content dicovery platform gcp
1.0.0
Este repositório contém o código e a automação necessários para construir uma plataforma simples de descoberta de conteúdo alimentada por modelos fundamentais da VertexAI. Esta plataforma deverá ser capaz de capturar conteúdo de documentos (inicialmente Google Docs), e com esse conteúdo gerar vetores de embeddings para serem armazenados em um banco de dados de vetores alimentado por VertexAI Matching Engine, posteriormente esses embeddings poderão ser utilizados para contextualizar uma dúvida geral do consumidor externo e com esse contexto solicita uma resposta a um modelo fundamental da VertexAI para obter uma resposta.
A plataforma pode ser separada em 4 componentes principais: camada de serviço de acesso, pipeline de captura de conteúdo, armazenamento de conteúdo e LLMs. A camada de serviços permite que consumidores externos enviem solicitações de ingestão de documentos e posteriormente enviem consultas sobre o conteúdo incluído nos documentos previamente ingeridos. O pipeline de captura de conteúdo é responsável por capturar o conteúdo do documento em NRT, extrair embeddings e mapear esses embeddings com conteúdo real que pode posteriormente ser usado para contextualizar as dúvidas dos usuários externos para um LLM. O armazenamento de conteúdo é separado em 3 finalidades distintas, ajuste fino LLM, correspondência de embeddings online e conteúdo fragmentado, cada uma delas gerenciada por um sistema de armazenamento especializado e com o objetivo geral de armazenar as informações necessárias aos componentes da plataforma para implementar a ingestão e consulta usa casos. Por último, mas não menos importante, a plataforma dispõe de 2 LLMs especializados para criar embeddings em tempo real a partir do conteúdo do documento ingerido e outro encarregado de gerar as respostas solicitadas pelos usuários da plataforma.
Todos os componentes descritos anteriormente são implementados usando serviços GCP disponíveis publicamente. Para enumerá-los: Cloud Build, Cloud Run, Cloud Dataflow, Cloud Pubsub, Cloud Storage, Cloud Bigtable, Vertex AI Matching Engine, Vertex AI Fundational models (embeddings e text-bison), juntamente com Google Docs e Google Drive como informações de conteúdo fontes.
A próxima imagem mostra como os diferentes componentes da arquitetura e das tecnologias interagem entre si.
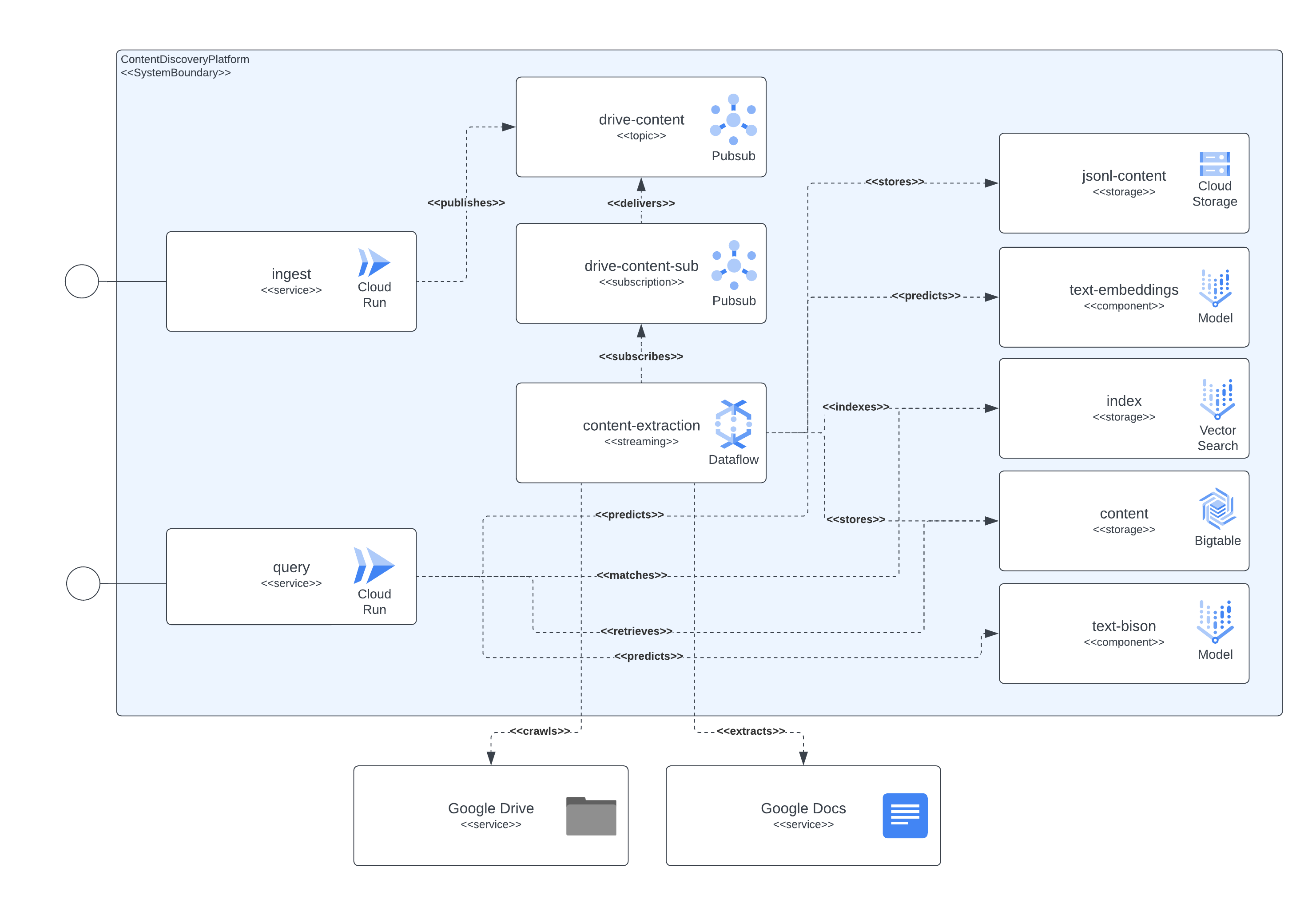
Esta plataforma utiliza Terraform para a configuração de todos os seus componentes. Para aqueles que atualmente não têm suporte nativo, criamos wrappers null_resource, que são boas soluções alternativas, mas tendem a ter arestas muito ásperas, portanto, esteja ciente de possíveis erros.
A implantação completa a partir de hoje (junho de 2023) pode levar até 90 minutos para ser concluída, sendo o maior culpado os componentes relacionados ao Matching Engine, que levam a maior parte desse tempo para serem criados e ficarem prontamente disponíveis. Com o tempo, esses tempos de execução estendidos só irão melhorar.
A configuração deve ser executável a partir dos scripts incluídos no repositório.
Existem alguns requisitos que precisam ser cumpridos para implantar esta plataforma, sendo estes:
Para ter todos os componentes implantados no GCP precisamos construir, criar infraestrutura e posteriormente implantar os serviços e pipelines.
Para conseguir isso, incluímos o script start.sh que basicamente orquestra os outros scripts incluídos para atingir o objetivo de implantação completo.
Também incluímos um script cleanup.sh encarregado de destruir a infraestrutura e limpar os dados coletados.
Em casos normais, os documentos do Google Workspace serão criados na mesma organização que hospeda o projeto onde o pipeline de ingestão de conteúdo é executado, portanto, para conceder permissões a esses documentos, adicione a conta de serviço que executa o pipeline aos documentos ou pasta de documentos , deve ser suficiente.
Caso seja necessário acessar documentos ou pastas existentes fora da organização do projeto, uma etapa adicional deverá ser concluída. Depois que a infraestrutura estiver configurada, o processo de implantação imprimirá instruções para conceder à conta de serviço que executa o pipeline de extração de conteúdo permissões para representar o acesso a documentos do Google Workspace por meio da delegação em todo o domínio. As informações para concluir as etapas podem ser vistas aqui: https://developers.google.com/workspace/guides/create-credentials#optional_set_up_domain-wide_delegation_for_a_service_account
A solução expõe alguns recursos por meio do GCP CloudRun e do API Gateway, que podem ser usados para interagir para ingestão de conteúdo e consultas de descoberta de conteúdo. Em todos os exemplos, usamos a string simbólica <service-address> , que deve ser substituída pela URL fornecida pelo CloudRun ( backend_service_url da saída do Terraform) ou API Gateway ( sevice_url da saída do Terraform) após a conclusão da implantação do serviço.
Ao precisar de interações CORS, os endpoints do API Gateway podem ser usados ao tentar concluir um protocolo de simulação. Atualmente, o CloudRun não oferece suporte a comandos OPTIONS não autenticados, mas os caminhos expostos por meio do API Gateway oferecem suporte a eles.
Este serviço é capaz de ingerir dados de documentos hospedados no Google Drive ou de solicitações independentes de várias partes que contêm um identificador de documento e o conteúdo do documento codificado como binário.
A ingestão do Google Drive é feita enviando uma solicitação HTTP semelhante ao próximo exemplo
$ > curl -X POST -H " Content-Type: application/json "
-H " Authorization: Bearer $( gcloud auth print-identity-token ) "
https:// < service-address > /ingest/content/gdrive
-d $' {"url":"https://docs.google.com/document/d/somevalid-googledocid"} ' Esta solicitação indicará a plataforma para obter o documento da url fornecida e caso a conta de serviço que executa a ingestão tenha permissões de acesso ao documento, extrairá o conteúdo dele e armazenará as informações para indexação, posterior descoberta e recuperação.
A solicitação pode conter o URL de um documento do Google ou de uma pasta do Google Drive. No último caso, a ingestão rastreará a pasta para que os documentos sejam processados. Além disso, é possível usar os urls de propriedade que esperam um JSONArray de valores string , cada um deles um URL válido do Documento do Google.
No caso de querer incluir o conteúdo de um artigo, documento ou página que seja acessível localmente pelo cliente de ingestão, a utilização do ponto final multipart deve ser suficiente para ingerir o documento. Veja o próximo comando curl como exemplo, o serviço espera que o campo do formulário documentId seja definido para identificar e indexar univocamente o conteúdo:
$ > curl -H " Authorization: Bearer $( gcloud auth print-identity-token ) "
-F documentId= < somedocid >
-F documentContent=@ < /some/local/directory/file/to/upload >
https:// < service-address > /ingest/content/multipartEste serviço expõe a capacidade de consulta aos usuários da plataforma, enviando consultas de texto natural aos serviços e dado que já existem índices de conteúdo após a ingestão na plataforma, o serviço retornará com informações resumidas através do modelo LLM.
A interação com o serviço pode ser feita através de uma troca REST, semelhante à da parte de ingestão, como visto no próximo exemplo.
$ > curl -X POST
-H " Content-Type: application/json "
-H " Authorization: Bearer $( gcloud auth print-identity-token ) "
https:// < service-address > /query/content
-d $' {"text":"summarize the benefits of using VertexAI foundational models for Generative AI applications?", "sessionId": ""} '
| jq .
# response from service
{
"content": "VertexAI foundational models are a set of pre-trained models that can be used to build and deploy machine learning applications. They are available in a variety of languages and frameworks, and can be used for a variety of tasks, including natural language processing, computer vision, and recommendation systems.nnVertexAI foundational models are a good choice for Generative AI applications because they provide a starting point for building these types of applications. They can be used to quickly and easily create models that can generate text, images, and other types of content.nnIn addition, VertexAI foundational models are scalable and can be used to process large amounts of data. They are also reliable and can be used to create applications that are available 24/7.nnOverall, VertexAI foundational models are a powerful tool for building Generative AI applications. They provide a starting point for building these types of applications, and they can be used to quickly and easily create models that can generate text, images, and other types of content.",
" sourceLinks " : [
]
}Há um caso especial aqui, onde ainda não há informações armazenadas para um determinado tópico. Se esse tópico se enquadrar no cenário do GCP, o modelo estará agindo como um especialista, pois configuramos um prompt que indica isso para a solicitação do modelo.
Caso queira ter um tipo de troca mais contextual com o serviço, um identificador de sessão (propriedade sessionId na solicitação JSON) deve ser fornecido para o serviço usar como chave de troca de conversa. Esta chave de conversação será usada para configurar o contexto correto para o modelo (resumindo as trocas anteriores) e acompanhar as últimas 5 trocas (pelo menos). Vale ressaltar também que o histórico de exchange será mantido por 24 horas, podendo ser alterado conforme políticas de GC do armazenamento BigTable na plataforma.
A seguir, um exemplo de uma conversa sensível ao contexto:
$ > curl -X POST
-H " Content-Type: application/json "
-H " Authorization: Bearer $( gcloud auth print-identity-token ) "
https:// < service-address > /query/content
-d $' {"text":"summarize the benefits of using VertexAI foundational models for Generative AI applications?", "sessionId": "some-session-id"} '
| jq .
# response from service
{
" content " : " VertexAI Foundational Models are a suite of pre-trained models that can be used to accelerate the development of Generative AI applications. These models are available in a variety of languages and domains, and they can be used to generate text, images, audio, and other types of content.nnUsing VertexAI Foundational Models can help you to:nn* Reduce the time and effort required to develop Generative AI applicationsn* Improve the accuracy and quality of your modelsn* Access the latest research and development in Generative AInnVertexAI Foundational Models are a powerful tool for developers who want to create innovative and engaging Generative AI applications. " ,
" sourceLinks " : [
]
}
$ > curl -X POST
-H " Content-Type: application/json "
-H " Authorization: Bearer $( gcloud auth print-identity-token ) "
https:// < service-address > /query/content
-d $' {"text":"describe the available LLM models?", "sessionId": "some-session-id"} '
| jq .
# response from service
{
" content " : " The VertexAI Foundational Models suite includes a variety of LLM models, including:nn* Text-to-text LLMs: These models can generate text based on a given prompt. They can be used for tasks such as summarization, translation, and question answering.n* Image-to-text LLMs: These models can generate text based on an image. They can be used for tasks such as image captioning and description generation.n* Audio-to-text LLMs: These models can generate text based on an audio clip. They can be used for tasks such as speech recognition and transcription.nnThese models are available in a variety of languages, including English, Spanish, French, German, and Japanese. They can be used to create a wide range of Generative AI applications, such as chatbots, customer service applications, and creative writing tools. " ,
" sourceLinks " : [
]
}
$ > curl -X POST
-H " Content-Type: application/json "
-H " Authorization: Bearer $( gcloud auth print-identity-token ) "
https:// < service-address > /query/content
-d $' {"text":"do rate limit apply for those LLMs?", "sessionId": "some-session-id"} '
| jq .
# response from service
{
" content " : " Yes, there are rate limits for the VertexAI Foundational Models. The rate limits are based on the number of requests per second and the total number of requests per day. For more information, please see the [VertexAI Foundational Models documentation](https://cloud.google.com/vertex-ai/docs/foundational-models#rate-limits). " ,
" sourceLinks " : [
]
}
$ > curl -X POST
-H " Content-Type: application/json "
-H " Authorization: Bearer $( gcloud auth print-identity-token ) "
https:// < service-address > /query/content
-d $' {"text":"care to share the price?", "sessionId": "some-session-id"} '
| jq .
# response from service
{
" content " : " The VertexAI Foundational Models are priced based on the number of requests per second and the total number of requests per day. For more information, please see the [VertexAI Foundational Models pricing page](https://cloud.google.com/vertex-ai/pricing#foundational-models). " ,
" sourceLinks " : [
]
}

