php rag
v1.1.0
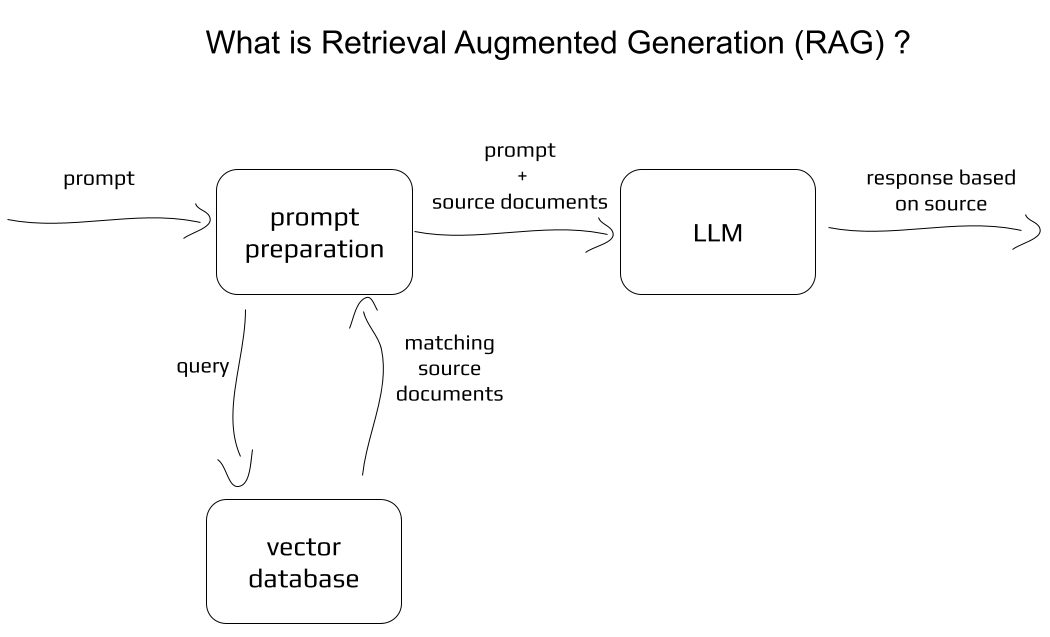
Este aplicativo usa LLM (Large Language Model) GPT-4o acessado via API OpenAI para gerar texto com base na entrada do usuário. A entrada do usuário é usada para recuperar informações relevantes do banco de dados e, em seguida, as informações recuperadas são usadas para gerar o texto. Esta abordagem combina o poder dos transformadores e o acesso aos documentos de origem.
Nesta aplicação específica, o banco de dados de mais de 1000 sites é pesquisado em busca de informações relacionadas a uma pessoa específica. O verdadeiro desafio aqui é que a pessoa pesquisada "Michał Żarnecki" aparece em 2 contextos diferentes como 2 pessoas diferentes com o mesmo nome. O objetivo é não apenas encontrar informações específicas, mas também compreender o contexto e evitar erros como misturar informações sobre duas pessoas diferentes com o mesmo nome.
Descrevi os conceitos usados nesta aplicação com mais detalhes no artigo em medium.com https://medium.com/@michalzarnecki88/a-guide-to-using-llm-retrieval-augmented-generation-with-php-3bff25ce6616
Para configuração, você precisa primeiro ter instalado o Docker e o Docker Compose https://docs.docker.com/compose/install/
Execute na CLI: cd app/src && composer install
Modelo de idioma de configuração - escolha uma das opções abaixo:opção com API OpenAI
"A" com modelo livre via ollama API3 local
"B" com API OpenAI
A opção B é mais simples e requer menos recursos de CPU e RAM, mas você precisa da chave de API OpenAI https://platform.openai.com/settings/profile?tab=api-keys A opção A requer mais recursos de CPU e RAM, mas você pode executar localmente usando a API ollama. Para esta opção é bom ter GPU.
Siga as instruções para a opção preferida A ou B abaixo:
Se você deseja configurar o ollama localmente, use as instruções na parte inferior deste arquivo, mas no caso de usar o docker não será necessário.
*Ollama fornece API local servindo LLMs: "Comece a usar grandes modelos de linguagem." https://ollama.com/
docker-compose up
*DICA: O script precisa primeiro transformar os documentos de origem, o que pode levar até 30 minutos. Se você quiser economizar algum tempo, basta remover parte dos documentos de app/src/documents.
Aguarde até que a configuração dos contêineres termine. Você verá nos logs do console:
php-app | Loaded documents complete
php-app | Postgres is ready - executing command
php-app | [Sat Nov 02 11:32:28.365214 2024] [core:notice] [pid 1:tid 1] AH00094: Command line: 'apache2 -D FOREGROUND'
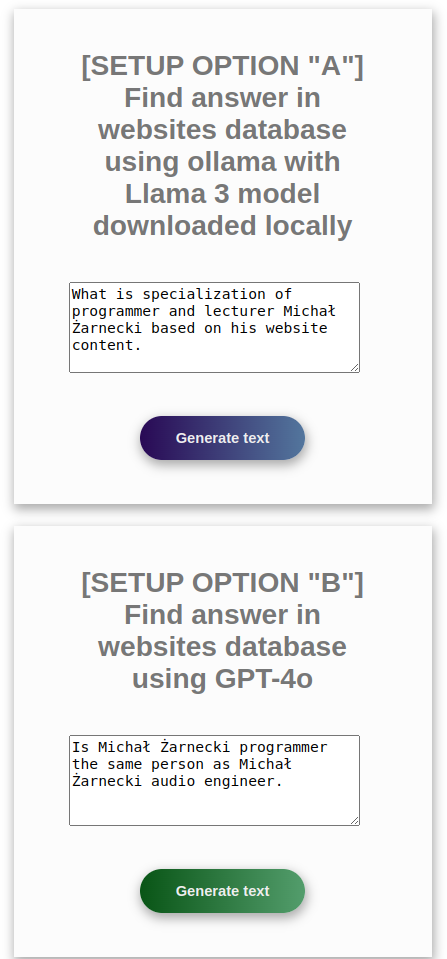
Você pode usar o aplicativo como API usando as solicitações abaixo:
Opção A ollama:
curl -d '{"prompt":"what is result of 2+2?"}' -H "Content-Type: application/json" -X POST http://127.0.0.1:2037/processOllama.php?api
Opção B OpenAI GPT:
curl -d '{"prompt":"what is result of 2+2?"}' -H "Content-Type: application/json" -X POST http://127.0.0.1:2037/processGpt.php?api
Execute docker interativo docker exec -it php-app sh
Execute na CLI: php minicli rag
Faça uma pergunta
##### INPUT:
What is the result of 2 + 2?
##### RESPONSE:
The result of 2 + 2 is 4.
##### INPUT:
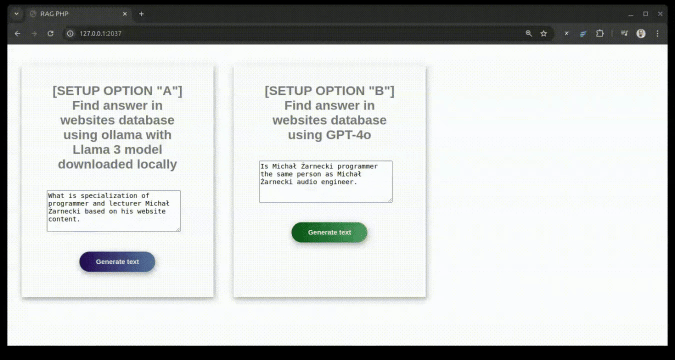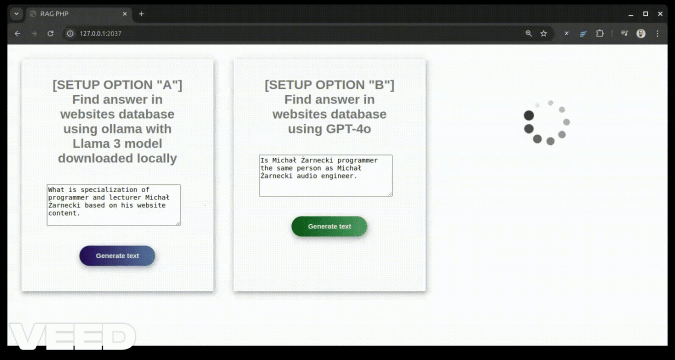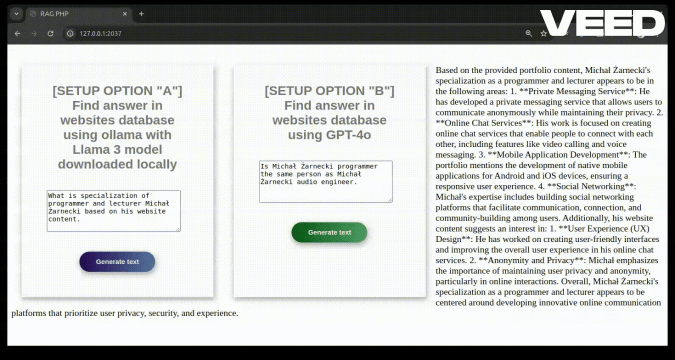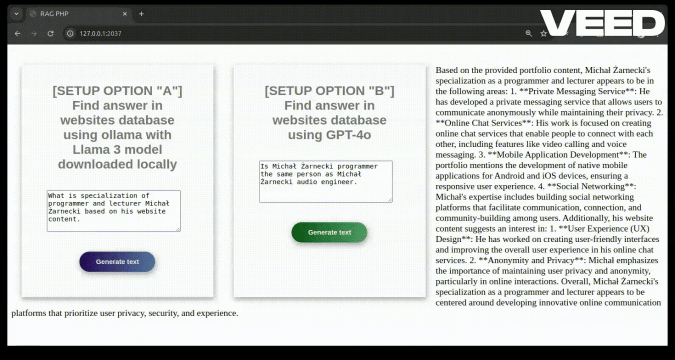
what is specialization of Michał Żarnecki based on his website content
##### RESPONSE:
Michał Żarnecki is a programmer and lecturer specializing in several key areas related to modern software development and data-driven technologies.
His expertise includes:
1. **Programming Languages**: Python, PHP, JavaScript.
2. **AI and Machine Learning**: Designing systems and solutions related to artificial intelligence and machine learning.
3. **Data Mining and Big Data**: Extracting valuable insights from large datasets.
4. **Natural Language Processing (NLP)**: Working on systems that understand and generate human language.
5. **Software Development Frameworks**: Utilizing various tools and frameworks such as Streamlit, TensorFlow, PyTorch, and langchain.
6. **Database Systems**: Implementing and working with databases like PostgreSQL, Elasticsearch, Neo4j, and others.
His portfolio highlights projects such as an AI chatbot for analyzing company documents and a self-driving vehicle based on TensorFlow and Raspberry Pi.
Additionally, he has contributed to conferences and created e-learning courses focused on machine learning, underscoring his dual role as a developer and educator.
##### INPUT:
Is Michał Żarnecki programmer the same person as Michał Żarnecki audio engineer?
##### RESPONSE:
Based on the information provided, it appears that Michał Żarnecki the programmer and Michał Żarnecki the audio engineer are not the same person.
Here’s why:
1. **Fields of Expertise**:
- Michał Żarnecki, the audio engineer, was a well-known operator and reżyser dźwięku (sound director) in Poland, with notable contributions to the Polish film industry, as mentioned in the Wikipedia excerpt.
- Michal Żarnecki, the programmer, has a portfolio focused on programming in Python, PHP, and JavaScript, with projects related to AI, machine learning, data mining, and software development.
2. **Lifespan**:
- Michał Żarnecki the audio engineer was born on November 12, 1946, and passed away on November 21, 2016.
- The projects listed in Michał Żarnecki the programmer’s portfolio date from 2014 to 2016, which would be conflicting if he had passed away in 2016 and was actively working in those years.
3. **Occupational Focus**:
- The audio engineer has a career documented in film sound engineering and education.
- The programmer’s career is centered around software development, mobile applications, ERP systems, and consulting in technology.
Given the distinct differences in their professional domains, timelines, and expertise, it is highly unlikely that they are the same individual
Conceito básico:
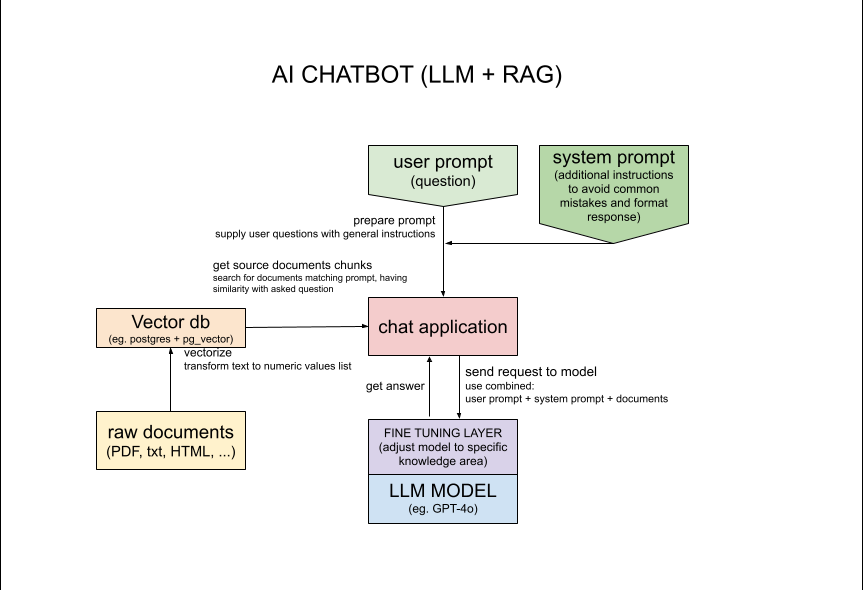
Mais detalhes para nerds:
Para acelerar o carregamento de documentos ou usar mais deles para melhor recuperação, manipule o valor $skipFirstN em app/src/service/DocumentLoader.php:20
Após alterações nos scripts PHP, reconstrua a janela de encaixe com comandos:
docker-compose rm
docker rmi -f php-rag
docker-compose up
os sites usados para preencher o banco de dados de vetores vêm do conjunto de dados "Classificação de sites" no Kaggle autor: Hetul Mehta link: https://www.kaggle.com/datasets/hetulmehta/website-classification?resource=download
artigos/repositórios relacionados:
https://medium.com/mlearning-ai/create-a-chatbot-in-python-with-langchain-and-rag-85bfba8c62d2
https://github.com/Krisseck/php-rag
https://ollama.com/downloadollama pull llama3:latestollama pull mxbai-embed-large ollama list
NAME ID SIZE MODIFIED
mxbai-embed-large:latest 468836162de7 669 MB 7 seconds ago
llama3:latest 365c0bd3c000 4.7 GB 17 seconds ago
ollama serveapp/src/loadDocuments.php (padrão) Por favor, deixe-me saber se você encontrar algum problema ou algo para melhorar. Você pode entrar em contato comigo pelo endereço de e-mail [email protected]. Sinta-se à vontade para relatar bugs e propor atualizações em solicitações pull.


