BigBertha
skeletal-integrations

BigBertha é um projeto de arquitetura que demonstra como LLMOps (Large Language Models Operations) automatizados podem ser alcançados em qualquer cluster Kubernetes usando tecnologias nativas de contêiner de código aberto?
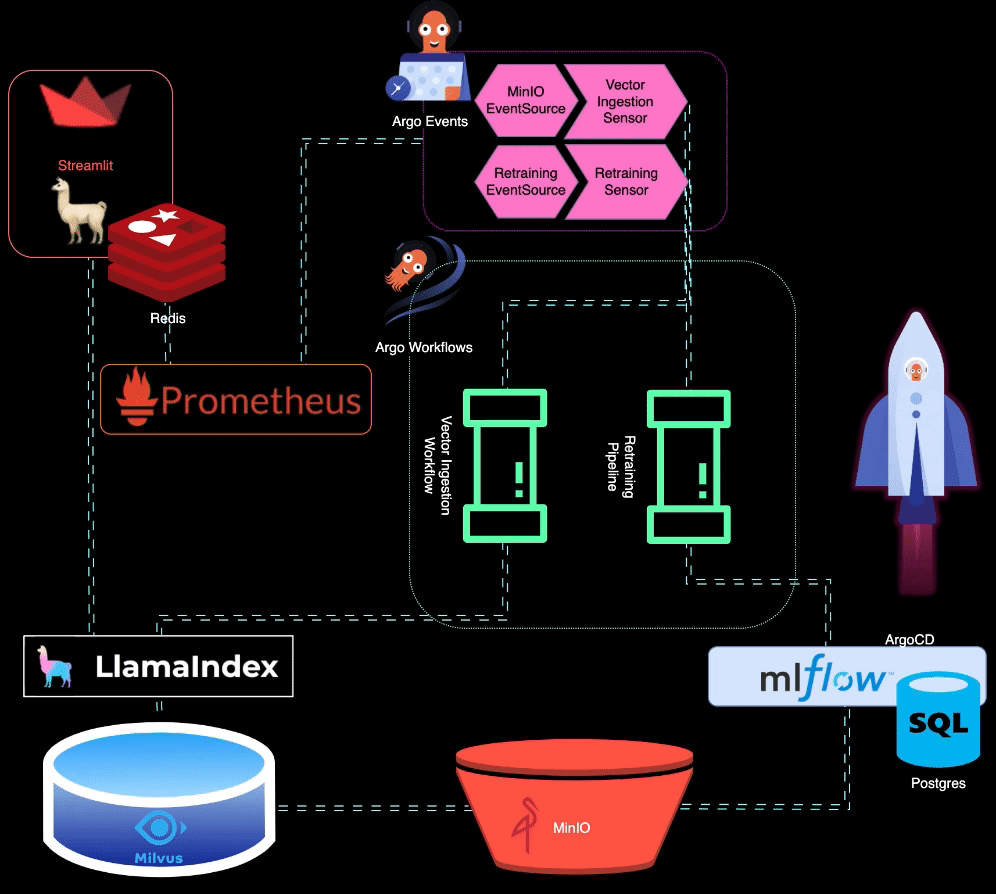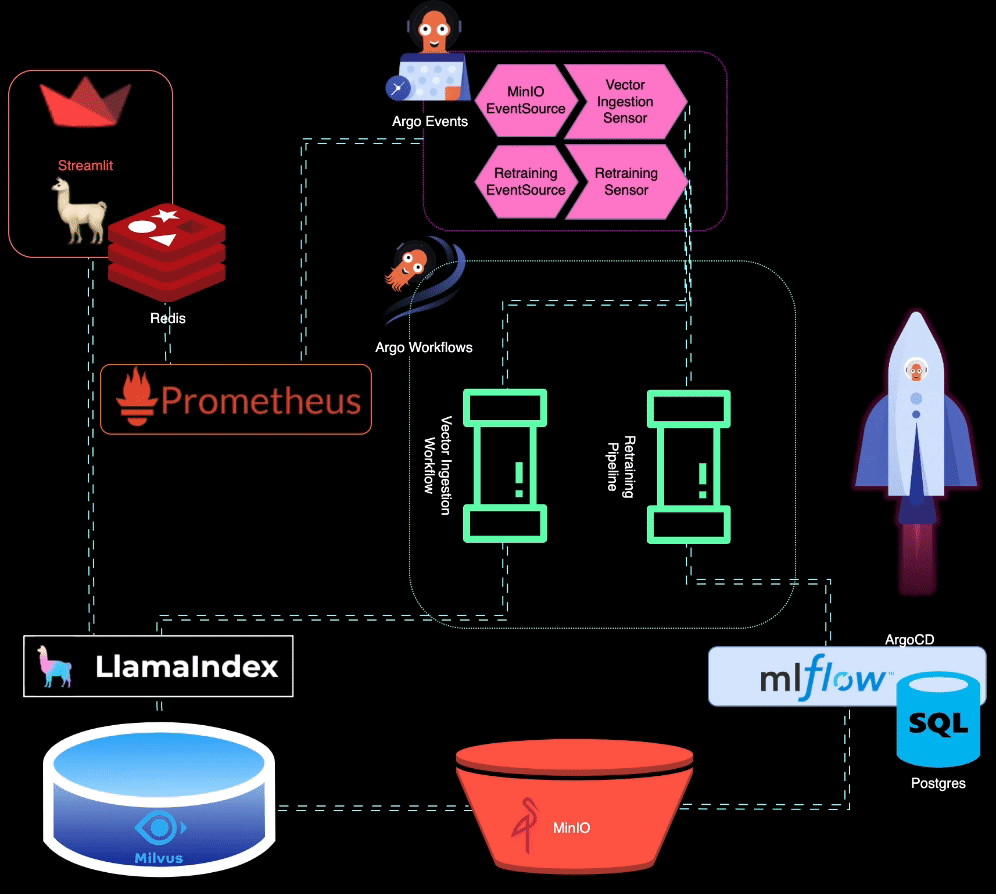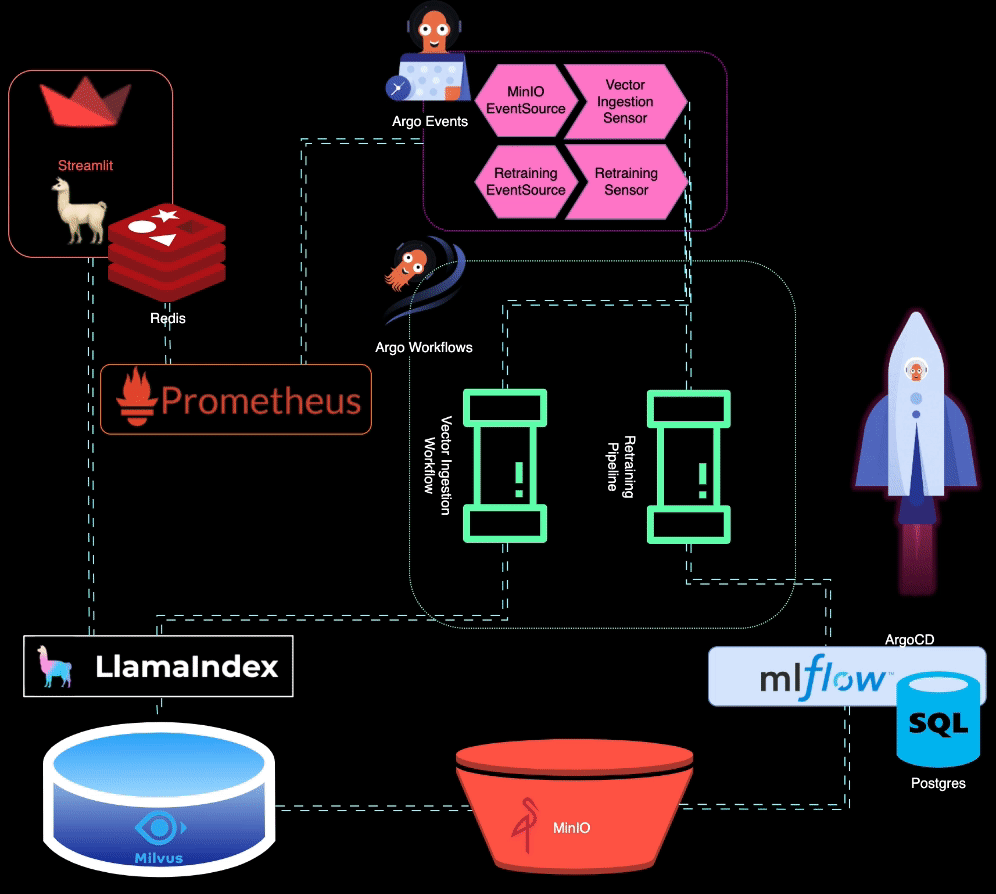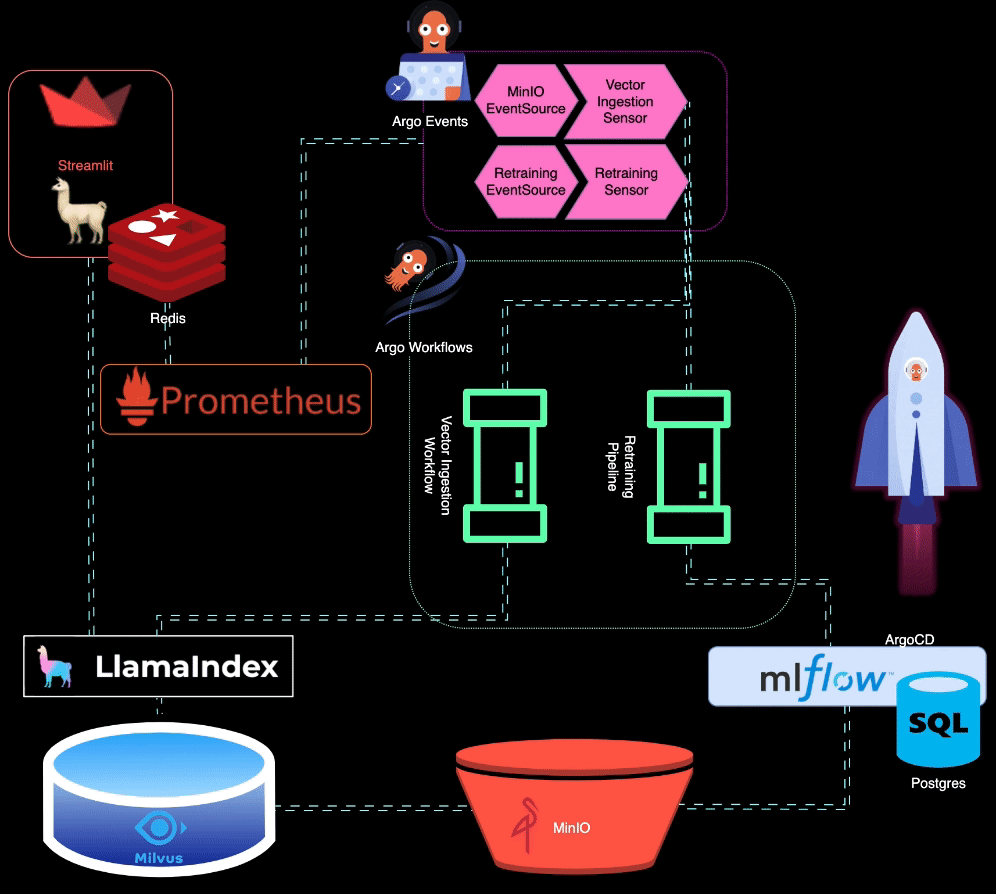
? BigBertha utiliza Prometheus para monitorar módulos de serviço LLM (Large Language Model). Para fins de demonstração, um aplicativo Streamlit é usado para servir o LLM, e o Prometheus extrai métricas dele. Alertas são configurados para detectar degradação de desempenho.
O Prometheus aciona alertas quando o desempenho do modelo diminui. Esses alertas são gerenciados pelo AlertManager, que usa Argo Events para acionar um pipeline de retreinamento para ajustar o modelo.
?️ O pipeline de retreinamento é orquestrado usando Argo Workflows. Esse pipeline pode ser adaptado para realizar retreinamento, ajuste fino e rastreamento de métricas específicos do LLM. MLflow é usado para registrar o LLM retreinado.
MinIO é usado para armazenamento de dados não estruturados. O Argo Events está configurado para escutar eventos de upload no MinIO, acionando um fluxo de trabalho de ingestão de vetores quando novos dados são carregados.
? Argo Workflows é usado para executar um pipeline de ingestão de vetores que utiliza LlamaIndex para gerar e ingerir vetores. Esses vetores são armazenados no Milvus, que serve como base de conhecimento para geração de recuperação aumentada.
BigBertha depende de vários componentes principais:
ArgoCD: uma ferramenta de entrega contínua nativa do Kubernetes que gerencia todos os componentes da pilha BigBertha.
Fluxos de trabalho Argo: um mecanismo de fluxo de trabalho nativo do Kubernetes usado para executar ingestão de vetores e pipelines de retreinamento de modelo.
Argo Events: Um gerenciador de dependência baseado em eventos nativo do Kubernetes que conecta vários aplicativos e componentes, acionando fluxos de trabalho baseados em eventos.
Prometheus + AlertManager: Usado para monitoramento e alertas relacionados ao desempenho do modelo.
LlamaIndex: Uma estrutura para conectar LLMs e fontes de dados, usada para ingestão e indexação de dados.
Milvus: um banco de dados de vetores nativo do Kubernetes para armazenar e consultar vetores.
MinIO: Um sistema de armazenamento de objetos de código aberto usado para armazenar dados não estruturados.
MLflow: uma plataforma de código aberto para gerenciar o ciclo de vida do aprendizado de máquina, incluindo rastreamento de experimentos e gerenciamento de modelos.
Kubernetes: a plataforma de orquestração de contêineres que automatiza a implantação, o dimensionamento e o gerenciamento de aplicativos em contêineres.
Contêineres Docker: os contêineres Docker são usados para empacotar e executar aplicativos de maneira consistente e reproduzível.
Como demonstração, BigBertha inclui um chatbot baseado em Streamlit que atende um modelo de chatbot quantizado Llama2 7B. Um aplicativo Flask simples é usado para expor métricas, e o Redis atua como intermediário entre os processos Streamlit e Flask.
Este projeto é de código aberto e é regido pelos termos e condições descritos no arquivo LICENSE incluído neste repositório.


