GenAI GeoGuesser
Adivinhe o nome do país a partir de hits gerados pela IA
Este projeto é uma versão diferente do popular jogo GeoGuessr, no qual você é colocado em um local mundial aleatório no Google Maps e precisa adivinhar o local durante uma contagem regressiva. Aqui você terá que adivinhar o nome do país com base em dicas multimodais geradas por modelos de IA, você pode escolher entre 3 modalidades, texto que fornece uma descrição textual do país, imagem que fornece uma imagem que lembra o país e áudio que fornece você uma amostra de áudio relacionada ao país.
Você pode conferir uma demonstração online deste aplicativo em seus espaços HuggingFace, esta demonstração foi limitada a gerar apenas dicas de imagens por motivos de desempenho.
Se você quiser saber um pouco mais sobre como este projeto funciona e como ele foi criado confira o artigo "Construindo um GeoGuesser generativo baseado em IA".
Fluxo de trabalho
- Escolha as modalidades de dicas desejadas.
- Escolha o número de dicas para cada modalidade.
- Clique no botão "Iniciar jogo".
- Veja todas as dicas e digite seu palpite no campo "Suposição do país".
- Clique no botão "Dar um palpite".
Demonstração
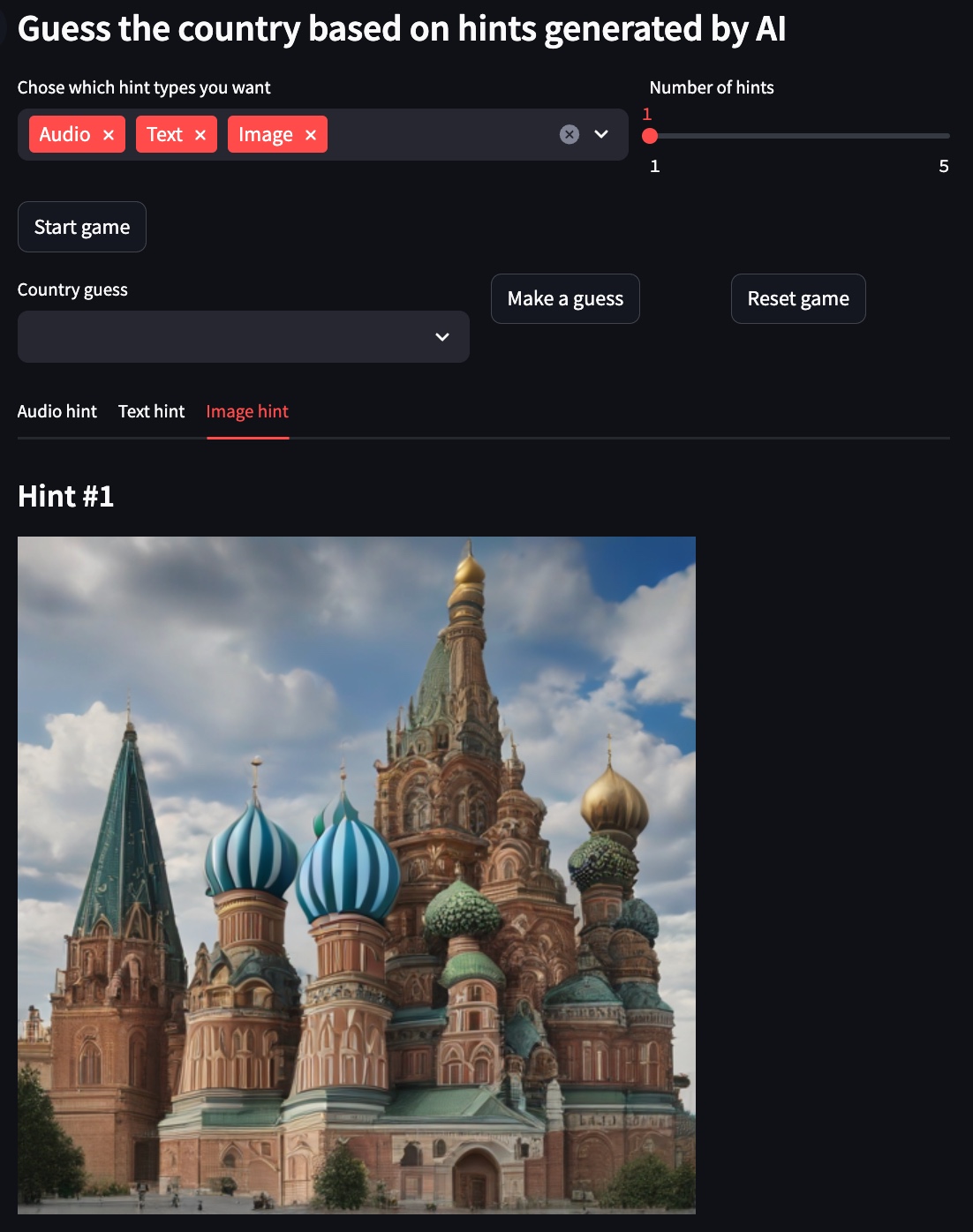
Para os exemplos abaixo, o país escolhido é a Rússia .
Dica de texto
Dica de imagem
Dica de áudio
Uso
A abordagem recomendada para usar este repositório é com Docker, mas você também pode usar um venv customizado, apenas certifique-se de instalar todas as dependências.
Configurações
local:
to_use: true
text:
model_id: google/gemma-1.1-2b-it
device: cpu
max_output_tokens: 50
temperature: 1
top_p: 0.95
top_k: 32
image:
model_id: stabilityai/sdxl-turbo
device: mps
num_inference_steps: 1
guidance_scale: 0.0
audio:
model_id: cvssp/audioldm2-music
device: cpu
num_inference_steps: 200
audio_length_in_s: 10
vertex:
to_use: false
project: {VERTEX_AI_PROJECT}
location: {VERTEX_AI_LOCALTION}
text:
model_id: gemini-1.5-pro-preview-0409
max_output_tokens: 50
temperature: 1
top_p: 0.95
top_k: 32
- local
- to_use: Se o projeto deve usar esta configuração
- texto
- model_id: Modelo usado para criar as dicas de texto
- dispositivo: Dispositivo usado pelo modelo, geralmente um de (cpu, cuda, mps)
- max_output_tokens: Número máximo de tokens gerados pelo modelo
- temperatura: A temperatura controla o grau de aleatoriedade na seleção do token. Temperaturas mais baixas são boas para avisos que esperam uma resposta verdadeira ou correta, enquanto temperaturas mais altas podem levar a resultados mais diversos ou inesperados. Com uma temperatura de 0, o token de maior probabilidade é sempre selecionado
- top_p: Top-p altera a forma como o modelo seleciona tokens para saída. Os tokens são selecionados do mais provável para o menos provável, até que a soma de suas probabilidades seja igual ao valor p superior. Por exemplo, se os tokens A, B e C tiverem uma probabilidade de 0,3, 0,2 e 0,1 e o valor p superior for 0,5, então o modelo selecionará A ou B como o próximo token (usando temperatura )
- top_k: Top-k altera a forma como o modelo seleciona tokens para saída. Um top-k de 1 significa que o token selecionado é o mais provável entre todos os tokens no vocabulário do modelo (também chamado de decodificação gananciosa), enquanto um top-k de 3 significa que o próximo token é selecionado entre os 3 tokens mais prováveis ( usando temperatura)
- imagem
- model_id: Modelo usado para criar as dicas da imagem
- dispositivo: Dispositivo usado pelo modelo, geralmente um de (cpu, cuda, mps)
- num_inference_steps: Número de etapas de inferência para o modelo
- guide_scale: Força a geração a corresponder melhor ao prompt, potencialmente às custas da qualidade ou diversidade da imagem
- áudio
- model_id: Modelo usado para criar as dicas de áudio
- dispositivo: Dispositivo usado pelo modelo, geralmente um de (cpu, cuda, mps)
- num_inference_steps: Número de etapas de inferência para o modelo
- audio_length_in_s: duração da dica de áudio
- vértice
- to_use: Se o projeto deve usar esta configuração
- projeto: nome do projeto usado pela Vertex AI
- localização: localização do projeto usada pela Vertex AI
- texto
- model_id: Modelo usado para criar as dicas de texto
- max_output_tokens: Número máximo de tokens gerados pelo modelo
- temperatura: A temperatura controla o grau de aleatoriedade na seleção do token. Temperaturas mais baixas são boas para avisos que esperam uma resposta verdadeira ou correta, enquanto temperaturas mais altas podem levar a resultados mais diversos ou inesperados. Com uma temperatura de 0, o token de maior probabilidade é sempre selecionado
- top_p: Top-p altera a forma como o modelo seleciona tokens para saída. Os tokens são selecionados do mais provável para o menos provável, até que a soma de suas probabilidades seja igual ao valor p superior. Por exemplo, se os tokens A, B e C tiverem uma probabilidade de 0,3, 0,2 e 0,1 e o valor p superior for 0,5, então o modelo selecionará A ou B como o próximo token (usando temperatura )
- top_k: Top-k altera a forma como o modelo seleciona tokens para saída. Um top-k de 1 significa que o token selecionado é o mais provável entre todos os tokens no vocabulário do modelo (também chamado de decodificação gananciosa), enquanto um top-k de 3 significa que o próximo token é selecionado entre os 3 tokens mais prováveis ( usando temperatura)
Comandos
Inicie o aplicativo do jogo.
Construa a imagem do Docker.
Aplique lint e formatação ao código (necessário apenas para desenvolvimento).


