RagHack - Aplicativo GenAI Fitness Advisor
Definição do problema:
Orientação de condicionamento físico personalizada : MyFitnessBuddy é um aplicativo GenAI Fitness Advisor que fornece rotinas de exercícios personalizadas, planos de dieta e uma calculadora de calorias alimentares, abordando as limitações de aplicativos de condicionamento físico genéricos.
Geração Aumentada de Recuperação Avançada : Aproveita uma abordagem híbrida que combina Geração Aumentada de Recuperação (RAG) e Geração Aumentada de Recuperação de Gráfico (GRAG) para fornecer respostas precisas e conscientes do contexto às consultas do usuário.
Apresentando inovação no RAGHack : Desenvolvido para o hackathon RAGHack, MyFitnessBuddy demonstra o poder das tecnologias RAG na criação de soluções de fitness envolventes e eficazes baseadas em IA usando Azure AI e estruturas populares.
Arquitetura e Implementação:
Visão geral da arquitetura:
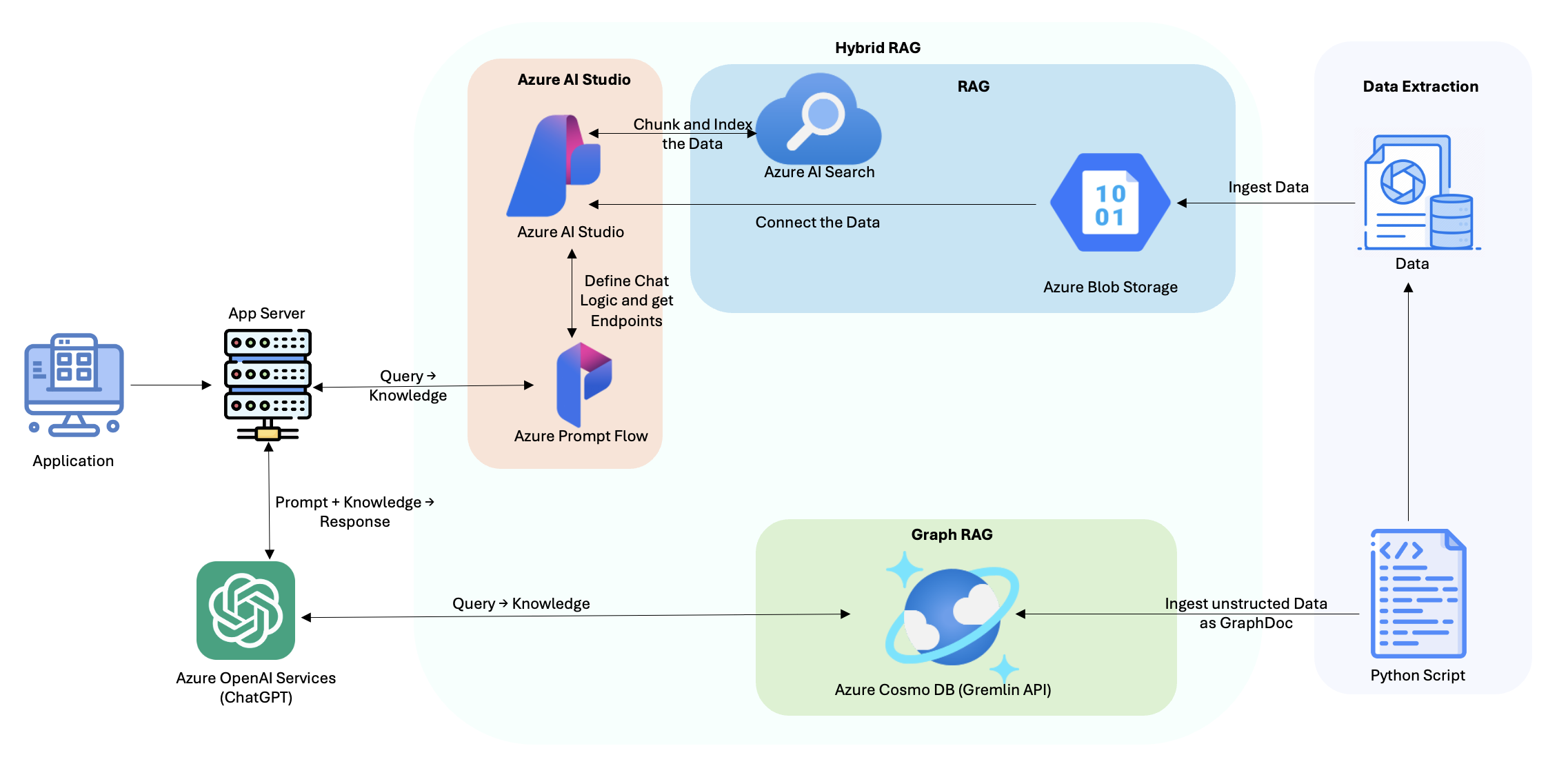
Fig.1 Arquitetura
MyFitnessBuddy usa uma arquitetura híbrida combinando Geração Aumentada de Recuperação (RAG) e Geração Aumentada de Recuperação de Gráfico (GRAG). Os dados são extraídos usando um script Python e ingeridos no Azure Blob Storage para dados estruturados e no Azure Cosmos DB (Gremlin API) para dados não estruturados. O Azure AI Search indexa os dados estruturados, enquanto a base de dados gráfica gere relações complexas nos dados não estruturados. O aplicativo utiliza o Azure AI Studio e o Prompt Flow para definir a lógica do chat e conectar fontes de dados. As consultas dos utilizadores são processadas pelo servidor de aplicações, recuperando informações relevantes do Azure AI Search e do Cosmos DB, que são então enviadas para Azure OpenAI Services (ChatGPT) para gerar respostas personalizadas. Essa abordagem híbrida garante orientação de condicionamento físico precisa, contextual e personalizada para os usuários.
Visão geral da implementação:
Extração e ingestão de dados:
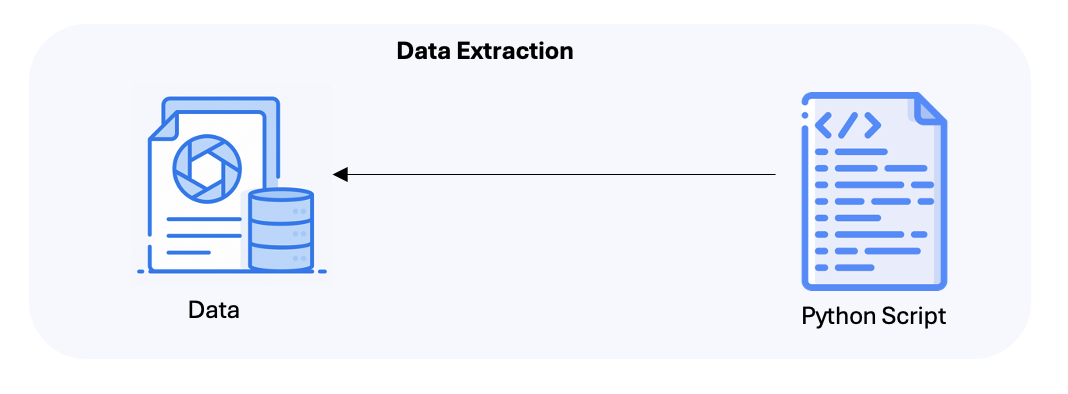
Fig 2. Arquitetura de extração de dados
- O processo começa com um script Python que extrai dados estruturados e não estruturados de diversas fontes. Esses dados são então ingeridos em dois sistemas de armazenamento diferentes:
- Armazenamento de Blobs do Azure: usado para dados estruturados, que são fragmentados e indexados.
- Azure Cosmos DB (API Gremlin): usado para dados não estruturados, ingeridos como GraphDoc para permitir a recuperação baseada em gráfico.
Abordagem RAG Híbrida:
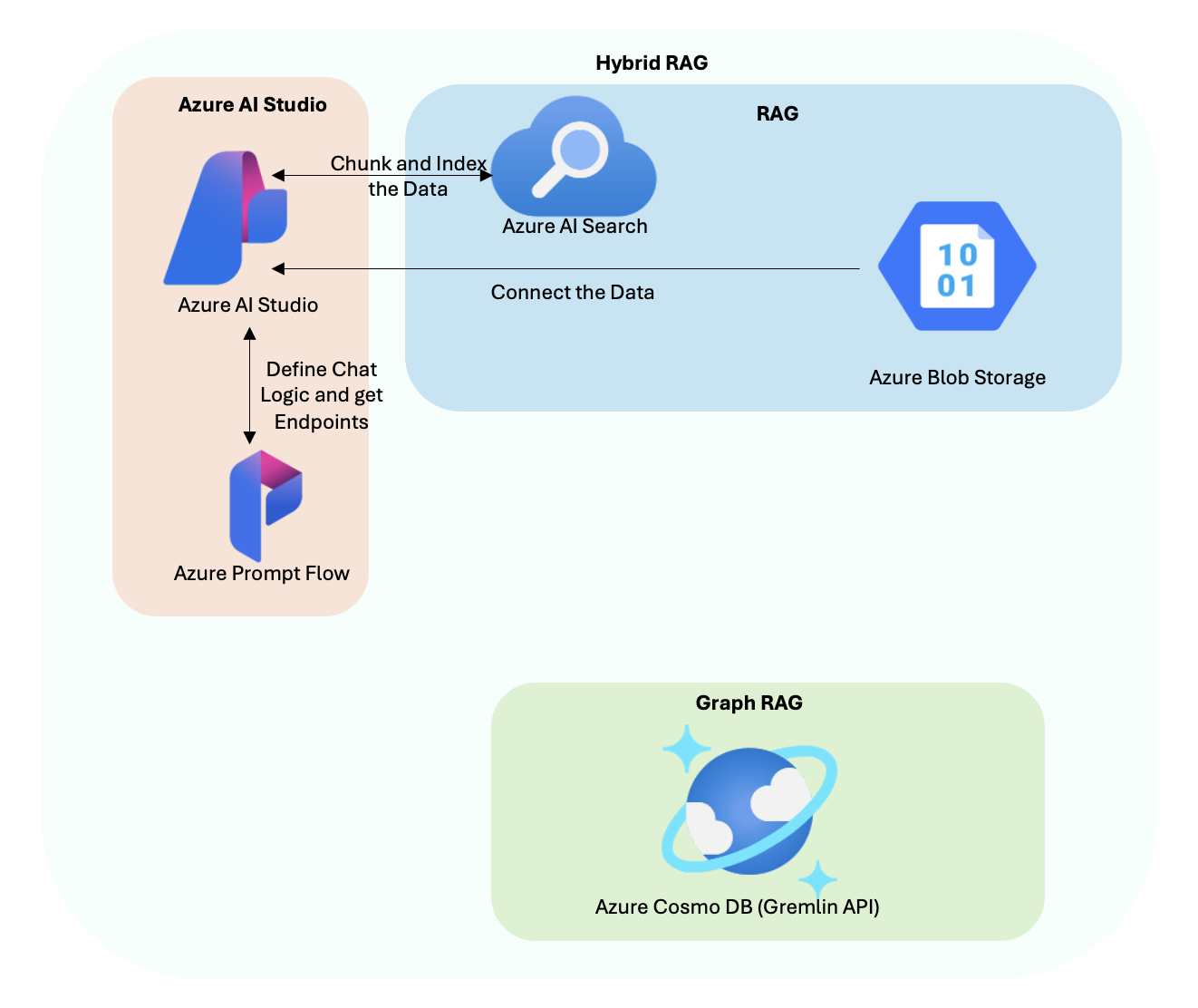
Fig 3. Arquitetura RAG Híbrida
- RAG (geração aumentada de recuperação):
- Os dados estruturados ingeridos no Azure Blob Storage estão ligados ao Azure AI Search para indexação e recuperação.
- O Azure AI Studio facilita a fragmentação e a indexação de dados, definindo a lógica de chat e gerando pontos de extremidade usando o Azure Prompt Flow.
- Quando uma consulta do utilizador é recebida, o Azure AI Search recupera informações relevantes dos dados indexados.
- Gráfico RAG (geração aumentada de recuperação de gráfico):
- O Azure Cosmos DB armazena os dados não estruturados num formato de gráfico utilizando a API Gremlin. Essa abordagem permite que o aplicativo entenda relacionamentos complexos entre entidades, como alimentos, exercícios e métricas de saúde do usuário.
- O Graph RAG recupera conhecimento contextualmente relevante do Azure Cosmos DB, que é então combinado com dados estruturados para geração de resposta aprimorada.
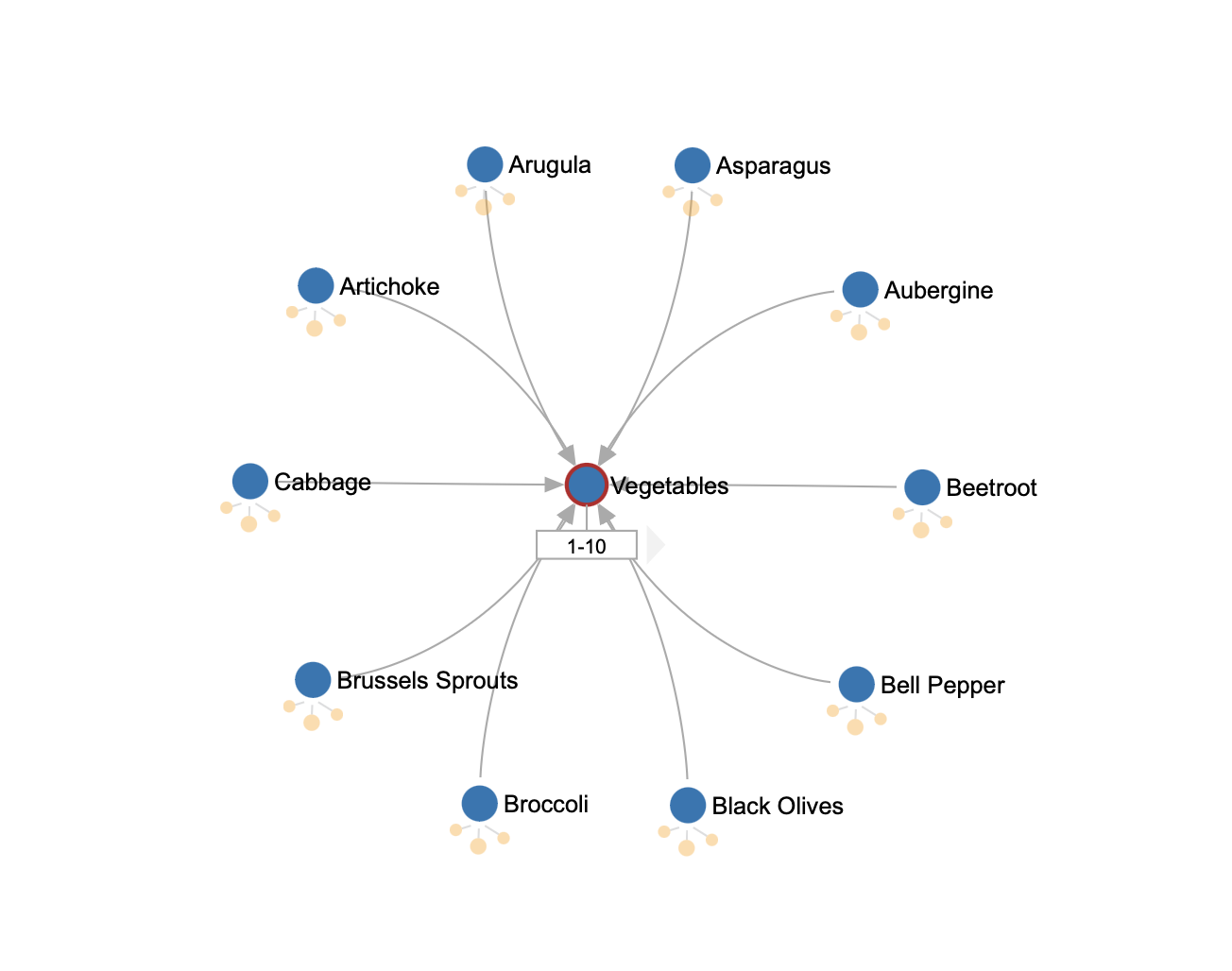
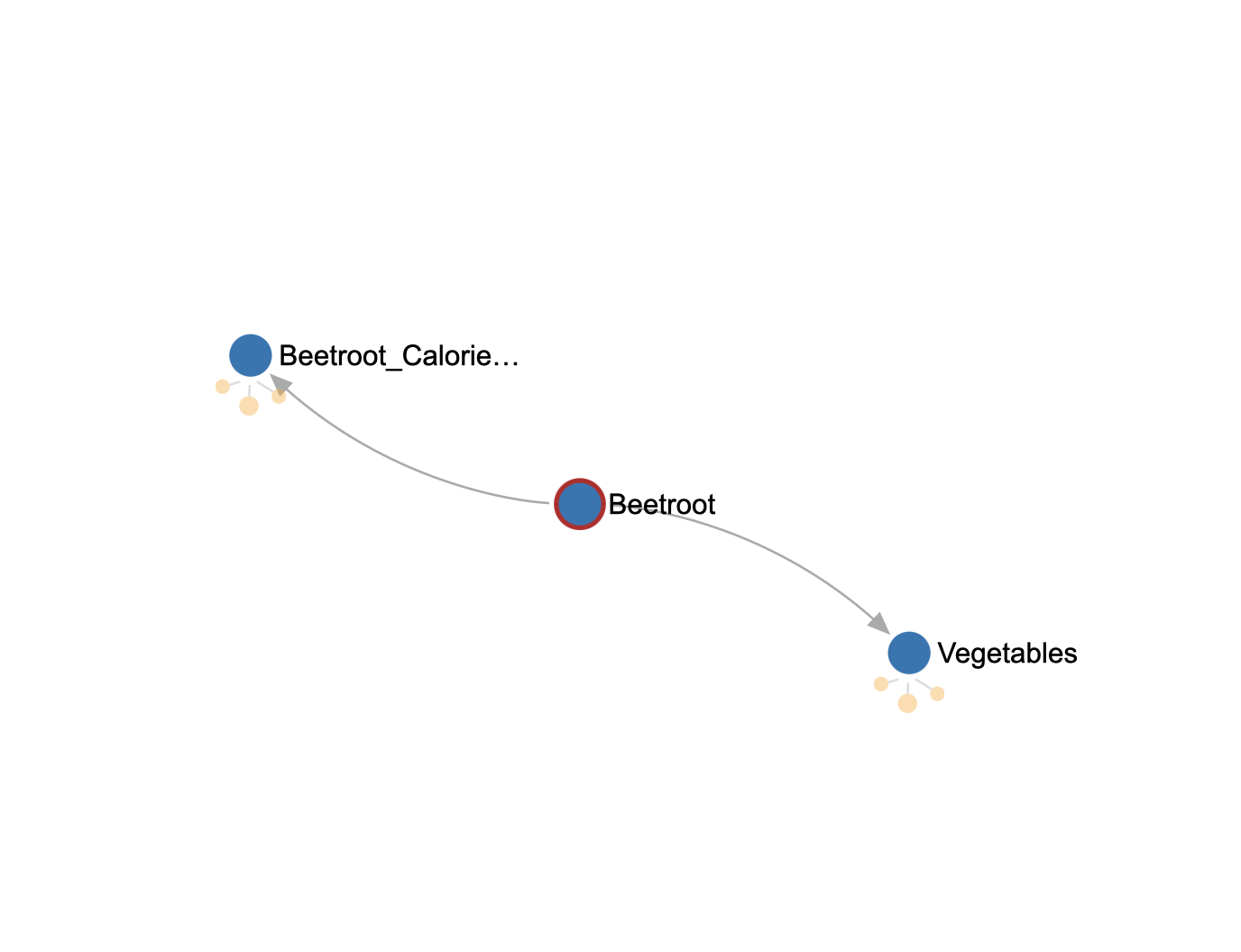
Fig 4. Exemplo de como os dados não estruturados são armazenados como gráfico no Azure CosmoDB (API Gremlin)
Estúdio de IA do Azure:

Figura 5. Arquitetura do Azure AI Studio
Fluxo de prompt
Implantamos dois endpoints usando o Azure Prompt Flow . Um é um endpoint de intenção de reescrita e o outro é My Fitness Buddy . Esses endpoints são projetados para resolver dois casos de uso diferentes: um se concentra na otimização da recuperação de documentos por meio da geração de consultas, enquanto o outro oferece aconselhamento personalizado sobre adequação dentro de limites seguros predefinidos com a base de conhecimento do RAG.
1. Reescrever o ponto final da intenção
Objetivo : Este endpoint foi projetado para lidar com uma tarefa específica: gerar consultas de pesquisa com base na pergunta de um usuário e no histórico de conversas anteriores. Ao combinar a “pergunta atual do usuário” e o contexto anterior, o endpoint gera uma única consulta canônica que inclui todos os detalhes necessários, sem variantes. Isso é empregado para sistemas de recuperação de documentos, onde a geração dessas consultas e intenções precisas leva a resultados mais precisos.
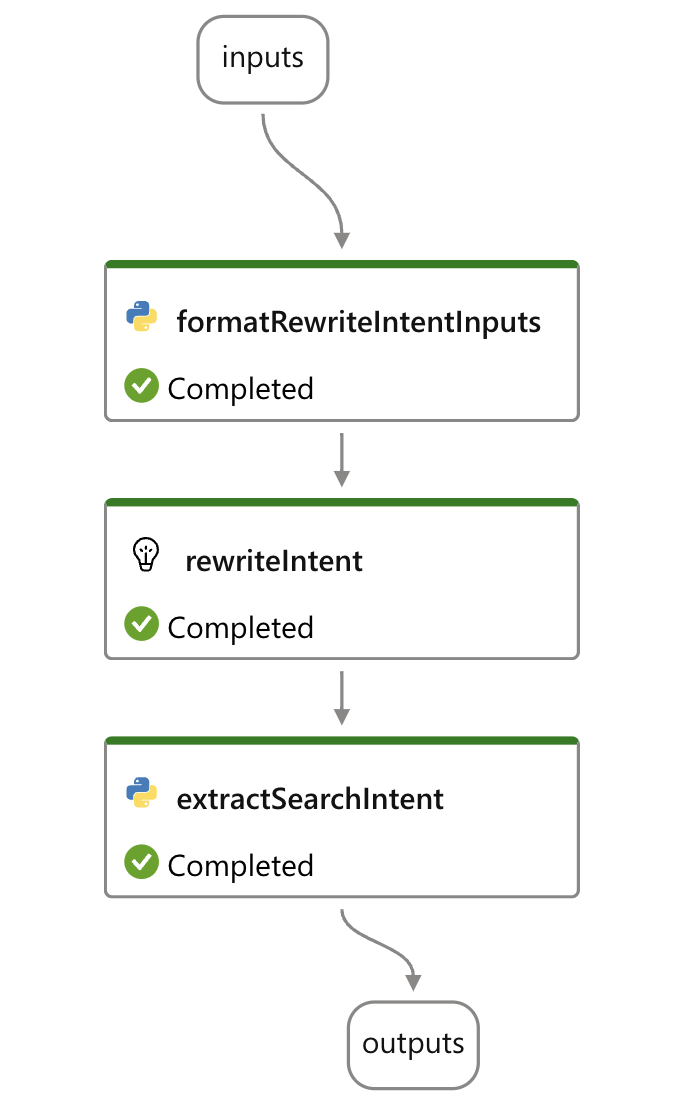
Fig 6. Ponto final do fluxo de intenção de reescrita
2. Ponto final do meu Fitness Buddy
Objetivo : O segundo endpoint é um My Fitness Buddy que oferece conselhos de condicionamento físico personalizados, planos de treino e dicas de nutrição com base nas informações do usuário. O assistente está programado para evitar aconselhamento médico e seguir apenas o conjunto de dados fornecido para garantir que todas as recomendações sejam seguras, motivacionais e baseadas em evidências e que a base de conhecimento seja recuperada para os pedaços de documentos configurados como índices de pesquisa.
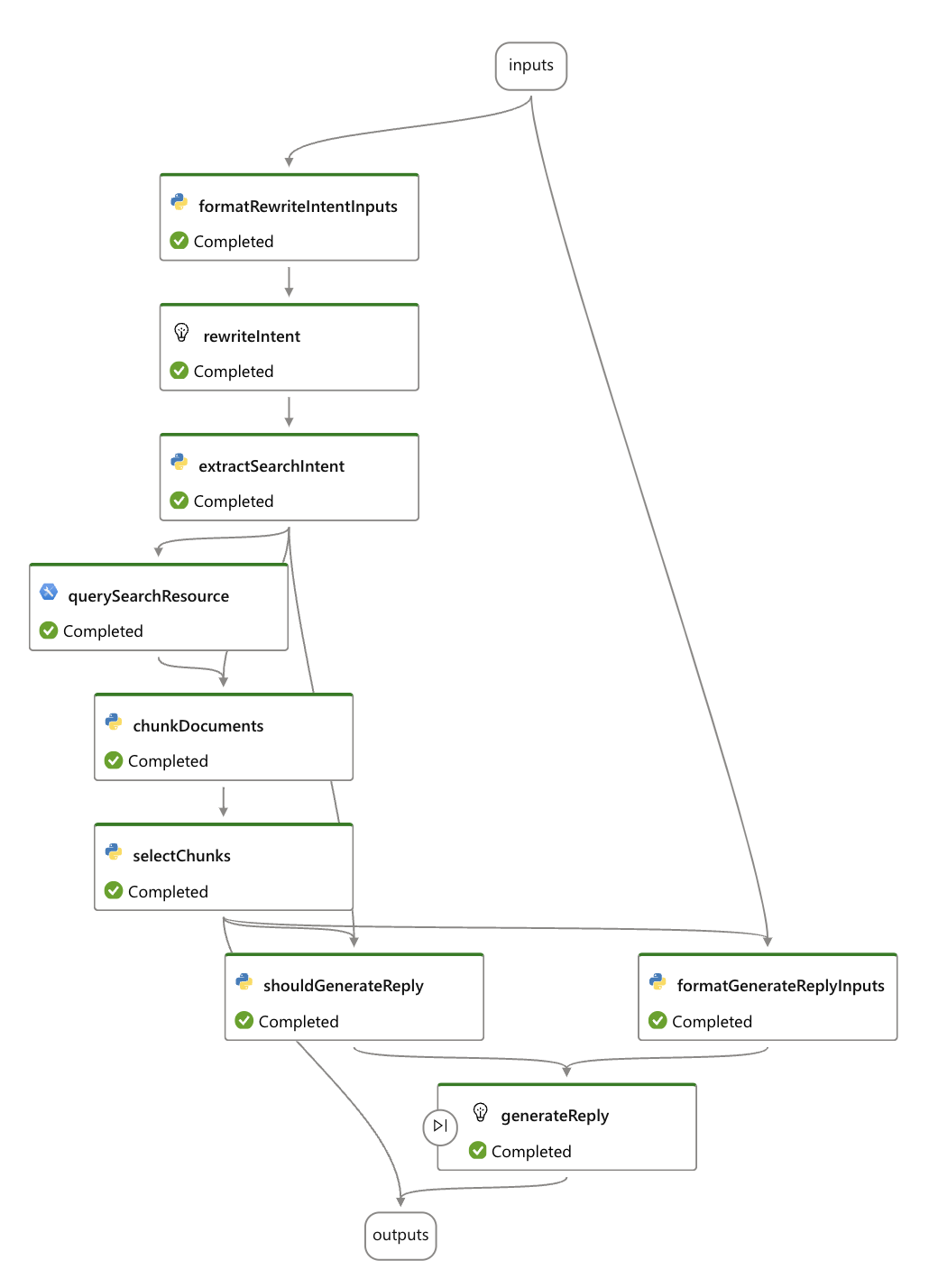
Fig 7. Fluxo do endpoint My Fitness Buddy
Fluxo de aplicação:
- O usuário interage com o aplicativo MyFitnessBuddy por meio de uma interface de chatbot baseada em Python Streamlit.
- O servidor de aplicativos processa a consulta do usuário e a direciona para o sistema de recuperação apropriado (Azure AI Search para dados estruturados ou Azure Cosmos DB para dados não estruturados) com base no tipo de consulta.
- As informações relevantes são recuperadas da fonte de dados selecionada e enviadas para Azure OpenAI Services (ChatGPT) juntamente com um prompt criado para gerar uma resposta personalizada.
- A resposta final, enriquecida com informações contextualmente relevantes, é devolvida ao usuário por meio do aplicativo Streamlit, fornecendo conselhos e recomendações de condicionamento físico personalizados.
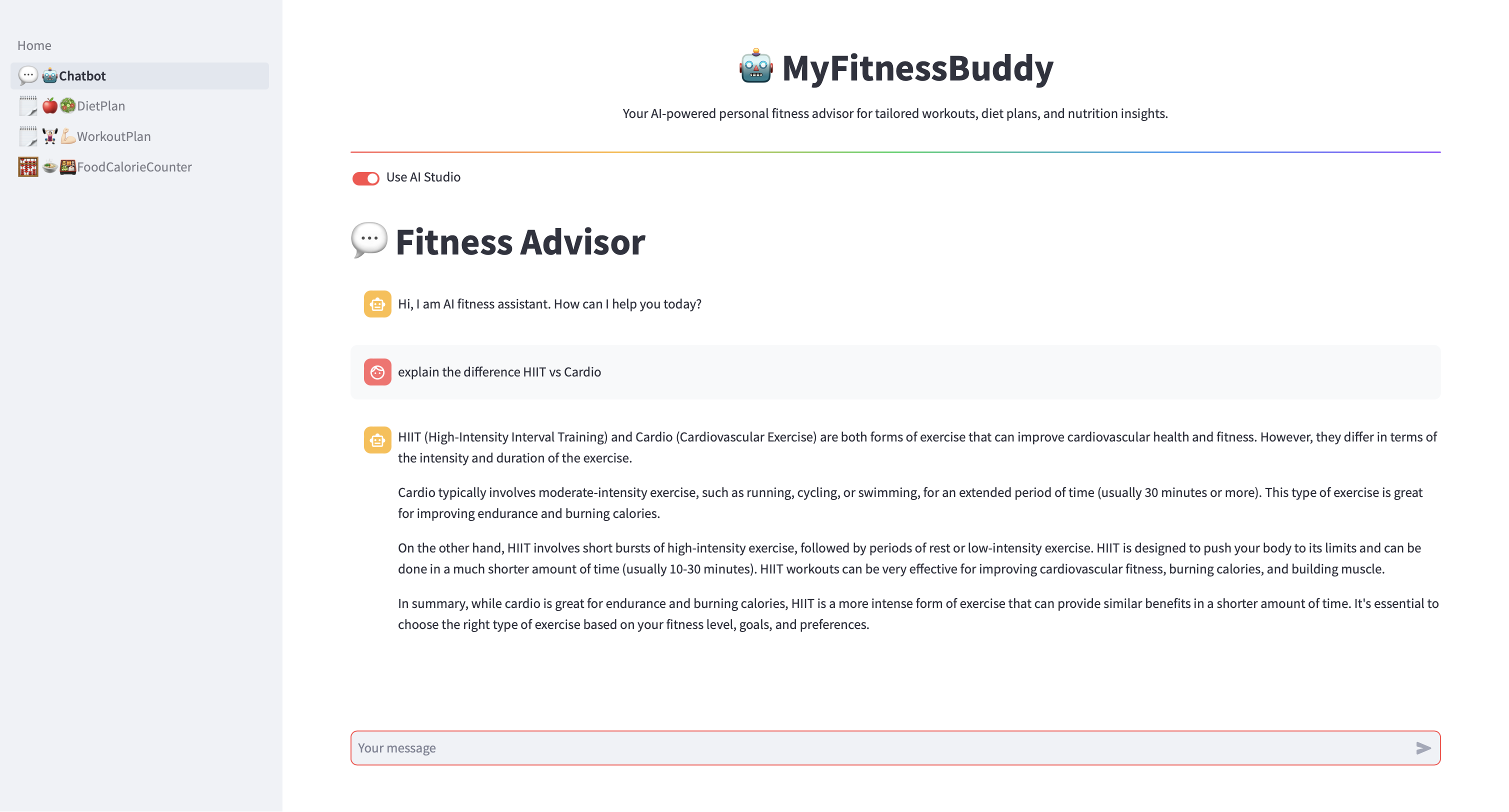
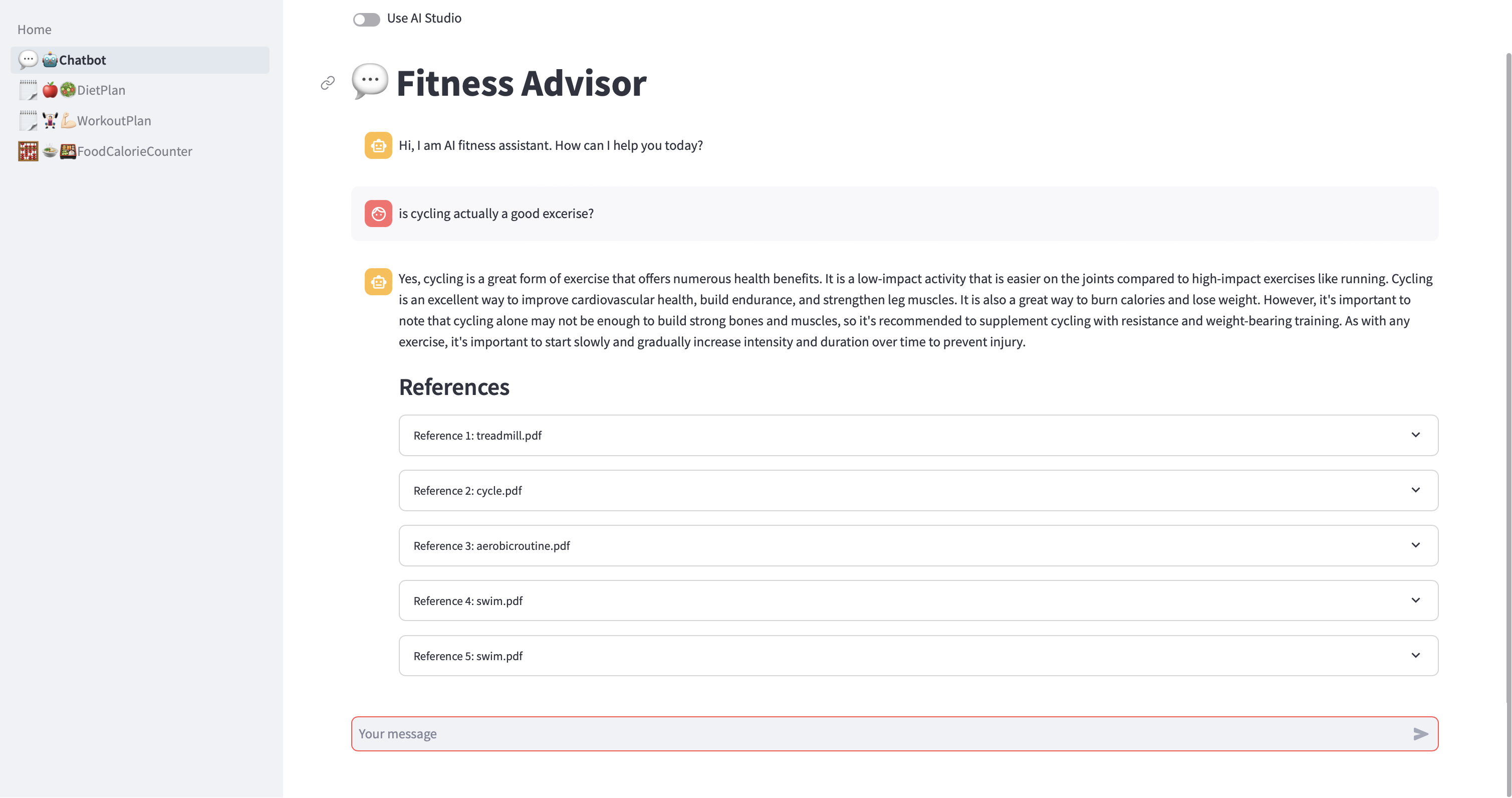
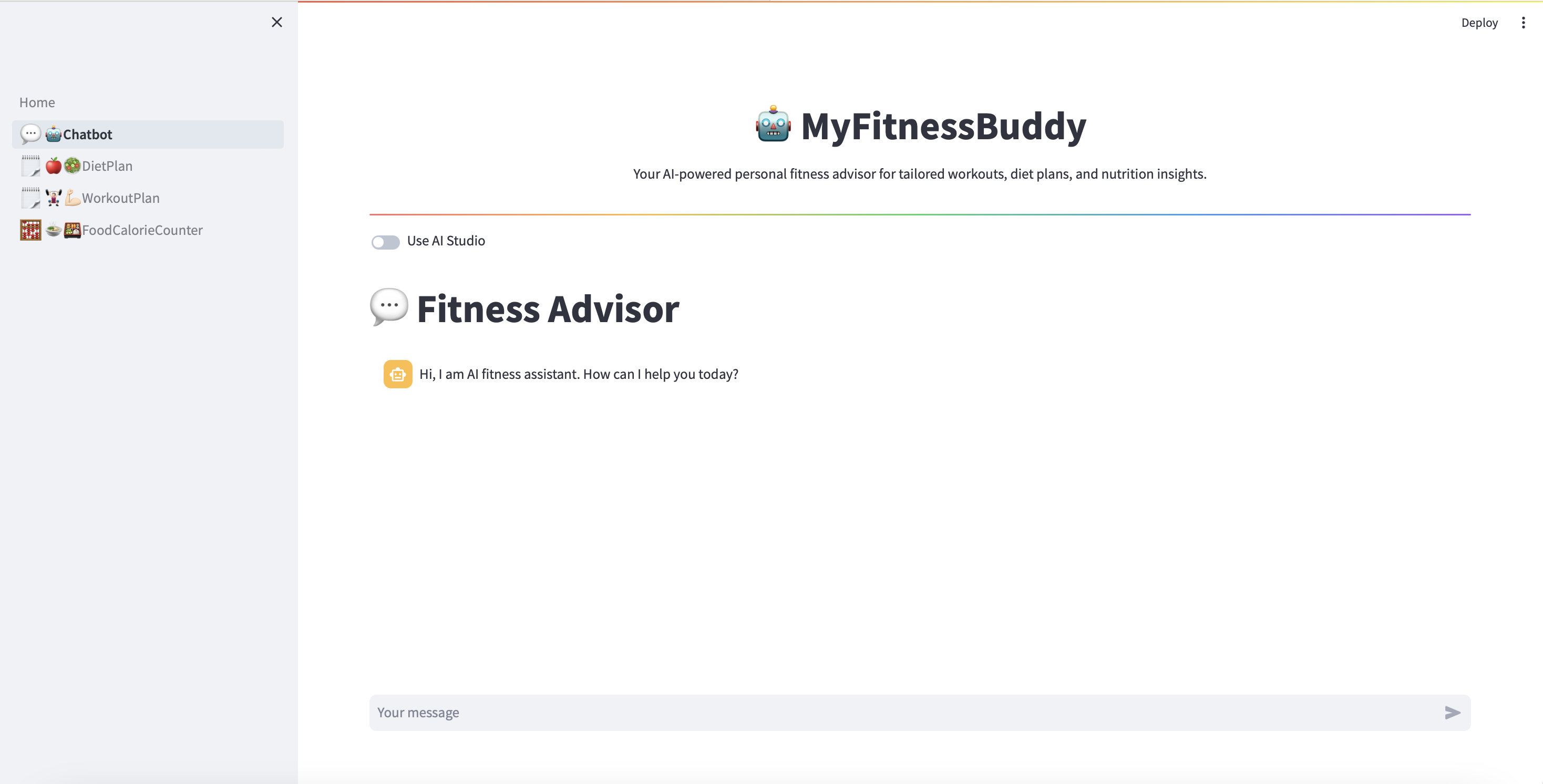
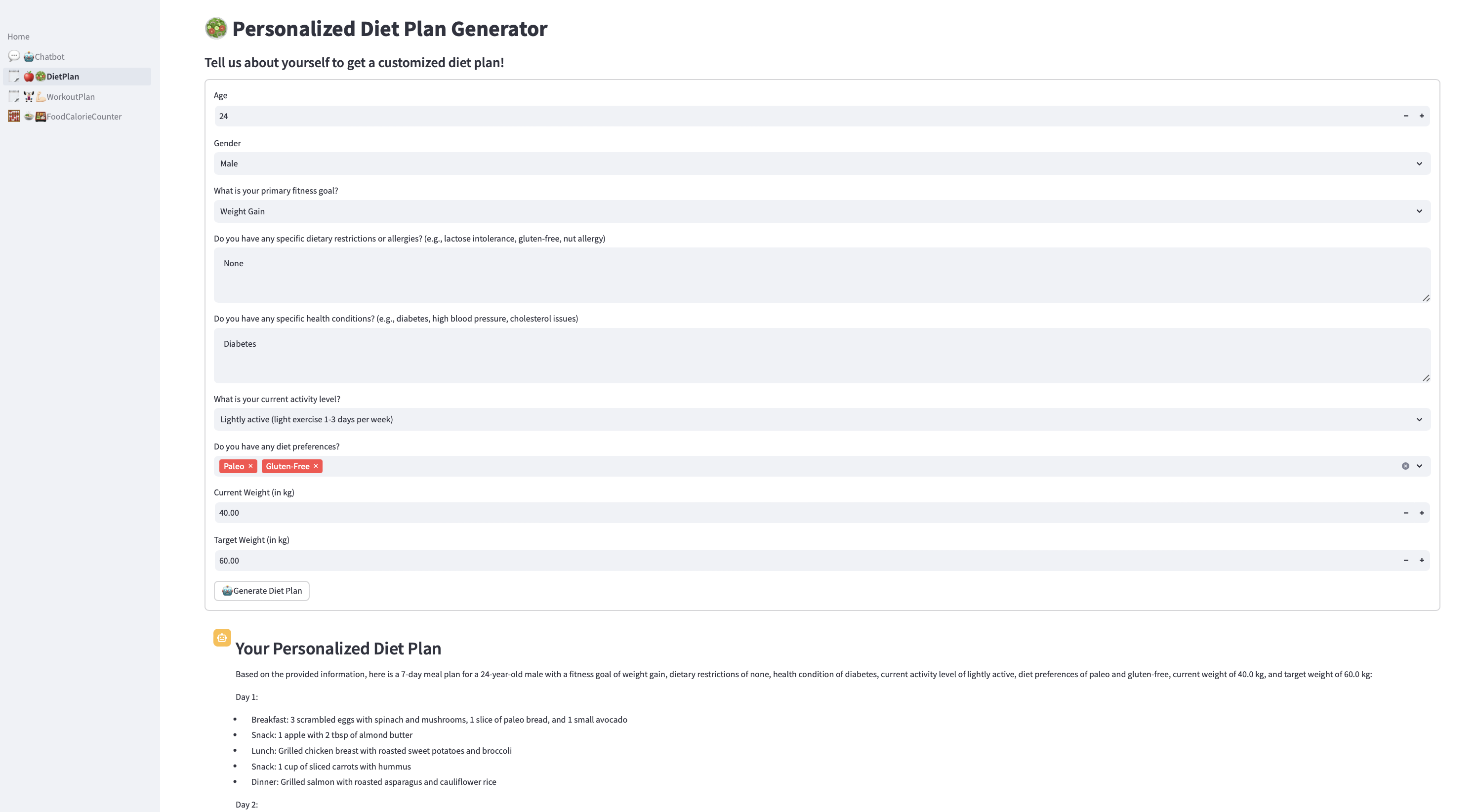
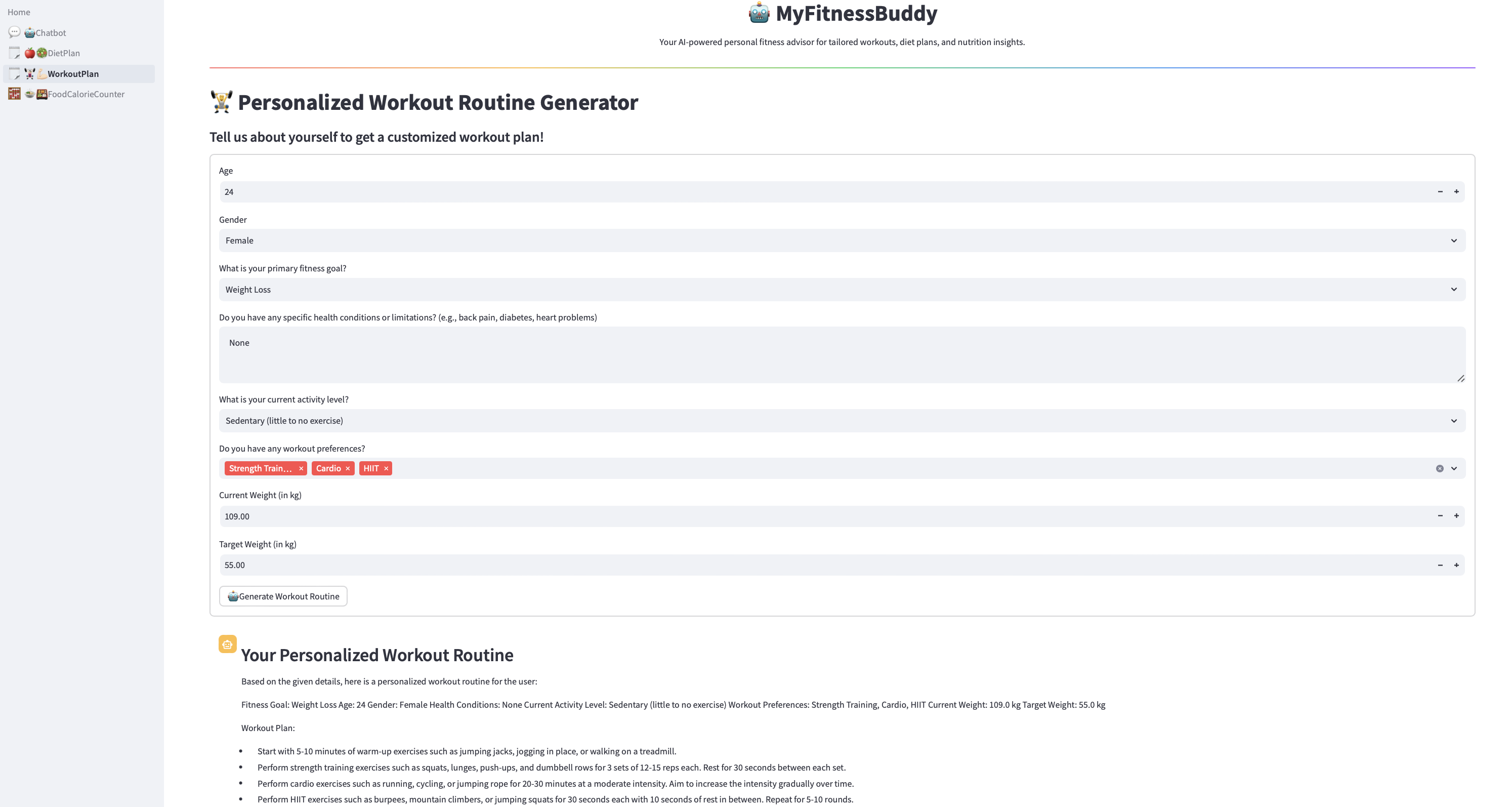
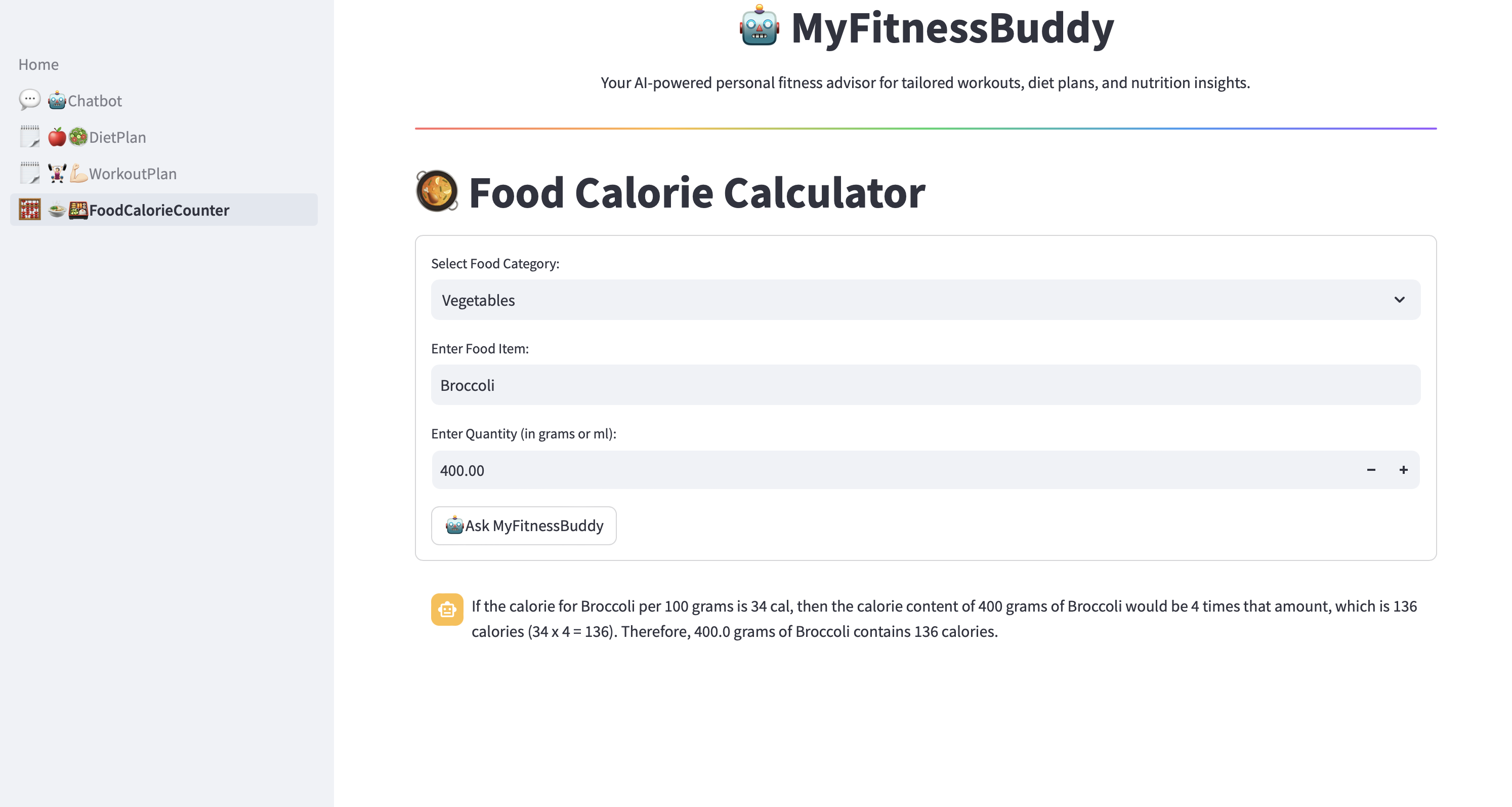
Figura 8. Aplicação
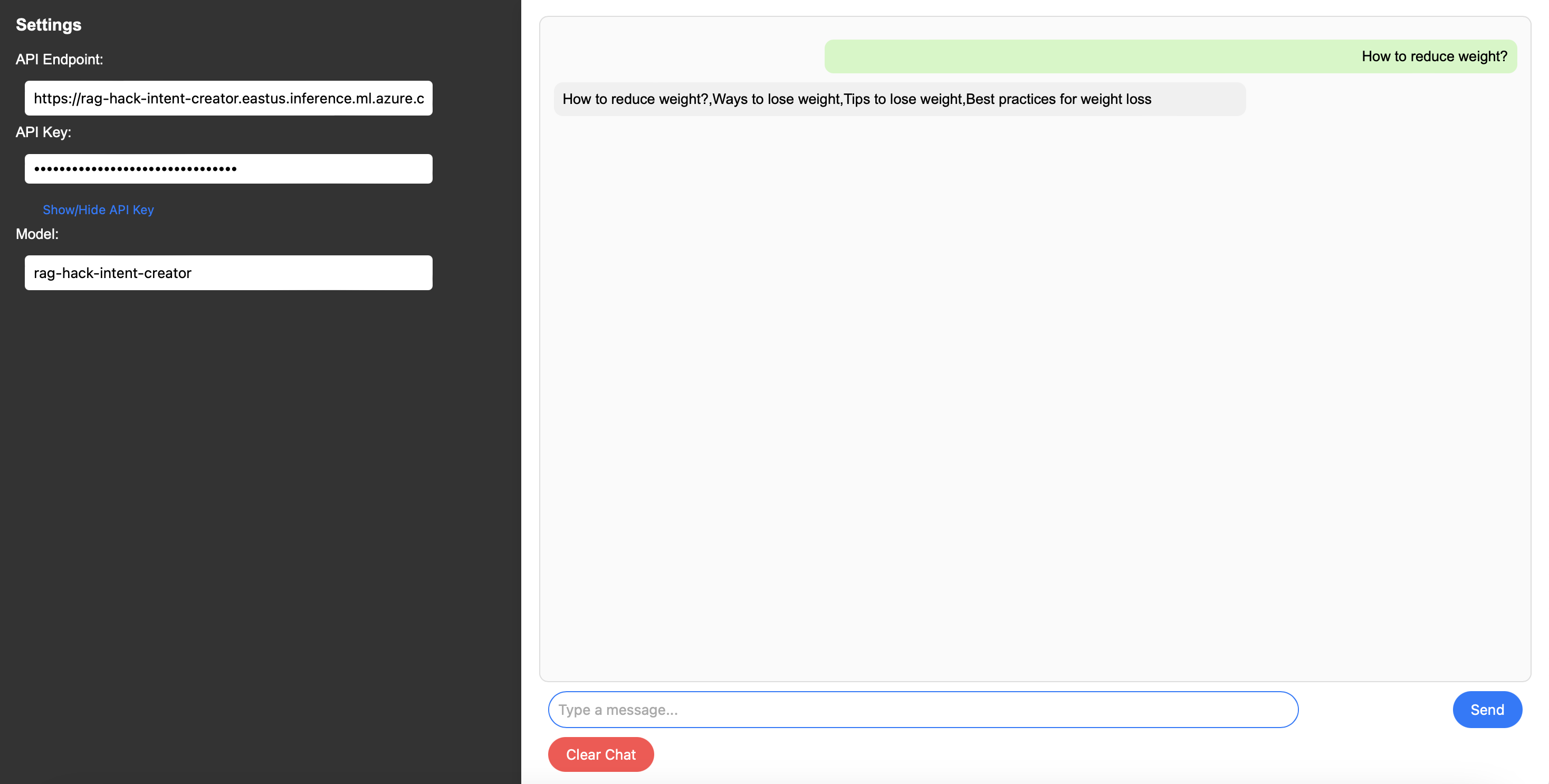
Fig 9. Ferramenta de teste para endpoints
Tecnologias utilizadas:
- Armazenamento e recuperação de dados: Azure Blob Storage, Azure Cosmos DB (Gremlin API), Azure AI Search.
- Modelos de IA e linguagem: Azure OpenAI Services (ChatGPT).
- Processamento de dados e fluxo lógico: Azure AI Studio, Azure Prompt Flow.
- Backend e Application Server: Python para extração e pré-processamento de dados, com múltiplos pontos de integração para ingestão e recuperação de dados.
Público-alvo:
- Entusiastas de Fitness: Indivíduos que são apaixonados por fitness e procuram rotinas de treino e planos de dieta personalizados para otimizar sua jornada de fitness.
- Indivíduos preocupados com a saúde: Pessoas que priorizam um estilo de vida saudável e desejam acesso fácil a informações nutricionais precisas, monitoramento de calorias e conselhos dietéticos personalizados.
- Iniciantes em condicionamento físico: recém-chegados que precisam de orientação sobre como iniciar sua jornada de condicionamento físico, incluindo rotinas básicas de exercícios, recomendações dietéticas e respostas a perguntas comuns relacionadas ao condicionamento físico.
- Profissionais ocupados: usuários com tempo limitado para planejamento de condicionamento físico que buscam acesso conveniente e sob demanda a orientações personalizadas de condicionamento físico e respostas rápidas a dúvidas relacionadas à saúde.
- Indivíduos com objetivos de saúde específicos: Aqueles com objetivos de condicionamento físico ou condições de saúde únicas que necessitam de planos e conselhos personalizados que considerem suas necessidades e preferências específicas.
Conclusão e Trabalhos Futuros:
Conclusão
MyFitnessBuddy demonstra o potencial de combinar técnicas avançadas de IA, como Retrieval-Augmented Generation (RAG) e Graph Retrieval-Augmented Generation (GRAG) para criar um consultor de fitness altamente personalizado e ciente do contexto. Ao aproveitar os recursos do Azure AI e integrar várias fontes de dados, o aplicativo fornece rotinas de treino personalizadas, planos dietéticos e respostas precisas às dúvidas dos usuários. Essa abordagem aumenta o envolvimento e a satisfação do usuário, fornecendo orientações de condicionamento físico personalizadas e relevantes.
Trabalho Futuro
- Personalização aprimorada: refine ainda mais os modelos para fornecer uma personalização mais granular com base no feedback, comportamento e preferências do usuário.
- Suporte multilíngue: implemente recursos multilíngues para alcançar um público mais amplo em todo o mundo.
- Análise avançada: desenvolva recursos de análise avançada para fornecer aos usuários insights mais profundos sobre seu progresso, hábitos e tendências de condicionamento físico.
- Fontes de dados expandidas: incorpore fontes de dados adicionais, como bancos de dados médicos e conteúdo gerado pelo usuário, para aprimorar a base de conhecimento do aplicativo e melhorar a precisão das recomendações.


