genai knowledge capture
1.0.0
Esta solução de prova de conceito explica uma solução potencial que pode ser usada para capturar o conhecimento tribal através de gravações de voz de funcionários seniores de uma empresa. Ele descreve metodologias para usar o serviço Amazon Transcribe e Amazon Bedrock para a documentação sistemática e verificação dos dados de entrada. Ao fornecer uma estrutura para a formalização deste conhecimento informal, a solução garante a sua longevidade e aplicabilidade a grupos subsequentes de colaboradores numa organização. Este esforço não só garante a manutenção sustentada da excelência operacional, mas também melhora a eficácia dos programas de formação através da incorporação de conhecimentos práticos adquiridos através da experiência direta.
Este aplicativo de demonstração é uma prova de conceito para um aplicativo de geração de documentos usando o Amazon Transcribe e o Amazon Bedrock.
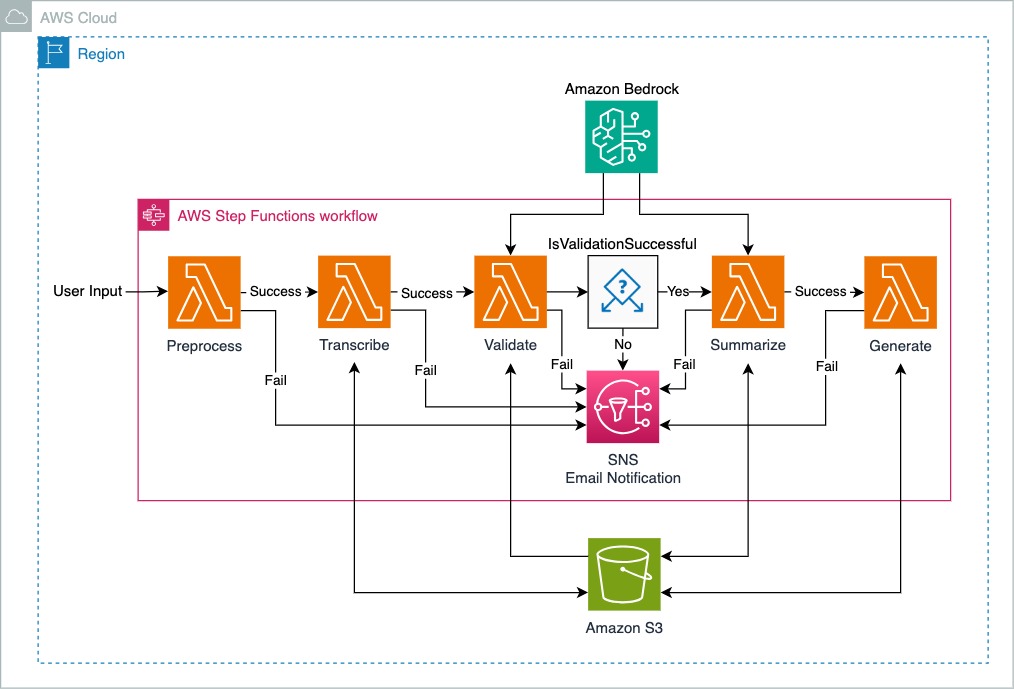
O diagrama descreve uma arquitetura de solução para um fluxo de trabalho orquestrado pelo AWS Step Functions em uma região da Nuvem AWS. O fluxo de trabalho consiste em várias etapas projetadas para processar a entrada do usuário, com mecanismos para tratamento de sucesso e falha em cada etapa. Abaixo está uma descrição do fluxo do processo:
Entrada do usuário : o fluxo de trabalho é iniciado com a entrada do usuário para acionar a função Lambda preprocess .
Pré-processamento : a entrada é primeiro pré-processada. Se for bem-sucedido, ele passa para a etapa transcribe ; se falhar, aciona o Amazon SNS para enviar notificações.
Transcrever : esta etapa obtém a saída da etapa anterior. Uma transcrição bem-sucedida segue para a etapa Validar, e as saídas da transcrição são armazenadas no bucket do Amazon S3.
Validar : Os dados transcritos são validados. Com base no resultado da validação, o fluxo de trabalho diverge:
Resumir : pós-validação, se os dados forem resumidos com sucesso, o texto resumido será armazenado no bucket do Amazon S3. Se falhar, aciona o Amazon SNS para enviar notificações.
Amazon Bedrock é o serviço principal que oferece suporte às funções Validate e Summarize Lambda.
Gerar : Esta etapa final gera o documento final a partir do texto resumido. Caso falhe, ele aciona o Amazon SNS para enviar notificações.
Cada etapa do processo é marcada com caminhos de "Sucesso" ou "Falha", indicando a capacidade do fluxo de trabalho de lidar com erros em vários estágios. Em caso de falha, o Amazon SNS é usado para enviar notificações ao usuário.
O fluxo de trabalho do AWS Step Functions opera como um orquestrador central, garantindo que cada tarefa seja executada na ordem correta e lidando adequadamente com o sucesso ou a falha de cada etapa.
O arquivo cdk.json informa ao CDK Toolkit como executar seu aplicativo.
Este projeto é configurado como um projeto Python padrão. O processo de inicialização também cria um virtualenv dentro deste projeto, armazenado no diretório .venv . Para criar o virtualenv ele assume que existe um executável python3 (ou python para Windows) em seu caminho com acesso ao pacote venv . Se por algum motivo a criação automática do virtualenv falhar, você poderá criar o virtualenv manualmente.
Para criar manualmente um virtualenv no MacOS e Linux:
$ python3 -m venv .venvApós a conclusão do processo init e a criação do virtualenv, você pode usar a etapa a seguir para ativar seu virtualenv.
$ source .venv/bin/activateSe você for uma plataforma Windows, você ativaria o virtualenv assim:
% .venvScripts activate.batAssim que o virtualenv for ativado, você poderá instalar as dependências necessárias.
$ pip install -r requirements.txt Para adicionar dependências adicionais, por exemplo, outras bibliotecas CDK, basta adicioná-las ao arquivo setup.py e executar novamente o comando pip install -r requirements.txt .
Neste ponto, você pode sintetizar o modelo CloudFormation para este código.
$ cdk synth Para adicionar dependências adicionais, por exemplo, outras bibliotecas CDK, basta adicioná-las ao arquivo setup.py e executar novamente o comando pip install -r requirements.txt .
Você precisará inicializá-lo se for a primeira vez que executa o cdk em uma conta e região específicas.
$ cdk bootstrap
Depois de inicializado, você pode prosseguir com a implantação do cdk.
$ cdk deploy
Se esta for a primeira vez que você o implanta, o processo pode levar aproximadamente de 30 a 45 minutos para criar várias imagens Docker no ECS (Amazon Elastic Container Service). Por favor, seja paciente até que seja concluído. Depois disso, ele começará a implantar a pilha docgen, o que normalmente leva de 5 a 8 minutos.
Assim que o processo de implantação for concluído, você verá a saída do cdk no terminal e também poderá verificar o status no console do CloudFormation.
Para excluir o cdk depois de terminar de usá-lo para evitar custos futuros, você pode excluí-lo através do console ou executar o seguinte comando no terminal.
$ cdk destroyTambém pode ser necessário excluir manualmente o bucket S3 gerado pelo cdk. Certifique-se de excluir todos os recursos gerados para evitar incorrer em custos.
cdk ls lista todas as pilhas no aplicativocdk synth emite o modelo CloudFormation sintetizadocdk deploy implanta esta pilha em sua conta/região padrão da AWScdk diff compara a pilha implantada com o estado atualcdk docs abre documentação do CDKcdk destroy dstroys uma ou mais pilhas especificadas code # Root folder for code for this solution
├── lambdas # Root folder for all lambda functions
│ ├── preprocess # Lambda function that processes user input, and outputs audio files uris for Amazon Transcribe
│ ├── transcribe # Lambda function that triggers Amazon Transcribe batch transcription
│ ├── validate # Lambda function that analyzes answers from Amazon Transcribe using LLMs from Amazon Bedrock
│ ├── summarize # Lambda function that summarizes on-topic texts from Amazon Transcribe using LLMs from Amazon Bedrock
│ └── generate # Lambda function that generates documents from the summary.
└── code_stack.py # Amazon CDK stack that deploys all AWS resources
Para adaptar o aplicativo DocGen para incorporar seus próprios dados, as etapas subsequentes devem ser seguidas:
Após a implantação, a infraestrutura AWS CDK facilitará a transferência automática de arquivos de áudio para o bucket Amazon S3 designado. Posteriormente, a execução da AWS Step Function pode ser iniciada para iniciar a fase de processamento.
Depois que a solução for implantada, você poderá assinar seu e-mail no tópico SNS para receber notificações.
Por favor, siga as notificações por e-mail do SNS.
Se alguma etapa do fluxo de trabalho StepFunction falhar, você receberá uma notificação por e-mail.
Após a implantação, você pode acionar a máquina de estado da AWS implantada usando o seguinte comando:
aws stepfunctions start-execution
--state-machine-arn "arn:aws:states:<your aws region>:<your account id>:stateMachine:genai-knowledge-capture-stack-state-machine"
--input "{"documentName": "<your document name>", "audioFileFolderUri": "s3://<your s3 bucket>/assets/audio_samples/what is amazon bedrock/"}"
Consulte CONTRIBUINDO para obter mais informações.
Esta biblioteca está licenciada sob a licença MIT-0. Veja o arquivo LICENÇA.


