
Avaliador de classificação avaliado
O Rated Ranking Evaluator (RRE) é uma ferramenta de avaliação da qualidade de pesquisa que, como o nome sugere, avalia a qualidade dos resultados provenientes de uma infraestrutura de pesquisa.
Ligações
- Avaliação da qualidade da pesquisa: uma perspectiva do desenvolvedor
- RRE no Haystack EU, Londres, 2018
- RRE na Fosdem 2019
- Avaliador de classificação avaliado (RRE) Teste prático de relevância @Chorus, 2021
- Rated Ranking Evaluator Enterprise: a próxima geração de ferramentas gratuitas de avaliação de qualidade de pesquisa, Pádua, 2021
- O Wiki do projeto, localizado em https://github.com/SeaseLtd/rated-ranking-evaluator/wiki
- Lista de discussão de usuários RRE: https://groups.google.com/g/rre-user
No momento, Apache Solr e Elasticsearch são suportados (consulte a documentação para versões suportadas).
A imagem a seguir ilustra o ecossistema RRE:
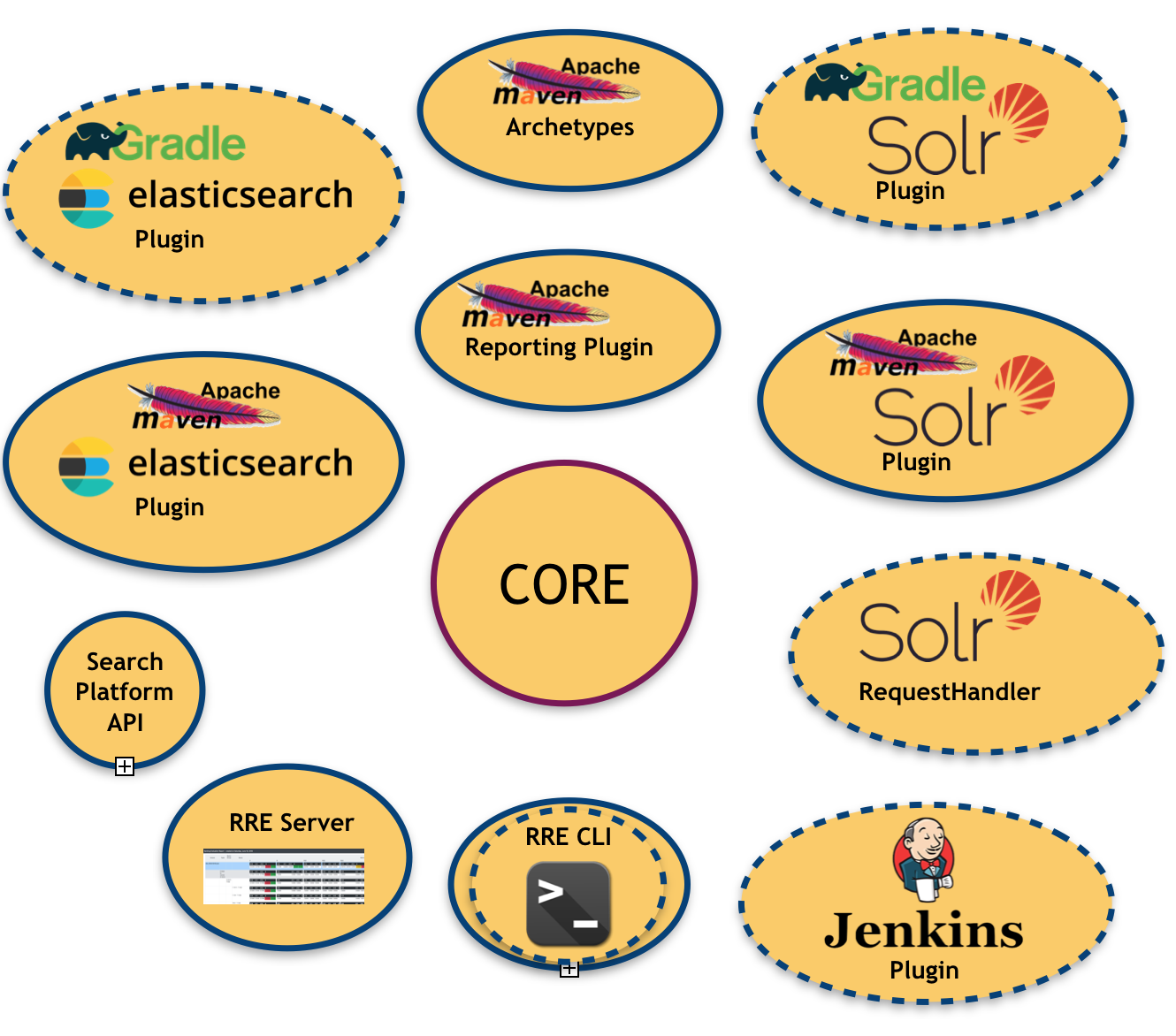
Como você pode ver, existem muitos módulos já implementados e planejados (aqueles com borda tracejada)
- um núcleo , que é a biblioteca central responsável por produzir os resultados da avaliação
- uma API de plataforma de pesquisa : para abstrair (e vincular) a plataforma de pesquisa subjacente
- um conjunto de ligações de plataforma de pesquisa : como dito acima, no momento temos duas ligações disponíveis (Apache Solr e Elasticsearch)
- um plugin Apache Maven para cada ligação de plataforma de pesquisa disponível: que permite injetar RRE em um sistema de construção baseado em Maven
- um plugin de relatórios Apache Maven : para produzir relatórios de avaliação em um formato legível por humanos (por exemplo, PDF, Excel), útil para direcionar usuários não técnicos
- um servidor RRE : um painel de controle simples baseado na web onde os resultados da avaliação são atualizados em tempo real após cada ciclo de construção.
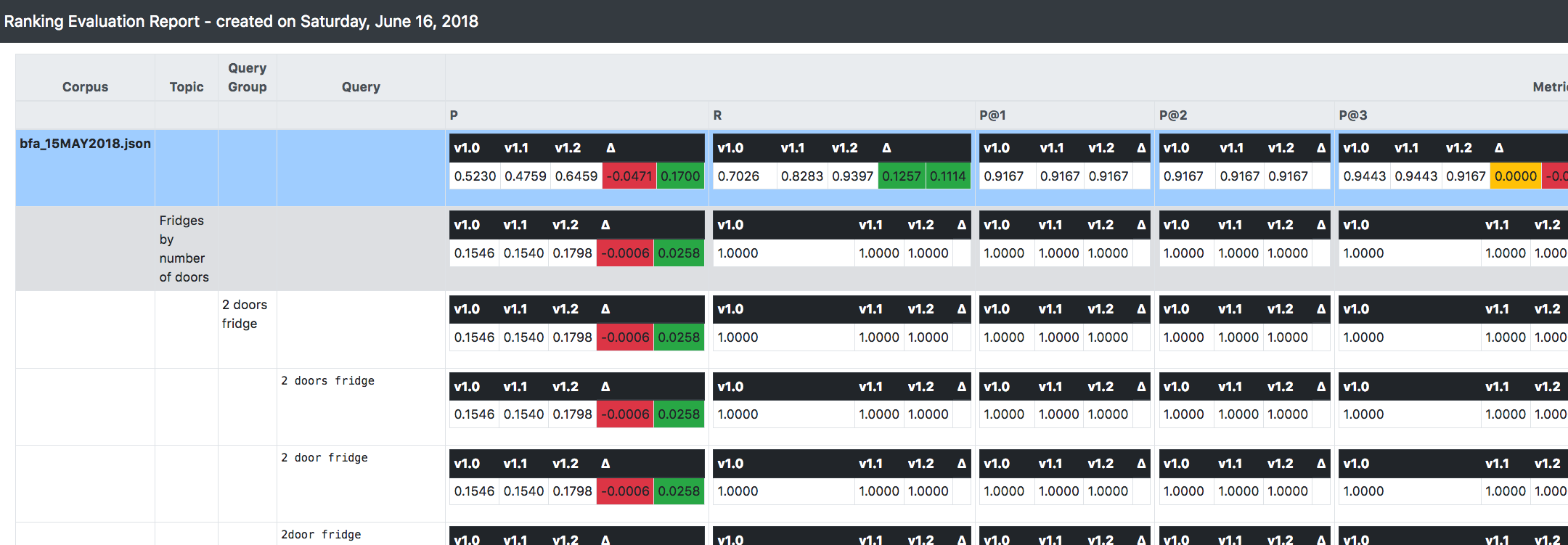
Todo o sistema foi construído como uma estrutura onde as métricas podem ser configuradas/ativadas e até mesmo conectadas (é claro, esta opção requer algum desenvolvimento). As métricas que fazem parte da versão atual do RRE são:
- Precisão : a fração de documentos recuperados que são relevantes.
- Recall : a fração de documentos relevantes que são recuperados.
- Precisão em 1 : esta métrica indica se o primeiro resultado superior da lista é relevante ou não.
- Precisão em 2 : igual à anterior, mas considera os dois primeiros resultados.
- Precisão em 3 : igual à anterior, mas considera os três primeiros resultados.
- Precisão em 10 : esta métrica mede o número de resultados relevantes nos 10 principais resultados de pesquisa.
- Classificação recíproca : é o inverso multiplicativo da classificação da primeira resposta "correta": 1 para o primeiro colocado, 1/2 para o segundo colocado, 1/3 para o terceiro e assim por diante.
- Classificação recíproca esperada (ERR) Uma extensão da classificação recíproca com relevância graduada, mede o período de tempo recíproco esperado que o usuário levará para encontrar um documento relevante.
- Precisão média : a área sob a curva de recuperação de precisão.
- NDCG em 10 : Ganho cumulativo descontado normalizado em 10; veja: https://en.wikipedia.org/w/index.php?title=Discounted_cumulative_gain§ion=4#Normalized_DCG
- Medida F : mede a eficácia da recuperação em relação a um usuário que atribui β vezes mais importância à recuperação do que à precisão. RRE fornece as três instâncias F-Measure mais populares: F0.5, F1 e F2
Além dessas métricas "folha", que são calculadas no nível da consulta, o RRE fornece um modelo de dados aninhado rico, onde a mesma métrica pode ser agregada em vários níveis. Por exemplo, as consultas são agrupadas em Grupos de Consultas e os Grupos de Consultas são agrupados em Tópicos. Isso significa que as mesmas métricas listadas acima também estão disponíveis em níveis superiores usando a média aritmética como critério de agregação. Como consequência disso, o RRE fornece também as seguintes métricas:
- Precisão média média : a média das precisões médias calculadas no nível da consulta.
- Classificação recíproca média : a média das classificações recíprocas calculadas no nível da consulta.
- todas as outras métricas listadas acima agregadas por sua média aritmética.
Uma das coisas mais importantes que você pode ver na imagem acima é que o RRE é capaz de acompanhar (e fazer comparações) entre várias versões do sistema em avaliação.
Ele incentiva uma abordagem incremental/iterativa/imutável ao desenvolver e evoluir um sistema de pesquisa: supondo que você esteja iniciando na versão 1.0, ao aplicar alguma alteração relevante à sua configuração, em vez de alterar essa versão, é melhor cloná-la e aplicar o mudanças para a nova versão (vamos chamá-la de 1.1).
Desta forma, quando a construção do sistema acontecer, o RRE irá computar tudo o que foi explicado acima (ou seja, as métricas) para cada versão disponível.
Além disso, fornecerá o delta/tendência entre as versões subsequentes, para que você possa obter imediatamente a direção geral para onde o sistema está indo, em termos de melhorias de relevância.



