genai_robotics
1.0.0
Este repositório contém uma configuração experimental com reconhecimento de privacidade para aproveitar métodos generativos de IA no controle robótico. Com a solução aqui apresentada, um usuário pode definir livremente ações por voz que são traduzidas em planos que um robô aspirador pode executar em um ambiente de mundo aberto que é observado por uma câmera.
As vantagens fundamentais dos métodos aqui apresentados são:
O sistema foi desenvolvido em um hackathon de 3 dias como um exercício de aprendizagem e prova de conceito de que ferramentas modernas de IA podem reduzir significativamente o tempo de desenvolvimento de soluções de controle robótico.
Para usar todos os recursos deste repositório, aqui está o que você deve ter:
Para começar, siga as etapas abaixo:
requirements.txt em um ambiente Python (testes com Python 3.11)src/config.template.toml para config.toml . Para todas as etapas abaixo, insira as credenciais adquiridas em config.tomlpython-roborock .src/run.py para executar o fluxo de trabalho. A melhor maneira de entender detalhadamente o que este repositório faz e como os elementos interagem é por meio de um diagrama de arquitetura:
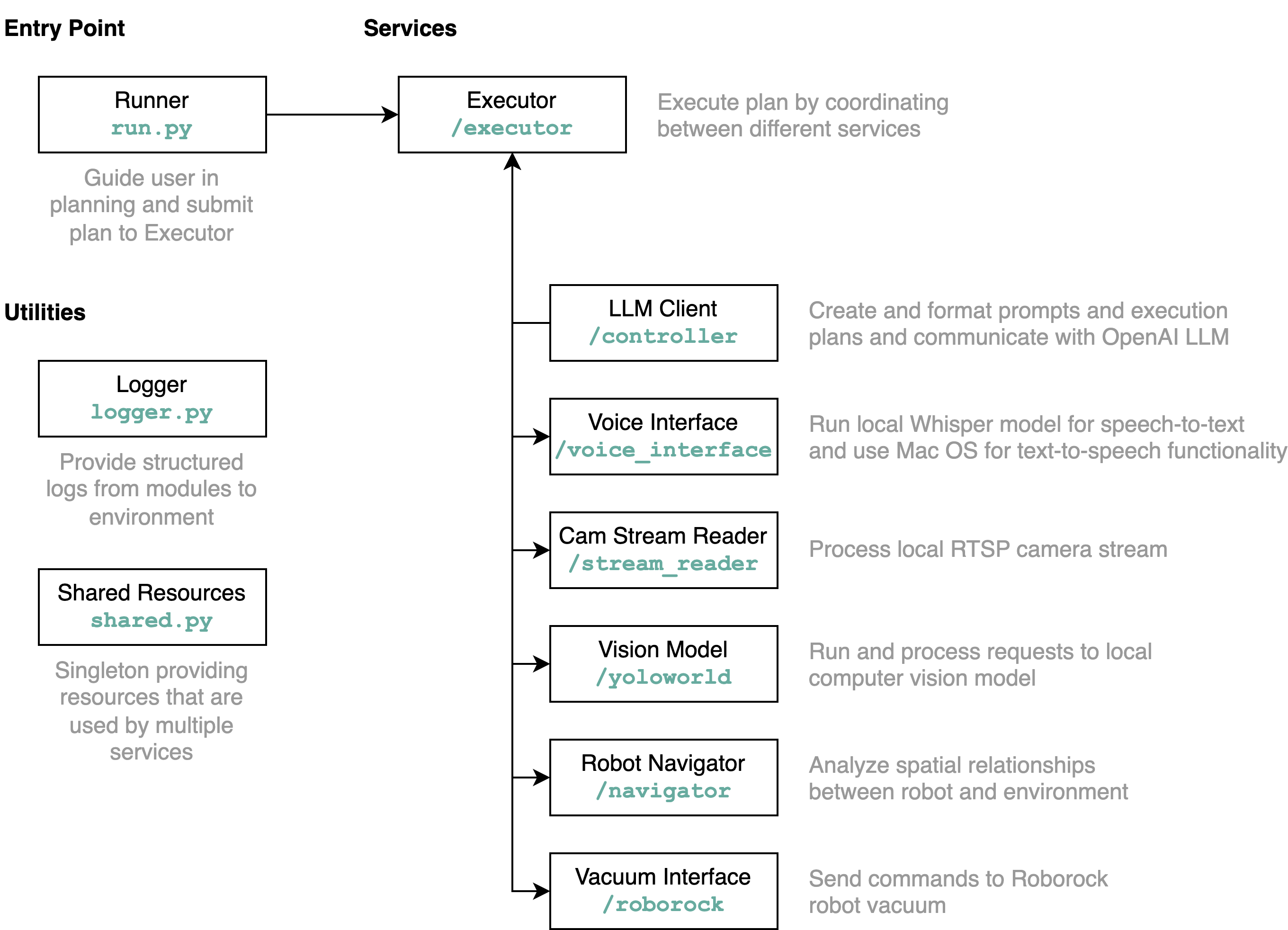
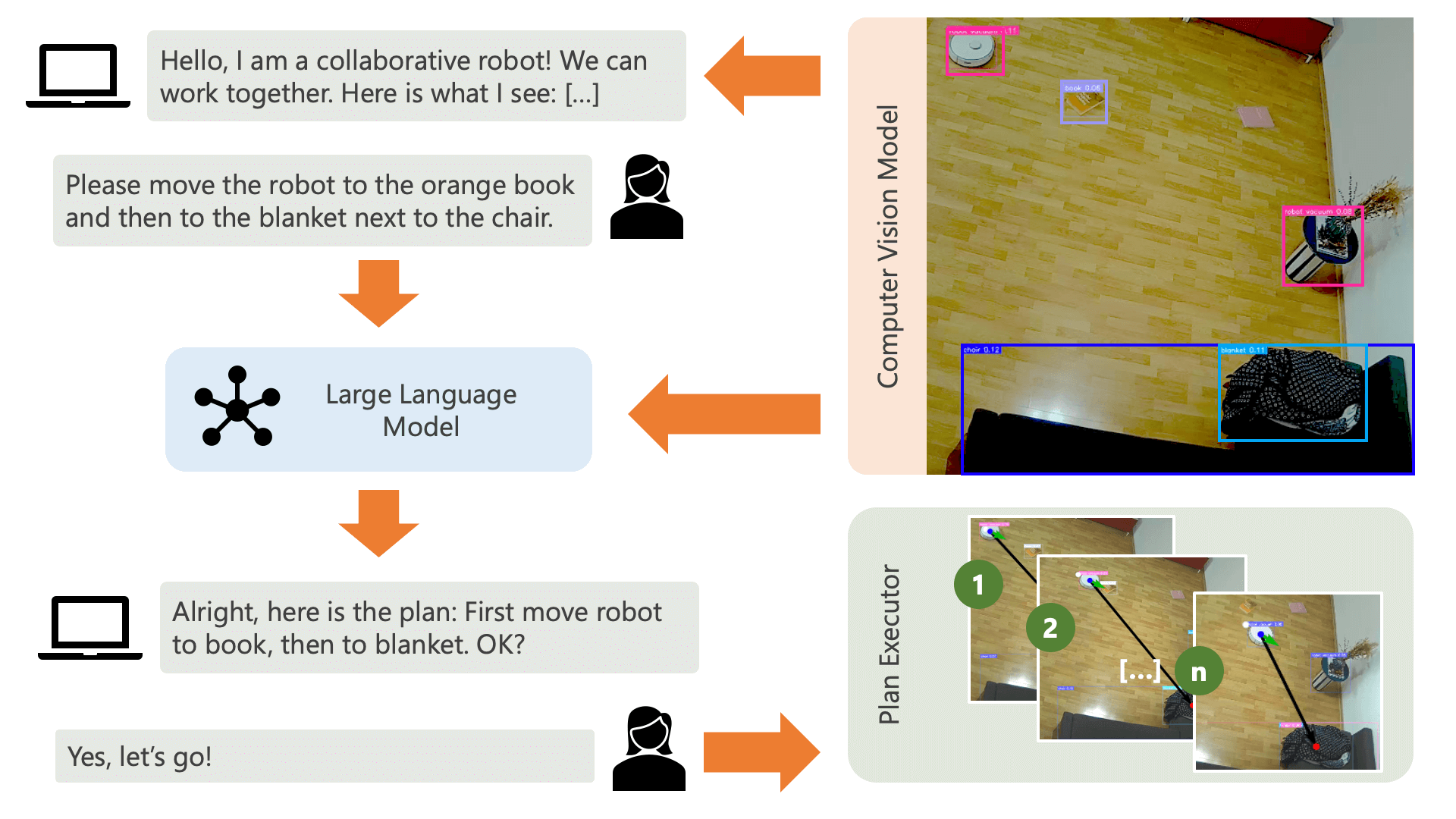
Quando você executa o arquivo run.py conforme descrito acima, aqui está o que acontece e como funciona:
O sistema cumprimenta o usuário com uma mensagem de áudio e espera que ele diga ao sistema o que deseja fazer. Por exemplo, um usuário pode querer que o robô pegue um café de uma pessoa sentada em uma cadeira amarela e o transporte para outra pessoa sentada em um sofá preto. O sistema criaria então um plano para executar essas ações.
O que o sistema precisa para entender como pode alcançar o que o usuário deseja? O sistema precisa estar ciente de seu ambiente e das ações que podem ser executadas neste ambiente. Aqui, usamos um modelo de visão computacional com detecção de objetos para fornecer informações sobre o ambiente ao sistema. O próprio aspirador pode executar 3 ações simples: avançar, virar e não fazer nada. Outra ação no ambiente é aguardar que o usuário execute determinada ação.
Para evitar confusão por parte do usuário, é importante que ele saiba como a IA percebe seu ambiente. Por exemplo, se um objeto não for reconhecido pelo modelo de visão computacional, a IA não conseguirá incluí-lo num plano. Também é importante que o usuário esteja ciente de que existe incerteza quanto ao reconhecimento dos modelos. Usando o modelo de linguagem grande GPT-4o da OpenAI com o prompt de descrição, o sistema apresenta uma explicação de seu ambiente e a lê para o usuário antes de perguntar ao usuário o que ele deseja que o sistema faça.
Dadas as informações do ambiente e a opinião do usuário sobre o que deseja fazer, o sistema pode então elaborar um plano. Aqui, pedimos ao LLM que elabore um plano, levando em consideração as informações do usuário e a descrição do ambiente. Você pode encontrar o modelo de prompt no diretório controller . O truque interessante aqui é que o LLM só tem conhecimento de seu ambiente por meio de duas tabelas geradas a partir dos resultados do modelo de visão computacional. Aqui está um exemplo:
Item locations:
| id | label | position | confidence | color_rgb |
|-----:|:-------------|:----------------|-------------:|:----------------|
| 0 | robot vacuum | (122.0, 140.0) | 0.23 | [205, 206, 210] |
| 1 | blanket | (1697.0, 923.0) | 0.59 | [60, 72, 90] |
| 2 | chair | (532.5, 210.0) | 0.39 | [177, 177, 171] |
| 3 | chair | (160.0, 521.5) | 0.24 | [99, 99, 98] |
| 4 | book | (1216.5, 601.0) | 0.2 | [137, 141, 155] |
Distances:
| id | 0 | 1 | 2 | 3 | 4 |
|-----:|-----:|-----:|-----:|-----:|-----:|
| 0 | 0 | 1758 | 416 | 383 | 1187 |
| 1 | 1758 | 0 | 1365 | 1588 | 578 |
| 2 | 416 | 1365 | 0 | 485 | 787 |
| 3 | 383 | 1588 | 485 | 0 | 1059 |
| 4 | 1187 | 578 | 787 | 1059 | 0 |
Depois que o LLM tiver processado o prompt de planejamento, ele produzirá duas coisas: o raciocínio e o plano. Antes de o sistema prosseguir com a execução do plano, ele usará o prompt de explicação para gerar um breve resumo do plano com o objetivo de obter a confirmação do usuário de que o plano corresponde ao que ele pediu para fazer. Isto está no espírito de uma abordagem human-in-the-loop, onde operamos a partir do ponto de vista de que, num ambiente físico real e aberto, as pessoas podem ser potencialmente prejudicadas pelas ações da IA, por isso é razoável pedir ajuda humana. feedback antes que a IA prossiga a execução de qualquer plano que ela mesma tenha elaborado.
Após a confirmação do usuário, o sistema prossegue com a execução do plano. Tal plano, conforme gerado pelo LLM, pode ser assim:
[
{ "action" : " MOVE " , "location" : [ 1216.5 , 601.0 ]},
{ "action" : " WAIT_UNTIL " , "task_fulfilled" : " Please place the book on the robot vacuum so that the robot can transport it to the chair. " },
{ "action" : " MOVE " , "location" : [ 532.5 , 210.0 ]},
{ "action" : " END " }
] Usando o executor , o sistema executa o plano passo a passo. Para reduzir qualquer tempo de configuração necessário, o controle do robô segue um algoritmo simples, impreciso, mas eficaz:
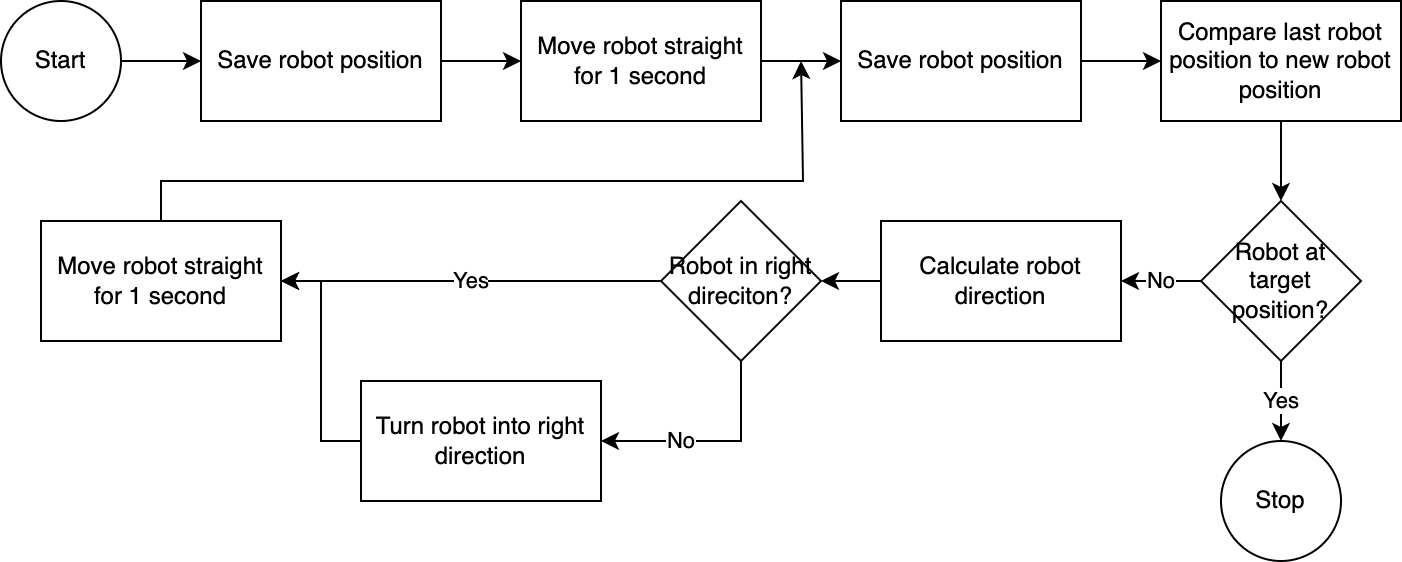
O sistema de visão computacional avalia a posição do robô. Através do código no módulo navigator , a posição do robô em relação à sua posição alvo e em relação à sua última posição conhecida é analisada e comparada. Esta abordagem é imperfeita porque a posição e a distorção da lente da câmera não são levadas em consideração. Os ângulos medidos através desta abordagem são imprecisos. No entanto, como o sistema é iterativo, os erros são frequentemente compensados. No entanto, é importante notar que isso tem um custo de velocidade. O sistema é lento, pois leva tempo para analisar a imagem, calcular um caminho e informar ao robô os próximos passos a serem seguidos.
Assim que o robô atingir sua posição alvo, o executor prossegue com a próxima etapa do plano. Para ações em que a entrada do usuário está envolvida, o executor usará a funcionalidade de conversão de texto em fala e de fala em texto para interagir com o usuário.
Neste sistema, usamos principalmente serviços executados em uma máquina ou rede local. A exceção é GPT-4o. Enviamos dados de texto para o modelo OpenAI pela internet. Os dados de texto incluem entradas transcritas do usuário e uma tabela de objetos reconhecidos. A única razão pela qual usamos o GPT-4o aqui é porque este é um dos melhores modelos disponíveis no momento do hackathon – também poderíamos executar um LLM local e então trabalhar totalmente sem conexão com a internet, preservando a privacidade de todo o fluxo de operações.
O modelo de visão computacional incluído neste repositório foi produzido pelo modelo YOLO-World em um espaço HuggingFace com o seguinte prompt: chair, book, candle, blanket, vase, bulb, robot vacuum, mug, glass, human . Se desejar reconhecer objetos adicionais, ajuste o prompt e baixe um modelo ONNX através deste espaço. Você pode então substituir o modelo no diretório src/yoloworld/models/rev0 .
Observe que para extrair o modelo corretamente, você precisa alterar manualmente o número máximo de caixas e os parâmetros de limite de pontuação no espaço HuggingFace antes de exportar o modelo.
Você pode aprender mais sobre o emocionante modelo YOLO-World, construído com base nos avanços recentes na modelagem de linguagem de visão no site YOLO-World.
Este projeto é publicado sob a licença MIT.
Este repositório não é monitorado ativamente e não há intenção de aumentá-lo – é antes de tudo um exercício de aprendizagem. No entanto, se você se sentir inspirado, sinta-se à vontade para contribuir com o projeto abrindo um problema no GitHub ou pull request.


