this is transparent which means the user doesn't know where, behind the scenes, the storage is located or what type of storage is used
Describe Cinder's components
cinder-api - receives API requests- cinder-volume - manages attached block devices
- cinder-scheduler - responsible for storing volumes
OpenStack - Keystone
Can you describe the following concepts in regards to Keystone?- Papel
- Tenant/Project
- Serviço
- Endpoint
- Símbolo
Role - A list of rights and privileges determining what a user or a project can perform- Tenant/Project - Logical representation of a group of resources isolated from other groups of resources. It can be an account, organization, ...
- Service - An endpoint which the user can use for accessing different resources
- Endpoint - a network address which can be used to access a certain OpenStack service
- Token - Used for access resources while describing which resources can be accessed by using a scope
What are the properties of a service? In other words, how a service is identified?
Usando:
Nome- Número de identificação
- Tipo
- Descrição
Explain the following: - PublicURL - InternalURL - AdminURL
PublicURL - Publicly accessible through public internet- InternalURL - Used for communication between services
- AdminURL - Used for administrative management
What is a service catalog?
A list of services and their endpoints
OpenStack Advanced - Services
Describe each of the following services- Rápido
- Saara
- Irônico
- Tesouro
- Aodh
- Ceilometer
Swift - highly available, distributed, eventually consistent object/blob store- Sahara - Manage Hadoop Clusters
- Ironic - Bare Metal Provisioning
- Trove - Database as a service that runs on OpenStack
- Aodh - Alarms Service
- Ceilometer - Track and monitor usage
Identify the service/project used for each of the following:- Database as a service which runs on OpenStack
- Bare Metal Provisioning
- Track and monitor usage
- Alarms Service
- Manage Hadoop Clusters
- highly available, distributed, eventually consistent object/blob store
Database as a service which runs on OpenStack - Trove- Bare Metal Provisioning - Ironic
- Track and monitor usage - Ceilometer
- Alarms Service - Aodh
- Manage Hadoop Clusters
- Manage Hadoop Clusters - Sahara
- highly available, distributed, eventually consistent object/blob store - Swift
OpenStack Advanced - Keystone
Can you describe Keystone service in detail?
You can't have OpenStack deployed without Keystone- It Provides identity, policy and token services
- The authentication provided is for both users and services
- The authorization supported is token-based and user-based.
- There is a policy defined based on RBAC stored in a JSON file and each line in that file defines the level of access to apply
Describe Keystone architecture
There is a service API and admin API through which Keystone gets requests- Keystone has four backends:
- Token Backend - Temporary Tokens for users and services
- Policy Backend - Rules management and authorization
- Identity Backend - users and groups (either standalone DB, LDAP, ...)
- Catalog Backend - Endpoints
- It has pluggable environment where you can integrate with:
- KVS (Key Value Store)
- SQL
- PAM
- Memcached
Describe the Keystone authentication process
Keystone gets a call/request and checks whether it's from an authorized user, using username, password and authURL- Once confirmed, Keystone provides a token.
- A token contains a list of user's projects so there is no to authenticate every time and a token can submitted instead
OpenStack Advanced - Compute (Nova)
What each of the following does?:- nova-api
- nova-compuate
- nova-conductor
- nova-cert
- nova-consoleauth
- nova-scheduler
nova-api - responsible for managing requests/calls- nova-compute - responsible for managing instance lifecycle
- nova-conductor - Mediates between nova-compute and the database so nova-compute doesn't access it directly
What types of Nova proxies are you familiar with?
Nova-novncproxy - Access through VNC connections- Nova-spicehtml5proxy - Access through SPICE
- Nova-xvpvncproxy - Access through a VNC connection
OpenStack Advanced - Networking (Neutron)
Explain BGP dynamic routing
What is the role of network namespaces in OpenStack?
OpenStack Advanced - Horizon
Can you describe Horizon in detail?
Django-based project focusing on providing an OpenStack dashboard and the ability to create additional customized dashboards- You can use it to access the different OpenStack services resources - instances, images, networks, ...
- By accessing the dashboard, users can use it to list, create, remove and modify the different resources
- It's also highly customizable and you can modify or add to it based on your needs
What can you tell about Horizon architecture?
API is backward compatible- There are three type of dashboards: user, system and settings
- It provides core support for all OpenStack core projects such as Neutron, Nova, etc. (out of the box, no need to install extra packages or plugins)
- Anyone can extend the dashboards and add new components
- Horizon provides templates and core classes from which one can build its own dashboard
Fantoche
What is Puppet? How does it works?
- Puppet is a configuration management tool ensuring that all systems are configured to a desired and predictable state.
Explain Puppet architecture
- Puppet has a primary-secondary node architecture. The clients are distributed across the network and communicate with the primary-secondary environment where Puppet modules are present. The client agent sends a certificate with its ID to the server; the server then signs that certificate and sends it back to the client. This authentication allows for secure and verifiable communication between the client and the master.
Can you compare Puppet to other configuration management tools? Why did you chose to use Puppet?
- Puppet is often compared to other configuration management tools like Chef, Ansible, SaltStack, and cfengine. The choice to use Puppet often depends on an organization's needs, such as ease of use, scalability, and community support.
Explain the following:
Modules - are a collection of manifests, templates, and files- Manifests - are the actual codes for configuring the clients
- Node - allows you to assign specific configurations to specific nodes
Explain Facter
- Facter is a standalone tool in Puppet that collects information about a system and its configuration, such as the operating system, IP addresses, memory, and network interfaces. This information can be used in Puppet manifests to make decisions about how resources should be managed, and to customize the behavior of Puppet based on the characteristics of the system. Facter is integrated into Puppet, and its facts can be used within Puppet manifests to make decisions about resource management.
What is MCollective?
- MCollective is a middleware system that integrates with Puppet to provide orchestration, remote execution, and parallel job execution capabilities.
Do you have experience with writing modules? Which module have you created and for what?
Explain what is Hiera
- Hiera is a hierarchical data store in Puppet that is used to separate data from code, allowing data to be more easily separated, managed, and reused.
Elástico
What is the Elastic Stack?
The Elastic Stack consists of:
- Elasticsearch
- Kibana
- Logstash
- Batidas
- Elastic Hadoop
- APM Server
Elasticsearch, Logstash and Kibana are also known as the ELK stack.
Explain what is Elasticsearch
From the official docs:
"Elasticsearch is a distributed document store. Instead of storing information as rows of columnar data, Elasticsearch stores complex data structures that have been serialized as JSON documents"
What is Logstash?
From the blog:
"Logstash is a powerful, flexible pipeline that collects, enriches and transports data. It works as an extract, transform & load (ETL) tool for collecting log messages."
Explain what beats are
Beats are lightweight data shippers. These data shippers installed on the client where the data resides. Examples of beats: Filebeat, Metricbeat, Auditbeat. There are much more.
What is Kibana?
From the official docs:
"Kibana is an open source analytics and visualization platform designed to work with Elasticsearch. You use Kibana to search, view, and interact with data stored in Elasticsearch indices. You can easily perform advanced data analysis and visualize your data in a variety of charts, tables, and maps."
Describe what happens from the moment an app logged some information until it's displayed to the user in a dashboard when the Elastic stack is used
The process may vary based on the chosen architecture and the processing you may want to apply to the logs. One possible workflow is:
The data logged by the application is picked by filebeat and sent to logstash- Logstash process the log based on the defined filters. Once done, the output is sent to Elasticsearch
- Elasticsearch stores the document it got and the document is indexed for quick future access
- The user creates visualizations in Kibana which based on the indexed data
- The user creates a dashboard which composed out of the visualization created in the previous step
Elasticsearch
What is a data node?
This is where data is stored and also where different processing takes place (eg when you search for a data).
What is a master node?
Part of a master node responsibilities:
- Track the status of all the nodes in the cluster
- Verify replicas are working and the data is available from every data node.
- No hot nodes (no data node that works much harder than other nodes)
While there can be multiple master nodes in reality only of them is the elected master node.
What is an ingest node?
A node which responsible for processing the data according to ingest pipeline. In case you don't need to use logstash then this node can receive data from beats and process it, similarly to how it can be processed in Logstash.
What is Coordinating only node?
From the official docs:
Coordinating only nodes can benefit large clusters by offloading the coordinating node role from data and master-eligible nodes. They join the cluster and receive the full cluster state, like every other node, and they use the cluster state to route requests directly to the appropriate place(s).
How data is stored in Elasticsearch?
Data is stored in an index- The index is spread across the cluster using shards
What is an Index?
Index in Elasticsearch is in most cases compared to a whole database from the SQL/NoSQL world.
You can choose to have one index to hold all the data of your app or have multiple indices where each index holds different type of your app (eg index for each service your app is running).
The official docs also offer a great explanation (in general, it's really good documentation, as every project should have):
"An index can be thought of as an optimized collection of documents and each document is a collection of fields, which are the key-value pairs that contain your data"
Explain Shards
An index is split into shards and documents are hashed to a particular shard. Each shard may be on a different node in a cluster and each one of the shards is a self contained index.
This allows Elasticsearch to scale to an entire cluster of servers.
What is an Inverted Index?
From the official docs:
"An inverted index lists every unique word that appears in any document and identifies all of the documents each word occurs in."
What is a Document?
Continuing with the comparison to SQL/NoSQL a Document in Elasticsearch is a row in table in the case of SQL or a document in a collection in the case of NoSQL. As in NoSQL a document is a JSON object which holds data on a unit in your app. What is this unit depends on the your app. If your app related to book then each document describes a book. If you are app is about shirts then each document is a shirt.
You check the health of your elasticsearch cluster and it's red. O que isso significa? What can cause the status to be yellow instead of green?
Red means some data is unavailable in your cluster. Some shards of your indices are unassigned. There are some other states for the cluster. Yellow means that you have unassigned shards in the cluster. You can be in this state if you have single node and your indices have replicas. Green means that all shards in the cluster are assigned to nodes and your cluster is healthy.
Verdadeiro ou Falso? Elasticsearch indexes all data in every field and each indexed field has the same data structure for unified and quick query ability
Falso. From the official docs:
"Each indexed field has a dedicated, optimized data structure. For example, text fields are stored in inverted indices, and numeric and geo fields are stored in BKD trees."
What reserved fields a document has?
Explain Mapping
What are the advantages of defining your own mapping? (or: when would you use your own mapping?)
You can optimize fields for partial matching- You can define custom formats of known fields (eg date)
- You can perform language-specific analysis
Explain Replicas
In a network/cloud environment where failures can be expected any time, it is very useful and highly recommended to have a failover mechanism in case a shard/node somehow goes offline or disappears for whatever reason. To this end, Elasticsearch allows you to make one or more copies of your index's shards into what are called replica shards, or replicas for short.
Can you explain Term Frequency & Document Frequency?
Term Frequency is how often a term appears in a given document and Document Frequency is how often a term appears in all documents. They both are used for determining the relevance of a term by calculating Term Frequency / Document Frequency.
You check "Current Phase" under "Index lifecycle management" and you see it's set to "hot". O que isso significa?
"The index is actively being written to". More about the phases here
What this command does? curl -X PUT "localhost:9200/customer/_doc/1?pretty" -H 'Content-Type: application/json' -d'{ "name": "John Doe" }'
It creates customer index if it doesn't exists and adds a new document with the field name which is set to "John Dow". Also, if it's the first document it will get the ID 1.
What will happen if you run the previous command twice? What about running it 100 times?
If name value was different then it would update "name" to the new value- In any case, it bumps version field by one
What is the Bulk API? What would you use it for?
Bulk API is used when you need to index multiple documents. For high number of documents it would be significantly faster to use rather than individual requests since there are less network roundtrips.
Query DSL
Explain Elasticsearch query syntax (Booleans, Fields, Ranges)
Explain what is Relevance Score
Explain Query Context and Filter Context
From the official docs:
"In the query context, a query clause answers the question “How well does this document match this query clause?” Besides deciding whether or not the document matches, the query clause also calculates a relevance score in the _score meta-field."
"In a filter context, a query clause answers the question “Does this document match this query clause?” The answer is a simple Yes or No — no scores are calculated. Filter context is mostly used for filtering structured data"
Describe how would an architecture of production environment with large amounts of data would be different from a small-scale environment
There are several possible answers for this question. One of them is as follows:
A small-scale architecture of elastic will consist of the elastic stack as it is. This means we will have beats, logstash, elastcsearch and kibana.
A production environment with large amounts of data can include some kind of buffering component (eg Reddis or RabbitMQ) and also security component such as Nginx.
Logstash
What are Logstash plugins? What plugins types are there?
Input Plugins - how to collect data from different sources- Filter Plugins - processing data
- Output Plugins - push data to different outputs/services/platforms
What is grok?
A logstash plugin which modifies information in one format and immerse it in another.
How grok works?
What grok patterns are you familiar with?
What is `_grokparsefailure?`
How do you test or debug grok patterns?
What are Logstash Codecs? What codecs are there?
Kibana
What can you find under "Discover" in Kibana?
The raw data as it is stored in the index. You can search and filter it.
You see in Kibana, after clicking on Discover, "561 hits". O que isso significa?
Total number of documents matching the search results. If not query used then simply the total number of documents.
What can you find under "Visualize"?
"Visualize" is where you can create visual representations for your data (pie charts, graphs, ...)
What visualization types are supported/included in Kibana?
What visualization type would you use for statistical outliers
Describe in detail how do you create a dashboard in Kibana
Filebeat
What is Filebeat?
Filebeat is used to monitor the logging directories inside of VMs or mounted as a sidecar if exporting logs from containers, and then forward these logs onward for further processing, usually to logstash.
If one is using ELK, is it a must to also use filebeat? In what scenarios it's useful to use filebeat?
Filebeat is a typical component of the ELK stack, since it was developed by Elastic to work with the other products (Logstash and Kibana). It's possible to send logs directly to logstash, though this often requires coding changes for the application. Particularly for legacy applications with little test coverage, it might be a better option to use filebeat, since you don't need to make any changes to the application code.
What is a harvester?
Read here
Verdadeiro ou Falso? a single harvester harvest multiple files, according to the limits set in filebeat.yml
Falso. One harvester harvests one file.
What are filebeat modules?
These are pre-configured modules for specific types of logging locations (eg, Traefik, Fargate, HAProxy) to make it easy to configure forwarding logs using filebeat. They have different configurations based on where you're collecting logs from.
Pilha Elástica
How do you secure an Elastic Stack?
You can generate certificates with the provided elastic utils and change configuration to enable security using certificates model.
Distribuído
Explain Distributed Computing (or Distributed System)
According to Martin Kleppmann:
"Many processes running on many machines...only message-passing via an unreliable network with variable delays, and the system may suffer from partial failures, unreliable clocks, and process pauses."
Another definition: "Systems that are physically separated, but logically connected"
What can cause a system to fail?
Do you know what is "CAP theorem"? (aka as Brewer's theorem)
According to the CAP theorem, it's not possible for a distributed data store to provide more than two of the following at the same time:
Availability: Every request receives a response (it doesn't has to be the most recent data)- Consistency: Every request receives a response with the latest/most recent data
- Partition tolerance: Even if some the data is lost/dropped, the system keeps running
What are the problems with the following design? How to improve it?
1. The transition can take time. In other words, noticeable downtime. 2. Standby server is a waste of resources - if first application server is running then the standby does nothing What are the problems with the following design? How to improve it?
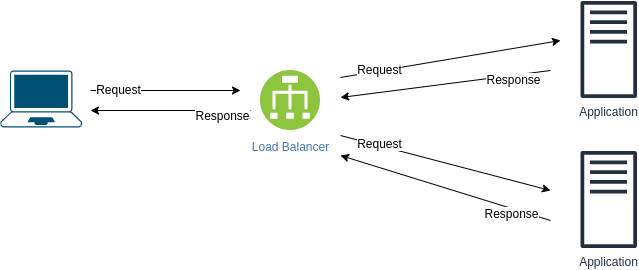
Issues: If load balancer dies , we lose the ability to communicate with the application. Ways to improve:
Add another load balancer- Use DNS A record for both load balancers
- Use message queue
What is "Shared-Nothing" architecture?
It's an architecture in which data is and retrieved from a single, non-shared, source usually exclusively connected to one node as opposed to architectures where the request can get to one of many nodes and the data will be retrieved from one shared location (storage, memory, ...).
Explain the Sidecar Pattern (Or sidecar proxy)
Diversos
| Nome | Tópico | Objective & Instructions | Solução | Comentários |
|---|
| Highly Available "Hello World" | Exercício | Solução | | |
What happens when you type in a URL in an address bar in a browser?
- The browser searches for the record of the domain name IP address in the DNS in the following order:
- Browser cache
- Operating system cache
- The DNS server configured on the user's system (can be ISP DNS, public DNS, ...)
- If it couldn't find a DNS record locally, a full DNS resolution is started.
- It connects to the server using the TCP protocol
- The browser sends an HTTP request to the server
- The server sends an HTTP response back to the browser
- The browser renders the response (eg HTML)
- The browser then sends subsequent requests as needed to the server to get the embedded links, javascript, images in the HTML and then steps 3 to 5 are repeated.
TODO: add more details!
API
Explain what is an API
I like this definition from blog.christianposta.com:
"An explicitly and purposefully defined interface designed to be invoked over a network that enables software developers to get programmatic access to data and functionality within an organization in a controlled and comfortable way."
What is an API specification?
From swagger.io:
"An API specification provides a broad understanding of how an API behaves and how the API links with other APIs. It explains how the API functions and the results to expect when using the API"
Verdadeiro ou Falso? API Definition is the same as API Specification
Falso. From swagger.io:
"An API definition is similar to an API specification in that it provides an understanding of how an API is organized and how the API functions. But the API definition is aimed at machine consumption instead of human consumption of APIs."
What is an API gateway?
An API gateway is like the gatekeeper that controls how different parts talk to each other and how information is exchanged between them.
The API gateway provides a single point of entry for all clients, and it can perform several tasks, including routing requests to the appropriate backend service, load balancing, security and authentication, rate limiting, caching, and monitoring.
By using an API gateway, organizations can simplify the management of their APIs, ensure consistent security and governance, and improve the performance and scalability of their backend services. They are also commonly used in microservices architectures, where there are many small, independent services that need to be accessed by different clients.
What are the advantages of using/implementing an API gateway?
Vantagens:
- Simplifies API management: Provides a single entry point for all requests, which simplifies the management and monitoring of multiple APIs.
- Improves security: Able to implement security features like authentication, authorization, and encryption to protect the backend services from unauthorized access.
- Enhances scalability: Can handle traffic spikes and distribute requests to backend services in a way that maximizes resource utilization and improves overall system performance.
- Enables service composition: Can combine different backend services into a single API, providing more granular control over the services that clients can access.
- Facilitates integration with external systems: Can be used to expose internal services to external partners or customers, making it easier to integrate with external systems and enabling new business models.
What is a Payload in API?
What is Automation? How it's related or different from Orchestration?
Automation is the act of automating tasks to reduce human intervention or interaction in regards to IT technology and systems.
While automation focuses on a task level, Orchestration is the process of automating processes and/or workflows which consists of multiple tasks that usually across multiple systems.
Tell me about interesting bugs you've found and also fixed
What is a Debugger and how it works?
What services an application might have?
Autorização- Registro
- Autenticação
- Pedido
- Front-end
- Back-end ...
What is Metadata?
Data about data. Basically, it describes the type of information that an underlying data will hold.
You can use one of the following formats: JSON, YAML, XML. Which one would you use? Por que?
I can't answer this for you :)
What's KPI?
What's OKR?
What's DSL (Domain Specific Language)?
Domain Specific Language (DSLs) are used to create a customised language that represents the domain such that domain experts can easily interpret it.
What's the difference between KPI and OKR?
YAML
What is YAML?
Data serialization language used by many technologies today like Kubernetes, Ansible, etc.
Verdadeiro ou Falso? Any valid JSON file is also a valid YAML file
Verdadeiro. Because YAML is superset of JSON.
What is the format of the following data? {
applications: [
{
name: "my_app",
language: "python",
version: 20.17
}
]
}
JSON What is the format of the following data? applications:
- app: "my_app"
language: "python"
version: 20.17
YAML How to write a multi-line string with YAML? What use cases is it good for?
someMultiLineString: | look mama I can write a multi-line string I love YAML
It's good for use cases like writing a shell script where each line of the script is a different command.
What is the difference between someMultiLineString: | to someMultiLineString: > ?
using > will make the multi-line string to fold into a single line
someMultiLineString: >
This is actually
a single line
do not let appearances fool you
What are placeholders in YAML?
They allow you reference values instead of directly writing them and it is used like this:
username: {{ my.user_name }}
How can you define multiple YAML components in one file?
Using this: --- For Examples:
document_number: 1
---
document_number: 2
Firmware
Explain what is a firmware
Wikipedia: "In computing, firmware is a specific class of computer software that provides the low-level control for a device's specific hardware. Firmware, such as the BIOS of a personal computer, may contain basic functions of a device, and may provide hardware abstraction services to higher-level software such as operating systems."
Cassandra
When running a cassandra cluster, how often do you need to run nodetool repair in order to keep the cluster consistent?- Within the columnFamily GC-grace Once a week
- Less than the compacted partition minimum bytes
- Depended on the compaction strategy
HTTP
What is HTTP?
Avinetworks: HTTP stands for Hypertext Transfer Protocol. HTTP uses TCP port 80 to enable internet communication. It is part of the Application Layer (L7) in OSI Model.
Describe HTTP request lifecycle
Resolve host by request to DNS resolver- Client SYN
- Server SYN+ACK
- Client SYN
- HTTP request
- HTTP response
Verdadeiro ou Falso? HTTP is stateful
Falso. It doesn't maintain state for incoming request.
How HTTP request looks like?
It consists of:
Request line - request type- Headers - content info like length, encoding, etc.
- Body (not always included)
What HTTP method types are there?
PEGAR- PUBLICAR
- CABEÇA
- COLOCAR
- EXCLUIR
- CONECTAR
- OPÇÕES
- TRACE
What HTTP response codes are there?
1xx - informational- 2xx - Success
- 3xx - Redirect
- 4xx - Error, client fault
- 5xx - Error, server fault
What is HTTPS?
HTTPS is a secure version of the HTTP protocol used to transfer data between a web browser and a web server. It encrypts the communication using SSL/TLS encryption to ensure that the data is private and secure.
Learn more: https://www.cloudflare.com/learning/ssl/why-is-http-not-secure/
Explain HTTP Cookies
HTTP is stateless. To share state, we can use Cookies.
TODO: explain what is actually a Cookie
What is HTTP Pipelining?
You get "504 Gateway Timeout" error from an HTTP server. O que isso significa?
The server didn't receive a response from another server it communicates with in a timely manner.
What is a proxy?
A proxy is a server that acts as a middleman between a client device and a destination server. It can help improve privacy, security, and performance by hiding the client's IP address, filtering content, and caching frequently accessed data.
- Proxies can be used for load balancing, distributing traffic across multiple servers to help prevent server overload and improve website or application performance. They can also be used for data analysis, as they can log requests and traffic, providing useful insights into user behavior and preferences.
What is a reverse proxy?
A reverse proxy is a type of proxy server that sits between a client and a server, but it is used to manage traffic going in the opposite direction of a traditional forward proxy. In a forward proxy, the client sends requests to the proxy server, which then forwards them to the destination server. However, in a reverse proxy, the client sends requests to the destination server, but the requests are intercepted by the reverse proxy before they reach the server.
- They're commonly used to improve web server performance, provide high availability and fault tolerance, and enhance security by preventing direct access to the back-end server. They are often used in large-scale web applications and high-traffic websites to manage and distribute requests to multiple servers, resulting in improved scalability and reliability.
When you publish a project, you usually publish it with a license. What types of licenses are you familiar with and which one do you prefer to use?
Explain what is "X-Forwarded-For"
Wikipedia: "The X-Forwarded-For (XFF) HTTP header field is a common method for identifying the originating IP address of a client connecting to a web server through an HTTP proxy or load balancer."
Load Balancers
What is a load balancer?
A load balancer accepts (or denies) incoming network traffic from a client, and based on some criteria (application related, network, etc.) it distributes those communications out to servers (at least one).
Why to used a load balancer?
Scalability - using a load balancer, you can possibly add more servers in the backend to handle more requests/traffic from the clients, as opposed to using one server.- Redundancy - if one server in the backend dies, the load balancer will keep forwarding the traffic/requests to the second server so users won't even notice one of the servers in the backend is down.
What load balancer techniques/algorithms are you familiar with?
Rodada Robin- Weighted Round Robin
- Least Connection
- Weighted Least Connection
- Resource Based
- Fixed Weighting
- Weighted Response Time
- Source IP Hash
- URL Hash
What are the drawbacks of round robin algorithm in load balancing?
A simple round robin algorithm knows nothing about the load and the spec of each server it forwards the requests to. It is possible, that multiple heavy workloads requests will get to the same server while other servers will got only lightweight requests which will result in one server doing most of the work, maybe even crashing at some point because it unable to handle all the heavy workloads requests by its own.- Each request from the client creates a whole new session. This might be a problem for certain scenarios where you would like to perform multiple operations where the server has to know about the result of operation so basically, being sort of aware of the history it has with the client. In round robin, first request might hit server X, while second request might hit server Y and ask to continue processing the data that was processed on server X already.
What is an Application Load Balancer?
In which scenarios would you use ALB?
At what layers a load balancer can operate?
L4 and L7
Can you perform load balancing without using a dedicated load balancer instance?
Yes, you can use DNS for performing load balancing.
What is DNS load balancing? What its advantages? When would you use it?
Load Balancers - Sticky Sessions
What are sticky sessions? What are their pros and cons?
Recommended read:
Contras:
Can cause uneven load on instance (since requests routed to the same instances) Pros:- Ensures in-proc sessions are not lost when a new request is created
Name one use case for using sticky sessions
You would like to make sure the user doesn't lose the current session data.
What sticky sessions use for enabling the "stickiness"?
Biscoitos. There are application based cookies and duration based cookies.
Explain application-based cookies
Generated by the application and/or the load balancer- Usually allows to include custom data
Explain duration-based cookies
Generated by the load balancer- Session is not sticky anymore once the duration elapsed
Load Balancers - Load Balancing Algorithms
Explain each of the following load balancing techniques- Rodada Robin
- Weighted Round Robin
- Least Connection
- Weighted Least Connection
- Resource Based
- Fixed Weighting
- Weighted Response Time
- Source IP Hash
- URL Hash
Explain use case for connection draining?
To ensure that a Classic Load Balancer stops sending requests to instances that are de-registering or unhealthy, while keeping the existing connections open, use connection draining. This enables the load balancer to complete in-flight requests made to instances that are de-registering or unhealthy. The maximum timeout value can be set between 1 and 3,600 seconds on both GCP and AWS.
Licenças
Are you familiar with "Creative Commons"? O que você sabe sobre isso?
The Creative Commons license is a set of copyright licenses that allow creators to share their work with the public while retaining some control over how it can be used. The license was developed as a response to the restrictive standards of traditional copyright laws, which limited access of creative works. Its creators to choose the terms under which their works can be shared, distributed, and used by others. They're six main types of Creative Commons licenses, each with different levels of restrictions and permissions, the six licenses are:
- Attribution (CC BY): Allows others to distribute, remix, and build upon the work, even commercially, as long as they credit the original creator.
- Attribution-ShareAlike (CC BY-SA): Allows others to remix and build upon the work, even commercially, as long as they credit the original creator and release any new creations under the same license.
- Attribution-NoDerivs (CC BY-ND): Allows others to distribute the work, even commercially, but they cannot remix or change it in any way and must credit the original creator.
- Attribution-NonCommercial (CC BY-NC): Allows others to remix and build upon the work, but they cannot use it commercially and must credit the original creator.
- Attribution-NonCommercial-ShareAlike (CC BY-NC-SA): Allows others to remix and build upon the work, but they cannot use it commercially, must credit the original creator, and must release any new creations under the same license.
- Attribution-NonCommercial-NoDerivs (CC BY-NC-ND): Allows others to download and share the work, but they cannot use it commercially, remix or change it in any way, and must credit the original creator.
Simply stated, the Creative Commons licenses are a way for creators to share their work with the public while retaining some control over how it can be used. The licenses promote creativity, innovation, and collaboration, while also respecting the rights of creators while still encouraging the responsible use of creative works.
More information: https://creativecommons.org/licenses/
Explain the differences between copyleft and permissive licenses
In Copyleft, any derivative work must use the same licensing while in permissive licensing there are no such condition. GPL-3 is an example of copyleft license while BSD is an example of permissive license.
Aleatório
How a search engine works?
How auto completion works?
What is faster than RAM?
CPU cache. Fonte
What is a memory leak?
A memory leak is a programming error that occurs when a program fails to release memory that is no longer needed, causing the program to consume increasing amounts of memory over time.
The leaks can lead to a variety of problems, including system crashes, performance degradation, and instability. Usually occurring after failed maintenance on older systems and compatibility with new components over time.
What is your favorite protocol?
SSH HTTP DHCP DNS ...
What is Cache API?
What is the C10K problem? Is it relevant today?
https://idiallo.com/blog/c10k-2016
Armazenar
What types of storage are there?
Explain Object Storage
Data is divided to self-contained objects- Objects can contain metadata
What are the pros and cons of object storage?
Prós:
Usually with object storage, you pay for what you use as opposed to other storage types where you pay for the storage space you allocate- Scalable storage: Object storage mostly based on a model where what you use, is what you get and you can add storage as need Cons:
- Usually performs slower than other types of storage
- No granular modification: to change an object, you have re-create it
What are some use cases for using object storage?
Explain File Storage
File Storage used for storing data in files, in a hierarchical structure- Some of the devices for file storage: hard drive, flash drive, cloud-based file storage
- Files usually organized in directories
What are the pros and cons of File Storage?
Prós:
Users have full control of their own files and can run variety of operations on the files: delete, read, write and move.- Security mechanism allows for users to have a better control at things such as file locking
What are some examples of file storage?
Local filesystem Dropbox Google Drive
What types of storage devices are there?
Explain IOPS
Explain storage throughput
What is a filesystem?
A file system is a way for computers and other electronic devices to organize and store data files. It provides a structure that helps to organize data into files and directories, making it easier to find and manage information. A file system is crucial for providing a way to store and manage data in an organized manner.
Commonly used filed systems: Windows:
Mac OS:
Explain Dark Data
Explain MBR
Questions you CAN ask
A list of questions you as a candidate can ask the interviewer during or after the interview. These are only a suggestion, use them carefully. Not every interviewer will be able to answer these (or happy to) which should be perhaps a red flag warning for your regarding working in such place but that's really up to you.
What do you like about working here?
How does the company promote personal growth?
What is the current level of technical debt you are dealing with?
Be careful when asking this question - all companies, regardless of size, have some level of tech debt. Phrase the question in the light that all companies have the deal with this, but you want to see the current pain points they are dealing with
This is a great way to figure how managers deal with unplanned work, and how good they are at setting expectations with projects.
Why I should NOT join you? (or 'what you don't like about working here?')
What was your favorite project you've worked on?
This can give you insights in some of the cool projects a company is working on, and if you would enjoy working on projects like these. This is also a good way to see if the managers are allowing employees to learn and grow with projects outside of the normal work you'd do.
If you could change one thing about your day to day, what would it be?
Similar to the tech debt question, this helps you identify any pain points with the company. Additionally, it can be a great way to show how you'd be an asset to the team.
For Example, if they mention they have problem X, and you've solved that in the past, you can show how you'd be able to mitigate that problem.
Let's say that we agree and you hire me to this position, after X months, what do you expect that I have achieved?
Not only this will tell you what is expected from you, it will also provide big hint on the type of work you are going to do in the first months of your job.
Teste
Explain white-box testing
Explain black-box testing
What are unit tests?
Unit test are a software testing technique that involves systimatically breaking down a system and testing each individual part of the assembly. These tests are automated and can be run repeatedly to allow developers to catch edge case scenarios or bugs quickly while developing.
The main objective of unit tests are to verify each function is producing proper outputs given a set of inputs.
What types of tests would you run to test a web application?
Explain test harness?
What is A/B testing?
What is network simulation and how do you perform it?
What types of performances tests are you familiar with?
Explain the following types of tests:- Load Testing
- Stress Testing
- Teste de capacidade
- Volume Testing
- Endurance Testing
Regex
Given a text file, perform the following exercises
Extrair
Extract all the numbers
Extract the first word of each line
"^w+" Bonus: extract the last word of each line
-
"w+(?=W*$)" (in most cases, depends on line formatting)
Extract all the IP addresses
- "b(?:d{1,3} .){3}d{1,3}b" IPV4:(This format looks for 1 to 3 digit sequence 3 times)
Extract dates in the format of yyyy-mm-dd or yyyy-dd-mm
Extract email addresses
- "b[A-Za-z0-9._%+-]+@[A-Za-z0-9.-]+ .[A-Za-z]{2,}b"
Substituir
Replace tabs with four spaces
Replace 'red' with 'green'
System Design
Explain what a "single point of failure" is.
A "single point of failure", in a system or organization, if it were to fail would cause the entire system to fail or significantly disrupt it's operation. In other words, it is a vulnerability where there is no backup in place to compensate for the failure. What is CDN?
CDN (Content Delivery Network) responsible for distributing content geographically. Part of it, is what is known as edge locations, aka cache proxies, that allows users to get their content quickly due to cache features and geographical distribution.
Explain Multi-CDN
In single CDN, the whole content is originated from content delivery network.
In multi-CDN, content is distributed across multiple different CDNs, each might be on a completely different provider/cloud.
What are the benefits of Multi-CDN over a single CDN?
Resiliency: Relying on one CDN means no redundancy. With multiple CDNs you don't need to worry about your CDN being down- Flexibility in Costs: Using one CDN enforces you to specific rates of that CDN. With multiple CDNs you can take into consideration using less expensive CDNs to deliver the content.
- Performance: With Multi-CDN there is bigger potential in choosing better locations which more close to the client asking the content
- Scale: With multiple CDNs, you can scale services to support more extreme conditions
Explain "3-Tier Architecture" (including pros and cons)
A "3-Tier Architecture" is a pattern used in software development for designing and structuring applications. It divides the application into 3 interconnected layers: Presentation, Business logic and Data storage. PROS: * Scalability * Security * Reusability CONS: * Complexity * Performance overhead * Cost and development time Explain Mono-repo vs. Multi-repo.What are the cons and pros of each approach?
In a Mono-repo, all the code for an organization is stored in a single,centralized repository. PROS (Mono-repo): * Unified tooling * Code Sharing CONS (Mono-repo): * Increased complexity * Slower cloning In a Multi-repo setup, each component is stored in it's own separate repository. Each repository has it's own version control history. PROS (Multi-repo):
Simpler to manage- Different teams and developers can work on different parts of the project independently, making parallel development easier. CONS (Multi-repo):
- Code duplication
- Integration challenges
What are the drawbacks of monolithic architecture?
Not suitable for frequent code changes and the ability to deploy new features- Not designed for today's infrastructure (like public clouds)
- Scaling a team to work monolithic architecture is more challenging
- If a single component in this architecture fails, then the entire application fails.
What are the advantages of microservices architecture over a monolithic architecture?
Each of the services individually fail without escalating into an application-wide outage.- Each service can be developed and maintained by a separate team and this team can choose its own tools and coding language
What's a service mesh?
It is a layer that facilitates communication management and control between microservices in a containerized application. It handles tasks such as load balancing, encryption, and monitoring. Explain "Loose Coupling"
In "Loose Coupling", components of a system communicate with each other with a little understanding of each other's internal workings. This improves scalability and ease of modification in complex systems. What is a message queue? When is it used?
It is a communication mechanism used in distributed systems to enable asynchronous communication between different components. It is generally used when the systems use a microservices approach. Escalabilidade
Explain Scalability
The ability easily grow in size and capacity based on demand and usage.
Explain Elasticity
The ability to grow but also to reduce based on what is required
Explain Disaster Recovery
Disaster recovery is the process of restoring critical business systems and data after a disruptive event. The goal is to minimize the impact and resume normal business activities quickly. This involves creating a plan, testing it, backing up critical data, and storing it in safe locations. In case of a disaster, the plan is then executed, backups are restored, and systems are hopefully brought back online. The recovery process may take hours or days depending on the damages of infrastructure. This makes business planning important, as a well-designed and tested disaster recovery plan can minimize the impact of a disaster and keep operations going.
Explain Fault Tolerance and High Availability
Fault Tolerance - The ability to self-heal and return to normal capacity. Also the ability to withstand a failure and remain functional.
High Availability - Being able to access a resource (in some use cases, using different platforms)
What is the difference between high availability and Disaster Recovery?
wintellect.com: "High availability, simply put, is eliminating single points of failure and disaster recovery is the process of getting a system back to an operational state when a system is rendered inoperative. In essence, disaster recovery picks up when high availability fails, so HA first."
Explain Vertical Scaling
Vertical Scaling is the process of adding resources to increase power of existing servers. For example, adding more CPUs, adding more RAM, etc.
What are the disadvantages of Vertical Scaling?
With vertical scaling alone, the component still remains a single point of failure. In addition, it has hardware limit where if you don't have more resources, you might not be able to scale vertically.
Which type of cloud services usually support vertical scaling?
Databases, cache. It's common mostly for non-distributed systems.
Explain Horizontal Scaling
Horizontal Scaling is the process of adding more resources that will be able handle requests as one unit
What is the disadvantage of Horizontal Scaling? What is often required in order to perform Horizontal Scaling?
A load balancer. You can add more resources, but if you would like them to be part of the process, you have to serve them the requests/responses. Also, data inconsistency is a concern with horizontal scaling.
Explain in which use cases will you use vertical scaling and in which use cases you will use horizontal scaling
Explain Resiliency and what ways are there to make a system more resilient
Explain "Consistent Hashing"
How would you update each of the services in the following drawing without having app (foo.com) downtime?
What is the problem with the following architecture and how would you fix it?
The load on the producers or consumers may be high which will then cause them to hang or crash.
Instead of working in "push mode", the consumers can pull tasks only when they are ready to handle them. It can be fixed by using a streaming platform like Kafka, Kinesis, etc. This platform will make sure to handle the high load/traffic and pass tasks/messages to consumers only when the ready to get them.

Users report that there is huge spike in process time when adding little bit more data to process as an input. Qual pode ser o problema?

How would you scale the architecture from the previous question to hundreds of users?
Cache
What is "cache"? In which cases would you use it?
What is "distributed cache"?
What is a "cache replacement policy"?
Dê uma olhada aqui
Which cache replacement policies are you familiar with?
You can find a list here
Explain the following cache policies:
Read about it here
Why not writing everything to cache instead of a database/datastore?
Caching and databases serve different purposes and are optimized for different use cases. Caching is used to speed up read operations by storing frequently accessed data in memory or on a fast storage medium. By keeping data close to the application, caching reduces the latency and overhead of accessing data from a slower, more distant storage system such as a database or disk.
On the other hand, databases are optimized for storing and managing persistent data. Databases are designed to handle concurrent read and write operations, enforce consistency and integrity constraints, and provide features such as indexing and querying.
Migrações
How you prepare for a migration? (or plan a migration)
You can mention:
roll-back & roll-forward cut over dress rehearsals DNS redirection
Explain "Branch by Abstraction" technique
Design a system
Can you design a video streaming website?
Can you design a photo upload website?
How would you build a URL shortener?
More System Design Questions
Additional exercises can be found in system-design-notebook repository.

Hardware
What is a CPU?
A central processing unit (CPU) performs basic arithmetic, logic, controlling, and input/output (I/O) operations specified by the instructions in the program. This contrasts with external components such as main memory and I/O circuitry, and specialized processors such as graphics processing units (GPUs).
What is RAM?
RAM (Random Access Memory) is the hardware in a computing device where the operating system (OS), application programs and data in current use are kept so they can be quickly reached by the device's processor. RAM is the main memory in a computer. It is much faster to read from and write to than other kinds of storage, such as a hard disk drive (HDD), solid-state drive (SSD) or optical drive.
What is a GPU?
A GPU, or Graphics Processing Unit, is a specialized electronic circuit designed to expedite image and video processing for display on a computer screen.
What is an embedded system?
An embedded system is a computer system - a combination of a computer processor, computer memory, and input/output peripheral devices—that has a dedicated function within a larger mechanical or electronic system. It is embedded as part of a complete device often including electrical or electronic hardware and mechanical parts.
Can you give an example of an embedded system?
A common example of an embedded system is a microwave oven's digital control panel, which is managed by a microcontroller.
When committed to a certain goal, Raspberry Pi can serve as an embedded system.
What types of storage are there?
There are several types of storage, including hard disk drives (HDDs), solid-state drives (SSDs), and optical drives (CD/DVD/Blu-ray). Other types of storage include USB flash drives, memory cards, and network-attached storage (NAS).
What are some considerations DevOps teams should keep in mind when selecting hardware for their job?
Choosing the right DevOps hardware is essential for ensuring streamlined CI/CD pipelines, timely feedback loops, and consistent service availability. Here's a distilled guide on what DevOps teams should consider:
Understanding Workloads :
- CPU : Consider the need for multi-core or high-frequency CPUs based on your tasks.
- RAM : Enough memory is vital for activities like large-scale coding or intensive automation.
- Storage : Evaluate storage speed and capacity. SSDs might be preferable for swift operations.
Expandability :
- Horizontal Growth : Check if you can boost capacity by adding more devices.
- Vertical Growth : Determine if upgrades (like RAM, CPU) to individual machines are feasible.
Connectivity Considerations :
- Data Transfer : Ensure high-speed network connections for activities like code retrieval and data transfers.
- Speed : Aim for low-latency networks, particularly important for distributed tasks.
- Backup Routes : Think about having backup network routes to avoid downtimes.
Consistent Uptime :
- Plan for hardware backups like RAID configurations, backup power sources, or alternate network connections to ensure continuous service.
System Compatibility :
- Make sure your hardware aligns with your software, operating system, and intended platforms.
Power Efficiency :
- Hardware that uses energy efficiently can reduce costs in long-term, especially in large setups.
Safety Measures :
- Explore hardware-level security features, such as TPM, to enhance protection.
Overseeing & Control :
- Tools like ILOM can be beneficial for remote handling.
- Make sure the hardware can be seamlessly monitored for health and performance.
Budgeting :
- Consider both initial expenses and long-term costs when budgeting.
Support & Community :
- Choose hardware from reputable vendors known for reliable support.
- Check for available drivers, updates, and community discussions around the hardware.
Planning Ahead :
- Opt for hardware that can cater to both present and upcoming requirements.
Operational Environment :
- Temperature Control : Ensure cooling systems to manage heat from high-performance units.
- Space Management : Assess hardware size considering available rack space.
- Reliable Power : Factor in consistent and backup power sources.
Cloud Coordination :
- If you're leaning towards a hybrid cloud setup, focus on how local hardware will mesh with cloud resources.
Life Span of Hardware :
- Be aware of the hardware's expected duration and when you might need replacements or upgrades.
Optimized for Virtualization :
- If utilizing virtual machines or containers, ensure the hardware is compatible and optimized for such workloads.
Adaptability :
- Modular hardware allows individual component replacements, offering more flexibility.
Avoiding Single Vendor Dependency :
- Try to prevent reliance on a single vendor unless there are clear advantages.
Eco-Friendly Choices :
- Prioritize sustainably produced hardware that's energy-efficient and environmentally responsible.
In essence, DevOps teams should choose hardware that is compatible with their tasks, versatile, gives good performance, and stays within their budget. Furthermore, long-term considerations such as maintenance, potential upgrades, and compatibility with impending technological shifts must be prioritized.
What is the role of hardware in disaster recovery planning and implementation?
Hardware is critical in disaster recovery (DR) solutions. While the broader scope of DR includes things like standard procedures, norms, and human roles, it's the hardware that keeps business processes running smoothly. Here's an outline of how hardware works with DR:
Storing Data and Ensuring Its Duplication :
- Backup Equipment : Devices like tape storage, backup servers, and external HDDs keep essential data stored safely at a different location.
- Disk Arrays : Systems such as RAID offer a safety net. If one disk crashes, the others compensate.
Alternate Systems for Recovery :
- Backup Servers : These step in when the main servers falter, maintaining service flow.
- Traffic Distributors : Devices like load balancers share traffic across servers. If a server crashes, they reroute users to operational ones.
Alternate Operation Hubs :
- Ready-to-use Centers : Locations equipped and primed to take charge immediately when the main center fails.
- Basic Facilities : Locations with necessary equipment but lacking recent data, taking longer to activate.
- Semi-prepped Facilities : Locations somewhat prepared with select systems and data, taking a moderate duration to activate.
Power Backup Mechanisms :
- Instant Power Backup : Devices like UPS offer power during brief outages, ensuring no abrupt shutdowns.
- Long-term Power Solutions : Generators keep vital systems operational during extended power losses.
Equipamento de rede :
- Backup Internet Connections : Having alternatives ensures connectivity even if one provider faces issues.
- Secure Connection Tools : Devices ensuring safe remote access, especially crucial during DR situations.
On-site Physical Setup :
- Organized Housing : Structures like racks to neatly store and manage hardware.
- Emergency Temperature Control : Backup cooling mechanisms to counter server overheating in HVAC malfunctions.
Alternate Communication Channels :
- Orbit-based Phones : Handy when regular communication methods falter.
- Direct Communication Devices : Devices like radios useful when primary systems are down.
Protection Mechanisms :
- Electronic Barriers & Alert Systems : Devices like firewalls and intrusion detection keep DR systems safeguarded.
- Physical Entry Control : Systems controlling entry and monitoring, ensuring only cleared personnel have access.
Uniformity and Compatibility in Hardware :
- It's simpler to manage and replace equipment in emergencies if hardware configurations are consistent and compatible.
Equipment for Trials and Upkeep :
- DR drills might use specific equipment to ensure the primary systems remain unaffected. This verifies the equipment's readiness and capacity to manage real crises.
In summary, while software and human interventions are important in disaster recovery operations, it is the hardware that provides the underlying support. It is critical for efficient disaster recovery plans to keep this hardware resilient, duplicated, and routinely assessed.
What is a RAID?
RAID is an acronym that stands for "Redundant Array of Independent Disks." It is a technique that combines numerous hard drives into a single device known as an array in order to improve performance, expand storage capacity, and/or offer redundancy to prevent data loss. RAID levels (for example, RAID 0, RAID 1, and RAID 5) provide varied benefits in terms of performance, redundancy, and storage efficiency.
What is a microcontroller?
A microcontroller is a small integrated circuit that controls certain tasks in an embedded system. It typically includes a CPU, memory, and input/output peripherals.
What is a Network Interface Controller or NIC?
A Network Interface Controller (NIC) is a piece of hardware that connects a computer to a network and allows it to communicate with other devices.
What is a DMA?
Direct memory access (DMA) is a feature of computer systems that allows certain hardware subsystems to access main system memory independently of the central processing unit (CPU).DMA enables devices to share and receive data from the main memory in a computer. It does this while still allowing the CPU to perform other tasks.
What is a Real-Time Operating Systems?
A real-time operating system (RTOS) is an operating system (OS) for real-time computing applications that processes data and events that have critically defined time constraints. An RTOS is distinct from a time-sharing operating system, such as Unix, which manages the sharing of system resources with a scheduler, data buffers, or fixed task prioritization in a multitasking or multiprogramming environment. Processing time requirements need to be fully understood and bound rather than just kept as a minimum. All processing must occur within the defined constraints. Real-time operating systems are event-driven and preemptive, meaning the OS can monitor the relevant priority of competing tasks, and make changes to the task priority. Event-driven systems switch between tasks based on their priorities, while time-sharing systems switch the task based on clock interrupts.
List of interrupt types
There are six classes of interrupts possible:
Externo- Machine check
- E/S
- Programa
- Reiniciar
- Supervisor call (SVC)
Grandes dados
Explain what is exactly Big Data
As defined by Doug Laney:
Volume: Extremely large volumes of data- Velocity: Real time, batch, streams of data
- Variety: Various forms of data, structured, semi-structured and unstructured
- Veracity or Variability: Inconsistent, sometimes inaccurate, varying data
What is DataOps? How is it related to DevOps?
DataOps seeks to reduce the end-to-end cycle time of data analytics, from the origin of ideas to the literal creation of charts, graphs and models that create value. DataOps combines Agile development, DevOps and statistical process controls and applies them to data analytics.
What is Data Architecture?
An answer from talend.com:
"Data architecture is the process of standardizing how organizations collect, store, transform, distribute, and use data. The goal is to deliver relevant data to people who need it, when they need it, and help them make sense of it."
Explain the different formats of data
Structured - data that has defined format and length (eg numbers, words)- Semi-structured - Doesn't conform to a specific format but is self-describing (eg XML, SWIFT)
- Unstructured - does not follow a specific format (eg images, test messages)
What is a Data Warehouse?
Wikipedia's explanation on Data Warehouse Amazon's explanation on Data Warehouse
What is Data Lake?
Data Lake - Wikipedia
Can you explain the difference between a data lake and a data warehouse?
What is "Data Versioning"? What models of "Data Versioning" are there?
What is ETL?
Apache Hadoop
Explain what is Hadoop
Apache Hadoop - Wikipedia
Explain Hadoop YARN
Responsible for managing the compute resources in clusters and scheduling users' applications
Explain Hadoop MapReduce
A programming model for large-scale data processing
Explain Hadoop Distributed File Systems (HDFS)
Distributed file system providing high aggregate bandwidth across the cluster.- For a user it looks like a regular file system structure but behind the scenes it's distributed across multiple machines in a cluster
- Typical file size is TB and it can scale and supports millions of files
- It's fault tolerant which means it provides automatic recovery from faults
- It's best suited for running long batch operations rather than live analysis
What do you know about HDFS architecture?
HDFS Architecture
Master-slave architecture- Namenode - master, Datanodes - slaves
- Files split into blocks
- Blocks stored on datanodes
- Namenode controls all metadata
Ceph
Explain what is Ceph
Ceph is an Open-Source Distributed Storage System designed to provide excellent performance, reliability, and scalability. It's often used in cloud computing environments and Data Centers. Verdadeiro ou Falso? Ceph favor consistency and correctness over performances
Verdadeiro Which services or types of storage Ceph supports?
Object (RGW)- Block (RBD)
- File (CephFS)
What is RADOS?
Reliable Autonomic Distributed Object Storage- Provides low-level data object storage service
- Strong Consistency
- Simplifies design and implementation of higher layers (block, file, object)
Describe RADOS software components
Monitor- Central authority for authentication, data placement, policy
- Coordination point for all other cluster components
- Protect critical cluster state with Paxos
- Gerente
- Aggregates real-time metrics (throughput, disk usage, etc.)
- Host for pluggable management functions
- 1 active, 1+ standby per cluster
- OSD (Object Storage Daemon)
Stores data on an HDD or SSD
- Services client IO requests
What is the workflow of retrieving data from Ceph?
The work flow is as follows: - The client sends a request to the ceph cluster to retrieve data:
Client could be any of the following
- Ceph Block Device
- Ceph Object Gateway
- Any third party ceph client
- The client retrieves the latest cluster map from the Ceph Monitor
- The client uses the CRUSH algorithm to map the object to a placement group. The placement group is then assigned to a OSD.
- Once the placement group and the OSD Daemon are determined, the client can retrieve the data from the appropriate OSD
What is the workflow of writing data to Ceph?
The work flow is as follows: - The client sends a request to the ceph cluster to retrieve data
- The client retrieves the latest cluster map from the Ceph Monitor
- The client uses the CRUSH algorithm to map the object to a placement group. The placement group is then assigned to a Ceph OSD Daemon dynamically.
- The client sends the data to the primary OSD of the determined placement group. If the data is stored in an erasure-coded pool, the primary OSD is responsible for encoding the object into data chunks and coding chunks, and distributing them to the other OSDs.
What are "Placement Groups"?
Describe in the detail the following: Objects -> Pool -> Placement Groups -> OSDs
What is OMAP?
What is a metadata server? Como funciona?
Packer
What is Packer? Para que é usado?
In general, Packer automates machine images creation. It allows you to focus on configuration prior to deployment while making the images. This allows you start the instances much faster in most cases.
Packer follows a "configuration->deployment" model or "deployment->configuration"?
A configuration->deployment which has some advantages like:
Deployment Speed - you configure once prior to deployment instead of configuring every time you deploy. This allows you to start instances/services much quicker.- More immutable infrastructure - with configuration->deployment it's not likely to have very different deployments since most of the configuration is done prior to the deployment. Issues like dependencies errors are handled/discovered prior to deployment in this model.
Liberar
Explain Semantic Versioning
This page explains it perfectly:
Given a version number MAJOR.MINOR.PATCH, increment the:
MAJOR version when you make incompatible API changes
MINOR version when you add functionality in a backwards compatible manner
PATCH version when you make backwards compatible bug fixes
Additional labels for pre-release and build metadata are available as extensions to the MAJOR.MINOR.PATCH format.
Certificados
If you are looking for a way to prepare for a certain exam this is the section for you. Here you'll find a list of certificates, each references to a separate file with focused questions that will help you to prepare to the exam. Boa sorte :)
AWS
- Cloud Practitioner (Latest update: 2020)
- Solutions Architect Associate (Latest update: 2021)
- Cloud SysOps Administration Associate (Latest update: Oct 2022)
Azul
- AZ-900 (Latest update: 2021)
Kubernetes
- Certified Kubernetes Administrator (CKA) (Latest update: 2022)
Additional DevOps and SRE Projects




Créditos
Thanks to all of our amazing contributors who make it easy for everyone to learn new things :)
Logos credits can be found here
Licença


