sandbox toy semantic search
1.0.0
################################################################################
# ____ _ ____ _ _ #
# / ___|___ | |__ ___ _ __ ___ / ___| __ _ _ __ __| | |__ _____ __ #
# | | / _ | '_ / _ '__/ _ ___ / _` | '_ / _` | '_ / _ / / #
# | |__| (_) | | | | __/ | | __/ ___) | (_| | | | | (_| | |_) | (_) > < #
# _______/|_| |_|___|_| ___| |____/ __,_|_| |_|__,_|_.__/ ___/_/_ #
# #
# This project is part of Cohere Sandbox, Cohere's Experimental Open Source #
# offering. This project provides a library, tooling, or demo making use of #
# the Cohere Platform. You should expect (self-)documented, high quality code #
# but be warned that this is EXPERIMENTAL. Therefore, also expect rough edges, #
# non-backwards compatible changes, or potential changes in functionality as #
# the library, tool, or demo evolves. Please consider referencing a specific #
# git commit or version if depending upon the project in any mission-critical #
# code as part of your own projects. #
# #
# Please don't hesitate to raise issues or submit pull requests, and thanks #
# for checking out this project! #
# #
################################################################################
Mantenedor: jcudit e lsgos
Projeto mantido até pelo menos (AAAA-MM-DD): 14/03/2023
Este é um exemplo de como usar a API Cohere para construir um mecanismo de busca semântica simples. Não se destina a estar pronto para produção ou escalar de forma eficiente (embora possa ser adaptado para esses fins), mas serve para mostrar a facilidade de produzir um mecanismo de busca alimentado por representações produzidas pelos Large Language Models (LLMs) de Cohere.
O algoritmo de busca usado aqui é bastante simples: ele simplesmente encontra o parágrafo que mais se aproxima da representação da pergunta, usando o ponto final co.embed . Isso é explicado com mais detalhes abaixo, mas aqui está um diagrama simples do que está acontecendo. Primeiro, dividimos o texto de entrada em uma série de parágrafos, armazenando seus endereços na entrada em uma lista e gerando uma incorporação vetorial para cada parágrafo usando co.embed :
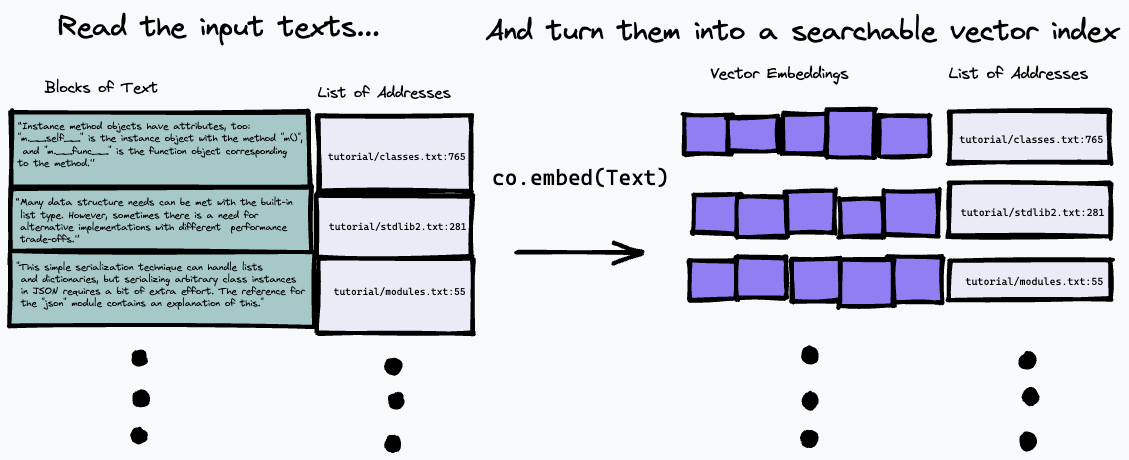
Então, podemos consultar nosso índice incorporando a consulta de texto e encontrando os parágrafos no texto de origem que têm a correspondência mais próxima usando alguma medida de similaridade vetorial (usamos a similaridade de cosseno): 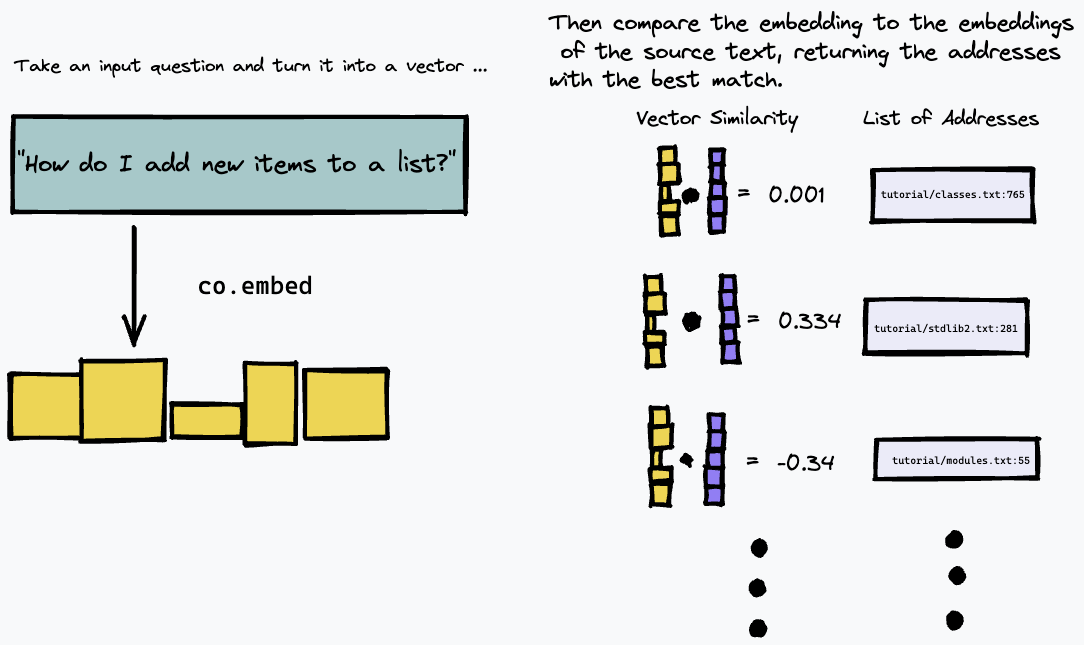
Como resultado, funciona melhor em fontes de texto onde a resposta a uma determinada pergunta provavelmente será dada por um parágrafo concreto no texto, como documentação técnica ou wikis internos que são estruturados como uma lista de instruções ou fatos concretos. Não funciona tão bem, por exemplo, para responder perguntas sobre textos de formato livre, como romances, onde a informação pode estar espalhada por vários parágrafos; você precisaria usar um método diferente de indexação do texto para isso.
Por exemplo, este repositório constrói um mecanismo de busca semântica simples sobre a versão em texto da documentação python mais recente.
Para instalar os requisitos do python, certifique-se de ter o poet instalado e execute:
# install python deps
poetry installVocê também deve ter o docker instalado. No OS X, se você usa homebrew, recomendamos executar
brew install --cask dockerAntes de executar o docker (por exemplo, para executar nosso servidor) pela primeira vez no OS X, abra o aplicativo Docker e conceda a ele os privilégios necessários para executar em seu sistema.
Você também precisará ter uma chave de API Cohere no COHERE_TOKEN . Obtenha um na plataforma Cohere (crie uma conta, se necessário) e grave-o em seu ambiente
export COHERE_TOKEN= < MY_API_KEY > (onde <MY_API_KEY> é a chave que você obteve, sem os colchetes <...> ).
Alternativamente, você pode passar COHERE_TOKEN=<MY_API_KEY> como um argumento adicional para qualquer comando make abaixo.
Siga estas etapas para primeiro construir um índice semântico da sua coleção de documentos. Essas etapas produzem um índice semântico para os documentos oficiais do Python, mas podem ser adaptados para coletas de dados arbitrárias.
Primeiro, baixe a documentação do python executando um dos seguintes comandos.
Se você quiser começar rapidamente, execute
make download-python-docs-smallpara limitar o conjunto de documentos ao tutorial python. Recomendamos fazer isso apenas para um teste rápido, pois os resultados serão muito limitados .
Se você quiser testar o mecanismo de pesquisa em toda a documentação do python, execute
make download-python-docsmas esteja ciente de que a produção dos embeddings levará horas (embora isso só precise ser feito uma vez).
Alternativamente, se você quiser experimentar seu próprio texto, basta baixá-lo como arquivos .txt para um diretório chamado txt/ neste repositório.
Assim que tiver algum texto, precisamos processá-lo em um índice de pesquisa de incorporações e endereços.
Isso pode ser feito usando o comando
make embeddings assumindo que seu texto de destino esteja no diretório ./txt/ .
O comando pesquisará o diretório ./txt/ recursivamente em busca de arquivos com extensão .txt e construirá um banco de dados simples dos embeddings, nome do arquivo e número de linha de cada parágrafo.
Aviso: se você tiver muito texto para pesquisar, isso pode demorar um pouco para terminar!
Depois de construir um arquivo embeddings.npz , você pode usar o seguinte comando para construir uma imagem docker que servirá um aplicativo REST simples para permitir que você consulte o banco de dados que você criou:
make buildVocê pode então iniciar o servidor usando
make runIsso é um pouco exagerado para um exemplo simples, mas foi projetado para refletir o fato de que a construção de um índice de um grande corpo de texto é relativamente lenta e garante que a consulta ao mecanismo seja rápida.
Se você quiser usar este projeto como um bloco de construção para um aplicativo real, é provável que você queira manter seu banco de dados de incorporações de texto em uma arquitetura de servidor e consultá-lo com um cliente leve. Empacotar o servidor como um aplicativo docker significa que é muito simples transformá-lo em um aplicativo “real”, implantando-o em um serviço de nuvem.
Se você abrir uma nova janela de terminal para qualquer uma das opções abaixo, lembre-se de executar
export COHERE_TOKEN= < MY_API_KEY > De longe, a opção mais fácil é executar nosso script auxiliar:
scripts/ask.sh " My query here "para consultar o banco de dados. O script usa um segundo argumento opcional que especifica o número de resultados desejados.
O script exibe uma interface vim modificada, com os seguintes comandos:
q para sair.O painel superior mostrará a posição no documento onde o resultado foi encontrado.
Quando o servidor estiver em execução, você poderá consultá-lo usando uma API REST simples. Você pode explorar a API diretamente acessando /docs#/default/search_search_post aqui. É uma API JSON REST simples; veja como você pode fazer uma consulta usando curl :
curl -X POST -H "Content-Type: application/json" -d '{"query": "How do I append to a list?", "num_results": 3}' http://localhost:8080/search
Isso retornará uma lista JSON de comprimento num_results , cada um com o nome do arquivo e o número da linha ( doc_url e block_url ) dos blocos que tiveram a correspondência semântica mais próxima da sua consulta. Mas você provavelmente deseja apenas ler a parte dos arquivos que é a melhor resposta.
Como estamos pesquisando em arquivos de texto locais, é um pouco mais fácil analisar a saída usando ferramentas de linha de comando; use o script python fornecido utils/query_server.py para consultá-lo na linha de comando. query_server.py imprime os resultados no formato file_name:line_number: padrão, para que possamos folhear os resultados reais de uma maneira agradável, aproveitando o modo quickfix do vim .
Supondo que você tenha o vim em sua máquina, você pode simplesmente
vim +cw -M -q <(python utils/query_server.py "my_query" --num_results 3)
para fazer com que o vim abra os arquivos de texto indexados nos locais retornados pelo algoritmo de pesquisa. (use :qall para fechar a janela e o navegador do quickfix). Você pode percorrer os resultados retornados usando :cn e :cp . Os resultados não são perfeitos; é uma pesquisa semântica, então você esperaria que a correspondência fosse um pouco confusa. Apesar disso, muitas vezes descubro que você pode obter a resposta para sua pergunta nos primeiros resultados, e usar a API do Cohere permite expressar sua pergunta em linguagem natural e construir um mecanismo de pesquisa surpreendentemente eficaz em apenas algumas linhas de código.
Algumas consultas úteis no caso de documentos python que mostram que a pesquisa funciona bem em questões genéricas de linguagem natural são:
How do I put new items in a list? (Observe que esta pergunta evita usar a palavra-chave 'append' e não corresponde exatamente a como os documentos explicam o acréscimo (eles dizem que é usado para adicionar novos itens ao final de uma lista). Mas a pesquisa semântica descobre corretamente que o parágrafo relevante ainda é a melhor correspondência.)How do I put things in a list?Are dictionary keys in insertion order?What is the difference between a tuple and a list? (observe para esta pergunta, que o primeiro resultado para mim é um FAQ sobre basicamente este tópico exato, mas com uma pergunta com uma formulação diferente. No entanto, como é uma pesquisa semântica, nosso algoritmo escolhe corretamente um resultado que corresponda ao significado, não apenas ao redação, da nossa consulta)How do I remove an item from a set?How do list comprehensions work? Este repositório usa uma estratégia muito simples para indexar um documento e procurar a melhor correspondência. Primeiro, ele divide cada documento em parágrafos ou “blocos”. Em seguida, ele chama co.embed em cada parágrafo, para gerar uma incorporação vetorial usando o modelo de linguagem de Cohere. Em seguida, ele armazena cada vetor de incorporação, juntamente com o documento correspondente e o número da linha do parágrafo, em uma matriz simples como um 'banco de dados'.
Para realmente fazer a pesquisa, usamos a biblioteca de pesquisa por similaridade FAISS. Quando recebemos uma consulta, usamos a mesma chamada da API Cohere para incorporar a consulta. Em seguida, usamos o FAISS para encontrar o topo
Se você tiver alguma dúvida ou comentário, registre um problema ou entre em contato conosco no Discord.
Se você gostaria de contribuir para este projeto, leia CONTRIBUTORS.md neste repositório e assine o Contrato de Licença de Colaborador antes de enviar qualquer solicitação pull. Um link para assinar o CLA Cohere será gerado na primeira vez que você fizer uma solicitação pull para um repositório Cohere.
Toy Semantic Search possui uma licença MIT, conforme encontrada no arquivo LICENSE.


