elastic_transformers
1.0.0
Elasticsearch semântico com transformadores de frases. Usaremos o poder do Elastic e a magia do BERT para indexar um milhão de artigos e realizar pesquisas lexicais e semânticas neles.
O objetivo é fornecer uma maneira fácil de configurar seu próprio Elasticsearch com recursos quase de última geração de incorporações contextuais/pesquisa semântica usando transformadores de PNL.
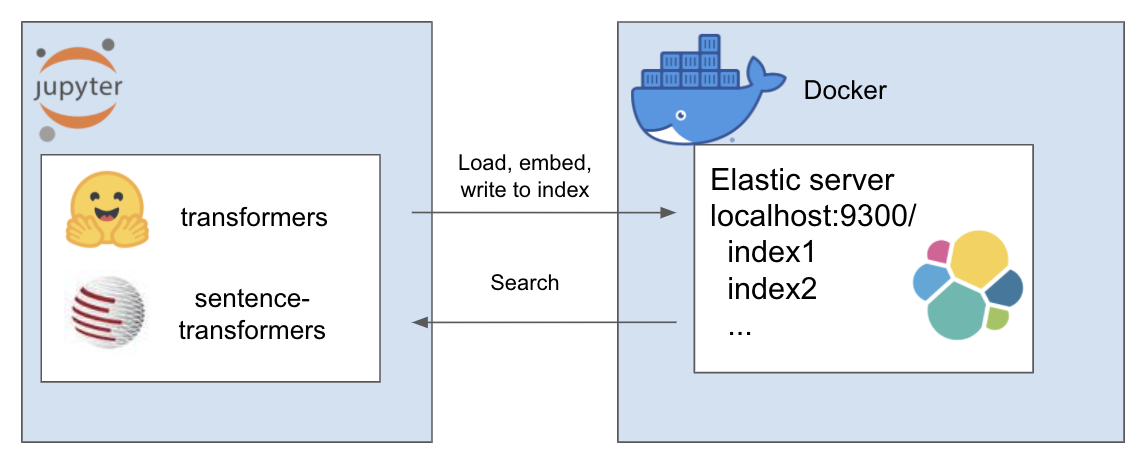
A configuração acima funciona da seguinte maneira
Meu ambiente se chama et e eu uso conda para isso. Navegue dentro do diretório do projeto
conda create - - name et python = 3.7
conda install - n et nb_conda_kernels
conda activate et
pip install - r requirements . txtPara este tutorial estou usando A Million News Headlines de Rohk e coloco-o na pasta de dados dentro do diretório do projeto.
elastic_transformers/
├── data/
Você descobrirá que as etapas são bastante abstratas, então você também pode fazer isso com o conjunto de dados de sua escolha
Siga as instruções sobre como configurar o Elastic com Docker na página do Elastic aqui. Para este tutorial, você só precisa executar as duas etapas:
O repositório apresenta a classe ElasiticTransformers. Utilitários que ajudam a criar, indexar e consultar índices do Elasticsearch que incluem embeddings
Inicie os links de conexão, bem como (opcionalmente) o nome do índice com o qual trabalhar
et = ElasticTransformers ( url = 'http://localhost:9300' , index_name = 'et-tiny' )create_index_spec define o mapeamento para o índice. Listas de campos relevantes podem ser fornecidas para pesquisa por palavra-chave ou pesquisa semântica (vetor denso). Ele também possui parâmetros para o tamanho do vetor denso, pois eles podem variar create_index - usa a especificação criada anteriormente para criar um índice pronto para pesquisa
et . create_index_spec (
text_fields = [ 'publish_date' , 'headline_text' ],
dense_fields = [ 'headline_text_embedding' ],
dense_fields_dim = 768
)
et . create_index ()write_large_csv - divide um arquivo CSV grande em partes e usa iterativamente um utilitário de incorporação predefinido para criar a lista de incorporações para cada parte e, posteriormente, alimentar os resultados no índice
et . write_large_csv ( 'data/tiny_sample.csv' ,
chunksize = 1000 ,
embedder = embed_wrapper ,
field_to_embed = 'headline_text' )pesquisa - permite selecionar pesquisa por palavra-chave ('match' no Elastic) ou semântica (densa no Elastic). Notavelmente, requer a mesma função de incorporação usada em write_large_csv
et . search ( query = 'search these terms' ,
field = 'headline_text' ,
type = 'match' ,
embedder = embed_wrapper ,
size = 1000 )Após a configuração bem-sucedida, use os seguintes blocos de anotações para fazer tudo funcionar
Este repositório combina os seguintes trabalhos incríveis de pessoas brilhantes. Confira o trabalho deles se ainda não o fez...


