qwen2 in a lambda
1.0.0
Atualizado em 09/11/2024
(Marcar a data devido à rapidez com que as APIs LLM em Python se movem e pode introduzir alterações significativas no momento em que alguém ler isto!)
Esta é uma pequena pesquisa sobre como podemos colocar arquivos de modelo Qwen GGUF no AWS Lambda usando Docker e SAM CLI
Adaptado de https://makit.net/blog/llm-in-a-lambda-function/
Eu queria descobrir se posso reduzir meus gastos com AWS aproveitando apenas os recursos do Lambda e não do Lambda + Bedrock, pois ambos os serviços incorreriam em mais custos no longo prazo.
A ideia era ajustar um modelo de linguagem pequeno que não consumisse tantos recursos relativamente falando e, esperançosamente, receber latência de subsegundo a segundo em uma configuração de memória de 128 a 256 MB
Eu queria usar também modelos GGUF para usar diferentes níveis de quantização para descobrir qual é o melhor desempenho/tamanho de arquivo a ser carregado na memória
qwen2-1_5b-instruct-q5_k_m.gguf em qwen_fuction/function/app.y / LOCAL_PATH qwen_function/function/requirements.txt (de preferência em um ambiente venv/conda)sam build / sam validatesam local start-api para testar localmentecurl --header "Content-Type: application/json" --request POST --data '{"prompt":"hello"}' http://localhost:3000/generate para solicitar o LLMsam deploy --guided para implantar na AWS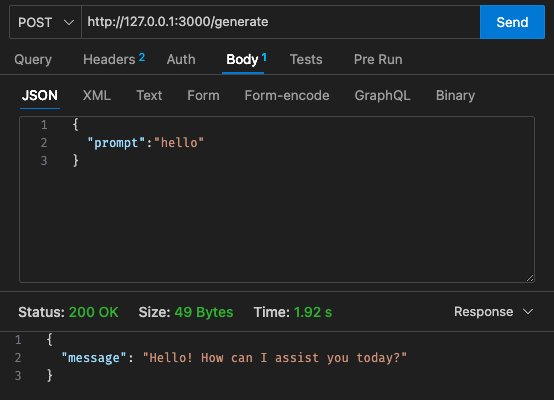
AWS
Configuração inicial - 128 MB, tempo limite de 30 segundos
Configuração ajustada nº 1 - 512 MB, tempo limite de 30 segundos
Configuração ajustada nº 2 - 512 MB, tempo limite de 30 segundos
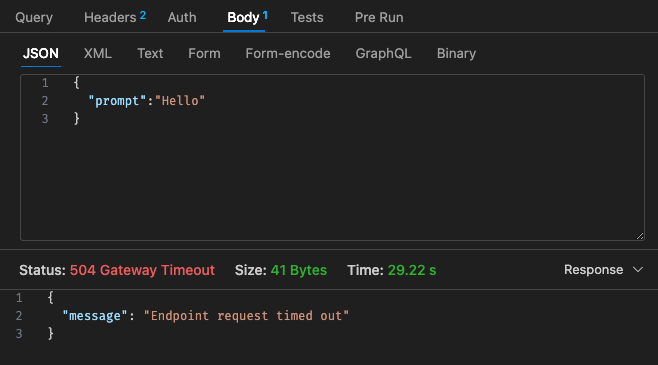
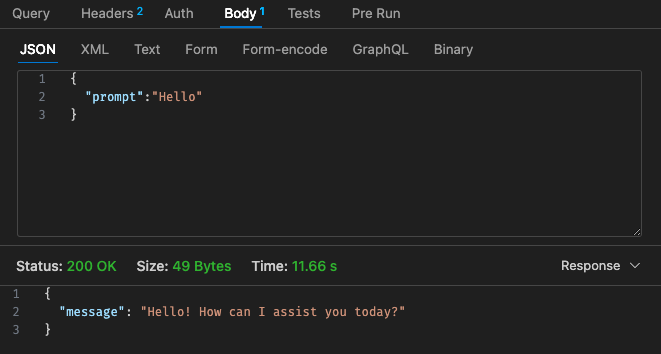
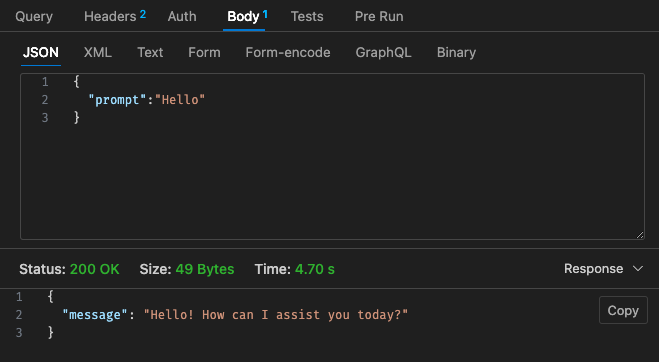
Referindo-nos à estrutura de preços do Lambda,
Pode ser mais barato usar apenas um LLM hospedado usando AWS Bedrock, etc. na nuvem, pois a estrutura de preços do Lambda com Qwen não parece mais competitiva em comparação com Claude 3 Haiku
Além disso, o tempo limite do gateway da API não é facilmente configurável além do tempo limite de 30 segundos, dependendo do seu caso de uso, isso pode não ser muito ideal
Os resultados via local dependem das especificações da sua máquina!! e pode distorcer fortemente sua percepção, expectativa versus realidade
Dependendo também do seu caso de uso, a latência por invocação e respostas lambda pode gerar experiências ruins para o usuário
Resumindo, acho que foi um pequeno experimento divertido, embora não tenha atendido aos requisitos de orçamento e latência do Qwen 1.5b para meu projeto paralelo. Obrigado a @makit novamente pelo guia!


