typesense
Version 27.1
Typesense é um mecanismo de pesquisa rápido e tolerante a erros de digitação para criar experiências de pesquisa agradáveis.
Uma alternativa Algolia de código aberto e
Uma alternativa ElasticSearch mais fácil de usar
Site | Documentação | Roteiro | Comunidade Slack | Tópicos da comunidade | Twitter
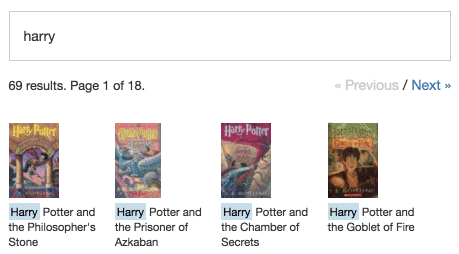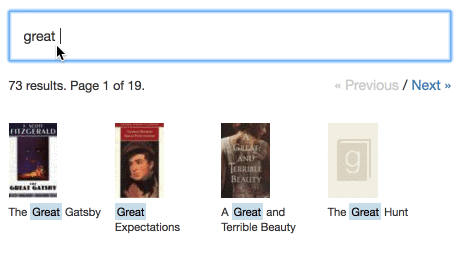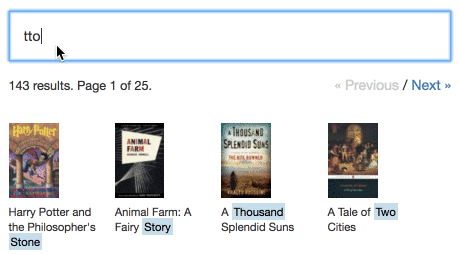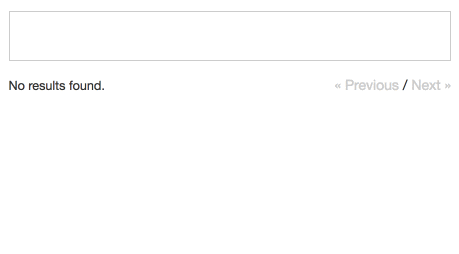
Aqui estão algumas demonstrações ao vivo que mostram o Typesense em ação em grandes conjuntos de dados:
? Se preferir assistir vídeos:
Não vê um recurso nesta lista? Pesquise nosso rastreador de problemas se alguém já o solicitou e adicione um comentário explicando seu caso de uso ou abra um novo problema se não. Priorizamos nosso roteiro com base no feedback dos usuários, por isso adoraríamos ouvir sua opinião.
Aqui está o roteiro público do Typesense: https://typesense.link/roadmap.
A primeira coluna também explica como priorizamos recursos, como você pode influenciar a priorização e nossa cadência de lançamento.
Adoraríamos fazer benchmark com conjuntos de dados maiores, se pudermos encontrar grandes conjuntos de dados de domínio público. Se você tiver alguma sugestão para conjuntos de dados estruturados abertos, informe-nos abrindo um problema. Também ficaríamos encantados se você pudesse compartilhar benchmarks de seus próprios grandes conjuntos de dados. Por favor, envie-nos um PR!
O Typesense é usado por vários usuários em diferentes domínios e setores.
No Typesense Cloud atendemos mais de 10 BILHÕES de pesquisas por mês. As imagens Docker da Typesense foram baixadas mais de 12 milhões de vezes.
Recentemente, começamos a documentar quem o usa em nosso Showcase. Se você quiser ser incluído na lista, sinta-se à vontade para editar SHOWCASE.md e nos enviar um PR.
Você também verá uma lista de logotipos de usuários na página inicial do Typesense Cloud.
Opção 1: Você pode baixar os pacotes binários que publicamos para Linux (x86_64 e arm64) e Mac (x86_64).
Opção 2: você também pode executar o Typesense a partir de nossa imagem oficial do Docker.
Opção 3: criar um cluster gerenciado com Typesense Cloud:

Aqui está um exemplo rápido mostrando como você pode criar uma coleção, indexar um documento e pesquisá-lo no Typesense.
Vamos começar iniciando o servidor Typesense via Docker:
docker run -p 8108:8108 -v/tmp/data:/data typesense/typesense:27.1 --data-dir /data --api-key=Hu52dwsas2AdxdE
Temos clientes API em algumas linguagens, mas vamos usar o cliente Python neste exemplo.
Instale o cliente Python para Typesense:
pip install typesense
Agora podemos inicializar o cliente e criar uma coleção companies :
import typesense
client = typesense . Client ({
'api_key' : 'Hu52dwsas2AdxdE' ,
'nodes' : [{
'host' : 'localhost' ,
'port' : '8108' ,
'protocol' : 'http'
}],
'connection_timeout_seconds' : 2
})
create_response = client . collections . create ({
"name" : "companies" ,
"fields" : [
{ "name" : "company_name" , "type" : "string" },
{ "name" : "num_employees" , "type" : "int32" },
{ "name" : "country" , "type" : "string" , "facet" : True }
],
"default_sorting_field" : "num_employees"
})Agora, vamos adicionar um documento à coleção que acabamos de criar:
document = {
"id" : "124" ,
"company_name" : "Stark Industries" ,
"num_employees" : 5215 ,
"country" : "USA"
}
client . collections [ 'companies' ]. documents . create ( document )Finalmente, vamos procurar o documento que acabamos de indexar:
search_parameters = {
'q' : 'stork' ,
'query_by' : 'company_name' ,
'filter_by' : 'num_employees:>100' ,
'sort_by' : 'num_employees:desc'
}
client . collections [ 'companies' ]. documents . search ( search_parameters )Você notou o erro de digitação no texto da consulta? Não é grande coisa. O Typesense lida com erros tipográficos imediatamente!
Um passo a passo está disponível em nosso site aqui.
Isso irá guiá-lo através do processo de inicialização de um servidor Typesense, indexação de dados nele e consulta do conjunto de dados.
Aqui está nossa documentação oficial da API, disponível em nosso site: https://typesense.org/api.
Se você notar algum problema com a documentação ou passo a passo, informe-nos ou envie-nos um PR aqui: https://github.com/typesense/typesense-website.
Embora você possa definitivamente usar CURL para interagir diretamente com o Typesense Server, oferecemos clientes API oficiais para simplificar o uso do Typesense no idioma de sua escolha. Os clientes de API vêm integrados com uma estratégia de repetição inteligente para garantir que as chamadas de API feitas por meio deles sejam resilientes, especialmente em uma configuração de alta disponibilidade.
Se não oferecermos um cliente API em seu idioma, você ainda poderá usar qualquer biblioteca cliente HTTP popular para acessar diretamente as APIs do Typesense.
Aqui estão alguns clientes e integrações contribuídos pela comunidade:
Aceitamos contribuições da comunidade para adicionar mais bibliotecas e integrações de clientes oficiais. Entre em contato conosco em [email protected] ou abra um problema no GitHub para colaborar conosco na arquitetura.
Também temos as seguintes integrações de estrutura:
Temos uma coleção Postman mantida pela comunidade aqui: https://github.com/typesense/postman.
Postman é um aplicativo que permite realizar solicitações HTTP apontando e clicando, em vez de digitá-las no terminal. A coleção Postman acima fornece solicitações de modelo que você pode importar para o Postman, para fazer chamadas de API rapidamente para o Typesense.
Você pode usar nosso adaptador InstantSearch.js para criar rapidamente experiências de pesquisa poderosas, completas com filtragem, classificação, paginação e muito mais.
Veja como: https://typesense.org/docs/guide/search-ui-components.html
Elasticsearch é um grande software que exige um esforço nada trivial para configurar, administrar, dimensionar e ajustar. Ele oferece alguns milhares de parâmetros de configuração para chegar à configuração ideal. Portanto, é mais adequado para grandes equipes que têm largura de banda para deixá-lo pronto para produção, monitorá-lo regularmente e escalá-lo, especialmente quando precisam armazenar bilhões de documentos e petabytes de dados (por exemplo: logs).
O Typesense foi desenvolvido especificamente para diminuir o “tempo de lançamento no mercado” para uma experiência de pesquisa agradável. É uma alternativa leve, mas poderosa e escalável, que se concentra na felicidade e experiência do desenvolvedor com uma API limpa e bem documentada, semântica clara e padrões inteligentes para que funcione bem imediatamente, sem que você precise girar muitos botões .
O Elasticsearch também é executado na JVM, o que por si só pode exigir um grande esforço de ajuste para funcionar de maneira ideal. O Typesense, por outro lado, é um binário nativo independente e leve, por isso é simples de configurar e operar.
Veja uma comparação de recursos lado a lado aqui.
Algolia é um produto proprietário, hospedado e de pesquisa como serviço que funciona bem quando o custo não é um problema. Pela nossa experiência, sites e aplicativos de rápido crescimento atingem rapidamente limites de pesquisa e indexação, acompanhados de atualizações caras de planos à medida que aumentam.
O Typesense, por outro lado, é um produto de código aberto que você pode executar em sua própria infraestrutura ou usar nossa oferta gerenciada de SaaS – Typesense Cloud. A versão de código aberto é de uso gratuito (além, é claro, dos seus próprios custos de infra-estrutura). Com o Typesense Cloud não cobramos por registros ou operações de pesquisa. Em vez disso, você obtém um cluster dedicado e pode lançar nele o máximo de dados e tráfego que puder suportar. Você paga apenas um custo fixo por hora e taxas de largura de banda, dependendo da configuração escolhida, semelhante à maioria das plataformas de nuvem modernas.
Do ponto de vista do produto, o Typesense está mais próximo em espírito do Algolia do que do Elasticsearch. No entanto, abordamos algumas limitações importantes com Algolia:
Algolia exige índices separados para cada ordem de classificação, o que conta para os limites do seu plano. A maioria das configurações de índice, como campos para pesquisar, campos para facetar, campos para agrupar, configurações de classificação, etc., são definidas antecipadamente quando o índice é criado, em vez de poder defini-los dinamicamente no momento da consulta.
Com o Typesense, essas configurações podem ser definidas no momento da pesquisa por meio de parâmetros de consulta, o que o torna muito flexível e desbloqueia novos casos de uso. O Typesense também é capaz de fornecer resultados classificados com um único índice, em vez de ter que criar vários. Isso ajuda a reduzir o consumo de memória.
Algolia oferece os seguintes recursos que o Typesense não possui atualmente: personalização e análise de pesquisa baseada em servidor. Para análises, você ainda pode instrumentar sua pesquisa no lado do cliente e enviar métricas de pesquisa para a ferramenta de análise da web de sua preferência.
Pretendemos preencher essa lacuna no Typesense, mas enquanto isso, informe-nos se algum deles for um obstáculo para o seu caso de uso, criando uma solicitação de recurso em nosso rastreador de problemas.
Veja uma comparação de recursos lado a lado aqui.
Um novo servidor Typesense consumirá cerca de 30 MB de memória. À medida que você começa a indexar documentos, o uso de memória aumentará correspondentemente. O quanto aumenta depende do número e tipo de campos que você indexa.
Nós nos esforçamos para manter as estruturas de dados na memória enxutas. Para se ter uma ideia aproximada: quando 1 milhão de títulos do Hacker News são indexados junto com seus pontos, o Typesense consome 165 MB de memória. O mesmo tamanho desses dados em disco no formato JSON é 88 MB. Se você tiver algum número de seus próprios conjuntos de dados que possamos adicionar a esta seção, envie-nos um PR!
Pela nossa experiência, as empresas geralmente ficam preocupadas quando as bibliotecas que utilizam são licenciadas pela GPL, uma vez que o código da biblioteca é diretamente integrado ao seu código e levará a trabalhos derivados e acionará a conformidade com a GPL. No entanto, o Typesense Server é um software de servidor e esperamos que os usuários normalmente o executem como um daemon separado e não o integrem ao seu próprio código. A GPL cobre e permite esse caso de uso generosamente (por exemplo: Linux é licenciado pela GPL) . Agora, AGPL é o que faz com que o software de servidor acessado através de uma rede resulte em trabalho derivado e não em GPL. E por esse motivo optamos por não usar AGPL para Typesense.
Agora, se alguém fizer modificações no servidor Typesense, a GPL permitirá que você ainda mantenha as modificações para si mesmo, desde que não distribua o código modificado. Assim, uma empresa pode, por exemplo, modificar o servidor Typesense e executar o código modificado internamente e ainda assim não ter que abrir o código-fonte de suas modificações, desde que disponibilize o código modificado para todos que tenham acesso ao software modificado.
Agora, se alguém fizer modificações no servidor Typesense e distribuir as modificações, é aí que a GPL entra em ação. Dado que publicamos nosso trabalho para a comunidade, gostaríamos que as modificações de outros também fossem abertas à comunidade no espírito de código aberto. Usamos GPL para esse propósito. Outras licenças permitiriam que nosso trabalho de código aberto fosse modificado, transformado em código fechado e distribuído, o que queremos evitar com o Typesense para a sustentabilidade do projeto a longo prazo.
Aqui estão mais informações sobre o porquê da GPL, conforme descrito pelo Discourse: https://meta.discourse.org/t/why-gnu-license/2531. Muitos dos pontos mencionados ali ressoam em nós.
Agora, todos os itens acima se aplicam apenas ao Typesense Server. Nossas bibliotecas clientes devem ser integradas ao código de nossos usuários e, portanto, usam a licença Apache.
Então, em resumo, AGPL é o que normalmente é problemático para software de servidor e optamos por não usá-lo. Acreditamos que a GPL para Typesense Server captura a essência do que queremos para este projeto de código aberto. A GPL tem uma longa história de uso bem-sucedido por projetos populares de código aberto. Nossas bibliotecas ainda são licenciadas pelo Apache.
Se você tiver detalhes que o impeçam de usar o Typesense devido a um problema de licenciamento, ficaremos felizes em explorar este tópico mais detalhadamente com você. Por favor, entre em contato conosco.
Se você tiver dúvidas gerais sobre o Typesense, quiser dizer olá ou apenas acompanhar, gostaríamos de convidá-lo a participar de nossa comunidade pública no Slack.
Se você tiver algum problema ou questão, crie um problema no GitHub e faremos o possível para ajudar.
Nós nos esforçamos para fornecer um bom suporte por meio de nossos rastreadores de problemas no GitHub. No entanto, se desejar receber suporte privado e priorizado com:
Oferecemos opções de suporte pago descritas aqui.
Somos uma equipe enxuta com a missão de democratizar a pesquisa e aceitaremos toda a ajuda que pudermos conseguir! Se você quiser se envolver, aqui estão informações sobre onde sua ajuda poderia ser útil: Contributing.md
Se quiser receber atualizações quando lançarmos novas versões, clique no botão "Assistir" na parte superior e selecione "Somente versões". O GitHub enviará notificações junto com um changelog a cada novo lançamento.
Também publicamos atualizações em nossa conta do Twitter sobre lançamentos e tópicos adicionais relacionados ao Typesense. Siga-nos aqui: @typesense.
Também postaremos atualizações em nossa comunidade do Slack.
Usamos o Bazel para construir o Typesense.
Typesense requer as seguintes dependências:
Consulte as etapas de construção do CI para obter o conjunto mais recente de dependências.
Depois de instalá-los, execute o seguinte na raiz do repositório:
bazel build //:typesense-serverA primeira construção levará algum tempo, pois outras bibliotecas de terceiros são extraídas e construídas como parte do processo de construção.
© 2016-presente Typesense Inc.


