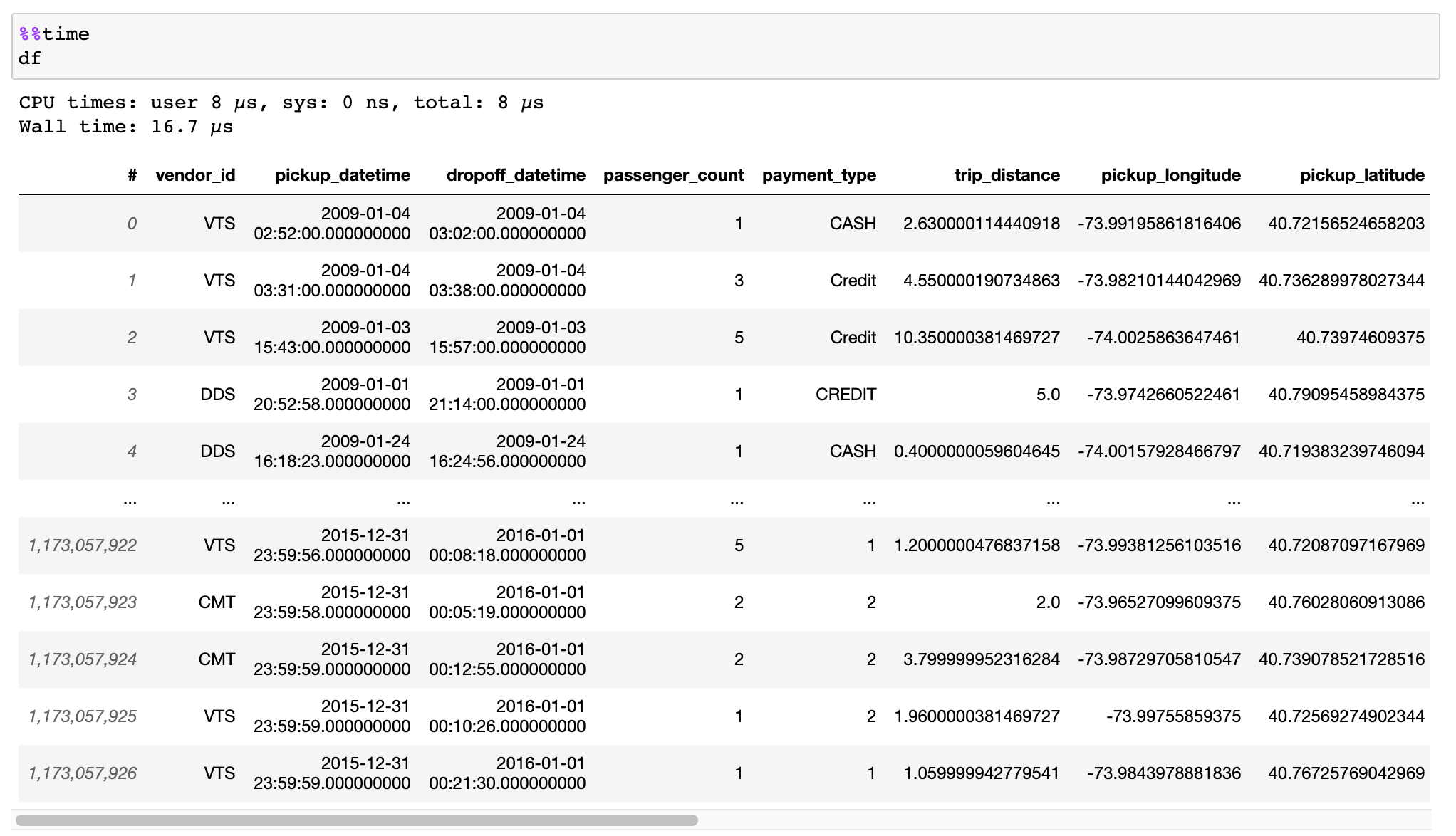
vaex
Version linked to the paper
Vaex é uma biblioteca Python de alto desempenho para DataFrames out-of-core preguiçosos (semelhantes ao Pandas), para visualizar e explorar grandes conjuntos de dados tabulares. Ele calcula estatísticas como média, soma, contagem, desvio padrão, etc., em uma grade N-dimensional para mais de um bilhão ( 10^9 ) de amostras/linhas por segundo . A visualização é feita usando histogramas , gráficos de densidade e renderização de volume 3D , permitindo a exploração interativa de big data. Vaex usa mapeamento de memória, política de cópia de memória zero e cálculos lentos para melhor desempenho (sem desperdício de memória).
Com pip:
$ pip install vaex
Ou conda:
$ conda install -c conda-forge vaex
Para mais detalhes, consulte a documentação
HDF5 e Apache Arrow suportados.

Leia a documentação sobre como converter com eficiência seus dados de arquivos CSV, Pandas DataFrames ou outras fontes.
Streaming lento do S3 com suporte em combinação com mapeamento de memória.

Não desperdice memória ou tempo com engenharia de recursos, nós (preguiçosamente) transformamos seus dados quando necessário.
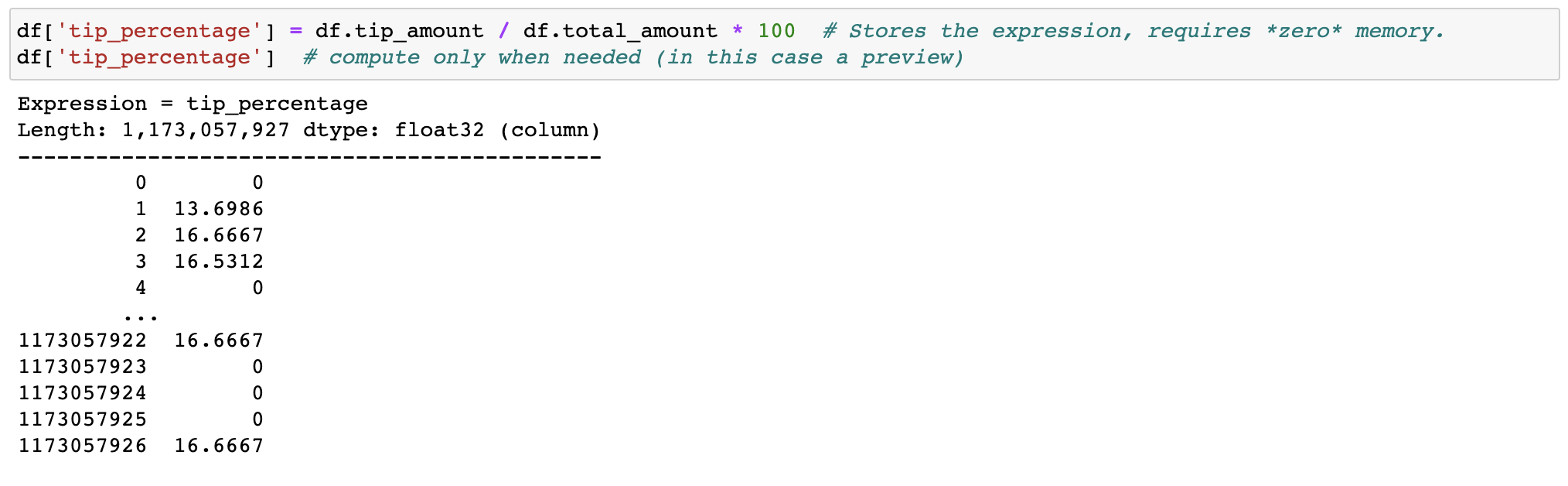
Filtrar e avaliar expressões não desperdiçará memória fazendo cópias; os dados são mantidos intactos no disco e serão transmitidos somente quando necessário. Adie o tempo antes de precisar de um cluster.
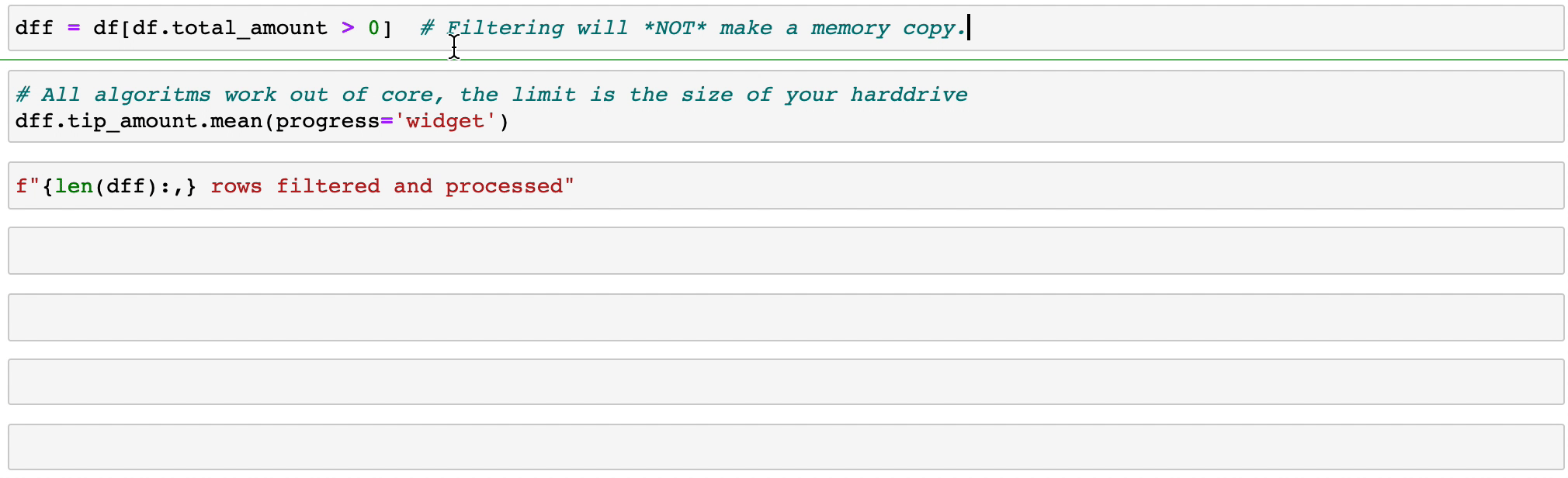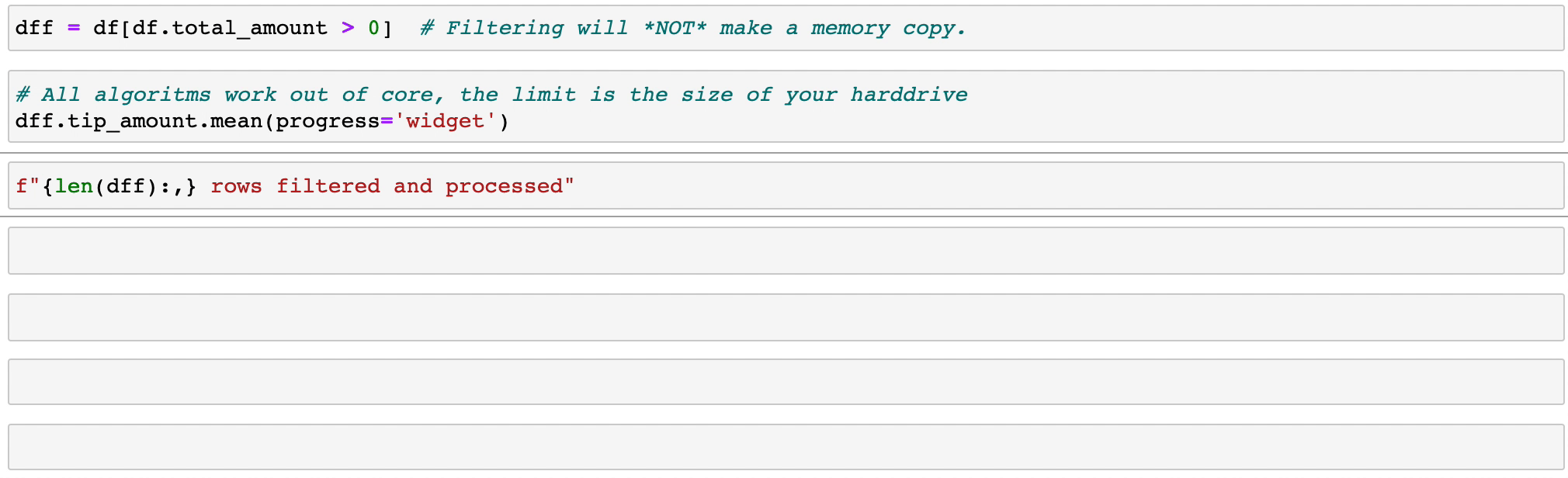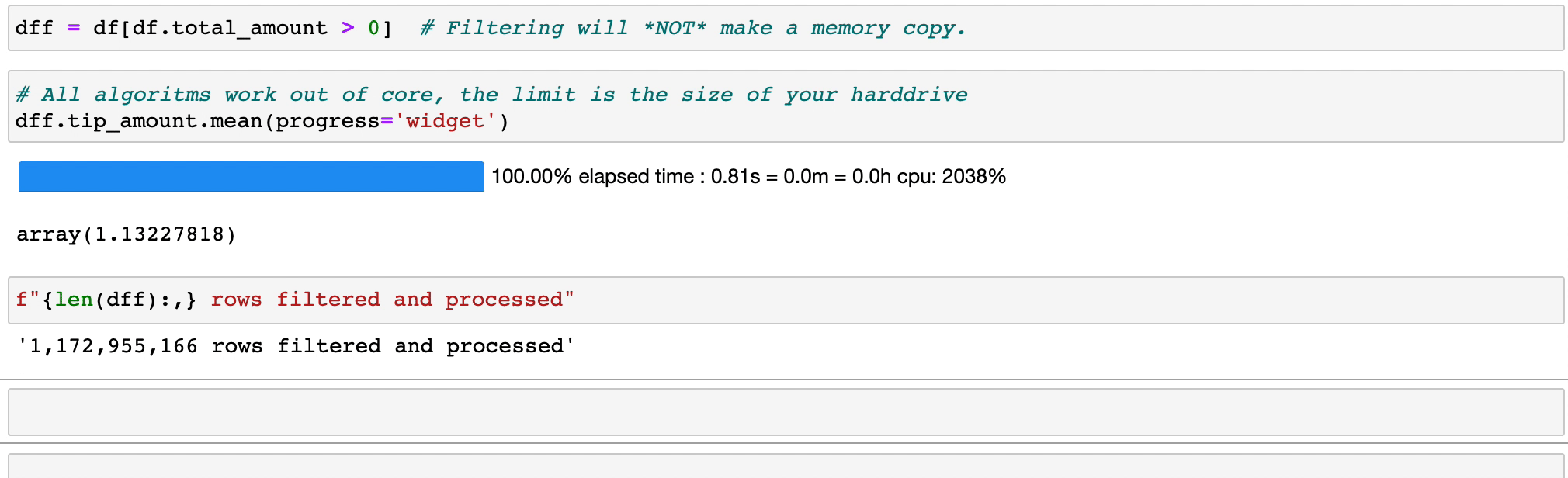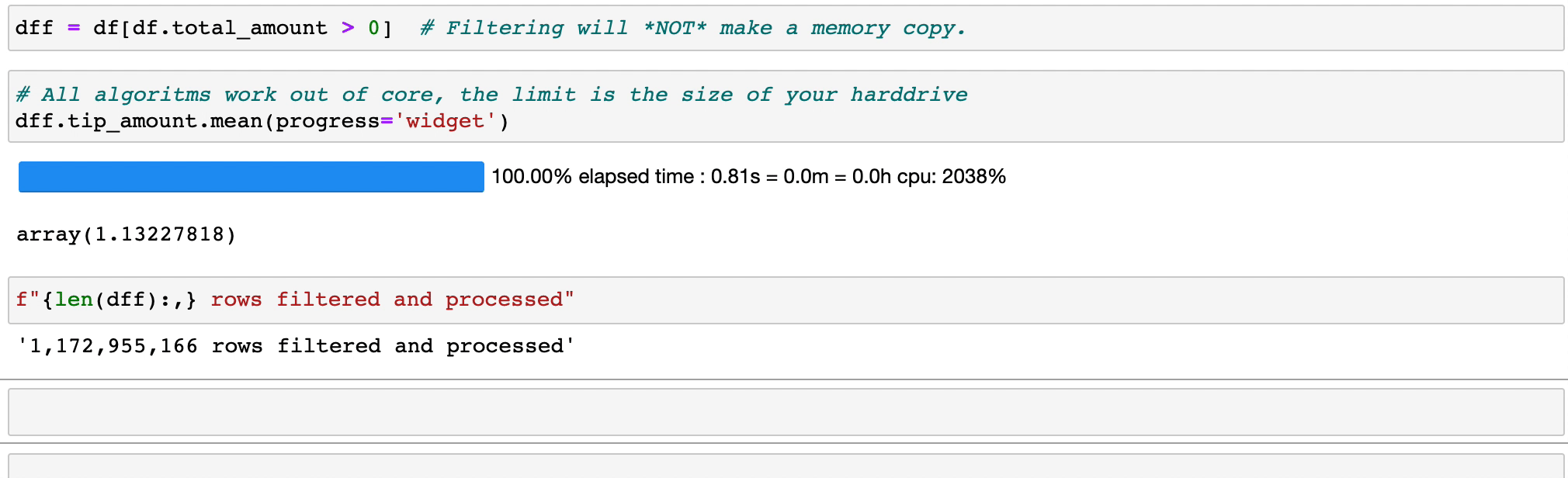
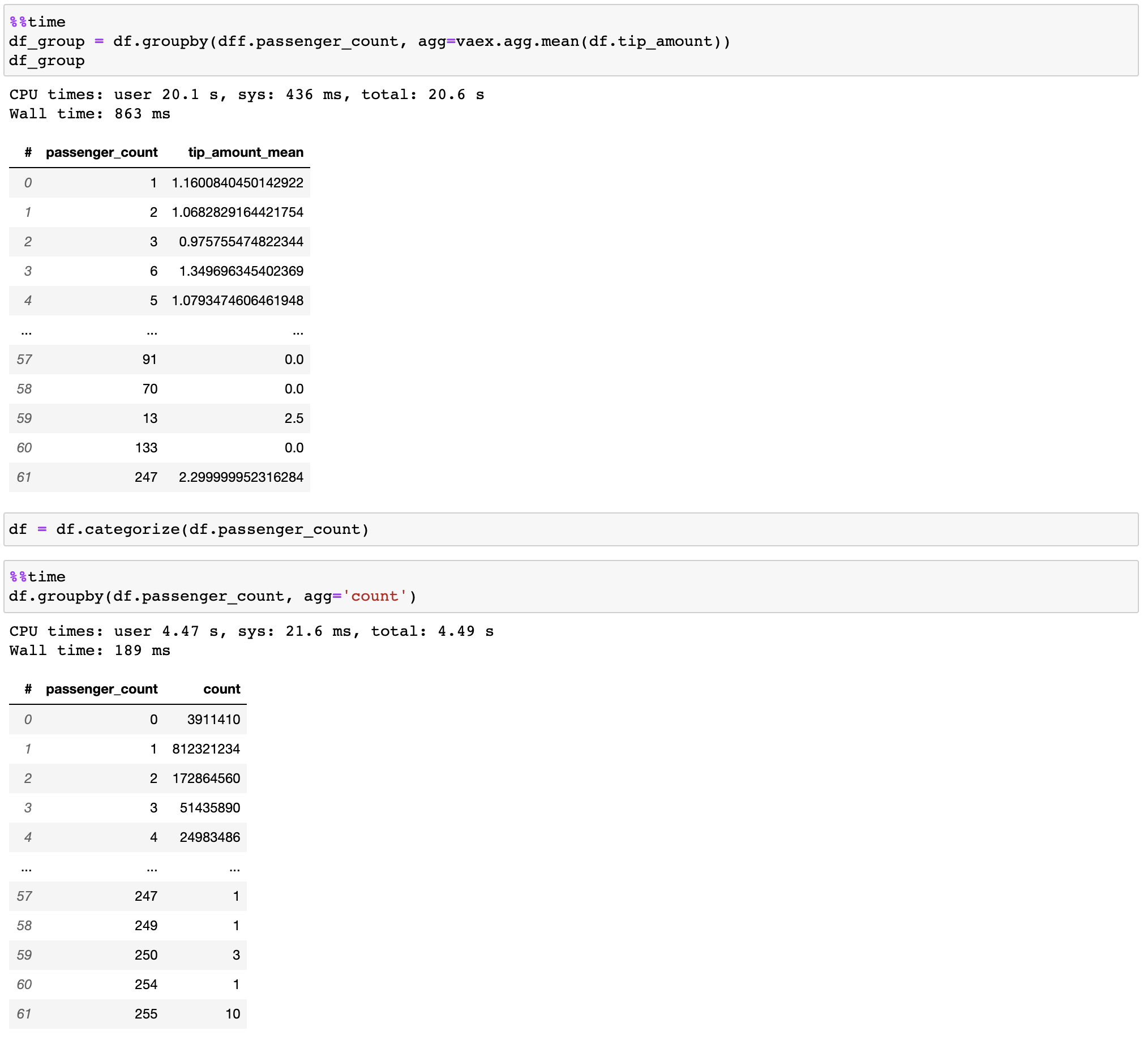
Vaex implementa operações groupby paralelizadas e de alto desempenho, especialmente ao usar categorias (>1 bilhão/segundo).
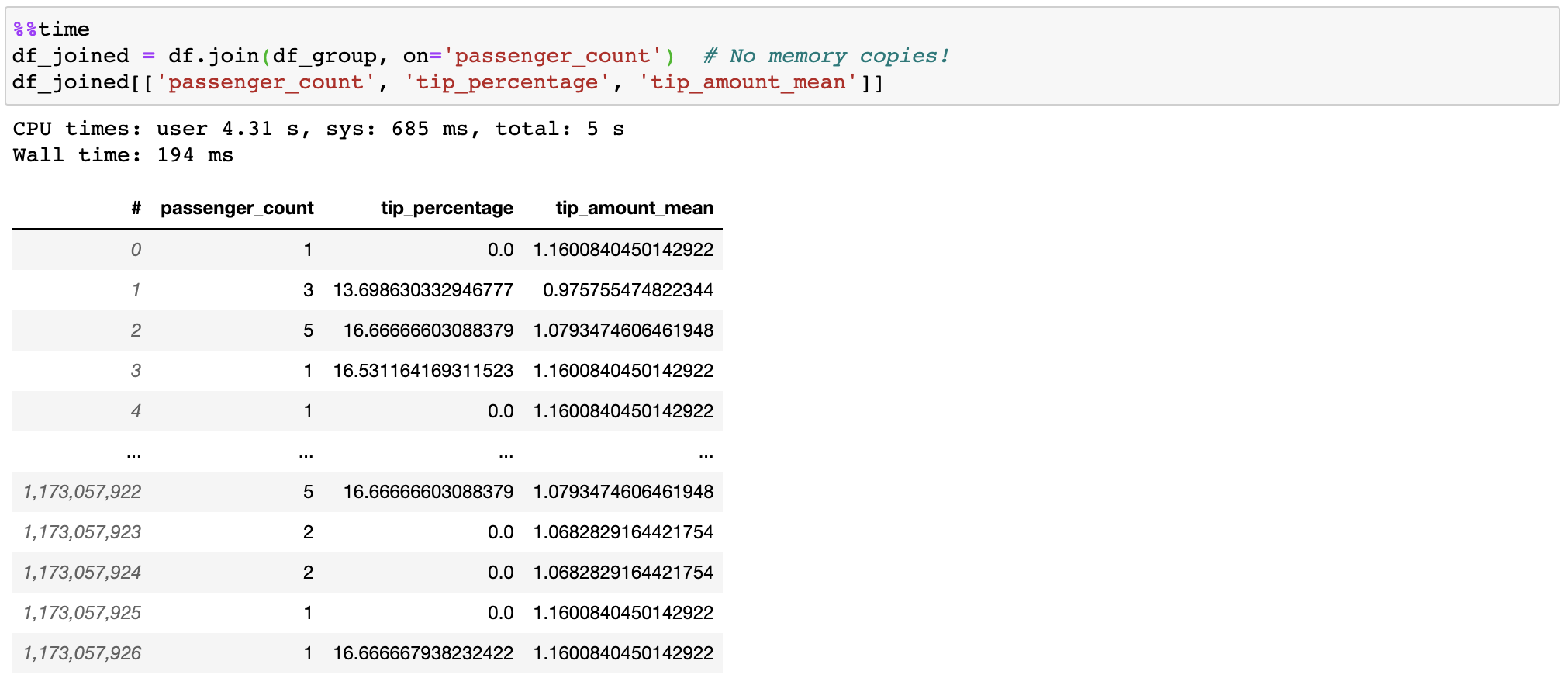
Vaex não copia/materializa a tabela ‘certa’ ao ingressar, economizando gigabytes de memória. Com a junção de subsegundos em um bilhão de linhas, é muito rápido!
Veja a página de contribuição.
Participe da discussão em nosso canal Slack!
Artigos
Siga nossos tutoriais
Assista às nossas palestras mais recentes:
Contate-nos para soluções de ciência de dados, treinamento ou suporte empresarial em https://vaex.io/


