opensquare
1.0.0

Inteligência de mídia social de código aberto e OSINT
Explore os documentos »
Ver demonstração · Reportar bug · Solicitar recurso
Houve 150 milhões de novos utilizadores de redes sociais entre Abril de 2022 e Abril de 2023 – um aumento de 3,2% face ao ano anterior em relação aos actuais 4,8 mil milhões de utilizadores de redes sociais em todo o mundo, representando 59,9% da população global e 92,7% de todos os utilizadores da Internet. As empresas usam as mídias sociais para obter insights sobre vários tópicos: sentimento do usuário em relação aos produtos, produtos fortes e produtos fracos, eventos, todas as coisas que atendem aos seus clientes. Para analistas de inteligência e pesquisadores de ciências sociais, quem são seus clientes? Os decisores políticos, o cidadão comum, todos na sociedade. O usuário deste projeto, seu cliente, são os analistas e pesquisadores de inteligência e ciências sociais. À medida que a tecnologia continua a subir a curva da inovação e a sociedade continua a utilizar cada vez mais as redes sociais como praça pública, os investigadores podem utilizar estes dados disponíveis para o bem, para extrair insights, para abrandar ou parar incidentes prejudiciais, para ajudar a sociedade, para desenvolver planos com base no consenso público, informar melhor os decisores políticos sobre o que os seus constituintes necessitam e desejam (e planear melhor soluções que aumentem a satisfação dos seus clientes). À medida que se torna mais difícil para os governos compreender e executar soluções que sirvam melhor os seus constituintes, a ideia de governação adaptativa, com foco em estruturas descentralizadas de tomada de decisão, torna-se inevitável. Os conhecimentos obtidos a partir dos meios de comunicação social não só podem ajudar os decisores políticos, como também podem ajudar entidades e grupos de governação adaptativa a servirem melhor as suas populações. Este produto destina-se ao analista de inteligência, ao cientista social, ao cientista de dados e àqueles interessados em melhorar a qualidade da nossa existência humana através de análises públicas profundas e soluções baseadas em dados.
(voltar ao topo)
(voltar ao topo)
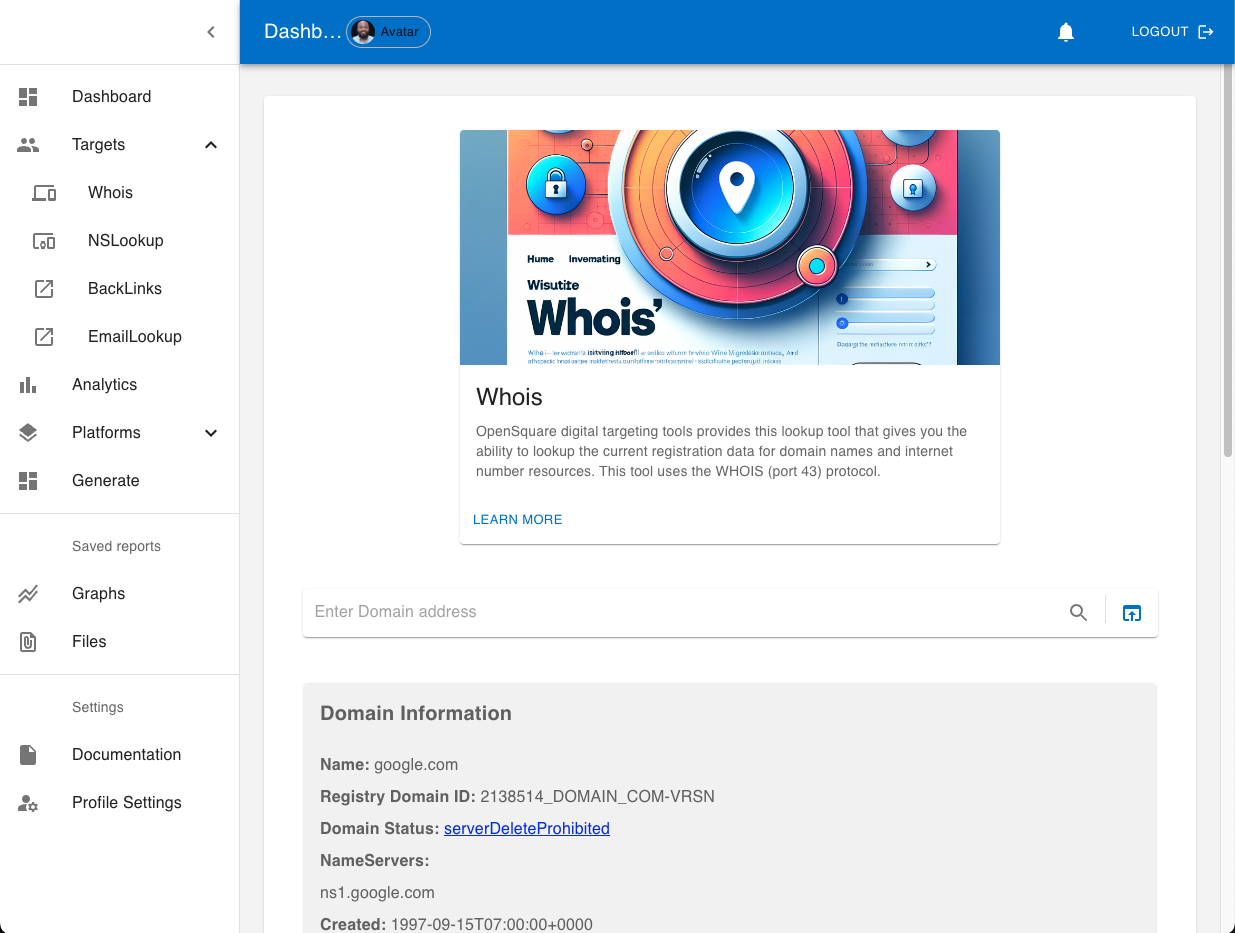
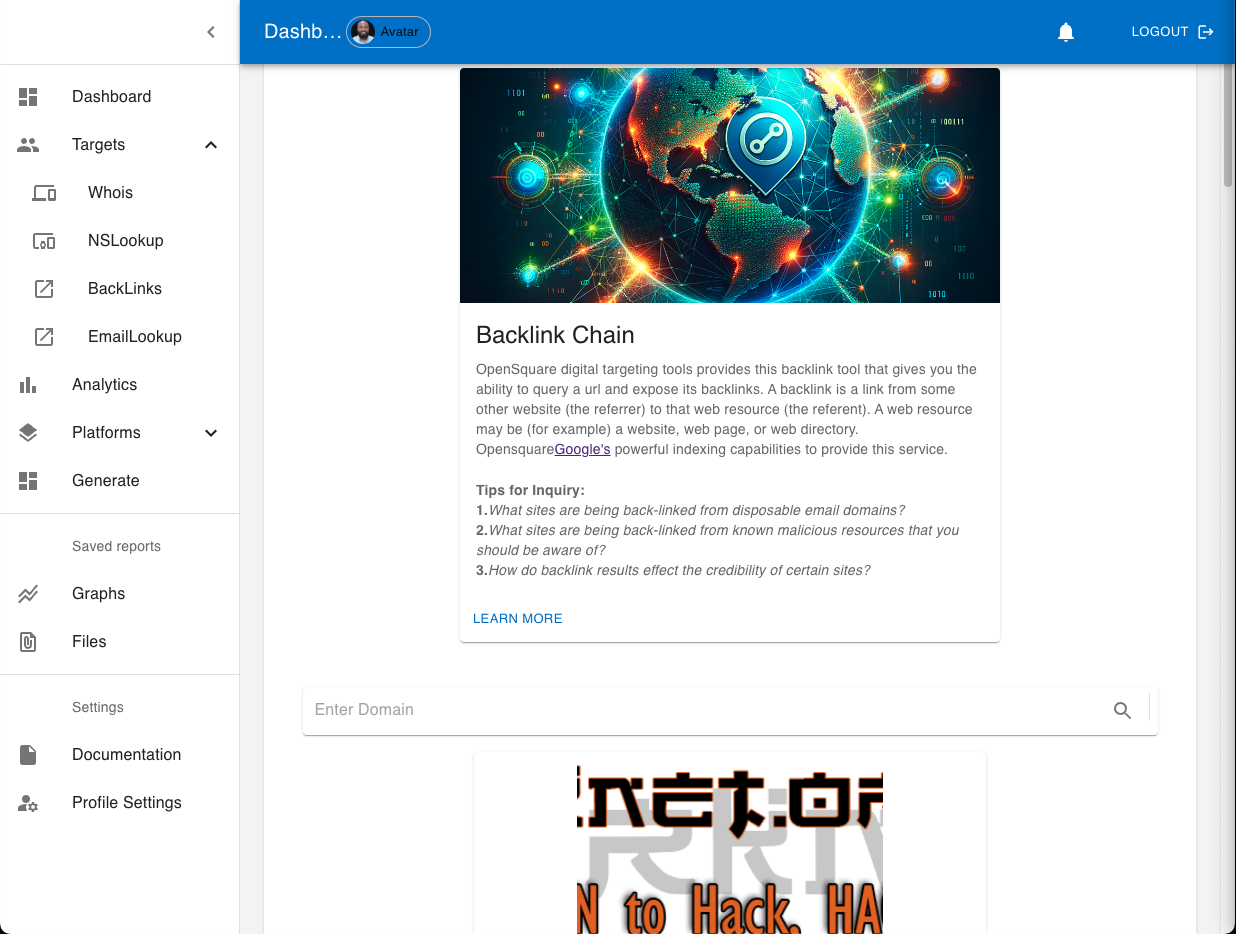
Junto com outros recursos, o OpenSquare fornece ferramentas de segmentação Digit Footprint, algumas usando métodos OSINT bem conhecidos, como Backlinks, NSLookup e Whois. Ter um conjunto geral de ferramentas em um único local pode aumentar a produtividade do usuário. Navegue facilmente entre os espaços de trabalho do painel e use a saída de uma ferramenta como entrada para outra.
Experimente gerar relatórios e documentos com GenAI. Use as informações e imagens que você coletou para gerar relatórios que resultem em vantagem de decisão. Peça ao nosso sistema de IA para gerar imagens para você com base no contexto da informação e resumir os principais detalhes. Aumente a produtividade e reduza drasticamente a velocidade de entrega de insights importantes aos tomadores de decisão usando interfaces arrastáveis e de clicar e apontar.
Opensquare utiliza Whisper: um modelo de reconhecimento de fala de uso geral. Ele é treinado em um grande conjunto de dados de áudio diversificado e também é um modelo multitarefa que pode realizar reconhecimento de fala multilíngue, tradução de fala e identificação de idioma.
Usando as APIs disponíveis do Opensquare, você pode consultar e transcrever vídeos do YouTube. As transcrições relatarão o tempo e as propriedades do texto. Esta API é usada para construir recursos no Opensquare, mas também estará disponível ao público como uma API fácil de usar.
opensquare/api/youtube/en/transcribe?videoId=l9AzO1FMgM8
produz:
[ { "time": "0.0", "text": "Java, a high-level multi-paradigm programming language famous for its ability to compile" }, { "time": "5.2", "text": "to platform independent bytecode." }, { "time": "7.44", "text": "It was designed by James Gosling in 1990 at Sun Microsystems." }, { "time": "11.700000000000001", "text": "One of its first demonstrations was the Star 7 PDA, which gave birth to the Java mascot" },... ]
Para obter uma cópia local instalada e funcionando, siga estas etapas simples de exemplo.
Linux
Java 17
java --versionMaven 3.9 ou superior
mvn --versionClonar o repositório
git git clone https://[email protected]/intelligence-opensent/opensentop.gitInstale o perfil padrão de dependências (incluindo NPM)
mvn clean installExecute o webpack em modo de desenvolvimento
npm run watch
Existem alguns arquivos de configuração que você precisa - sinta-se à vontade para me enviar um ping para eles.
(voltar ao topo)
Este projeto usa o Frontend-Maven-Plugin de Eirik Sletteberg, que permite que nossa equipe use um único plugin para compilações de front-end e back-end em um único repositório. Este plugin é capaz de diversas configurações, mas a configuração utilizada neste projeto é mínima apenas usando Webpack e poucas configurações para instalação de Node e NPM. A essência desse uso vem da criação do pacote do projeto que é integrado usando um <script> na raiz do aplicativo React (típico do React) exposto no arquivo index.html na pasta de recursos do Springboot.
<body>
<div id='root'>
</div>
<script src="built/bundle.js"></script>
</body>
O Webpack criará um pacote de construção que contém a fonte da entrada do aplicativo React em app.js no pacote js deste projeto.
entry: path.resolve(__dirname, "/src/main/js/app.js"),
devtool: 'inline-source-map',
cache: true,
mode: 'development',
output: {
path: __dirname,
filename: 'src/main/resources/static/built/bundle.js'
},
(voltar ao topo)
Se você estiver executando o kafka, revise os documentos. Primeiro, certifique-se de que o servidor zoo-keeper esteja em execução antes de executar o servidor kafka. Às vezes, a pasta zookeeper configs /config não está configurada corretamente. Se necessário, certifique-se de que clientPort=2181 esteja definido em zookeeper.properties e para garantir portas não conflitantes, certifique-se de admin.serverPort=8083 esteja definido no mesmo arquivo. Também queremos garantir que bootstrap.servers=9092 esteja configurado em producer.properties : esta é uma lista de corretores usados para inicializar o conhecimento sobre o restante do formato de cluster, o que é importante para a configuração do springboot deste projeto abaixo:
@Bean
public ConsumerFactory<String, OpenSentTaskStatus> consumerFactory() {
Map<String, Object> configurationProperties = new HashMap<>();
configurationProperties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");
configurationProperties.put(ConsumerConfig.GROUP_ID_CONFIG, "group_id");
configurationProperties.put(JsonDeserializer.TRUSTED_PACKAGES, "*");
configurationProperties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
configurationProperties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, JsonDeserializer.class);
configurationProperties.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "earliest");
return new DefaultKafkaConsumerFactory<>(configurationProperties);
}
@Bean
public ProducerFactory<String, OpenSentTaskStatus> producerFactory() {
Map<String, Object> props = new HashMap<>();
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class);
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, JsonSerializer.class);
return new DefaultKafkaProducerFactory<>(props);
}
Consulte os problemas em aberto para obter uma lista completa dos recursos propostos (e dos problemas conhecidos).
(voltar ao topo)
(voltar ao topo)
Wali Morris - @LinkedIn - [email protected]
Link do projeto: GitHub
(voltar ao topo)
(voltar ao topo)


