full stack on prem cv mlops
1.0.0
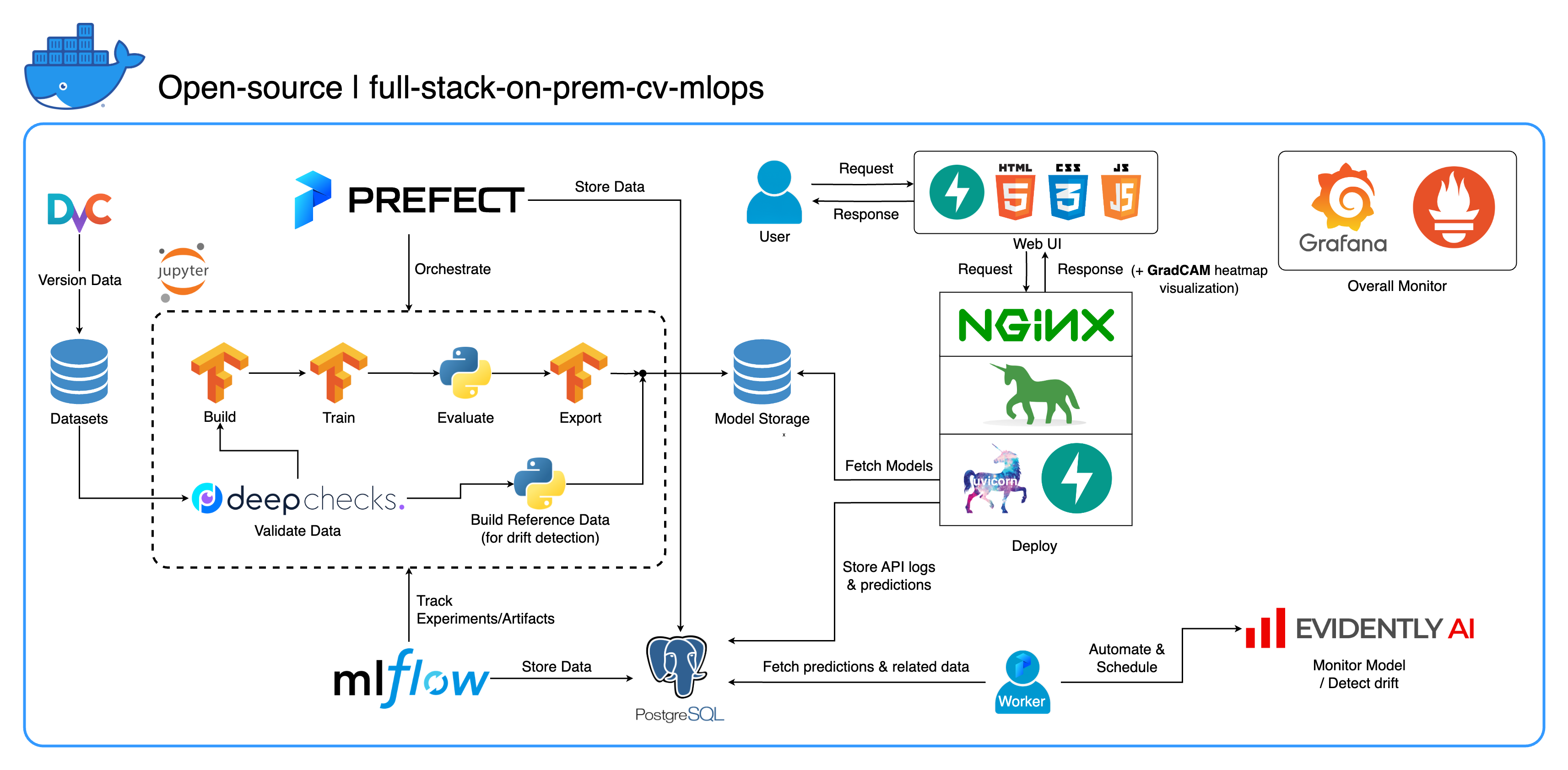
Bem-vindo ao nosso abrangente ecossistema MLOps local projetado especificamente para tarefas de visão computacional, com foco principal na classificação de imagens. Este repositório fornece tudo que você precisa, desde um espaço de trabalho de desenvolvimento no Jupyter Lab/Notebook até serviços de nível de produção. A melhor parte? Leva apenas "1 configuração e 1 comando" para executar todo o sistema, desde a construção do modelo até a implantação! Integramos diversas práticas recomendadas para garantir escalabilidade e confiabilidade, mantendo ao mesmo tempo a flexibilidade. Embora nosso caso de uso principal gire em torno da classificação de imagens, nossa estrutura de projeto pode se adaptar facilmente a uma ampla variedade de desenvolvimentos de ML/DL, até mesmo na transição do local para a nuvem!
Outro objetivo é mostrar como integrar todas essas ferramentas e fazê-las funcionar juntas em um sistema completo. Se você estiver interessado em componentes ou ferramentas específicas, sinta-se à vontade para escolher o que atende às necessidades do seu projeto.
Todo o sistema é conteinerizado em um único arquivo Docker Compose. Para configurá-lo, tudo que você precisa fazer é executar docker-compose up ! Este é um sistema totalmente local, o que significa que não há necessidade de uma conta na nuvem e não custará um centavo para usar o sistema inteiro!
É altamente recomendável assistir aos vídeos de demonstração na seção Vídeos de demonstração para obter uma visão geral abrangente e entender como aplicar este sistema aos seus projetos. Esses vídeos contêm detalhes importantes que podem ser muito longos e não claros o suficiente para serem abordados aqui.
Demonstração: https://youtu.be/NKil4uzmmQc
Passo a passo técnico detalhado: https://youtu.be/l1S5tHuGBA8
Recursos no vídeo:
Para usar este repositório, você só precisa do Docker. Para referência, usamos Docker versão 24.0.6, build ed223bc e Docker Compose versão v2.21.0-desktop.1 no Mac M1.
Implementamos várias práticas recomendadas neste projeto:
tf.data para TensorFlowimgaug lib para maior flexibilidade nas opções de aumento do que as funções principais do TensorFlowos.env para configurações importantes ou de nível de serviçologging em vez de print.env para variáveis em docker-compose.ymldefault.conf.template para Nginx para aplicar variáveis de ambiente com elegância na configuração do Nginx (novo recurso no Nginx 1.19)A maioria das portas pode ser personalizada no arquivo .env na raiz deste repositório. Aqui estão os padrões:
123456789 )[email protected] , pw: SuperSecurePwdHere )admin , pw: admin ) Você deve considerar comentar essas linhas platform: linux/arm64 em docker-compose.yml se não estiver usando um computador baseado em ARM (estamos usando Mac M1 para desenvolvimento). Caso contrário, este sistema não funcionará.
--recurse-submodules em seu comando: git clone --recurse-submodules https://github.com/jomariya23156/full-stack-on-prem-cv-mlopsdeploy no serviço jupyter em docker-compose.yml e alterar a imagem base em services/jupyter/Dockerfile de ubuntu:18.04 para nvidia/cuda:11.4.3-cudnn8-devel-ubuntu20.04 (o texto está lá no arquivo, basta comentar e descomentar) para aproveitar sua(s) GPU(s). Você também pode precisar instalar nvidia-container-toolkit na máquina host para que funcione. Para usuários de Windows/WSL2, achamos este artigo muito útil.docker-compose up ou docker-compose up -d para desconectar o terminal.datasets/animals10-dvc e siga as etapas na seção Como usar . http://localhost:8888/labcd ~/workspace/docker-compose.yml ) conda activate computer-viz-dlpython run_flow.py --config configs/full_flow_config.yamltasksflowsrun_flow.py na raiz do repositório.start(config) em seu arquivo de fluxo. Esta função aceita a configuração como um ditado Python e basicamente chama o fluxo específico nesse arquivo.datasets e todos devem ter a mesma estrutura de diretórios que está dentro deste repositório.central_storage em ~/ariya/ deve conter pelo menos 2 subdiretórios chamados models e ref_data . Este central_storage serve ao propósito de armazenamento de objetos de armazenar todos os arquivos preparados para serem usados em ambientes de desenvolvimento e implantação. (Esta é uma das coisas que você pode considerar mudar para um serviço de armazenamento em nuvem caso queira implantar na nuvem e torná-lo mais escalonável)Convenções IMPORTANTES para ter MUITO CUIDADO caso queira alterar (porque essas coisas estão amarradas e usadas em diferentes partes do sistema):
central_storage -> Dentro deve haver subdiretórios models/ ref_data/<model_name>.yaml , <model_name>_uae , <model_name>_bbsd , <model_name>_ref_data.parquetcurrent_model_metadata_file e monitor_pool_namecomputer-viz-dl (valor padrão), com todos os pacotes necessários para este repositório. Todos os comandos/códigos Python devem ser executados neste Jupyter.central_storage atua como o armazenamento central de arquivos usado durante o desenvolvimento e a implantação. Ele contém principalmente arquivos de modelo (incluindo detectores de deriva) e dados de referência no formato Parquet. No final da etapa de treinamento do modelo, novos modelos são salvos aqui e o serviço de implantação extrai modelos desse local. ( Observação : este é o local ideal para substituir serviços de armazenamento em nuvem para escalabilidade.)model na configuração para construir um modelo de classificador. O modelo é construído com TensorFlow e sua arquitetura é codificada em tasks/model.py:build_model .dataset na configuração para preparar um conjunto de dados para treinamento. DvC é usado nesta etapa para verificar a consistência dos dados no disco em comparação com a versão especificada na configuração. Se houver alterações, ele converte de volta para a versão especificada programaticamente. Se quiser manter as alterações, caso esteja experimentando o conjunto de dados, você pode definir o campo dvc_checkout na configuração como falso para que o DvC não faça suas coisas.train na configuração para construir um carregador de dados e iniciar o processo de treinamento. As informações e os artefatos do experimento são rastreados e registrados com MLflow . Observação: o relatório de resultados (em um arquivo .html ) do DeepChecks também é carregado no experimento de treinamento no MLflow para a convenção.model no arquivo config.central_storage (neste caso, basta fazer uma cópia para o local central_storage . Esta é a etapa que você pode alterar para enviar arquivos para armazenamento em nuvem)model/drift_detection na configuração.central_storage .central_storage .central_storage . (esta é uma preocupação discutida no vídeo de demonstração do tutorial, assista para mais detalhes)current_model_metadata_file armazenando o nome do arquivo de metadados do modelo terminado com .yaml e monitor_pool_name armazenando o nome do pool de trabalho para implantar o trabalhador e os fluxos do Prefect.cd programaticamente em deployments/prefect-deployments e execute prefect --no-prompt deploy --name {deploy_name} usando entradas da seção deploy/prefect na configuração. Como tudo já está encaixado e conteinerizado neste repositório, converter o serviço local para nuvem é bastante simples. Ao terminar de desenvolver e testar sua API de serviço, você pode simplesmente desmembrar services/dl_service construindo o contêiner a partir de seu Dockerfile e enviá-lo para um serviço de registro de contêiner em nuvem (AWS ECR, por exemplo). É isso!
Nota: Há um problema potencial no código de serviço se você quiser usá-lo em um ambiente de produção real. Abordei isso no vídeo detalhado e recomendo que você passe algum tempo assistindo o vídeo inteiro. 
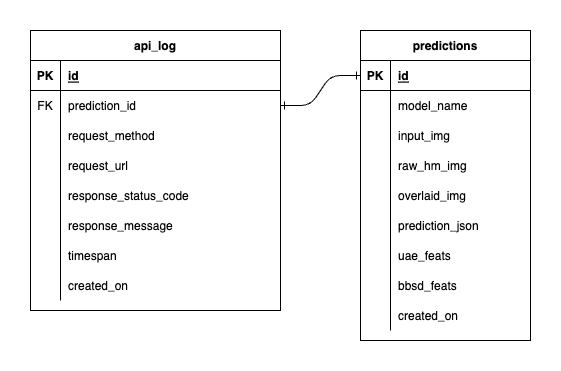
Temos três bancos de dados dentro do PostgreSQL: um para MLflow, um para Prefect e um que criamos para nosso serviço de modelo de ML. Não nos aprofundaremos nos dois primeiros, pois são autogerenciados por essas ferramentas. O banco de dados para nosso serviço de modelo de ML é aquele que nós mesmos projetamos.
Para evitar uma complexidade esmagadora, mantivemos tudo simples com apenas duas tabelas. Os relacionamentos e atributos são mostrados no DER abaixo. Essencialmente, nosso objetivo é armazenar detalhes essenciais sobre as solicitações recebidas e as respostas do nosso serviço. Todas essas tabelas são criadas e manipuladas automaticamente, então você não precisa se preocupar com configuração manual.
Digno de nota: input_img , raw_hm_img e overlaid_img são imagens codificadas em base64 armazenadas como strings. uae_feats e bbsd_feats são conjuntos de recursos de incorporação para nossos algoritmos de detecção de desvio.
ImportError: /lib/aarch64-linux-gnu/libGLdispatch.so.0: cannot allocate memory in static TLS block , tente export LD_PRELOAD=/lib/aarch64-linux-gnu/libGLdispatch.so.0 e execute novamente seu roteiro.

