genkitx hnsw
1.0.0

Você pode contribuir com este plugin neste Repositório.
HNSW é um banco de dados de vetores Hierarchical Navigable Small World (HNSW) que está entre os índices de melhor desempenho para pesquisa de similaridade vetorial. HNSW é uma tecnologia extremamente popular que sempre produz desempenho de última geração com velocidades de pesquisa super rápidas e recuperação fantástica. saiba mais sobre o HNSW.
Você pode preferir este banco de dados vetorial se preferir
Com isso, você pode obter uma geração de aumento de recuperação (RAG) de alto desempenho em IA generativa, para que não precise construir seu próprio modelo de IA ou retreinar o modelo de IA para obter mais contexto ou conhecimento; em vez disso, você pode adicionar uma camada adicional de contexto para que seu modelo de IA pode compreender mais conhecimento do que o modelo de IA básico conhece. isso é útil se você deseja obter mais contexto ou mais conhecimento com base em informações ou conhecimentos específicos que você define.
Você tem um aplicativo ou site de restaurante, pode adicionar informações específicas sobre seus restaurantes, endereço, lista de cardápio de comida com seu preço e outras coisas específicas, para que quando seu cliente perguntar algo à IA sobre seu restaurante, sua IA possa responder com precisão . isso pode eliminar seu esforço para construir um Chatbot; em vez disso, você pode usar IA generativa enriquecida com conhecimento específico.
Exemplo de conversa:
You : Qual é a lista de preços do meu restaurante na cidade de Surabaya?
AI : Lista de preços:
Antes de instalar o plugin, certifique-se de ter os seguintes pré-requisitos instalados:
npm install -g typescript )Para instalar este plugin, você pode executar este comando ou com seu gerenciador de pacotes preferido
npm install genkitx-hnswEste plugin possui diversas funcionalidades conforme abaixo:
HNSW Indexer Usado para criar um índice vetorial com base em todos os dados e informações que você forneceu. este Índice vetorial será usado como referência de conhecimento do HNSW Retriever.HNSW Retriever Usado para obter resposta generativa de IA com o modelo Gemini como base enriquecida com conhecimento e contexto adicionais com base em seu índice vetorial. Este é um uso do fluxo do plugin Genkit para salvar dados no armazenamento de vetores com HNSW Vector Store, Gemini Embedder e Gemini LLM.
Prepare seus dados ou documentos em uma pasta 
Importe o plugin para o seu projeto Genkit
import { hnswIndexer } from " genkitx-hnsw " ;
export default configureGenkit({
plugins: [
hnswIndexer({ apiKey: " GOOGLE_API_KEY " })
]
}) ; Abra Genkit UI e escolha o plugin registrado HNSW Indexer
Execute o fluxo com o parâmetro obrigatório de entrada e saída
dataPath : O caminho dos seus dados e outros documentos a serem aprendidos pela IAindexOutputPath : seu caminho de saída esperado para seu índice de armazenamento de vetores que é processado com base nos dados e documentos que você forneceu 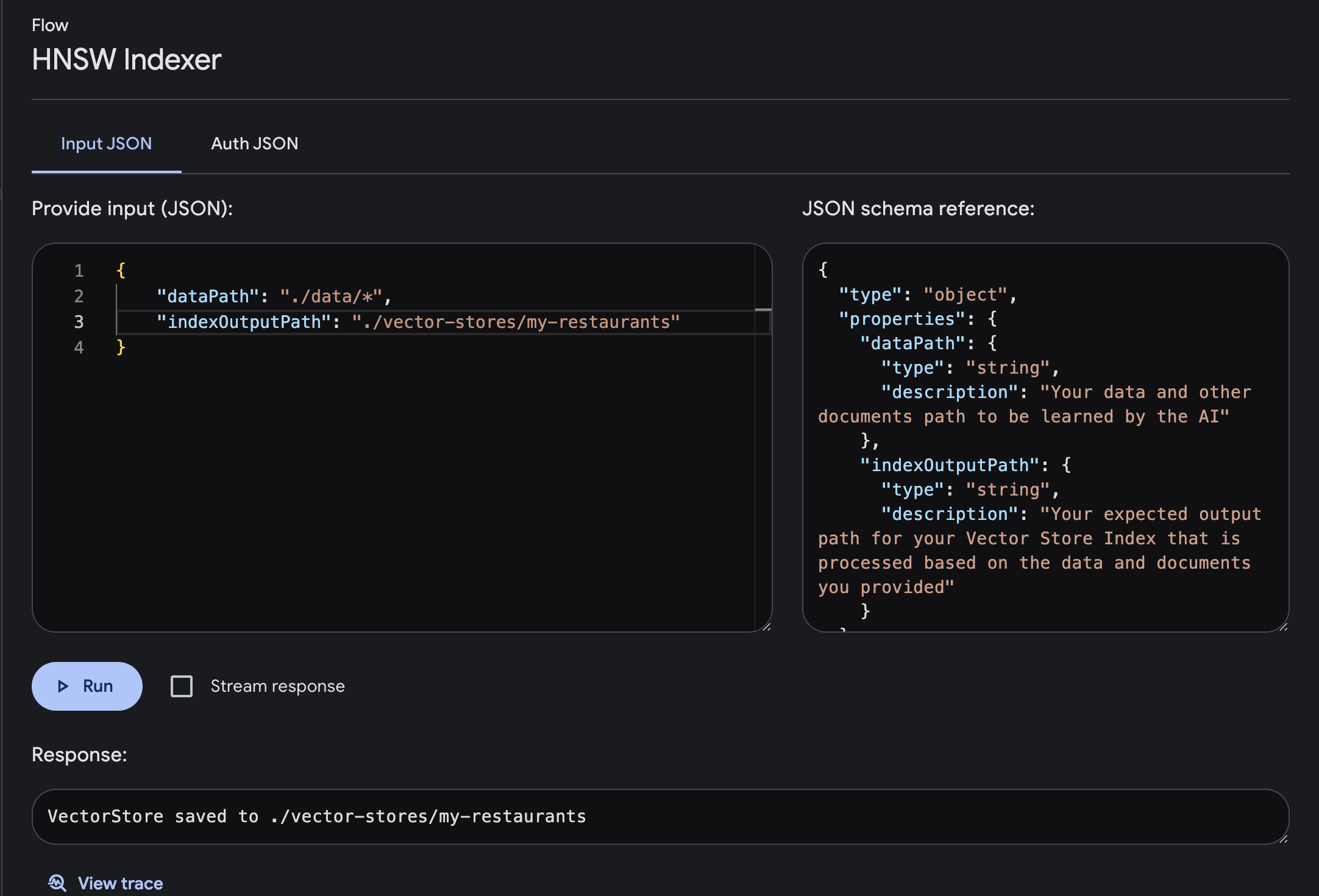
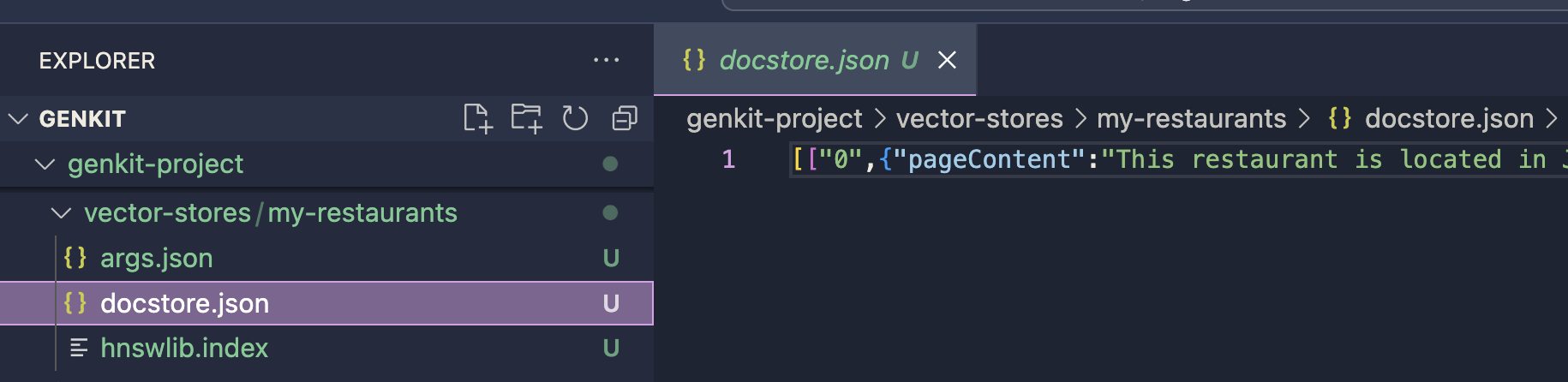 O armazenamento de vetores será salvo no caminho de saída definido. este índice será usado para o processo de geração de prompt com o plugin HNSW Retriever. você pode continuar a implementação usando o plugin HNSW Retriever
O armazenamento de vetores será salvo no caminho de saída definido. este índice será usado para o processo de geração de prompt com o plugin HNSW Retriever. você pode continuar a implementação usando o plugin HNSW Retriever
chunkSize: number Quantos dados são processados por vez. É como dividir uma grande tarefa em pedaços menores para torná-la mais gerenciável. Ao definir o tamanho do bloco, decidimos quanta informação a IA trata de uma só vez, o que pode afetar a velocidade e a precisão do processo de aprendizagem da IA.
default value : 12720
separator: string Durante a criação de um índice vetorial, é um símbolo ou caractere usado para separar diferentes informações nos dados de entrada. Ajuda a IA a compreender onde termina uma unidade de dados e começa outra, permitindo-lhe processar e aprender com os dados de forma mais eficaz.
default value : "n"
Este é um uso do fluxo do plugin Genkit para processar seu prompt com o modelo Gemini LLM enriquecido com informações ou conhecimentos adicionais e específicos dentro do banco de dados de vetores HNSW que você forneceu. com este plugin você obterá resposta LLM com contexto específico adicional.
Importe o plugin para o seu projeto Genkit
import { googleAI } from " @genkit-ai/googleai " ;
import { hnswRetriever } from " genkitx-hnsw " ;
export default configureGenkit({
plugins: [
googleAI (),
hnswRetriever({ apiKey: " GOOGLE_API_KEY " })
]
}) ;Certifique-se de importar o plugin GoogleAI para o provedor de modelo Gemini LLM, atualmente este plugin suporta apenas Gemini, fornecerá mais modelos em breve!
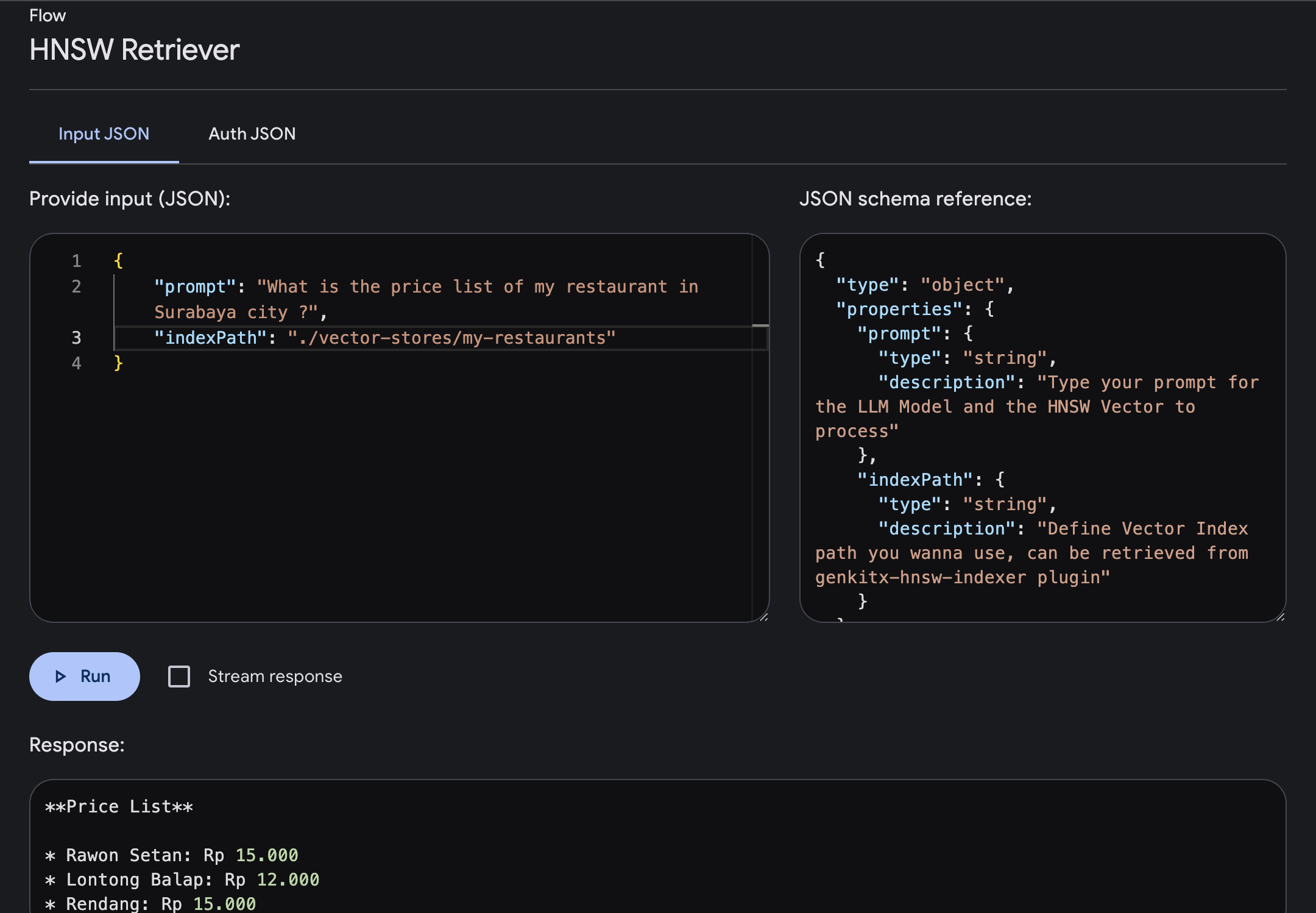
Abra Genkit UI e escolha o Plugin HNSW Retriever registrado Execute o fluxo com o parâmetro necessário
prompt : digite seu prompt onde você obterá respostas com um contexto mais enriquecido com base no vetor fornecido.indexPath : Defina o caminho do índice vetorial da pasta que você deseja usar como referência de conhecimento, onde você obtém esse caminho de arquivos do plugin HNSW Indexer.Neste exemplo, vamos tentar perguntar sobre as informações da lista de preços de um restaurante na cidade de Surabaya, onde foram fornecidas no Vector Index.
Podemos digitar o prompt e executá-lo, após o término do fluxo, você receberá uma resposta enriquecida com conhecimentos específicos baseados no seu Índice de Vetores.
temperature: number controla a aleatoriedade da saída gerada. Temperaturas mais baixas resultam em resultados mais determinísticos, com o modelo selecionando o token mais provável em cada etapa. Temperaturas mais altas aumentam a aleatoriedade, permitindo que o modelo explore tokens menos prováveis, gerando potencialmente um texto mais criativo, mas menos coerente.
default value : 0.1
maxOutputTokens: number Este parâmetro especifica o número máximo de tokens (palavras ou subpalavras) que o modelo deve gerar em uma única etapa de inferência. Ajuda a controlar o comprimento do texto gerado.
default value : 500
topK: number A amostragem Top-K restringe as escolhas do modelo aos K tokens mais prováveis em cada etapa. Isto ajuda a evitar que o modelo considere tokens excessivamente raros ou improváveis, melhorando a coerência do texto gerado.
default value : 1
topP: number A amostragem Top-P, também conhecida como amostragem de núcleo, considera a distribuição de probabilidade cumulativa de tokens e seleciona o menor conjunto de tokens cuja probabilidade cumulativa excede um limite predefinido (geralmente denotado como P). Isto permite a seleção dinâmica do número de tokens considerados em cada etapa, dependendo da probabilidade dos tokens.
default value : 0
stopSequences: string[] São sequências de tokens que, quando gerados, sinalizam ao modelo para parar de gerar texto. Isso pode ser útil para controlar o comprimento ou o conteúdo da saída gerada, como garantir que o modelo pare de gerar após chegar ao final de uma frase ou parágrafo.
default value : []
Licença: Apache 2.0


