doc genius ai
v1.0

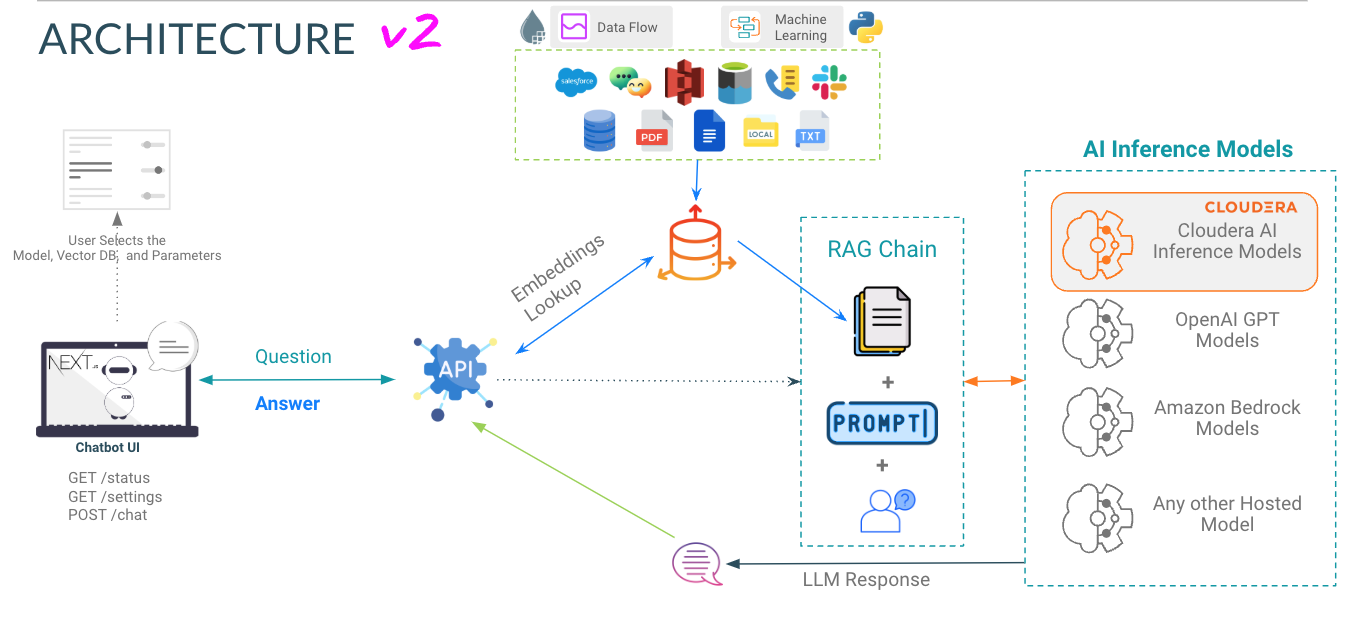
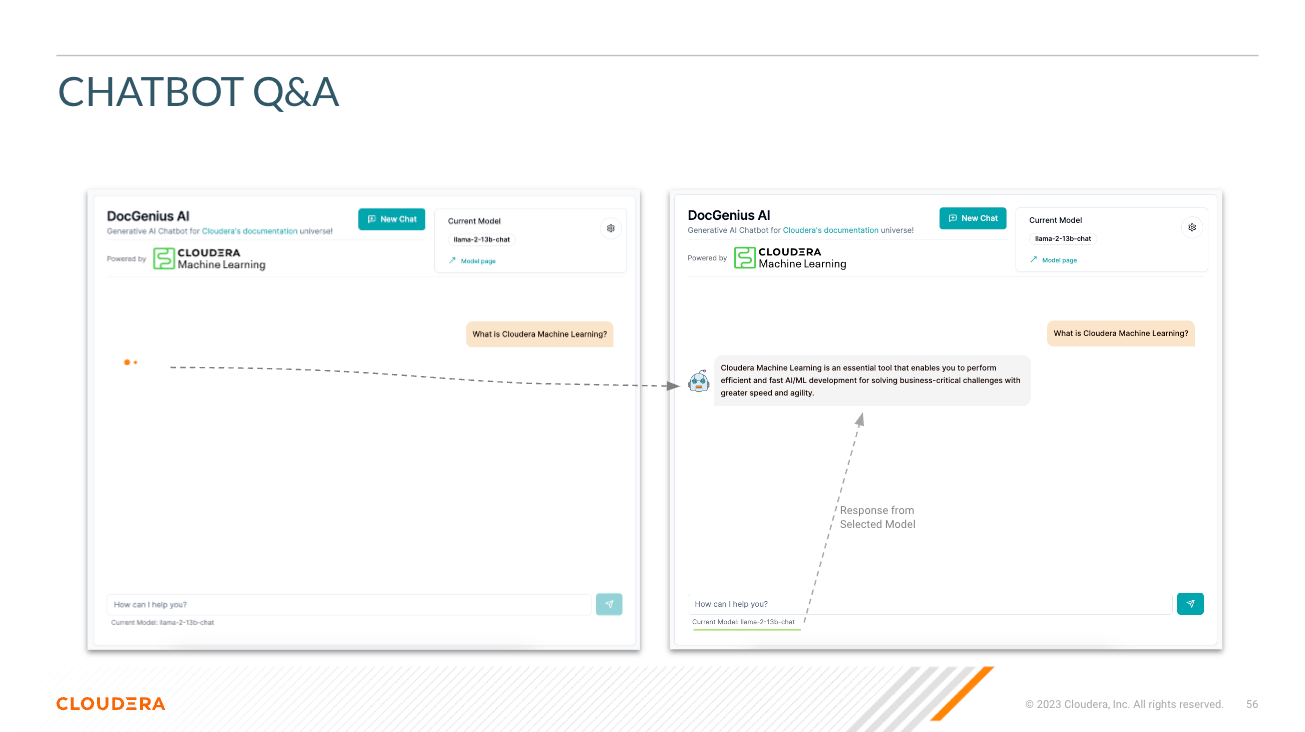
Selecionar modelo - Aqui o usuário pode selecionar o modelo de chat de parâmetro Llama3 70B ( llama-3-70b )
Selecione Temperatura (Aleatoriedade da Resposta) - Aqui o usuário pode dimensionar a aleatoriedade da resposta do modelo. Números mais baixos garantem uma resposta mais aproximada e objetiva, enquanto números mais altos incentivam a criatividade do modelo.
Selecione o número de tokens (comprimento da resposta) - Aqui foram fornecidas várias opções. O número de tokens que o usuário usa está diretamente relacionado ao comprimento da resposta que o modelo retorna.
Pergunta - Exatamente como parece; é aqui que o usuário pode fazer uma pergunta ao modelo
Resposta - Esta é a resposta gerada pelo modelo dado o contexto em seu banco de dados vetorial. Observe que se a pergunta não puder ser correlacionada ao conteúdo da sua base de conhecimento, você poderá obter respostas alucinadas.
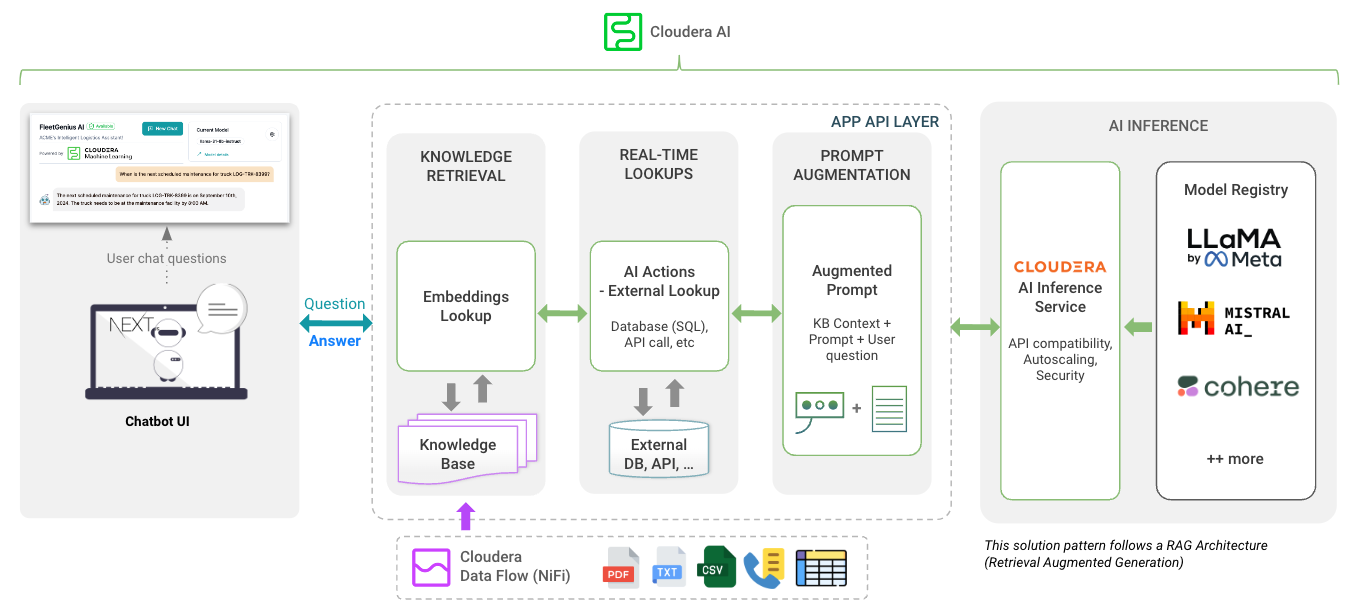
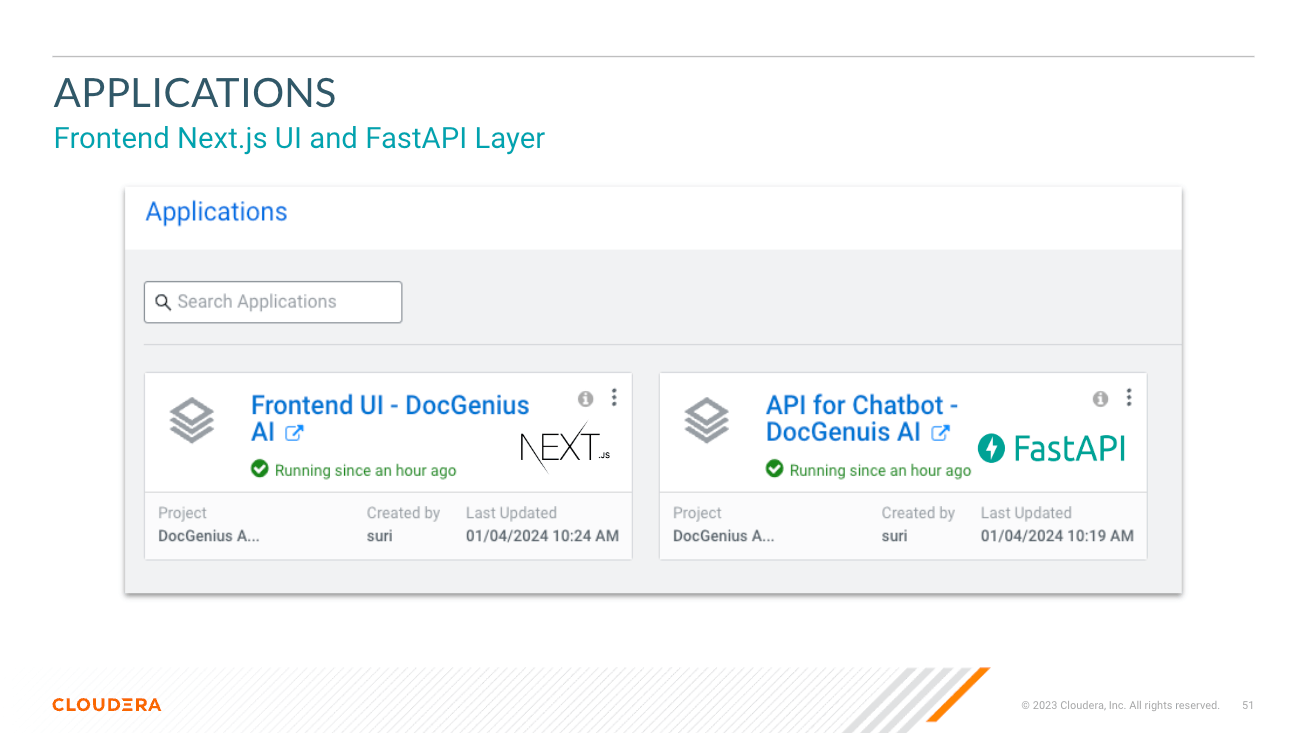
O diretório app hospeda o FastAPI para seus LLMs
O diretório chat-ui hospeda o código da UI do Chatbot.
Observe as variáveis ao implantar o AMP. Consulte os documentos de inferência do Cloduera AI para obter o endpoint e a chave da inferência.
JupyterLab - Python 3.11 - GPU Nvidia
https://docs.cloudera.com/machine-learning/cloud/applied-ml-prototypes/topics/ml-amp-project-spec.html
Isso cria as seguintes cargas de trabalho com requisitos de recursos:
2 CPU, 16GB MEM2 CPU, 8GB MEM2 CPU, 1 GPU, 16GB MEM doc-genius-ai/
├── app/ # Application directory for API and Model Serving
│ └── [..subdirs..]
│ └── chatbot/ # has the model serving python files for RAG, Prompt, Fine-tuning models
│ └── main.py # main.py file to start the API
├── chat-ui/ # Directory for the chatbot UI in Next.js
│ └── [..subdirs..]
│ └── app.py # app.py file to serve build files in .next directory via Flask
├── pipeline/ # Pipeline directory for data processing or workflow pipelines and vector load
├── data/ # Data directory for storing datasets or data files or RAG KB
├── models/ # Models directory for LLMs / ML models
├── session/ # Scripts for CML Sessions and Validation Tasks
├── images/ # Directory for storing project related images
├── api.md # Documentation for the APIs
├── README.md # Detailed description of the project
├── .gitignore # Specifies intentionally untracked files to ignore
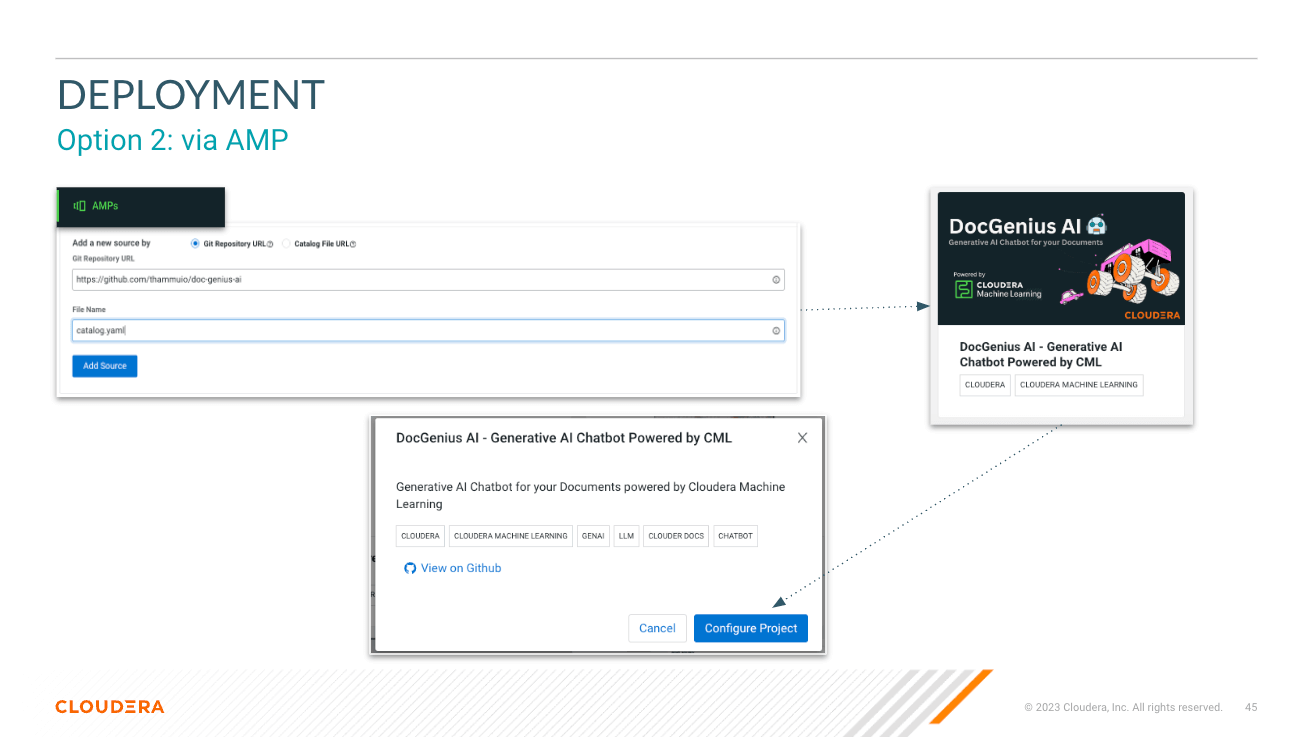
├── catalog.yaml # YAML file that contains descriptive information and metadata for the displaying the AMP projects in the CML Project Catalog.
├─ .project-metadata.yaml # Project metadata file that provides configuration and setup details
├── cdsw-build.sh # Script for building the Model dependencies
└── requirements.txt # Python dependencies for Model Serving
IMPORTANTE: Leia o seguinte antes de prosseguir. Este AMP inclui ou depende de determinados pacotes de software de terceiros. As informações sobre esses pacotes de software de terceiros são disponibilizadas no arquivo de aviso associado a esta AMP. Ao configurar e iniciar este AMP, você fará com que esses pacotes de software de terceiros sejam baixados e instalados em seu ambiente, em alguns casos, de sites de terceiros. Para cada pacote de software de terceiros, consulte o arquivo de aviso e os sites aplicáveis para obter mais informações, incluindo os termos de licença aplicáveis.
Se você não deseja baixar e instalar pacotes de software de terceiros, não configure, inicie ou use este AMP. Ao configurar, iniciar ou usar o AMP, você reconhece a declaração acima e concorda que a Cloudera não é responsável de forma alguma pelos pacotes de software de terceiros.
Copyright (c) 2024 - Cloudera, Inc. Todos os direitos reservados.


