Interactive RAG
1.0.0
Os agentes estão revolucionando a forma como aproveitamos os modelos de linguagem para a tomada de decisões e o desempenho de tarefas. Agentes são sistemas que utilizam modelos de linguagem para tomar decisões e executar tarefas. Eles são projetados para lidar com cenários complexos e fornecer mais flexibilidade em comparação com abordagens tradicionais. Os agentes podem ser considerados mecanismos de raciocínio que aproveitam modelos de linguagem para processar informações, recuperar dados relevantes, ingerir (pedaços/incorporar) e gerar respostas.
No futuro, os agentes desempenharão um papel vital no processamento de texto, na automatização de tarefas e na melhoria das interações homem-computador à medida que os modelos de linguagem avançam.
Neste exemplo, focaremos especificamente na alavancagem de agentes na Geração Aumentada de Recuperação (RAG) dinâmica. Usando ActionWeaver e MongoDB Atlas, você poderá modificar sua estratégia RAG em tempo real por meio de interações conversacionais. Seja selecionando mais pedaços, aumentando o tamanho do pedaço ou ajustando outros parâmetros, você pode ajustar sua abordagem RAG para obter a qualidade e precisão de resposta desejadas. Você pode até adicionar/remover fontes do seu banco de dados de vetores usando linguagem natural!
# LLM Config
self.rag_config = {
"num_sources": 2,
"source_chunk_size": 1000,
"min_rel_score": 0.00,
"unique": True,
"summarize_chunks": True, # adds latency at ingest, everything comes at a cost
}
O texto fragmentado é ótimo, mas como armazená-lo?
Resumir economiza espaço e acelera as coisas, mas pode perder detalhes.
O armazenamento de dados brutos é preciso, mas volumoso, mais lento e "ruidoso".
Prós de resumir:
Contras de resumir:
O que é certo para você? Depende das suas necessidades! Considerar:
DEMONSTRAÇÃO 1
Crie um novo ambiente Python
python3 -m venv envAtive o novo ambiente Python
source env/bin/activateInstale os requisitos
pip3 install -r requirements.txtDefina os parâmetros em params.py:
# MongoDB
MONGODB_URI = " "
DATABASE_NAME = " genai "
COLLECTION_NAME = " rag "
# If using OpenAI
OPENAI_API_KEY = " "
# If using Azure OpenAI
OPENAI_TYPE = " azure "
OPENAI_API_VERSION = " 2023-10-01-preview "
OPENAI_AZURE_ENDPOINT = " https://.openai.azure.com/ "
OPENAI_AZURE_DEPLOYMENT = " "
Crie um índice de pesquisa com a seguinte definição
{
"mappings" : {
"dynamic" : true ,
"fields" : {
"embedding" : {
"dimensions" : 384 ,
"similarity" : " cosine " ,
"type" : " knnVector "
}
}
}
}Defina o ambiente
export OPENAI_API_KEY=Para executar o aplicativo RAG
env/bin/streamlit run rag/app.pyAs informações de log geradas pelo aplicativo serão anexadas ao app.log.
Este bot suporta as seguintes ações: responder perguntas, pesquisar na web, ler URLs, remover fontes, listar todas as fontes e redefinir mensagens. Ele também suporta uma ação chamada iRAG que permite controlar dinamicamente a estratégia RAG do seu agente.
Ex: "definir configuração RAG para 3 fontes e tamanho de bloco 1250" => Nova configuração RAG:{'num_sources': 3, 'source_chunk_size': 1250, 'min_rel_score': 0, 'unique': True}.
def __call__(self, text):
text = self.preprocess_query(text)
self.messages += [{"role": "user", "content":text}]
response = self.llm.create(messages=self.messages, actions = [
self.read_url,self.answer_question,self.remove_source,self.reset_messages,
self.iRAG, self.get_sources_list,self.search_web
], stream=True)
return response
Se o bot não conseguir fornecer uma resposta à pergunta a partir dos dados armazenados na loja Atlas Vector e de sua estratégia RAG (número de fontes, tamanho do bloco, min_rel_score, etc.), ele iniciará uma pesquisa na web para encontrar informações relevantes. Você pode então instruir o bot a ler e aprender com esses resultados.
RAG é legal e tudo mais, mas criar a “estratégia RAG” certa é complicado. O tamanho do bloco e o número de fontes únicas terão um impacto direto na resposta gerada pelo LLM.
No desenvolvimento de uma estratégia RAG eficaz, o processo de ingestão de fontes da web, agrupamento, incorporação, tamanho do bloco e a quantidade de fontes usadas desempenham papéis cruciais. A fragmentação divide o texto de entrada para melhor compreensão, a incorporação captura o significado e o número de fontes impacta a diversidade de respostas. Encontrar o equilíbrio certo entre o tamanho do bloco e o número de fontes é essencial para respostas precisas e relevantes. Experimentação e ajuste fino são necessários para determinar as configurações ideais.
Antes de mergulharmos em 'Recuperação', vamos primeiro falar sobre "Processo de Ingestão"
Por que ter um processo separado para “ingerir” seu conteúdo em seu banco de dados vetorial? Usando a magia dos agentes, podemos facilmente adicionar novo conteúdo ao banco de dados vetorial.
Existem muitos tipos de bancos de dados que podem armazenar esses embeddings, cada um com seus usos especiais. Mas para tarefas que envolvem aplicações GenAI, recomendo o MongoDB.
Pense no MongoDB como um bolo que você pode comer e comer. Dá a você o poder de sua linguagem para fazer consultas, Mongo Query Language. Também inclui todos os excelentes recursos do MongoDB. Além disso, permite armazenar esses blocos de construção (incorporação vetorial) e realizar operações matemáticas neles, tudo em um só lugar. Isso torna o MongoDB Atlas um balcão único para todas as suas necessidades de incorporação de vetores!
@action("read_url", stop=True)
def read_url(self, urls: List[str]):
"""
Invoke this ONLY when the user asks you to 'read', 'add' or 'learn' some URL(s).
This function reads the content from specified sources, and ingests it into the Knowledgebase.
URLs may be provided as a single string or as a list of strings.
IMPORTANT! Use conversation history to make sure you are reading/learning/adding the right URLs.
Parameters
----------
urls : List[str]
List of URLs to scrape.
Returns
-------
str
A message indicating successful reading of content from the provided URLs.
"""
with self.st.spinner(f"```Analyzing the content in {urls}```"):
loader = PlaywrightURLLoader(urls=urls, remove_selectors=["header", "footer"])
documents = loader.load_and_split(self.text_splitter)
self.index.add_documents(
documents
)
return f"```Contents in URLs {urls} have been successfully ingested (vector embeddings + content).```"
{
"mappings": {
"dynamic": true,
"fields": {
"embedding": {
"dimensions": 384, #dimensions depends on the model
"similarity": "cosine",
"type": "knnVector"
}
}
}
}
def recall(self, text, n_docs=2, min_rel_score=0.25, chunk_max_length=800,unique=True):
#$vectorSearch
print("recall=>"+str(text))
response = self.collection.aggregate([
{
"$vectorSearch": {
"index": "default",
"queryVector": self.gpt4all_embd.embed_query(text), #GPT4AllEmbeddings()
"path": "embedding",
#"filter": {},
"limit": 15, #Number (of type int only) of documents to return in the results. Value can't exceed the value of numCandidates.
"numCandidates": 50 #Number of nearest neighbors to use during the search. You can't specify a number less than the number of documents to return (limit).
}
},
{
"$addFields":
{
"score": {
"$meta": "vectorSearchScore"
}
}
},
{
"$match": {
"score": {
"$gte": min_rel_score
}
}
},{"$project":{"score":1,"_id":0, "source":1, "text":1}}])
tmp_docs = []
str_response = []
for d in response:
if len(tmp_docs) == n_docs:
break
if unique and d["source"] in tmp_docs:
continue
tmp_docs.append(d["source"])
str_response.append({"URL":d["source"],"content":d["text"][:chunk_max_length],"score":d["score"]})
kb_output = f"Knowledgebase Results[{len(tmp_docs)}]:n```{str(str_response)}```n## n```SOURCES: "+str(tmp_docs)+"```nn"
self.st.write(kb_output)
return str(kb_output)
Usando ActionWeaver, um wrapper leve para API de chamada de função, podemos construir um agente proxy de usuário que recupera e ingere informações relevantes com eficiência usando MongoDB Atlas.
Um agente proxy é um intermediário que envia solicitações de clientes para outros servidores ou recursos e depois traz as respostas de volta.
Este agente apresenta os dados ao usuário de forma interativa e customizável, melhorando a experiência geral do usuário.
O UserProxyAgent possui vários parâmetros RAG que podem ser customizados, como chunk_size (ex. 1000), num_sources (ex. 2), unique (ex. True) e min_rel_score (ex. 0,00).
class UserProxyAgent:
def __init__(self, logger, st):
self.rag_config = {
"num_sources": 2,
"source_chunk_size": 1000,
"min_rel_score": 0.00,
"unique": True,
}
Aqui estão alguns benefícios importantes que influenciaram nossa decisão de escolher o ActionWeaver:
Um agente é basicamente apenas um programa ou sistema de computador projetado para perceber seu ambiente, tomar decisões e atingir objetivos específicos.
Pense em um agente como uma entidade de software que apresenta algum grau de autonomia e executa ações em seu ambiente em nome de seu usuário ou proprietário, mas de forma relativamente independente. Toma iniciativas para realizar ações por conta própria, deliberando suas opções para atingir seu(s) objetivo(s). A ideia central dos agentes é usar um modelo de linguagem para escolher uma sequência de ações a serem executadas. Em contraste com as cadeias, onde uma sequência de ações é codificada, os agentes usam um modelo de linguagem como mecanismo de raciocínio para determinar quais ações tomar e em que ordem.
Ações são funções que um agente pode invocar. Existem duas considerações importantes de design em torno das ações:
Giving the agent access to the right actions
Describing the actions in a way that is most helpful to the agent
Sem pensar em ambos, você não será capaz de construir um agente funcional. Se você não der ao agente acesso a um conjunto correto de ações, ele nunca será capaz de cumprir os objetivos que você atribuiu. Se você não descrever bem as ações, o agente não saberá como utilizá-las adequadamente.
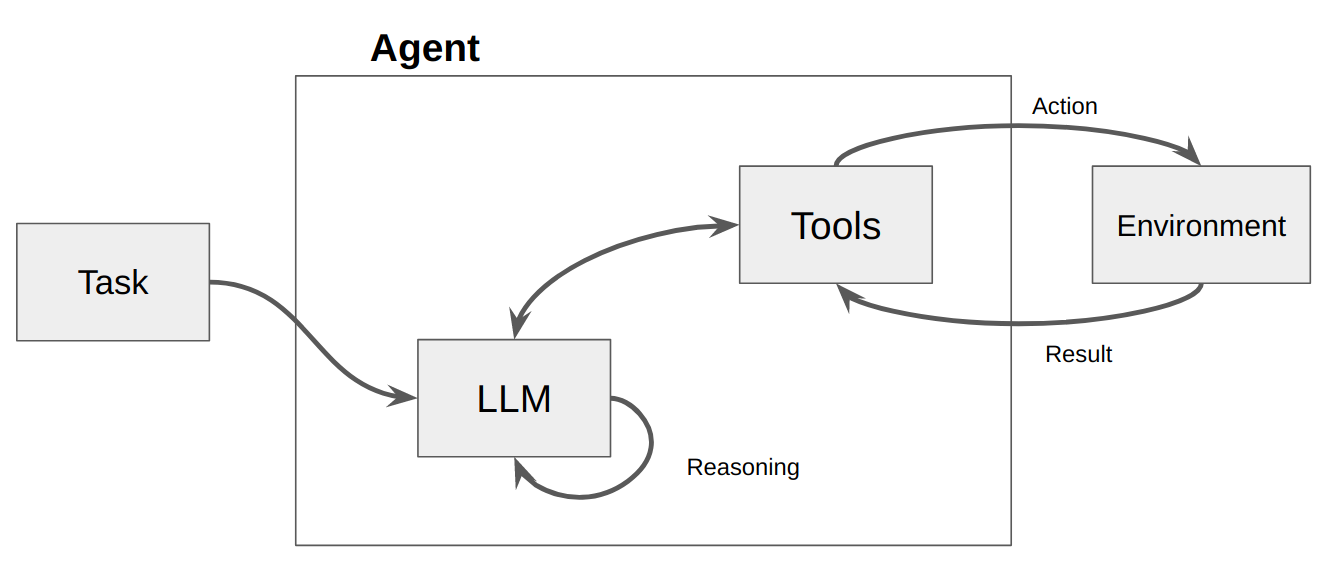
Um LLM é então chamado, resultando em uma resposta ao usuário OU em ações a serem executadas. Se for determinado que uma resposta é necessária, ela será passada ao usuário e o ciclo será encerrado. Se for determinado que uma ação é necessária, essa ação será então executada e uma observação (resultado da ação) será feita. Essa ação e a observação correspondente são adicionadas de volta ao prompt (chamamos isso de “pasta de rascunho do agente”) e o loop é redefinido, ou seja. o LLM é chamado novamente (com o scratchpad do agente atualizado).
No ActionWeaver, podemos influenciar o loop adicionando stop=True|False a uma ação. Se stop=True , o LLM retornará imediatamente a saída da função. Isto também restringirá o LLM de fazer múltiplas chamadas de função. Nesta demonstração usaremos apenas stop=True
ActionWeaver também suporta controle de loop mais complexo usando orch_expr(SelectOne[actions]) e orch_expr(RequireNext[actions]) , mas deixarei isso para a PARTE II.
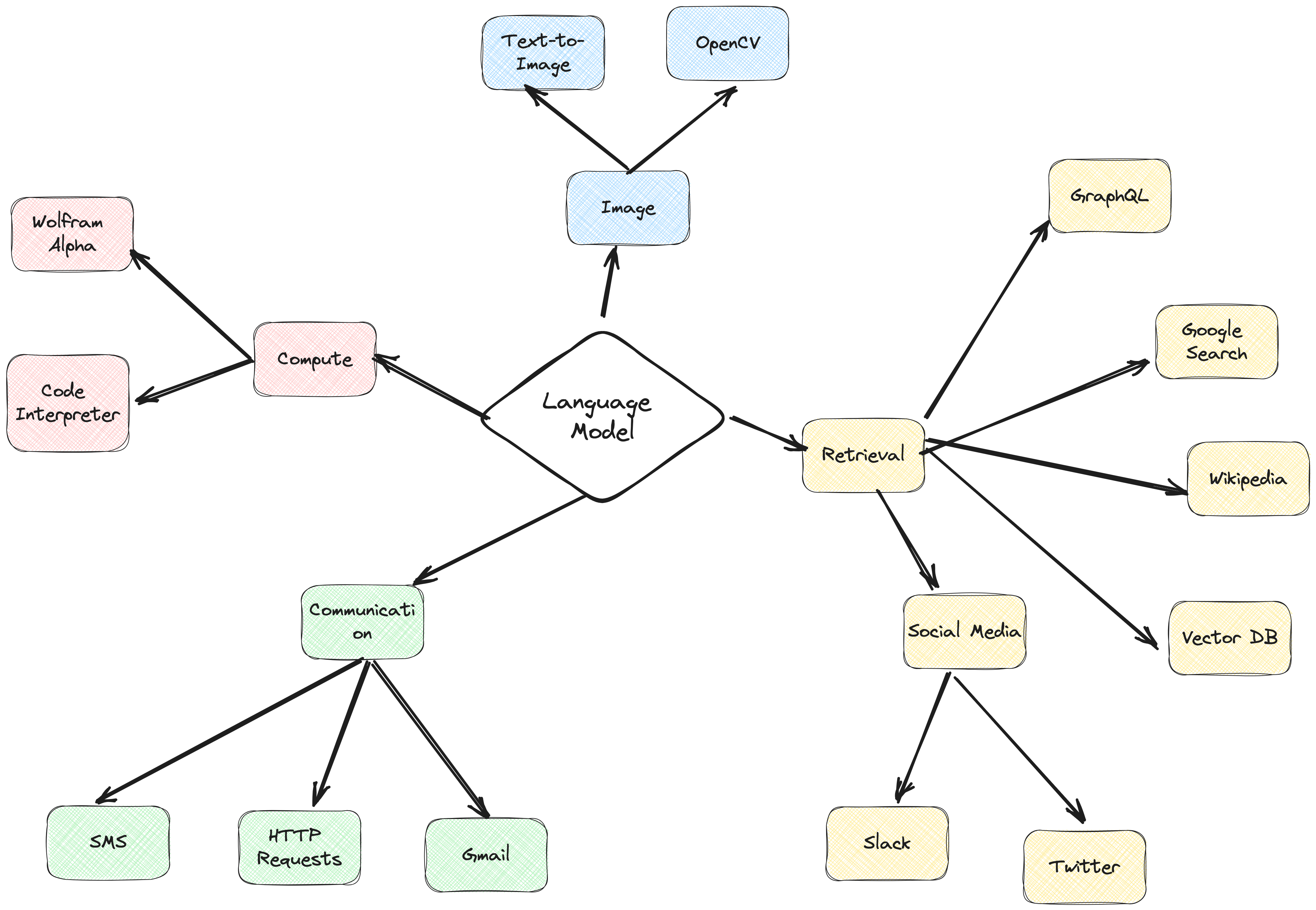
A estrutura do agente ActionWeaver é uma estrutura de aplicativo de IA que coloca a chamada de função em seu núcleo. Ele foi projetado para permitir a fusão perfeita de sistemas de computação tradicionais com os poderosos recursos de raciocínio dos Modelos de Linguagem. ActionWeaver é construído em torno do conceito de chamada de função LLM, enquanto estruturas populares como Langchain e Haystack são construídas em torno do conceito de pipelines.

Leia mais em: https://thinhdanggroup.github.io/function-calling-openai/
Os desenvolvedores podem anexar QUALQUER função Python como uma ferramenta com um decorador simples. No exemplo a seguir, apresentamos a ação get_sources_list, que será invocada pela API OpenAI.
ActionWeaver utiliza a assinatura e a documentação do método decorado como descrição, passando-os para a API de função do OpenAI.
ActionWeaver fornece um wrapper leve que se encarrega de converter as informações do docstring/decorator no formato correto para a API OpenAI.
@action(name="get_sources_list", stop=True)
def get_sources_list(self):
"""
Invoke this to respond to list all the available sources in your knowledge base.
Parameters
----------
None
"""
sources = self.collection.distinct("source")
if sources:
result = f"Available Sources [{len(sources)}]:n"
result += "n".join(sources[:5000])
return result
else:
return "N/A"
stop=True quando adicionado a uma ação significa que o LLM retornará imediatamente a saída da função, mas isso também restringe o LLM de fazer múltiplas chamadas de função. Por exemplo, se questionado sobre o clima em Nova York e São Francisco, o modelo invocaria duas funções separadas sequencialmente para cada cidade. No entanto, com stop=True , esse processo é interrompido quando a primeira função retorna informações meteorológicas de Nova York ou São Francisco, dependendo da cidade que ela consulta primeiro.
Para uma compreensão mais aprofundada de como esse bot funciona nos bastidores, consulte o arquivo bot.py. Além disso, você pode explorar o repositório ActionWeaver para obter mais detalhes.
A geração de rastreamentos de raciocínio permite que o modelo induza, rastreie e atualize planos de ação e até mesmo lide com exceções. Este exemplo usa ReAct combinado com cadeia de pensamento (CoT).
Cadeia de Pensamento
Raciocínio + Ação
[EXAMPLES]
- User Input: What is MongoDB?
- Thought: I have to think step by step. I should not answer directly, let me check my available actions before responding.
- Observation: I have an action available "answer_question".
- Action: "answer_question"('What is MongoDB?')
- User Input: Reset chat history
- Thought: I have to think step by step. I should not answer directly, let me check my available actions before responding.
- Observation: I have an action available "reset_messages".
- Action: "reset_messages"()
- User Input: remove source https://www.google.com, https://www.example.com
- Thought: I have to think step by step. I should not answer directly, let me check my available actions before responding.
- Observation: I have an action available "remove_source".
- Action: "remove_source"(['https://www.google.com', 'https://www.example.com'])
- User Input: read https://www.google.com, https://www.example.com
- Thought: I have to think step by step. I should not answer directly, let me check my available actions before responding.
- Observation: I have an action available "read_url".
- Action: "read_url"(['https://www.google.com','https://www.example.com'])
[END EXAMPLES]
As técnicas de estímulo Chain of Thought (CoT) e ReAct entram em ação nesses exemplos. Veja como:
Solicitação de Cadeia de Pensamento (CoT):
Solicitação de reação:
Em resumo, tanto o CoT como o ReAct desempenham um papel crucial nestes exemplos. O CoT permite que o modelo raciocine passo a passo e escolha as ações apropriadas, enquanto o ReAct estende essa funcionalidade permitindo que o modelo interaja com seu ambiente e atualize seus planos de acordo. Esta combinação de raciocínio e ação torna os grandes modelos de linguagem mais flexíveis e versáteis, permitindo-lhes lidar com uma gama mais ampla de tarefas e situações.
Vamos começar fazendo uma pergunta ao nosso agente. Neste caso, "O que é uma manga?" . A primeira coisa que acontecerá é tentar "recuperar" qualquer informação relevante usando similaridade de incorporação de vetores. Em seguida, ele formulará uma resposta com o conteúdo que “relembrou” ou realizará uma pesquisa na web. Como nossa base de conhecimento está vazia no momento, precisamos adicionar algumas fontes antes que ela possa formular uma resposta.
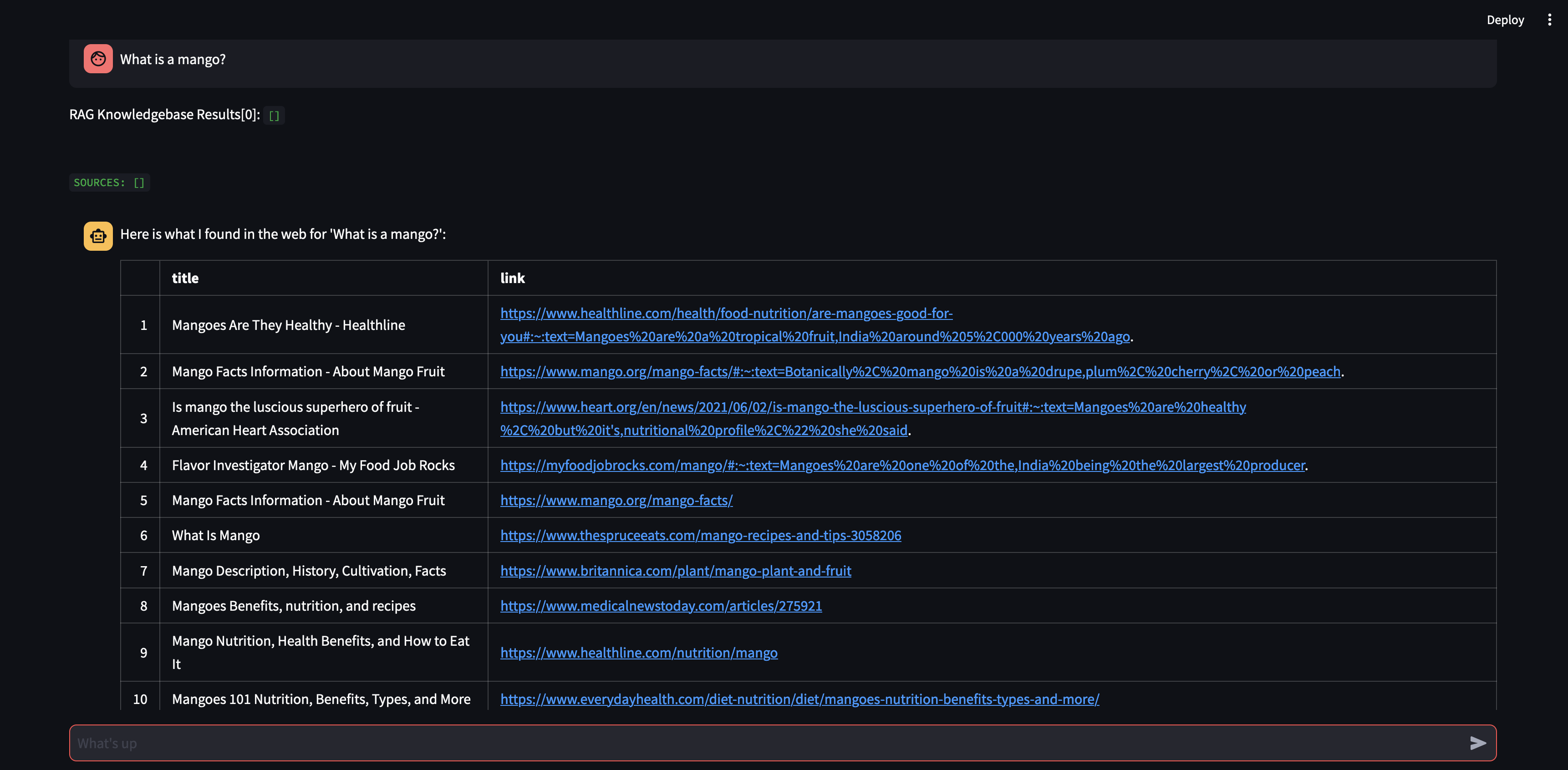
Como o bot não consegue fornecer uma resposta usando o conteúdo do banco de dados de vetores, ele iniciou uma pesquisa no Google para encontrar informações relevantes. Agora podemos dizer quais fontes ele deve “aprender”. Neste caso, diremos para aprender as duas primeiras fontes a partir dos resultados da pesquisa.
A seguir, vamos modificar a estratégia RAG! Vamos fazer com que ele use apenas uma fonte e use um pequeno tamanho de 500 caracteres.
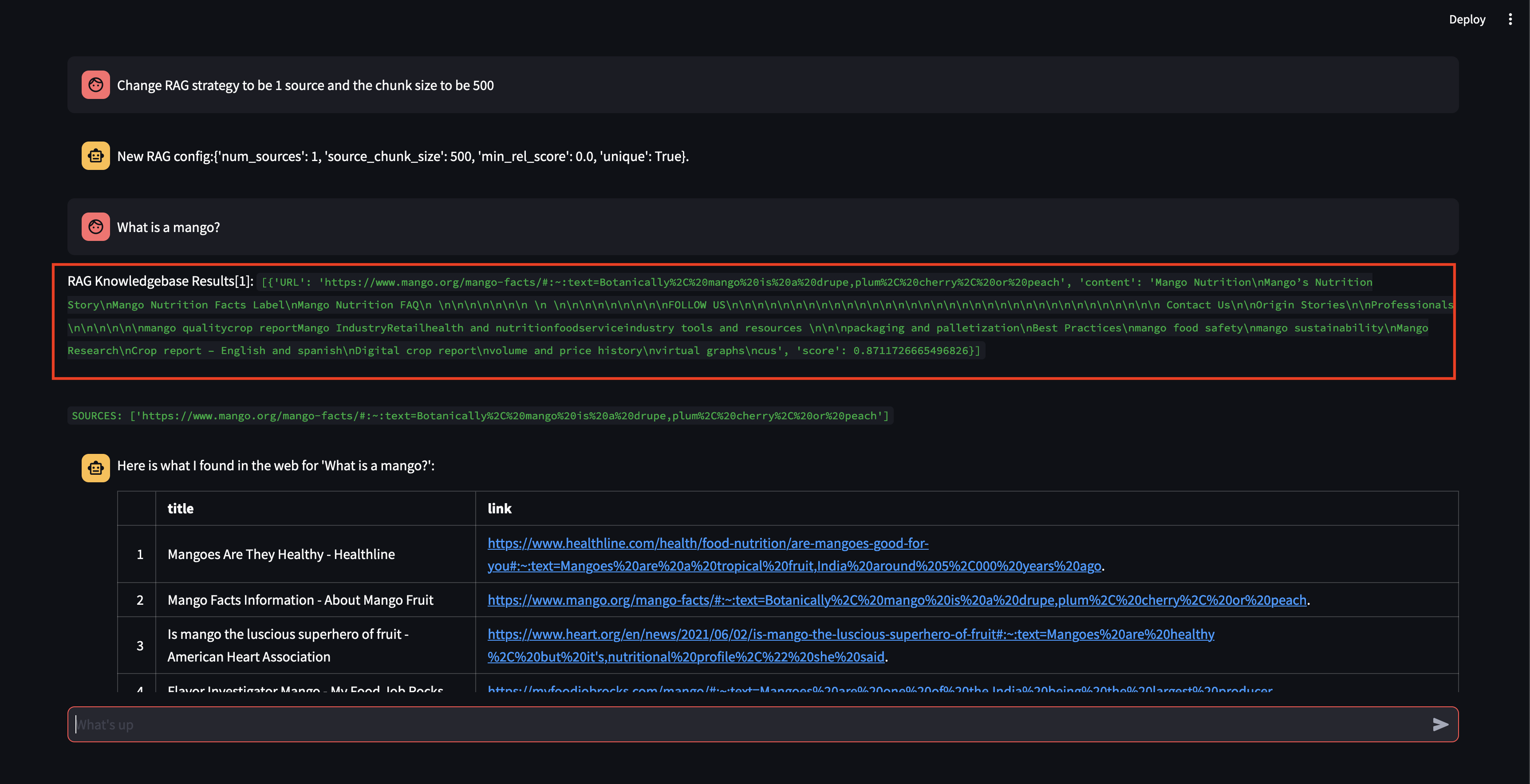
Observe que, embora tenha conseguido recuperar um pedaço com uma pontuação de relevância bastante alta, não foi capaz de gerar uma resposta porque o tamanho do pedaço era muito pequeno e o conteúdo do pedaço não era relevante o suficiente para formular uma resposta. Como não conseguiu gerar uma resposta com o pequeno pedaço, realizou uma pesquisa na web em nome do usuário.
Vamos ver o que acontece se aumentarmos o tamanho do bloco para 3.000 caracteres em vez de 500.
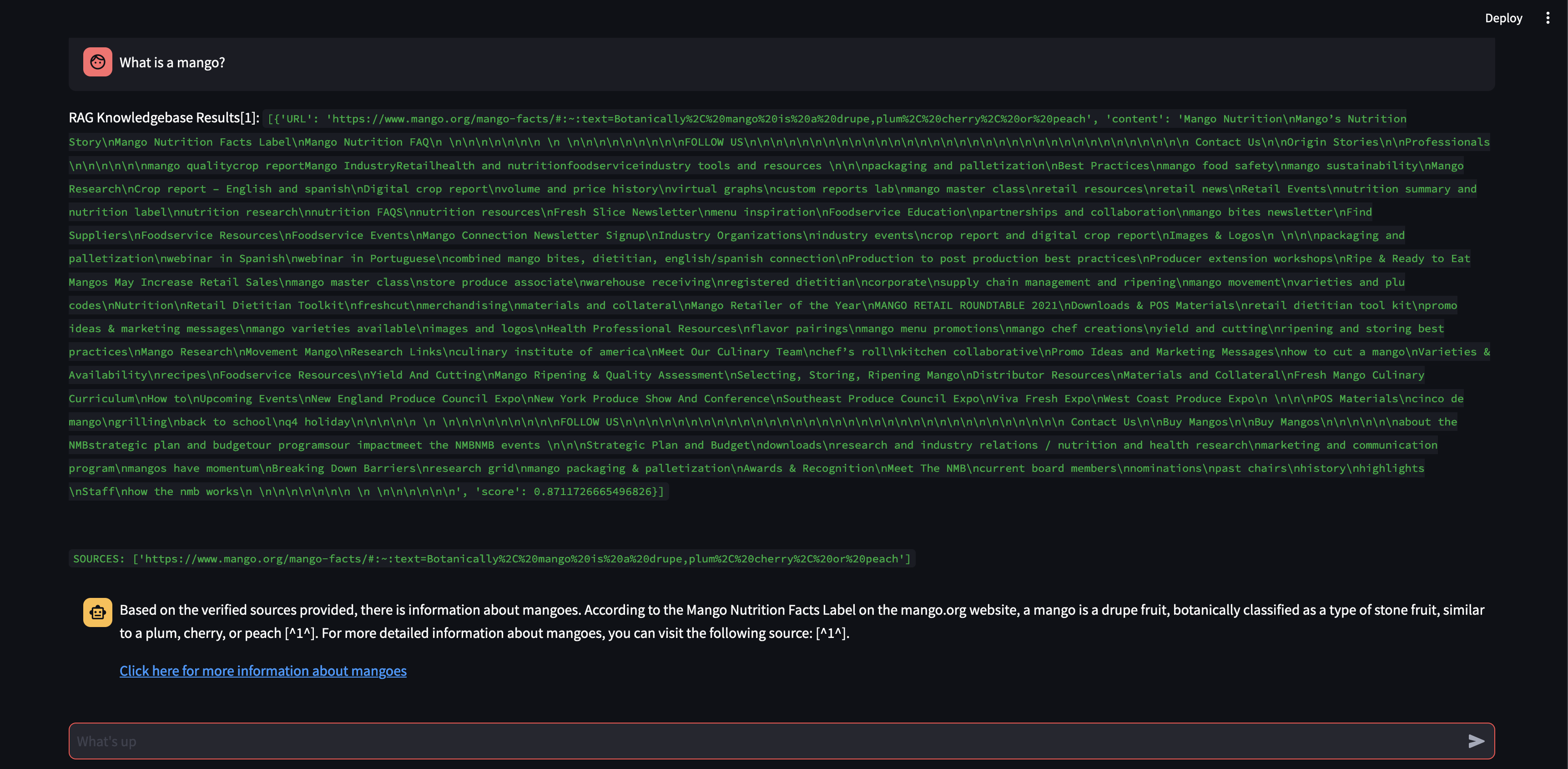
Agora, com um tamanho de bloco maior, foi possível formular a resposta com precisão usando o conhecimento do banco de dados vetorial!
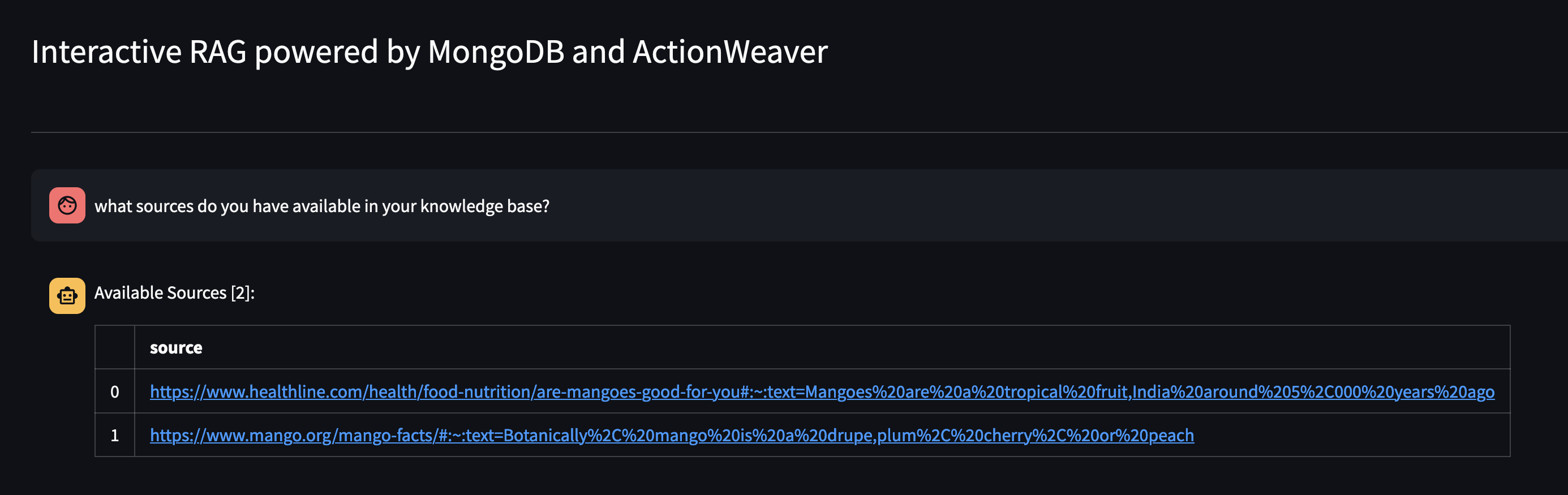
Vamos ver o que está disponível na base de conhecimento do Agente perguntando: Quais fontes você possui em sua base de conhecimento?
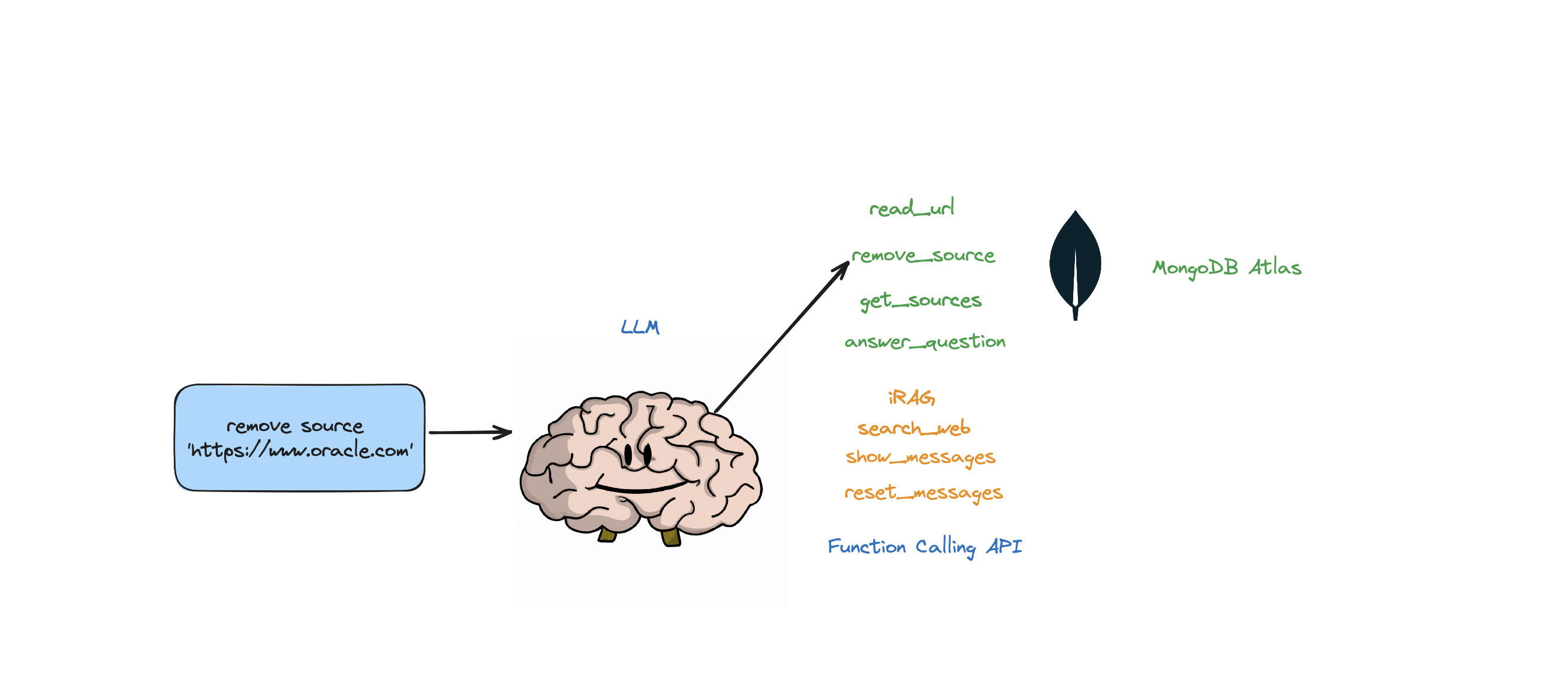
Se quiser remover um recurso específico, você pode fazer algo como:
USER: remove source 'https://www.oracle.com' from the knowledge base
Para remover todas as fontes da coleção – poderíamos fazer algo como:
USER: what sources do you have in your knowledge base?
AGENT: {response}
USER: remove all those sources please
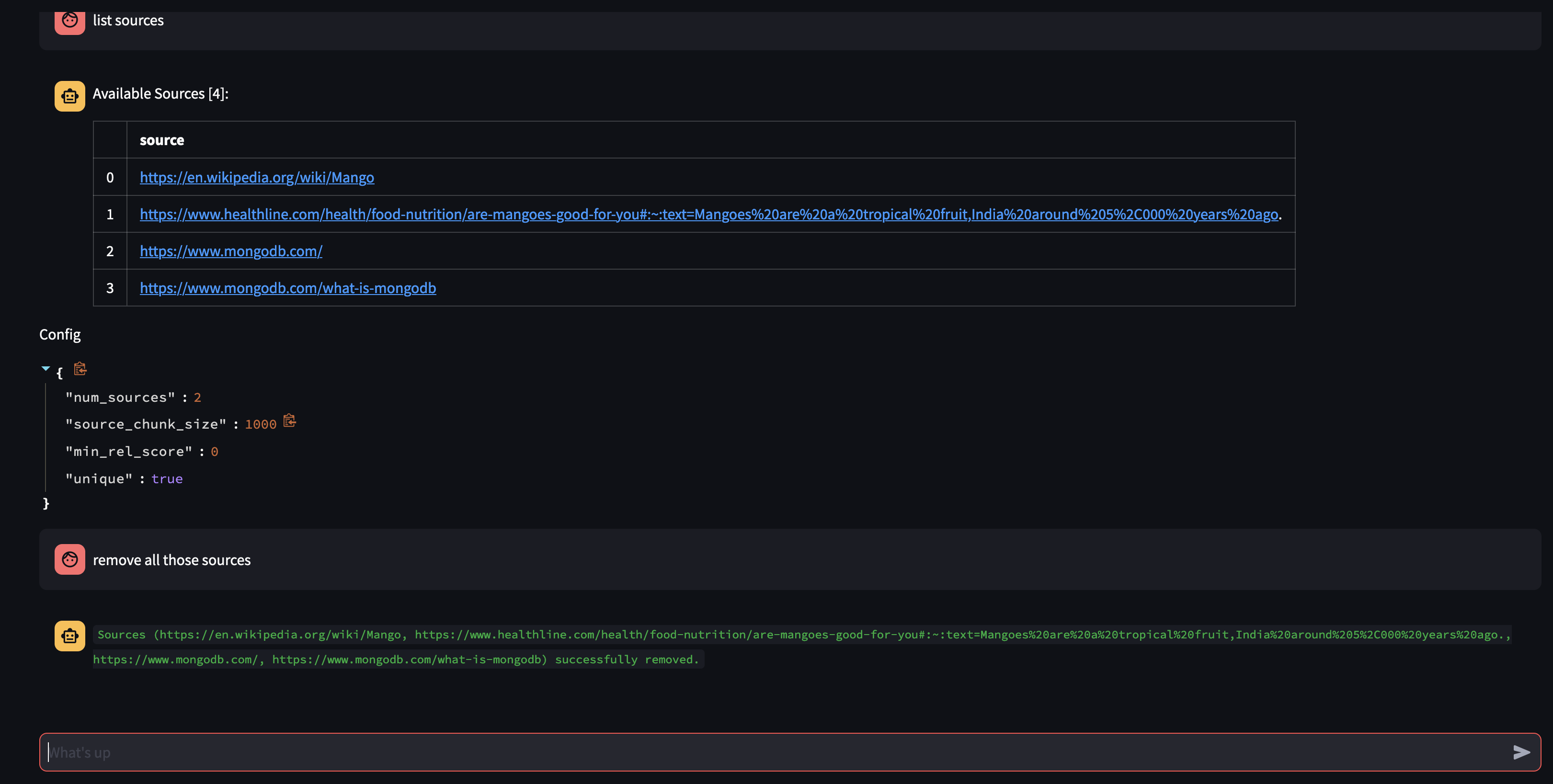
Esta demonstração deu uma ideia do funcionamento interno do nosso agente de IA, mostrando sua capacidade de aprender e responder às dúvidas dos usuários de maneira interativa. Testemunhamos como ela combina perfeitamente sua base de conhecimento interna com pesquisa na Web em tempo real para fornecer informações abrangentes e precisas. O potencial desta tecnologia é vasto, indo muito além da simples resposta a perguntas. Nada disso seria possível sem a magia da API de chamada de função .
Isso foi inspirado em https://github.com/TengHu/Interactive-RAG
Aceitamos contribuições da comunidade de código aberto.
Licença Apache 2.0


