bean searcher
v4.3.5

Inglês | 中文
Documentação: https://bs.zhxu.cn
阿里云最低 1 折:https://www.aliyun.com/minisite/goods?userCode=zugtbi5w
Blogs JueJin:
Apenas uma linha de código para alcançar:
Design thinking: o pensamento do Bean Searcher
Arquitetura:
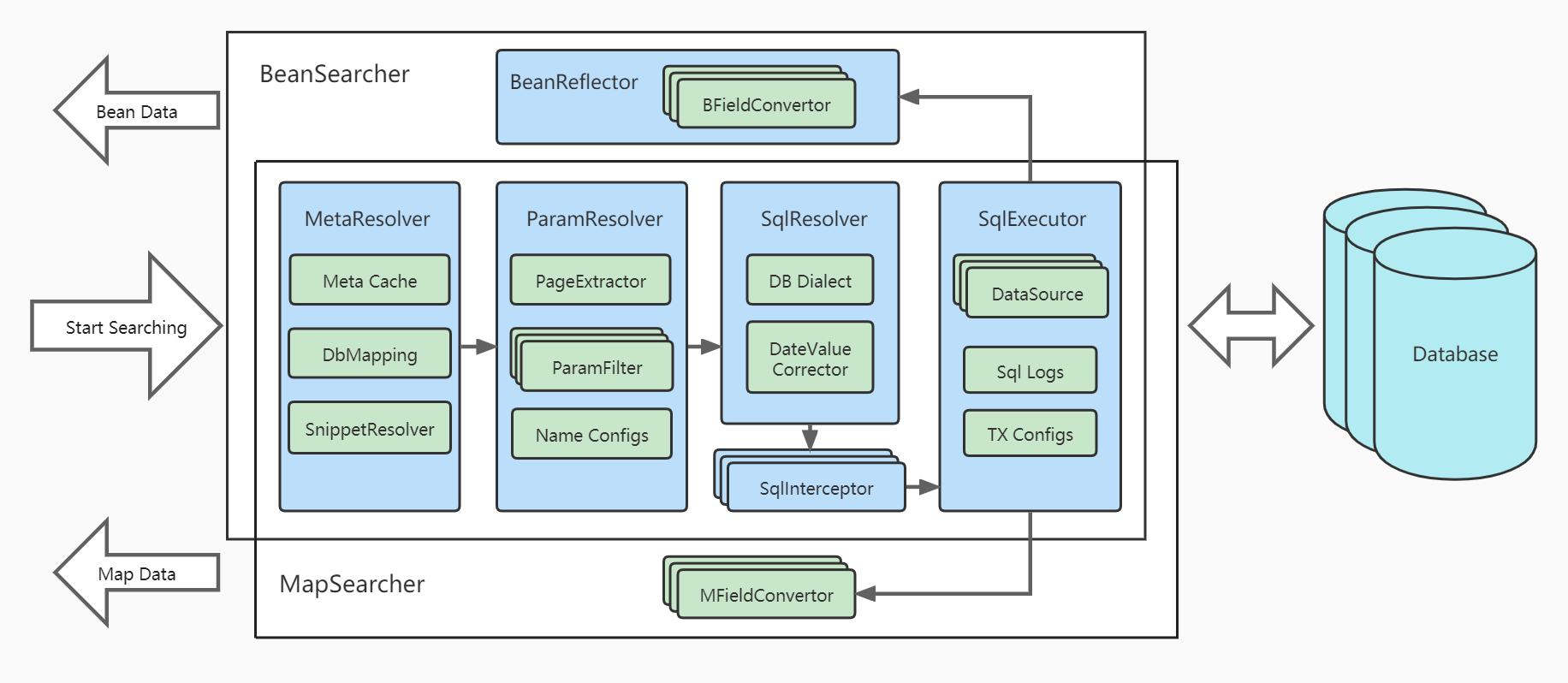
Embora CREATE/UPDATE/DELETE sejam os pontos fortes do Hibernate, MyBatis, DataJDBC e outros ORM, consultas, especialmente consultas de lista complexas com múltiplas condições , múltiplas tabelas , paginação , classificação , sempre foram seus pontos fracos.
ORM tradicional é difícil de realizar uma recuperação de lista complexa com menos código, mas o Bean Searcher tem feito grandes esforços nesse sentido. Essas consultas complexas podem ser resolvidas em quase uma linha de código.
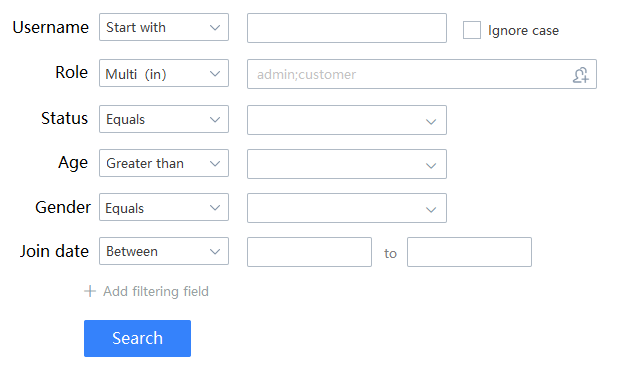
O back-end precisa escrever uma API de recuperação e, se for escrito com ORM tradicional, a complexidade do código será muito alta
Mas o Bean Searcher pode:
Primeiro, você tem uma classe Entity:
@ SearchBean ( tables = "user u, role r" , joinCond = "u.role_id = r.id" , autoMapTo = "u" )
public class User {
private long id ;
private String username ;
private int status ;
private int age ;
private String gender ;
private Date joinDate ;
private int roleId ;
@ DbField ( "r.name" )
private String roleName ;
// Getters and setters...
}Então você pode completar a API com uma linha de código:
@ RestController
@ RequestMapping ( "/user" )
public class UserController {
@ Autowired
private BeanSearcher beanSearcher ; // Inject BeanSearcher
@ GetMapping ( "/index" )
public SearchResult < User > index ( HttpServletRequest request ) {
// Only one line of code written here
return beanSearcher . search ( User . class , MapUtils . flat ( request . getParameterMap ()), new String []{ "age" });
}
}Esta linha de código pode alcançar:
agePor exemplo, esta API pode ser solicitada da seguinte forma:
GET: /user/index
Recuperando por paginação padrão:
{
"dataList" : [
{
"id" : 1 ,
"username" : " Jack " ,
"status" : 1 ,
"age" : 25 ,
"gender" : " Male " ,
"joinDate" : " 2021-10-01 " ,
"roleId" : 1 ,
"roleName" : " User "
},
... // 15 records default
],
"totalCount" : 100 ,
"summaries" : [
2500 // age statistics
]
} GET: /user/index? page=1 & size=10
Recuperação por paginação especificada
GET: /user/index? status=1
Recuperação com status = 1 por paginação padrão
GET: /user/index? name=Jac & name-op=sw
Recuperação com name começando com Jac por paginação padrão
GET: /user/index? name=Jack & name-ic=true
Recuperação com name = Jack (caso ignorado) por paginação padrão
GET: /user/index? sort=age & order=desc
Classificação de recuperação por age decrescente e por paginação padrão
GET: /user/index? onlySelect=username,age
username,age apenas por paginação padrão:
{
"dataList" : [
{
"username" : " Jack " ,
"age" : 25 ,
},
... // 15 records default
],
"totalCount" : 100 ,
"summaries" : [
2500 // age statistics
]
} GET: /user/index? selectExclude=joinDate
Recuperando a paginação padrão excluída joinDate
Map < String , Object > params = MapUtils . builder ()
. selectExclude ( User :: getJoinDate ) // Exclude joinDate field
. field ( User :: getStatus , 1 ) // Filter:status = 1
. field ( User :: getName , "Jack" ). ic () // Filter:name = 'Jack' (case ignored)
. field ( User :: getAge , 20 , 30 ). op ( Opetator . Between ) // Filter:age between 20 and 30
. orderBy ( User :: getAge , "asc" ) // Sorting by age ascending
. page ( 0 , 15 ) // Pagination: page=0 and size=15
. build ();
List < User > users = beanSearcher . searchList ( User . class , params );Demonstrações :
Usar o Bean Searcher pode economizar muito o tempo de desenvolvimento das complexas APIs de recuperação de lista!
domain original, sem definir uma nova EntityBean Searcher pode funcionar com qualquer framework JavaWeb, como: SpringBoot, SpringMVC, Grails, Jfinal e assim por diante.
Tudo que você precisa é adicionar uma dependência:
implementation ' cn.zhxu:bean-searcher-boot-stater:4.3.4 ' e então você pode injetar Searcher em um Controller ou Service :
/**
* Inject a MapSearcher, which retrieved data is Map objects
*/
@Autowired
private MapSearcher mapSearcher;
/**
* Inject a BeanSearcher, which retrieved data is generic objects
*/
@Autowired
private BeanSearcher beanSearcher;Tudo que você precisa é adicionar uma dependência:
implementation ' cn.zhxu:bean-searcher-solon-plugin:4.3.4 ' e então você pode injetar Searcher em um Controller ou Service :
/**
* Inject a MapSearcher, which retrieved data is Map objects
*/
@Inject
private MapSearcher mapSearcher;
/**
* Inject a BeanSearcher, which retrieved data is generic objects
*/
@Inject
private BeanSearcher beanSearcher;Adicionando esta dependência:
implementation ' cn.zhxu:bean-searcher:4.3.4 ' então você pode construir um Searcher com SearcherBuilder :
DataSource dataSource = ... // Get the dataSource of the application
// DefaultSqlExecutor suports multi datasources
SqlExecutor sqlExecutor = new DefaultSqlExecutor ( dataSource );
// build a MapSearcher
MapSearcher mapSearcher = SearcherBuilder . mapSearcher ()
. sqlExecutor ( sqlExecutor )
. build ();
// build a BeanSearcher
BeanSearcher beanSearcher = SearcherBuilder . beanSearcher ()
. sqlExecutor ( sqlExecutor )
. build ();Você pode personalizar e estender qualquer componente no Bean Searcher.
Por exemplo:
FieldOp para oferecer suporte a outro operador de campoDbMapping para suportar anotações de outros ORMParamResolver para oferecer suporte a parâmetros de consulta JSONFieldConvertor para suportar qualquer tipo de campoDialect para suportar mais banco de dadosReferência: https://bs.zhxu.cn
[ Sa-Token ]一个轻量级 Java 权限认证框架,让鉴权变得简单、优雅!
[ Fluent MyBatis ] MyBatis 语法增强框架, 综合了 MyBatisPlus, DynamicSql,Jpa 等框架的特性和优点,利用注解处理器生成代码
[ OkHttps ]轻量却强大的 HTTP 客户端,前后端通用,支持 WebSocket 与 Stomp 协议
[ hrun4j ]接口自动化测试解决方案 --工具选得好,下班回家早;测试用得对,半夜安心睡
[JsonKit]超轻量级 JSON 门面工具,用法简单,不依赖具体实现,让业务代码与 Jackson, Gson, Fastjson 等解耦!
[ UI gratuita ]基于 Vue3 + TypeScript,一个非常轻量炫酷的 UI 组件库 !
git checkout -b feat/xxxxgit commit -am 'feat(function): add xxxxx'git push origin feat/xxxxpull request

