optuna
v4.1.0
? Site | ? Documentos | Guia de instalação | Tutorial | Exemplos | Twitter | LinkedIn | Médio
Optuna é uma estrutura de software de otimização automática de hiperparâmetros, especialmente projetada para aprendizado de máquina. Ele apresenta uma API de usuário imperativa, definida por execução . Graças à nossa API definida por execução , o código escrito com Optuna desfruta de alta modularidade e o usuário do Optuna pode construir dinamicamente os espaços de busca para os hiperparâmetros.
Terminator , que foi expandido no Optuna 4.0.JournalStorage , que está estabilizado no Optuna 4.0.pip install -U optuna . Encontre as últimas novidades aqui e confira nosso artigo. Optuna possui funcionalidades modernas como segue:
Usamos os termos estudo e tentativa da seguinte forma:
Consulte o código de exemplo abaixo. O objetivo de um estudo é descobrir o conjunto ideal de valores de hiperparâmetros (por exemplo, regressor e svr_c ) através de múltiplas tentativas (por exemplo, n_trials=100 ). Optuna é um framework desenvolvido para automação e aceleração de estudos de otimização.
import ...
# Define an objective function to be minimized.
def objective ( trial ):
# Invoke suggest methods of a Trial object to generate hyperparameters.
regressor_name = trial . suggest_categorical ( 'regressor' , [ 'SVR' , 'RandomForest' ])
if regressor_name == 'SVR' :
svr_c = trial . suggest_float ( 'svr_c' , 1e-10 , 1e10 , log = True )
regressor_obj = sklearn . svm . SVR ( C = svr_c )
else :
rf_max_depth = trial . suggest_int ( 'rf_max_depth' , 2 , 32 )
regressor_obj = sklearn . ensemble . RandomForestRegressor ( max_depth = rf_max_depth )
X , y = sklearn . datasets . fetch_california_housing ( return_X_y = True )
X_train , X_val , y_train , y_val = sklearn . model_selection . train_test_split ( X , y , random_state = 0 )
regressor_obj . fit ( X_train , y_train )
y_pred = regressor_obj . predict ( X_val )
error = sklearn . metrics . mean_squared_error ( y_val , y_pred )
return error # An objective value linked with the Trial object.
study = optuna . create_study () # Create a new study.
study . optimize ( objective , n_trials = 100 ) # Invoke optimization of the objective function. Observação
Mais exemplos podem ser encontrados em optuna/optuna-examples.
Os exemplos cobrem diversas configurações de problemas, como otimização multiobjetivo, otimização restrita, remoção e otimização distribuída.
Optuna está disponível no Python Package Index e no Anaconda Cloud.
# PyPI
$ pip install optuna # Anaconda Cloud
$ conda install -c conda-forge optunaImportante
Optuna suporta Python 3.8 ou mais recente.
Além disso, fornecemos imagens docker Optuna no DockerHub.
Optuna possui recursos de integração com diversas bibliotecas de terceiros. As integrações podem ser encontradas em optuna/optuna-integration e o documento está disponível aqui.
Optuna Dashboard é um painel da web em tempo real para Optuna. Você pode verificar o histórico de otimização, a importância dos hiperparâmetros, etc. em gráficos e tabelas. Você não precisa criar um script Python para chamar as funções de visualização do Optuna. Solicitações de recursos e relatórios de bugs são bem-vindos!
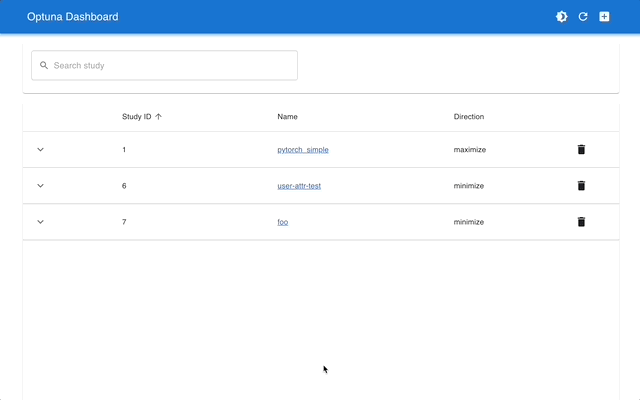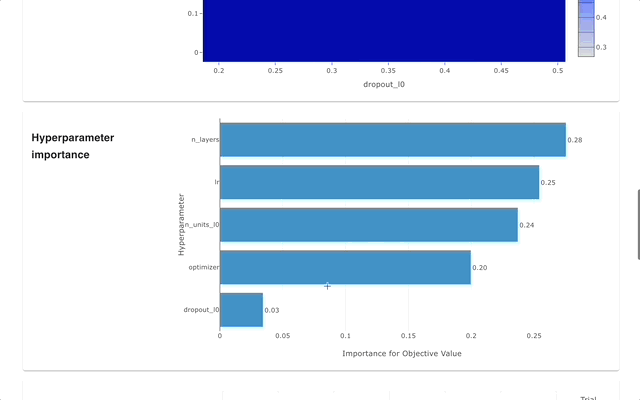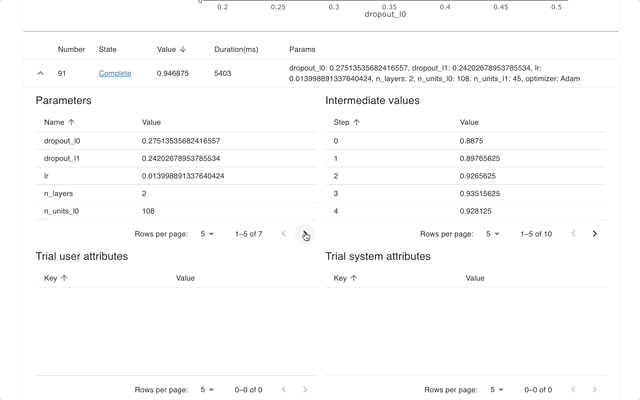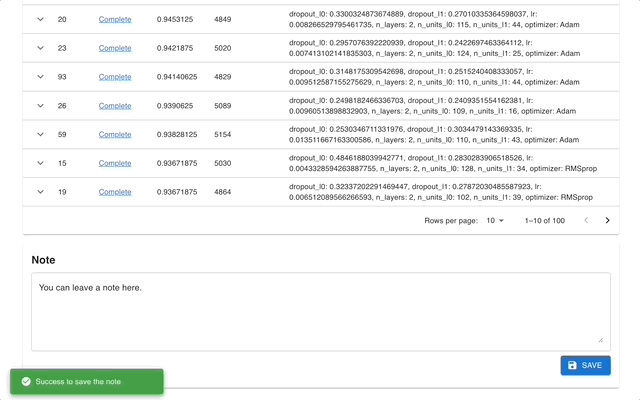
optuna-dashboard pode ser instalado via pip:
$ pip install optuna-dashboardDica
Verifique a conveniência do Optuna Dashboard usando o código de exemplo abaixo.
Salve o código a seguir como optimize_toy.py .
import optuna
def objective ( trial ):
x1 = trial . suggest_float ( "x1" , - 100 , 100 )
x2 = trial . suggest_float ( "x2" , - 100 , 100 )
return x1 ** 2 + 0.01 * x2 ** 2
study = optuna . create_study ( storage = "sqlite:///db.sqlite3" ) # Create a new study with database.
study . optimize ( objective , n_trials = 100 )Então tente os comandos abaixo:
# Run the study specified above
$ python optimize_toy.py
# Launch the dashboard based on the storage `sqlite:///db.sqlite3`
$ optuna-dashboard sqlite:///db.sqlite3
...
Listening on http://localhost:8080/
Hit Ctrl-C to quit.OptunaHub é uma plataforma de compartilhamento de recursos para Optuna. Você pode usar os recursos registrados e publicar seus pacotes.
optunahub pode ser instalado via pip:
$ pip install optunahub
# Install AutoSampler dependencies (CPU only is sufficient for PyTorch)
$ pip install cmaes scipy torch --extra-index-url https://download.pytorch.org/whl/cpu Você pode carregar o módulo registrado com optunahub.load_module .
import optuna
import optunahub
def objective ( trial : optuna . Trial ) -> float :
x = trial . suggest_float ( "x" , - 5 , 5 )
y = trial . suggest_float ( "y" , - 5 , 5 )
return x ** 2 + y ** 2
module = optunahub . load_module ( package = "samplers/auto_sampler" )
study = optuna . create_study ( sampler = module . AutoSampler ())
study . optimize ( objective , n_trials = 10 )
print ( study . best_trial . value , study . best_trial . params )Para obter mais detalhes, consulte a documentação do optunahub.
Você pode publicar seu pacote via optunahub-registry. Veja o tutorial do OptunaHub.
Quaisquer contribuições para Optuna são mais que bem-vindas!
Se você é novo no Optuna, verifique as primeiras questões boas. Eles são pontos de partida relativamente simples, bem definidos e geralmente bons para você se familiarizar com o fluxo de trabalho de contribuição e com outros desenvolvedores.
Se você já contribuiu para a Optuna, recomendamos as demais questões de boas-vindas à contribuição.
Para orientações gerais sobre como contribuir com o projeto, dê uma olhada em CONTRIBUTING.md.
Se você usa Optuna em um de seus projetos de pesquisa, cite nosso artigo KDD "Optuna: uma estrutura de otimização de hiperparâmetros de última geração":
@inproceedings { akiba2019optuna ,
title = { {O}ptuna: A Next-Generation Hyperparameter Optimization Framework } ,
author = { Akiba, Takuya and Sano, Shotaro and Yanase, Toshihiko and Ohta, Takeru and Koyama, Masanori } ,
booktitle = { The 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining } ,
pages = { 2623--2631 } ,
year = { 2019 }
}Licença MIT (ver LICENÇA).
Optuna usa os códigos dos projetos SciPy e fdlibm (consulte LICENSE_THIRD_PARTY).


