elassandra
v6.2.3.38

Elassandra é uma distribuição Apache Cassandra que inclui um mecanismo de busca Elasticsearch. Elassandra é um banco de dados multimestre e mecanismo de pesquisa em várias nuvens com suporte para replicação em vários datacenters no modo ativo/ativo.
O código do Elasticsearch é incorporado nos nós do Cassanda, fornecendo recursos de pesquisa avançados nas tabelas do Cassandra e o Cassandra serve como um armazenamento de dados e configuração do Elasticsearch.
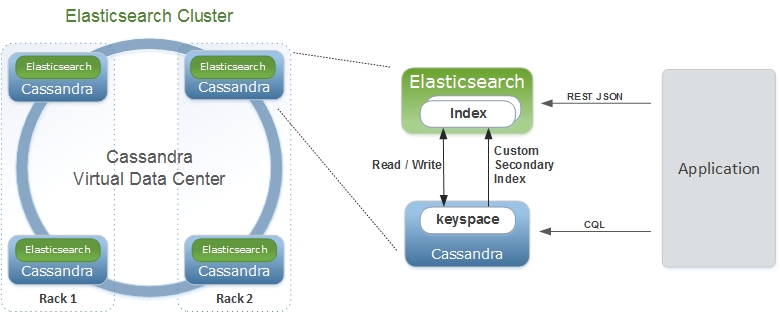
O Elassandra oferece suporte a vnodes Cassandra e é dimensionado horizontalmente adicionando mais nós sem a necessidade de reestilhaçar índices.
A documentação do projeto está disponível em doc.elassandra.io.
Para usuários do Cassandra, o elassandra fornece recursos do Elasticsearch:
Para usuários do Elasticsearch, o elassandra oferece recursos úteis:
Guia de início rápido para executar um cluster Elassandra de nó único no docker.
Implante o Elassandra lançando um Google Kubernetes Engine:
<<<<<<< HEAD Desde a versão 6.8.4.2, o estado do aplicativo gossip X1 pode ser compactado usando uma propriedade do sistema. Habilitar essas configurações permite a criação de vários índices virtuais. Antes de ativar esta configuração, atualize todos os nós 6.8.4.x para 6.8.4.2 (ou superior). Depois que todos os nós estiverem na versão 6.8.4.2, eles poderão descompactar o estado do aplicativo, mesmo que as configurações ainda não estejam configuradas localmente.
Elassandra usa o protocolo Cassandra GOSSIP para gerenciar a tabela de roteamento Elasticsearch e Elassandra 6.8.4.2+ adiciona suporte para compactação do estado do aplicativo X1 para aumentar o número máximo de índices Elasticsearch. Para compatibilidade com versões anteriores, a compactação é desabilitada por padrão, mas depois que todos os seus nós forem atualizados para a versão 6.8.4.2+, você deve habilitar a compactação X1 adicionando -Des.compress_x1=true em seu conf/jvm.options e reiniciando todos nós. Os nós que executam a versão 6.8.4.2+ são capazes de ler X1 compactado e não compactado.
Antes da versão 6.2.3.21, o fator de replicação Cassandra para o keyspace elasic_admin (e elastic_admin_[datacenter.group]) era ajustado automaticamente para o número de nós do datacenter. Desde a versão 6.2.3.21 e por ter um impacto no desempenho em clusters grandes, agora cabe ao administrador do Elassandra ajustar adequadamente o fator de replicação para esse keyspace. Lembre-se de que as atualizações de mapeamento do Elasticsearch dependem de uma transação PAXOS que exige que os nós QUORUM sejam bem-sucedidos, portanto, o fator de replicação deve ser de pelo menos 3 em cada datacenter.
A versão de metadados do Elassandra 6.2.3.19 agora depende da tabela Cassandra elastic_admin.metadata_log (que era elastic_admin.metadata de 6.2.3.8 a 6.2.3.18) para manter o histórico de atualização do mapeamento do elasticsearch e se recuperar automaticamente de um possível problema de tempo limite de gravação do PAXOS.
Ao atualizar o primeiro nó de um cluster, o Elassandra copia automaticamente o metadata.version atual para a nova tabela elastic_admin.metadata_log . Para evitar inconsistência no mapeamento do Elasticsearch, você deve evitar a atualização do mapeamento enquanto a atualização contínua estiver em andamento. Depois que todos os nós forem atualizados, o elastic_admin.metadata não será mais usado e poderá ser removido. Em seguida, você pode obter o histórico de atualização do mapeamento no novo elastic_admin.metadata_log e saber qual nó atualizou o mapeamento, quando e por qual motivo.
O Elassandra 6.2.3.8+ agora gerencia totalmente o mapeamento elasticsearch no esquema CQL por meio do uso de extensões de esquema CQL (consulte system_schema.tables , extensões de coluna ). Essas extensões de tabela e as atualizações de esquema CQL resultantes da criação/modificação do índice elasticsearch são atualizadas em atualizações de esquema atômico em lote para garantir consistência quando ocorrem atualizações simultâneas. Além disso, essas extensões são armazenadas em binário e suportam atualizações parciais para serem mais eficientes. Como resultado, o mapeamento do elasticsearch não é mais armazenado na tabela elastic_admin.metadata .
AVISO: durante a atualização contínua, as alterações no mapeamento do elasticserach não são propagadas entre os nós que executam as versões nova e antiga, portanto, não altere seu mapeamento durante a atualização. Depois que todos os seus nós tiverem sido atualizados para 6.2.3.8+ e validados, aplique as seguintes instruções CQL para remover metadados inúteis do elasticsearch:
ALTER TABLE elastic_admin.metadata DROP metadata ;
ALTER TABLE elastic_admin.metadata WITH comment = ' ' ;AVISO: Devido às extensões de tabela CQL usadas pelo Elassandra, algumas versões antigas do cqlsh podem levar à seguinte mensagem de erro "O objeto 'módulo' não possui o atributo 'viewkeys'." . Isso vem do antigo driver python cassandra incorporado no Cassandra e foi relatado em CASSANDRA-14942. Possíveis soluções alternativas:
docker run -it --rm strapdata/cqlsh:0.1 node.example.com Certifique-se de que o Java 8 esteja instalado e que JAVA_HOME aponte para o local correto.
export CASSANDRA_HOME=<extracted_directory>bin/cassandra -ebin/nodetool statuscurl -XGET localhost:9200/_cluster/state Tente indexar um documento em um índice inexistente:
curl -XPUT ' http://localhost:9200/twitter/_doc/1?pretty ' -H ' Content-Type: application/json ' -d ' {
"user": "Poulpy",
"post_date": "2017-10-04T13:12:00Z",
"message": "Elassandra adds dynamic mapping to Cassandra"
} 'Então procure em Cassandra:
bin/cqlsh -e " SELECT * from twitter. " _doc " " Nos bastidores, Elassandra criou um novo twitter e tabela Keyspace _doc .
admin@cqlsh > DESC KEYSPACE twitter;
CREATE KEYSPACE twitter WITH replication = { ' class ' : ' NetworkTopologyStrategy ' , ' DC1 ' : ' 1 ' } AND durable_writes = true;
CREATE TABLE twitter . " _doc " (
" _id " text PRIMARY KEY ,
message list < text > ,
post_date list < timestamp > ,
user list < text >
) WITH bloom_filter_fp_chance = 0 . 01
AND caching = { ' keys ' : ' ALL ' , ' rows_per_partition ' : ' NONE ' }
AND comment = ' '
AND compaction = { ' class ' : ' org.apache.cassandra.db.compaction.SizeTieredCompactionStrategy ' , ' max_threshold ' : ' 32 ' , ' min_threshold ' : ' 4 ' }
AND compression = { ' chunk_length_in_kb ' : ' 64 ' , ' class ' : ' org.apache.cassandra.io.compress.LZ4Compressor ' }
AND crc_check_chance = 1 . 0
AND dclocal_read_repair_chance = 0 . 1
AND default_time_to_live = 0
AND gc_grace_seconds = 864000
AND max_index_interval = 2048
AND memtable_flush_period_in_ms = 0
AND min_index_interval = 128
AND read_repair_chance = 0 . 0
AND speculative_retry = ' 99PERCENTILE ' ;
CREATE CUSTOM INDEX elastic__doc_idx ON twitter. " _doc " () USING ' org.elassandra.index.ExtendedElasticSecondaryIndex ' ;Por padrão, os campos do Elasticsearch com vários valores são mapeados para a lista do Cassandra. Agora, insira uma linha com CQL:
INSERT INTO twitter. " _doc " ( " _id " , user, post_date, message)
VALUES ( ' 2 ' , [ ' Jimmy ' ], [dateof(now())], [ ' New data is indexed automatically ' ]);
SELECT * FROM twitter. " _doc " ;
_id | message | post_date | user
-- ---+--------------------------------------------------+-------------------------------------+------------
2 | [ ' New data is indexed automatically ' ] | [ ' 2019-07-04 06:00:21.893000+0000 ' ] | [ ' Jimmy ' ]
1 | [ ' Elassandra adds dynamic mapping to Cassandra ' ] | [ ' 2017-10-04 13:12:00.000000+0000 ' ] | [ ' Poulpy ' ]
( 2 rows)Em seguida, procure-o com a API Elasticsearch:
curl " localhost:9200/twitter/_search?q=user:Jimmy&pretty "E aqui está um exemplo de resposta:
{
"took" : 3 ,
"timed_out" : false ,
"_shards" : {
"total" : 1 ,
"successful" : 1 ,
"skipped" : 0 ,
"failed" : 0
},
"hits" : {
"total" : 1 ,
"max_score" : 0.6931472 ,
"hits" : [
{
"_index" : " twitter " ,
"_type" : " _doc " ,
"_id" : " 2 " ,
"_score" : 0.6931472 ,
"_source" : {
"post_date" : " 2019-07-04T06:00:21.893Z " ,
"message" : " New data is indexed automatically " ,
"user" : " Jimmy "
}
}
]
}
} This software is licensed under the Apache License, version 2 ("ALv2"), quoted below.
Copyright 2015-2018, Strapdata ([email protected]).
Licensed under the Apache License, Version 2.0 (the "License"); you may not
use this file except in compliance with the License. You may obtain a copy of
the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS, WITHOUT
WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the
License for the specific language governing permissions and limitations under
the License.


