wagtail_textract
1.0.0
Este pacote não tem manutenção e não temos planos de mantê-lo.
Aconselhamos você a usá-lo como exemplo, talvez copie o código em seu próprio projeto, mas não instale o pacote.
Este pacote serve para substituir a classe Document do Wagtail por uma que permite pesquisar o conteúdo do arquivo Document usando textract.
Textract pode extrair texto (entre outros) de arquivos PDF, Excel e Word.
O pacote foi inspirado na edição "Pesquisar: Extrair texto de documentos" do Wagtail.
Os documentos funcionarão como antes, exceto que a pesquisa de documentos na interface administrativa do Wagtail também encontrará termos de pesquisa no conteúdo dos arquivos.
Algumas capturas de tela para ilustrar.
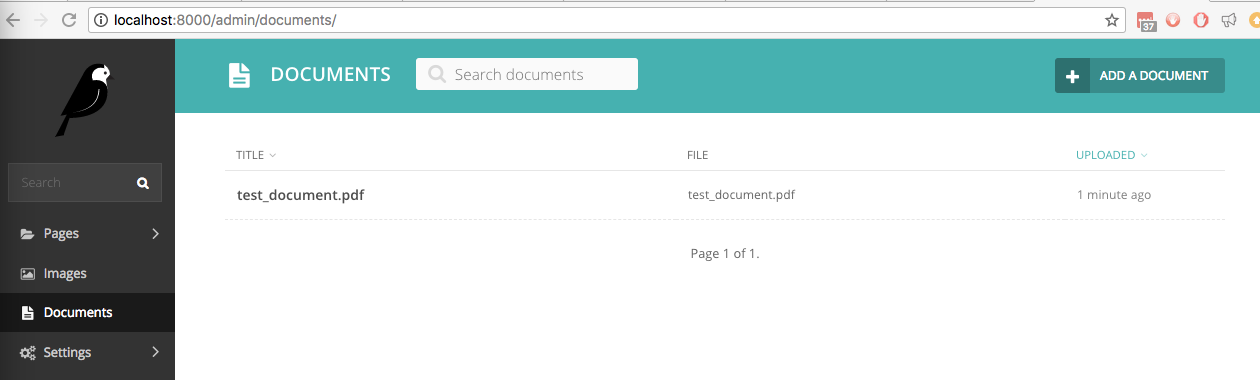
Em nosso novo site Wagtail com wagtail_textract instalado, carregamos um arquivo chamado test_document.pdf com texto manuscrito. Ele está listado na interface administrativa em Documentos:
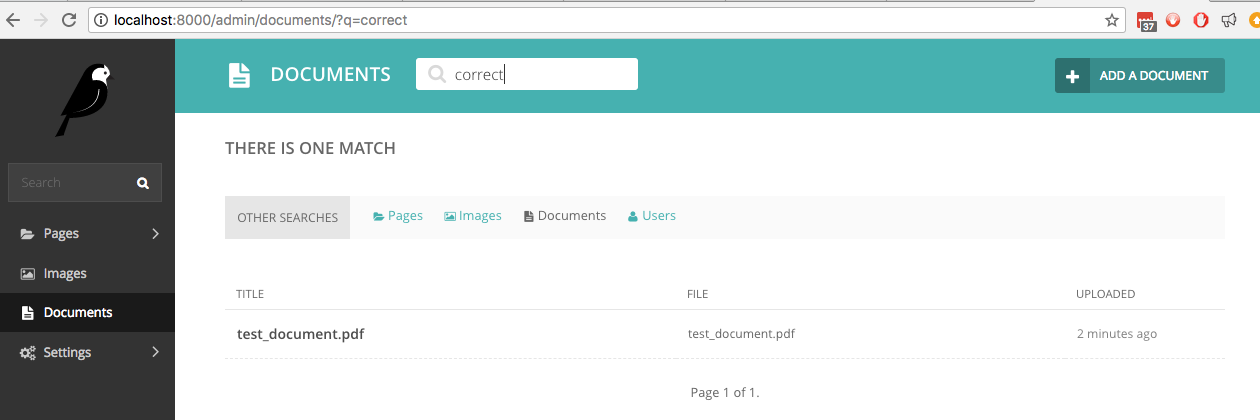
Se agora procurarmos em Documentos a palavra correct , que é uma das palavras manuscritas, a pesquisa ao vivo a encontrará:
A suposição é que esta pesquisa não deve estar disponível apenas na interface administrativa do Wagtail, mas também em uma visualização de pesquisa voltada ao público, para a qual fornecemos um exemplo de código.
Usamos este pacote em produção desde agosto de 2018 em https://nuffic.nl.
wagtail_textract aos seus requisitos e/ou pip install wagtail_textractINSTALLED_APPS .WAGTAILDOCS_DOCUMENT_MODEL = "wagtail_textract.document" nas configurações do Django.Observação: você receberá um aviso de incompatibilidade durante a instalação do wagtail_texttract (Wagtail 2.0.1 instalado):
requests 2.18.4 has requirement chardet<3.1.0,>=3.0.2, but you'll have chardet 2.3.0 which is incompatible.
textract 1.6.1 has requirement beautifulsoup4==4.5.3, but you'll have beautifulsoup4 4.6.0 which is incompatible.
Não vimos isso levando a problemas, mas é algo para se manter em mente.
Para fazer textract usar o Tesseract, o que acontece se textract normal não encontrar texto, você precisa adicionar os arquivos de dados nos quais o Tesseract pode basear sua correspondência de palavras.
Crie um diretório tessdata no diretório do seu projeto e baixe os idiomas desejados.
A transcrição é feita automaticamente após salvar o documento, em um executor asyncio para evitar o bloqueio da resposta durante o processamento.
Para transcrever todos os documentos existentes, execute o comando de gerenciamento::
./manage.py transcribe_documents
Isso pode levar muito tempo, obviamente.
Aqui está um exemplo de código para uma visualização de pesquisa (fora da interface administrativa do Wagtail) que mostra os resultados da página e do documento.
from itertools import chain
from wagtail . core . models import Page
from wagtail . documents . models import get_document_model
def search ( request ):
# Search
search_query = request . GET . get ( 'query' , None )
if search_query :
page_results = Page . objects . live (). search ( search_query )
document_results = Document . objects . search ( search_query )
search_results = list ( chain ( page_results , document_results ))
# Log the query so Wagtail can suggest promoted results
Query . get ( search_query ). add_hit ()
else :
search_results = Page . objects . none ()
# Render template
return render ( request , 'website/search_results.html' , {
'search_query' : search_query ,
'search_results' : search_results ,
}) Seu modelo deve permitir o tratamento de documentos de maneira diferente das páginas, porque você não pode gerar pageurl result em um documento:
{% if result . file %}
< a href = " {{ result.url }} " >{{ result }}</ a >
{% else %}
< a href = " {% pageurl result %} " >{{ result }}</ a >
{% endif %} Para usar wagtail_texttract, seu modelo CustomizedDocument deve fazer o mesmo que o documento de wagtail_texttract:
TranscriptionMixinsearch_fields from wagtail_textract . models import TranscriptionMixin
class CustomizedDocument ( TranscriptionMixin , ...):
"""Extra fields and methods for Document model."""
search_fields = ... + [
index . SearchField (
'transcription' ,
partial_match = False ,
),
] Observe que a primeira classe da subclasse deve ser TranscriptionMixin , portanto, seu save() tem precedência sobre as outras classes pai.
Para executar testes, verifique este repositório e:
make test
Um relatório de cobertura será gerado em ./coverage_html_report/ .


